什么情况?
下面的一段简单代码,发现了奇怪的编码问题:
String docPath = "姝f枃";
// docPath = "正文"; // 注释1
System.out.println("default = " + docPath);
String docPath1 = new String(docPath.getBytes(), "GBK");
System.out.println("GBK = " + docPath1);
String docPath2 = new String(docPath.getBytes(), "UTF-8");
System.out.println("UTF-8 = " + docPath2);
String docPath3 = new String(docPath.getBytes(), "ISO-8859-1");
System.out.println("ISO-8859-1 = " + docPath3);
打印出来结果是?
default = 正文
GBK = 正文
UTF-8 = ????
ISO-8859-1 = ????
而把 注释1 打开,结果是:
default = ????
GBK = ????
UTF-8 = ????
ISO-8859-1 = ????
匪夷所思啊! 简直不可思议!!
查看文件编码:
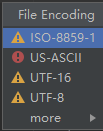
看起来编码是 ISO-8859-1 ?? ( 经过后面的反复测试,发现, 这个高亮的选中行并不是 文件的实际编码!! ), 转换成utf-8, 结果显示:
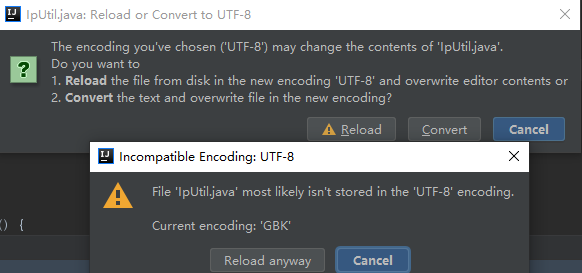
看起来当前文件编码是 GBK ? ———— 没错, 这个应该就是 文件的实际编码!!!
可是为什么 我明明 源码写的是 正文, 打印出来的是 “ 姝f枃 ” ??
难道是 console的显示编码的原因? console的显示编码 不可知,是不是 project encoding呢?
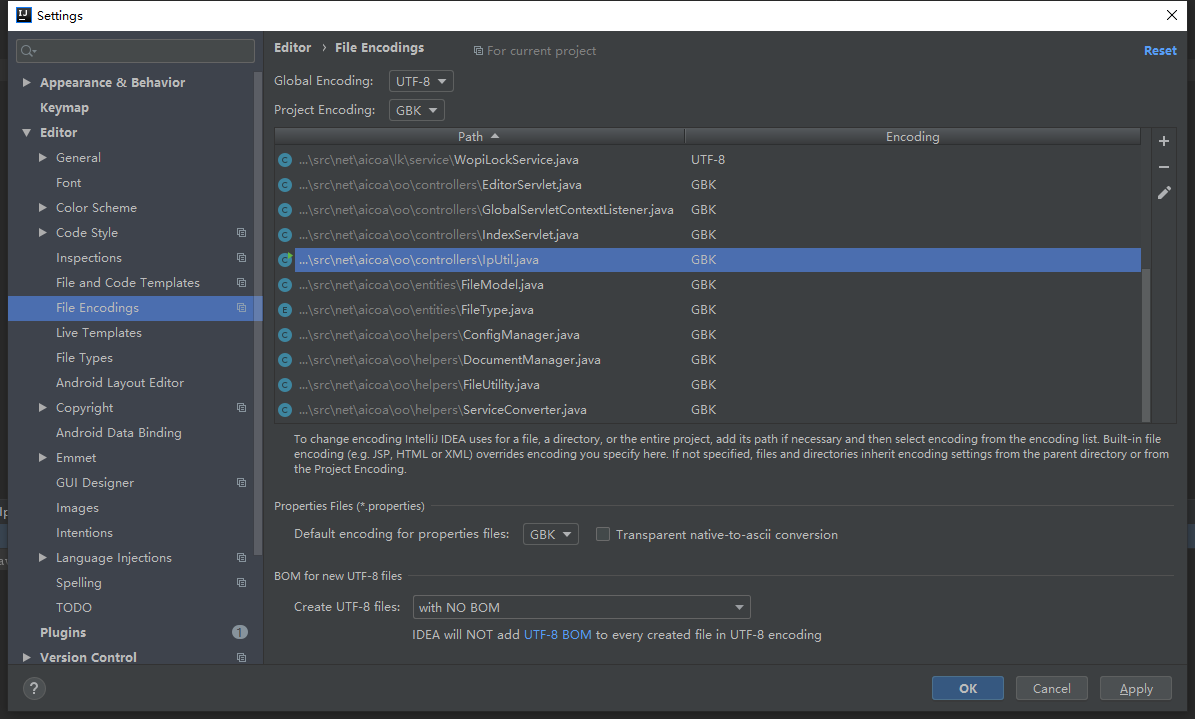
把Globa encoding 设置为GBK吧,结果还是一样的.. .
点击Reload Anyway , 结果,文件完全乱码了:
这里说明一下 Reload 和 Convert 的区别, 测试发现, Reload 就相当于 重新用新的编码打散然后用项目编码格式编码,然后加载,然后覆盖;Convert 是直接用新编码转换然后覆盖;;
难道是IDEA的问题?
通过cmd 命令行执行,可以看到结果都是一样的:
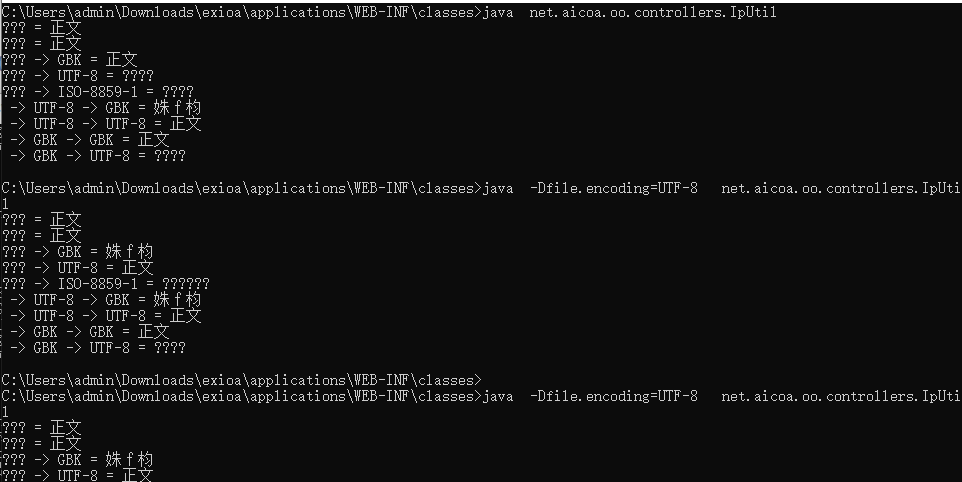
文件编码设置为GBK的时候, 出现了不可思议,如果文件编码设置是UTF-8, 则一切正常。。(同时可以看到 跟 -Dfile.encoding 参数是无关的!! 可以理解为 -Dfile.encoding 只在java 读取某些 外部 文件的时候的 默认编码?)
这就奇怪了。这说明class文件本身的内容就是那个了吧。跟IDEA 无关; 等等, 难道IDEA console 和 cmd 窗口的编码也是GBK?所以..
难道是。。。
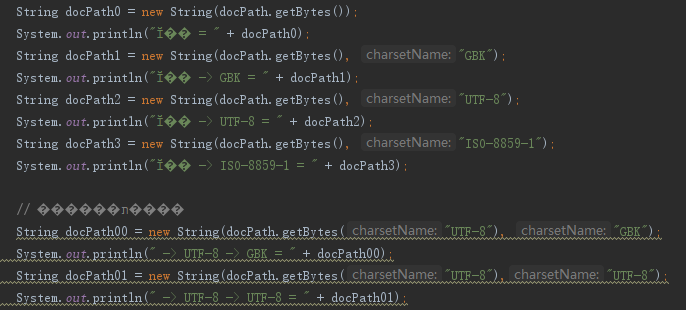
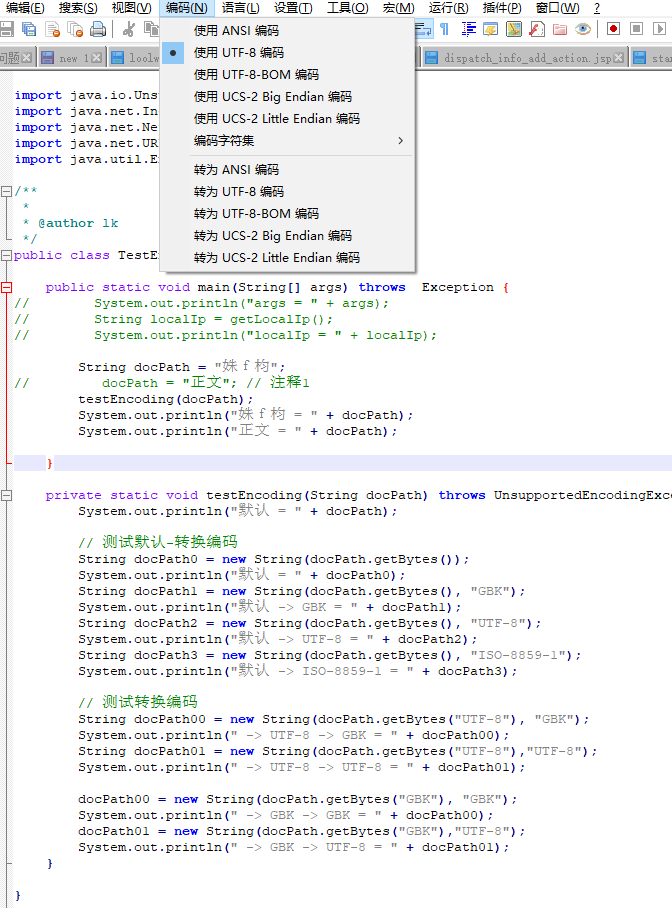
新建一个文件TestEncoding.java,notepad++ 编辑, 把原来的内容拷贝过来,
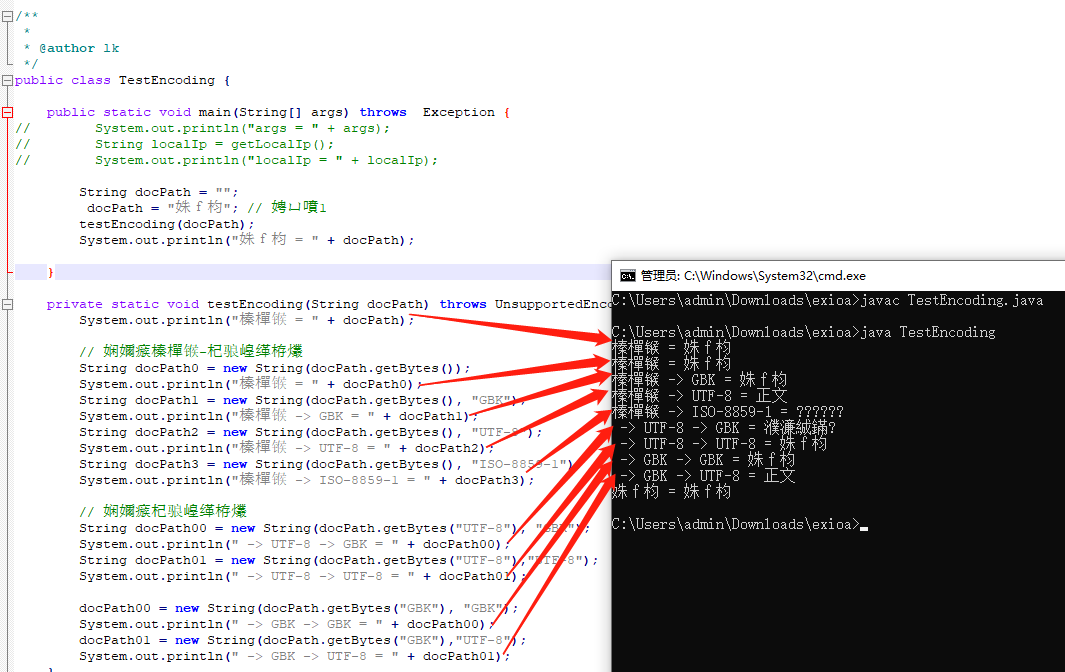
import java.io.UnsupportedEncodingException; import java.net.InetAddress; import java.net.NetworkInterface; import java.net.URLDecoder; import java.util.Enumeration; /** * * @author lk */ public class TestEncoding { public static void main(String[] args) throws Exception { // System.out.println("args = " + args); // String localIp = getLocalIp(); // System.out.println("localIp = " + localIp); String docPath = "姝f枃"; docPath = "正文"; // 注释1 testEncoding(docPath); System.out.println("正文 = " + docPath); System.out.println("姝f枃 = " + docPath); } private static void testEncoding(String docPath) throws UnsupportedEncodingException { System.out.println("默认 = " + docPath); // 测试默认-转换编码 String docPath0 = new String(docPath.getBytes()); System.out.println("默认 = " + docPath0); String docPath1 = new String(docPath.getBytes(), "GBK"); System.out.println("默认 -> GBK = " + docPath1); String docPath2 = new String(docPath.getBytes(), "UTF-8"); System.out.println("默认 -> UTF-8 = " + docPath2); String docPath3 = new String(docPath.getBytes(), "ISO-8859-1"); System.out.println("默认 -> ISO-8859-1 = " + docPath3); // 测试转换编码 String docPath00 = new String(docPath.getBytes("UTF-8"), "GBK"); System.out.println(" -> UTF-8 -> GBK = " + docPath00); String docPath01 = new String(docPath.getBytes("UTF-8"),"UTF-8"); System.out.println(" -> UTF-8 -> UTF-8 = " + docPath01); docPath00 = new String(docPath.getBytes("GBK"), "GBK"); System.out.println(" -> GBK -> GBK = " + docPath00); docPath01 = new String(docPath.getBytes("GBK"),"UTF-8"); System.out.println(" -> GBK -> UTF-8 = " + docPath01); } }
编码设置为UTF-8 ,
javac编译,然后java执行一下,发现错误:

仔细检查发现,,正是 “姝f枃” 这几个字符,在utf-8 格式下是不能被解析的!! 替换为空格 “”就好了,但是 编译执行后发现 还是不对:
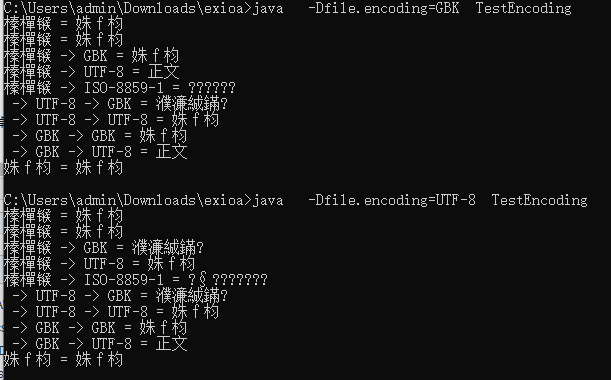
真是不可思议! 可见, 这个跟 是否是 IDEA 无关,这个是 编译之后的 class 文件本身内容的关系;
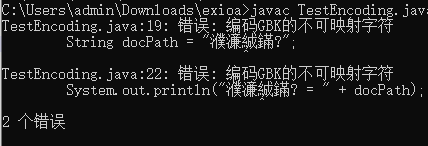
有时候出现:

哦, 错误: 编码GBK的不可映射字符。 ———— 连编译都不通过了!!
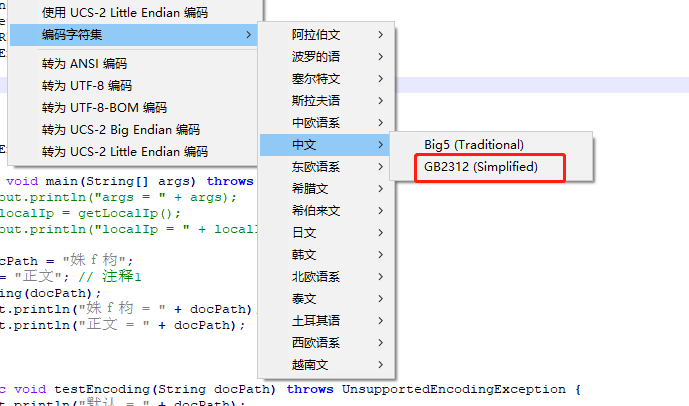
转换为GB2312,出现
点击“是”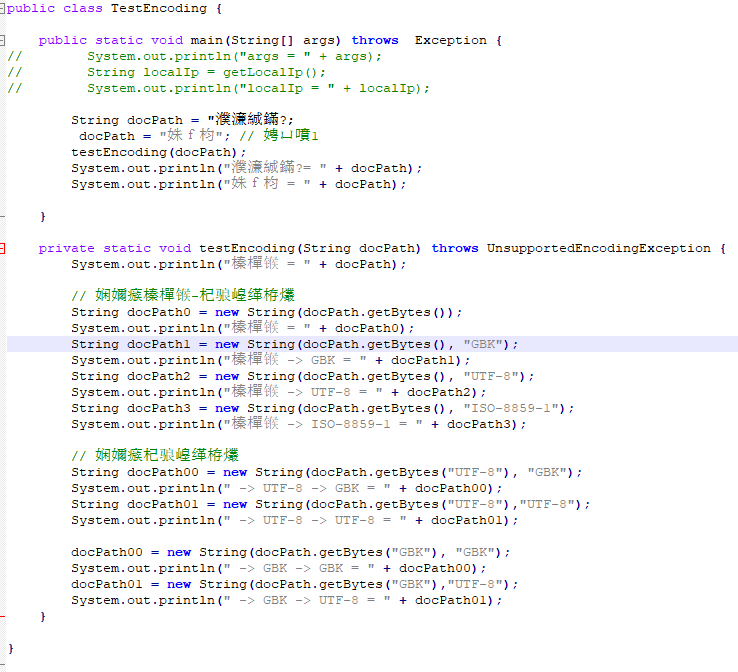
可见出现了乱码,特别注意到, 上面的页面的字样和 之前执行class 打印出来的 是一样的!
javac 同样有错:
郁闷了, 先把文件开始的那个文件内容复制,然后把Notepad++ 里的文件内容清空,然后编码转换为GB2312,然后复制文件内容;
然后javac, java 一切正常了。
然后编码格式强制转换为Utf-8, 出现下面的情况:

然后javac编译, java运行,发现结果跟 在IDEA中发现的一样的奇怪、不可思议; 可见,刚刚的转换过程,出现了问题, 应该来说,不能直接这么转换!!
然后呢,再转换为GB2312,
一切又正常了!!
难道是我电脑问题? windows 默认编码是GBK,所以? 拿到linux 虚拟机上运行一遍,发现结果是一样的。
再仔细想想,貌似 文件编码是GBK的时候能够打印 源码所见的 正确的结果, 文件编码设置是UTF-8的时候,就一定会出现奇怪现象...
为什么?
为此,我能想到的唯一的 解释是:编译之后的 class 文件本身内容不同,把不同看起来相同的 源码,用不同的编码格式保存,然后编译,然后对比class, 果然发现不同:
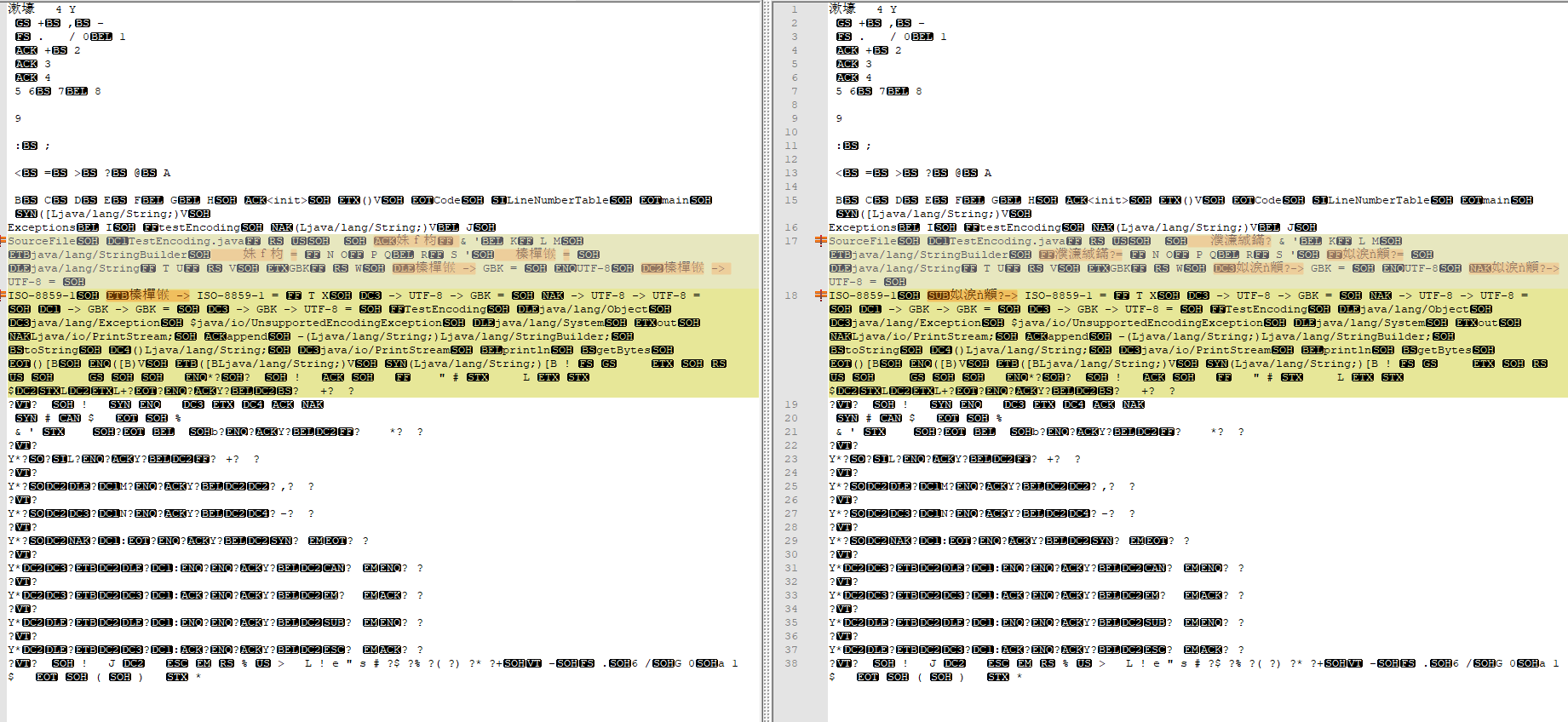
++++++++++++++++++++ ++++++++++++++++++++ ++++++++++++++++++++ 补充 start
后面研究了下 javac 命令,发现其实它是有一个 -encoding 参数的!! 之前一直没怎么注意!! 其实 上面奇怪现象的原因, 就是这个! javac 的默认编码参数是 系统编码, 所以...
C:Usersadmin est>javac 用法: javac <options> <source files> 其中, 可能的选项包括: -g 生成所有调试信息 -g:none 不生成任何调试信息 -g:{lines,vars,source} 只生成某些调试信息 -nowarn 不生成任何警告 -verbose 输出有关编译器正在执行的操作的消息 -deprecation 输出使用已过时的 API 的源位置 -classpath <路径> 指定查找用户类文件和注释处理程序的位置 -cp <路径> 指定查找用户类文件和注释处理程序的位置 -sourcepath <路径> 指定查找输入源文件的位置 -bootclasspath <路径> 覆盖引导类文件的位置 -extdirs <目录> 覆盖所安装扩展的位置 -endorseddirs <目录> 覆盖签名的标准路径的位置 -proc:{none,only} 控制是否执行注释处理和/或编译。 -processor <class1>[,<class2>,<class3>...] 要运行的注释处理程序的名称; 绕过默认的搜索进程 -processorpath <路径> 指定查找注释处理程序的位置 -parameters 生成元数据以用于方法参数的反射 -d <目录> 指定放置生成的类文件的位置 -s <目录> 指定放置生成的源文件的位置 -h <目录> 指定放置生成的本机标头文件的位置 -implicit:{none,class} 指定是否为隐式引用文件生成类文件 -encoding <编码> 指定源文件使用的字符编码 -source <发行版> 提供与指定发行版的源兼容性 -target <发行版> 生成特定 VM 版本的类文件 -profile <配置文件> 请确保使用的 API 在指定的配置文件中可用 -version 版本信息 -help 输出标准选项的提要 -A关键字[=值] 传递给注释处理程序的选项 -X 输出非标准选项的提要 -J<标记> 直接将 <标记> 传递给运行时系统 -Werror 出现警告时终止编译 @<文件名> 从文件读取选项和文件名
测试发现, 只要 javac 的 -encoding参数 和java 源码文件的编码格式一致, 那么就不会出现奇怪现象了!!
(原来如此,这么简单的原因没注意到,瞎jb忙 ... )
可是,为什么 IDEA中看到的GBK 编码的源码, 执行结果也是有乱码? 我感觉,可能文件都没有重新编译过吧。 可以把所有class 文件清除了然后再执行一遍。
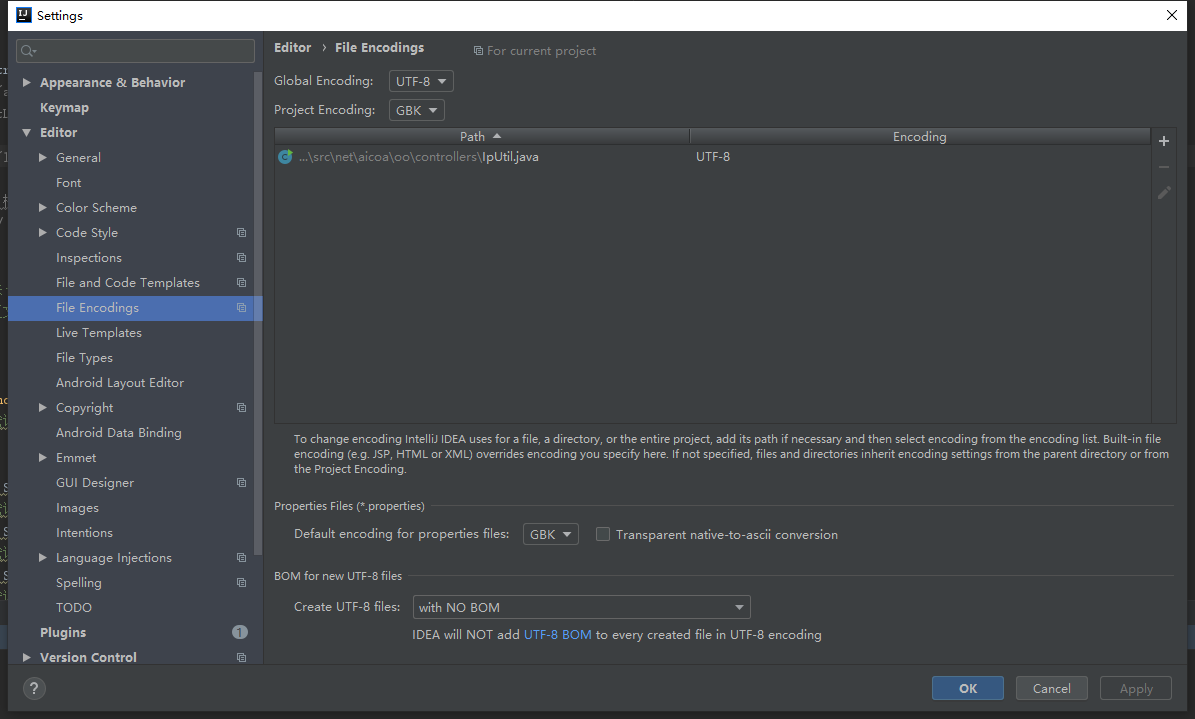
直接修改上图的 Project Encoding 是不会引起重新编译的! Global Encoding 作用不太清楚, 这个的设置, 不管它设置gbk 还是utf-8 ,结果都是 正确的。。
另外, 观察到IDEA 中也是可以设置javac 参数的:
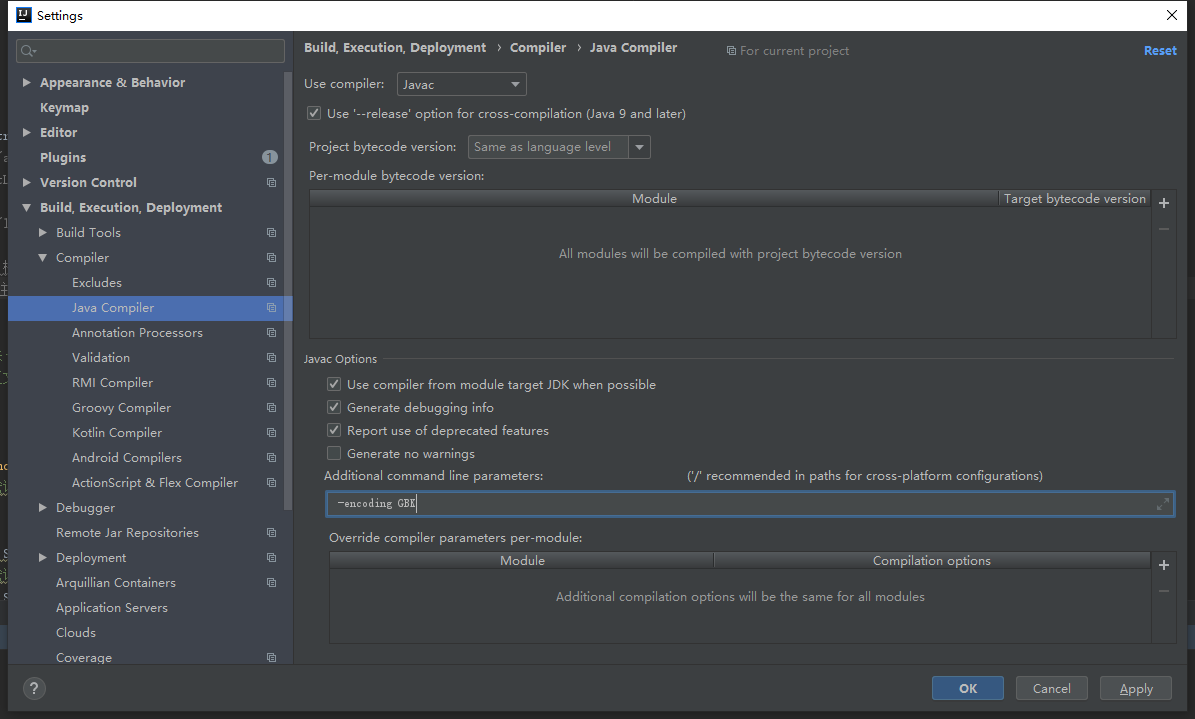
这个设置 确实有生效;
++++++++++++++++++++ ++++++++++++++++++++ ++++++++++++++++++++ 补充 end
怎么办?
总之,
0 javac 的 -encoding参数 是相当关键的, 默认是系统编码,windows 就是 GBK! 所以当我们设置java 源码文件编码为utf-8,然后编译的时候 需要注意 设置 javac 的 -encoding参数 !!
1 可见不是可得!! 有些java源码文件,其中的字符看起来 是正确编码,其实那个是 用其他编码格式编码的结果! 但是为什么 它在源码中显示正确呢? 那大概是因为 两种编码格式比如 UTF-8和GBK 有一定的交集, 编码reload或convert之后 ,呈现了相同的展现,但其实 内容是不同的!—— 这TM 确实有些不好理解啊!换言之, 源码的字样 到了 class 中会发生一些变化! 两者不是相同的!! 所以打印出来的 会不同!
2 编码转换的时候要小心,特别是 reload,很容易出问题的! 不能直接这么转换。如果用Notepad++ 转换文件编码格式, 出现了 “无法恢复警告” 那么就不能转;同样, 用IDEA reload 也要小心。
3 还是 class 内容的不同;