1. Reinforcement Learning
R L有两种策略,一种是基于Policy,另一种基于value;
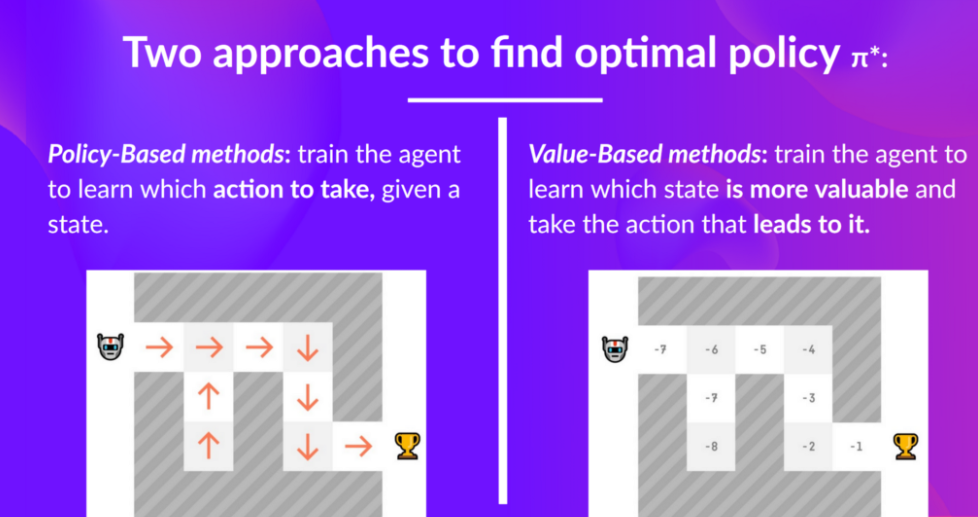
Reinforcement Learning的两种策略的主要目的都是找到学习到一个最优策略函数(pi),该函数会最大化目标奖励;找到最优策略函数有两种主要方法:一是直接通过交给agent学习如何选择需要做出的action(Policy-Based Methods);二是间接方法,教给agent如何做出最有价值的action从而达到more valuable states(Value-Based Methods)。
1.1 Policy-Based Methods
train/learn a policy function directly,该函数建立每个state到其相关的最好的action的映射;或者是在该状态时下一组可能的action的概率分布;此时没有value function,所以不能手动定义policy,而是通过train得到policy;
policy分为两种:一种是deterministic,此时给定的状态都会得到相同的action,即对一个state(s_0),通过策略函数(pi(s_0)),会得到动作(a_0);另一种是stochastic,会输出(pi(a|s)=P[A|s]),即得到action的概率分布。
1.2 Value based methods
Train a value function to learn which state is more valuable and using this value function to take the action that leads to it,该函数将a state映射到the expected value of being at that state.
这种没有train policy,所以需要手动规定,比如给定一个value function总是采取最大值的操作,则该policy即为贪心策略;
即从给定state开始,按照策略(指期望得到最大的value)能够得到的预期回报。如下图所示,value function可以算出每个给定状态的value。
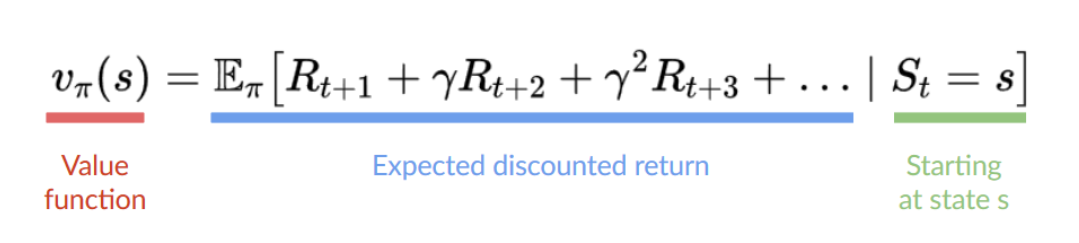
Q-Learning (classic Reinforcement Learning) and then Deep Q-Learning both are value-based Methods.
value-based function有两种:一种是state-value function,state-value function对每个state都会输出一个期望(如果从当前给定state开始的话),其中(pi)表示policy,
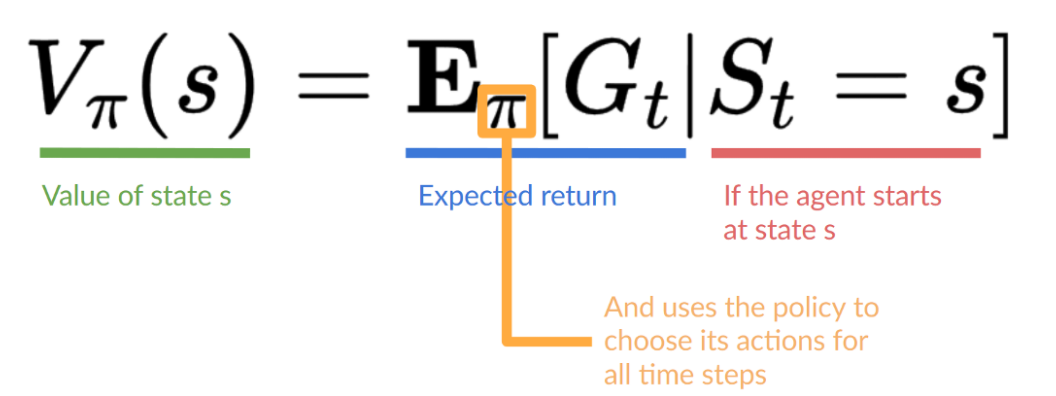
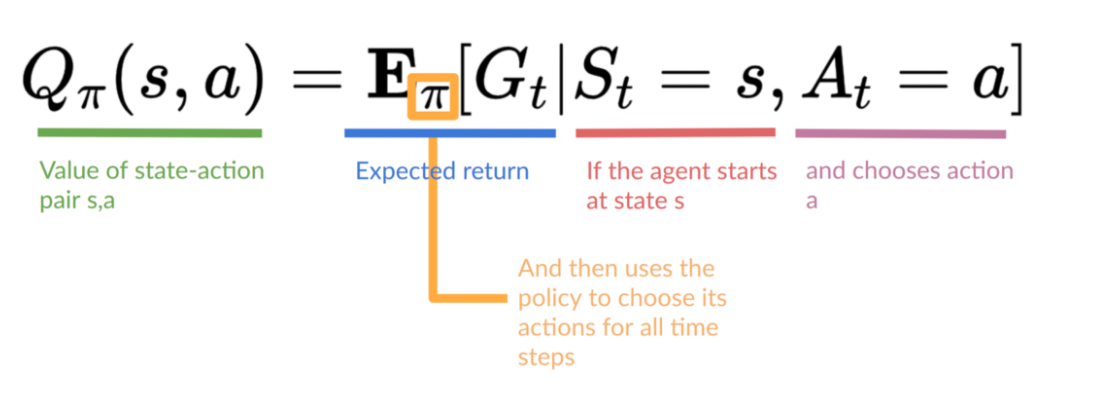
另一种是action-value function,而action-value function对每一对< state,action > 也会输出一个期望;
1.3 Difference
两种方法都需要policy,但是在value-based中不需要train policy,只需要直接手动指定policy即可(比如贪心策略),然后policy使用value function中得到的value来进行操作;
即policy-based中的optimal policy是train得到的,但是value-based找到value function就可以得到optimal policy;但是两者都会输出一个预期收益。
1.4 Use Bellman Equation to get reward
预期收益可以使用贝尔曼方程(recursive)进行简化计算,如下,其中(R_{t+1})指即时回报,即(V(S_t)=R_{t+1}+gamma V(S_{t+1}))。
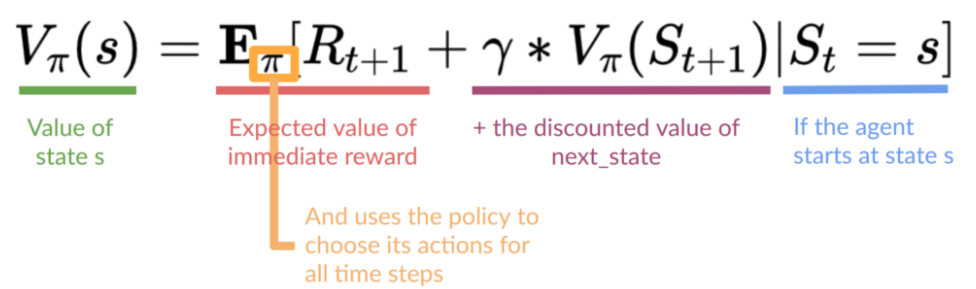
1.5 How to train value function or policy function
RL agent 是通过和环境进行交互习得经验进行学习的,Monte Carlo和Temporal Difference Learning是两种常见的策略都是基于此,用于train value function or policy function,不同之处在于Monte Carlo使用之前的全部经验来学习,而Temporal Difference Learning只是用一步(如((S_t,A_t,R_{t+1},S_{t+1})))进行学习。
以value-based为例,Monte Carlo会在前面一部分的步骤都结束之后,计算结果(G_t)然后对(V(S_t))进行更新,如下:

比如设置learning rate=0.1 and discount rate =1(相等于没有discount),假如(G_t=R_{t+1}+R_{t+2}+dots R_{t+10}),则就可以根据上面的公式对(V(S_t)=V(S_t)+0.1*[G_{t}-V(S_t)])进行更新,需要注意后面两个(V(S_t))初始值为0。
而Temporal Difference Learning(TD learning)每一步之后(得到(R_{t+1}))就进行更新,在这里就没有(G_t)(an entire episode),此时的(G_t=R_{t+1}+gamma V(S_{t+1}))
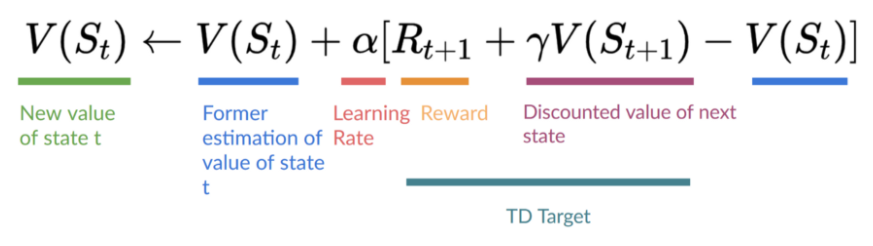
2. Q-Learning
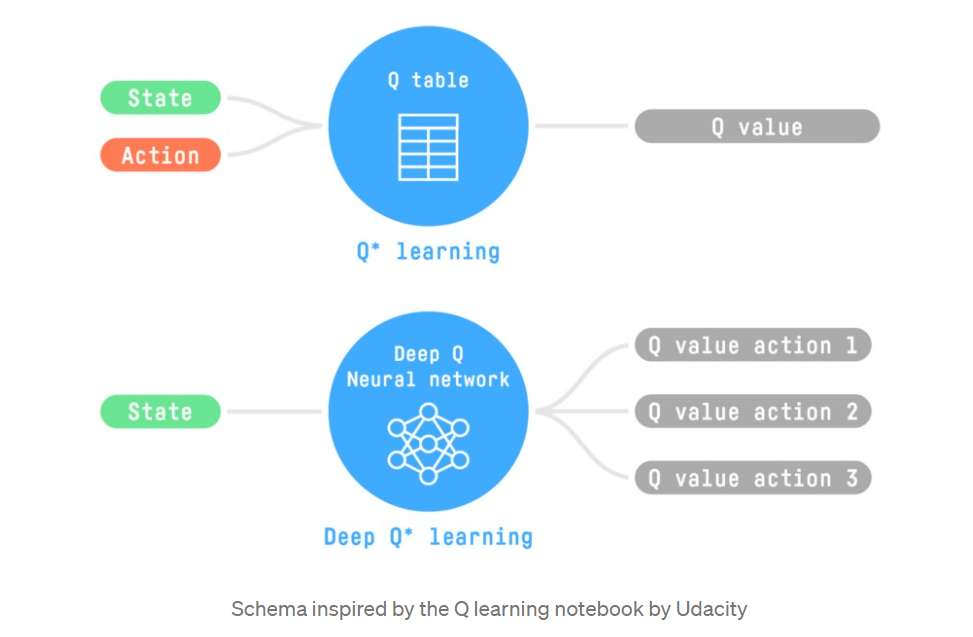
2.1 What is Q-Learning
Q-Learning is an off-policy value-based method that uses a TD approach to train its action-value function.
TD approach(即Temporal Difference Learning)指的是在每一步都updates its action-value function。
off-policy指的是using a different policy for acting and updating。
实际上Q-Learning目的就是train a action-value function(在这里叫做Q-Function),具体而言,Q-Function拥有一个Q-table,其中包含全部的state-action pair value。所以给定一个state-action对,Q-Function会搜索Q-table然后输出对应的值。
则当训练结束,即可得到optimal Q-Function (Q)->optimal Q-table,从而拥有一个optimal policy (pi),给定一个state就可以知道best action,value function和policy关系如下:
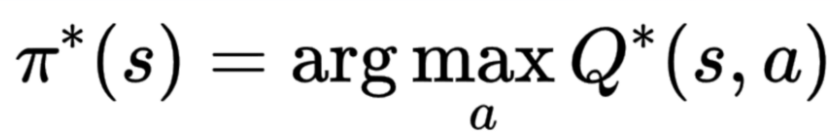
而training的过程就是不断更新Q-table的过程。
在每个time step,都可以得到a tuple (state, action, reward, new_state)。
2.2 Q-Learning Algorithm

step 1:初始化Q-table,常见操作时初始化为0;

step 2:使用Epsilon Greedy Strategy来选择action,Epsilon Greedy Strategy首先给个(epsilon),则有(1-epsilon)的可能采取贪心行为(即exploration),(epsilon)的可能采取随机行为(即exploitation)。
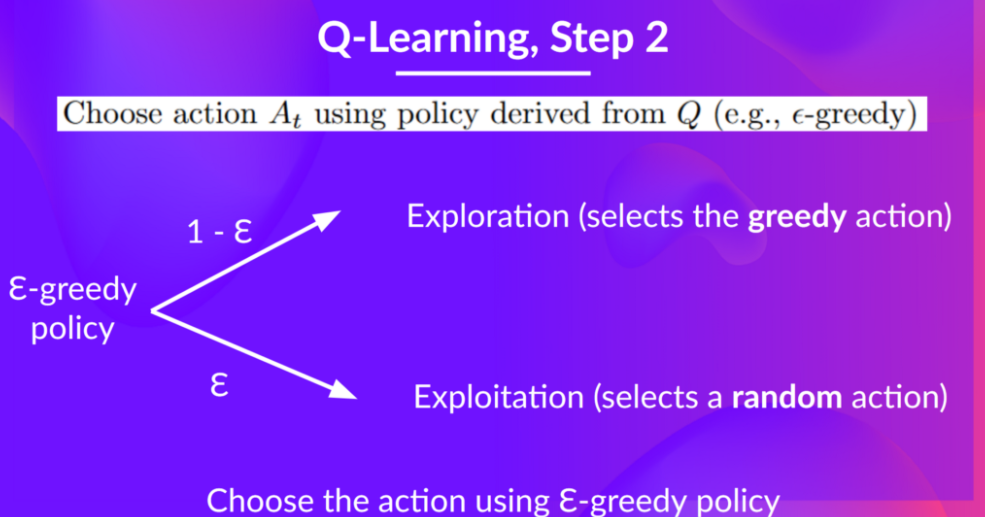
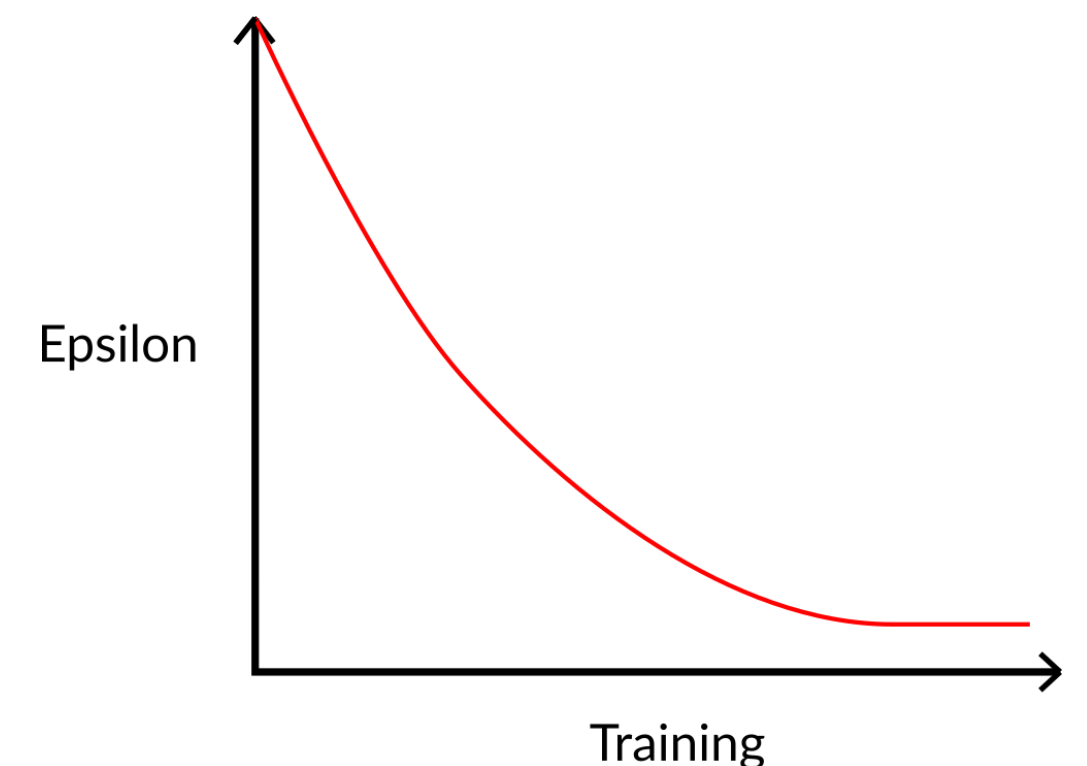
最开始的时候因为(epsilon)的值比较大,所以一般会采取random action,随着training的进度,该值不断下降,如下图所示:
step 3:执行action (A_t),得到(R_{t+1})和(S_{t+1})。

step 4:更新(Q(S_t,A_t)),TD方法需要再每次交互后都进行update;
结合TD方法公式:
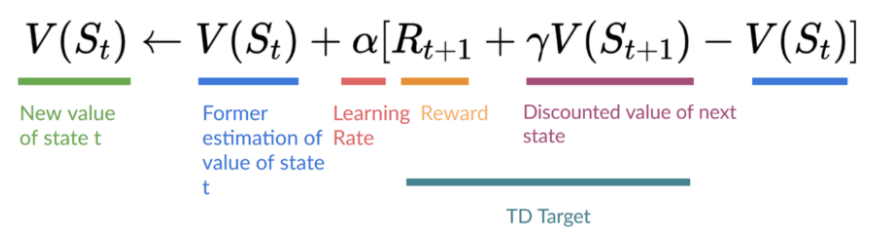
则Q-Function更新公式如下:
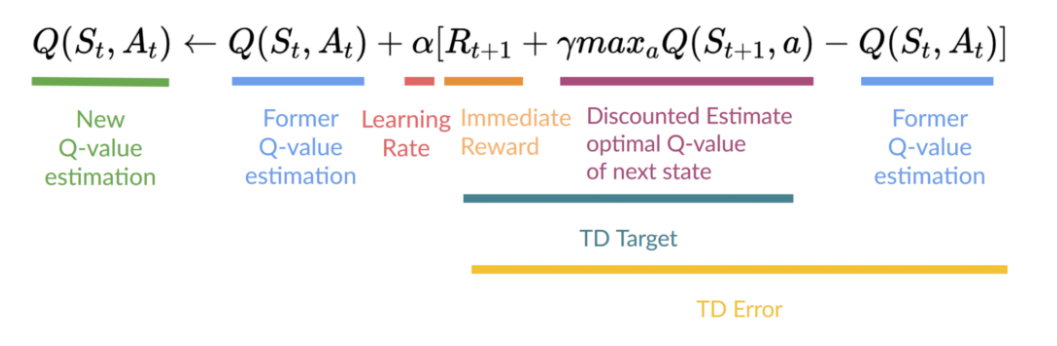
即为了更新(Q(S_t,A_t)),需要(S_t,A_t,R_{t+1},S_{t+1});
同时为更新state-action pair的Q-value,需要得到TD-target,这里使用(R_{t+1})来得到下一个state-action pair,此时是基于贪心策略的,当Q-value更新完毕之后,在一个新state时再使用Epsilon Greedy Strategy来选择action。
2.3 Off-policy and On-policy
更新和选择action的策略不同即为off-policy,反之为on-policy,如下:

3. Deep Q-Learning
使用Deep Q Neural Network(DQN)来替代Q-table,给定一个state,来对每一个action,进行value approximation。
DQN以四帧图像(具体为 an 84x84x4 image produced by the preprocessing map)作为input,output为所有state (s)下可能采取的action的Q value,DQN使用Bellman equation来最小化loss function,如下图所示:
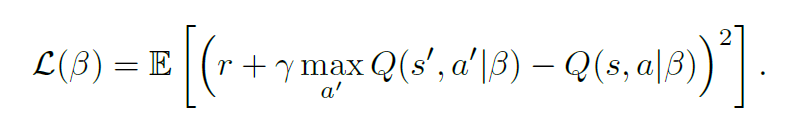
以下的例子以游戏Doom为例!
3.1 Preprocessing map
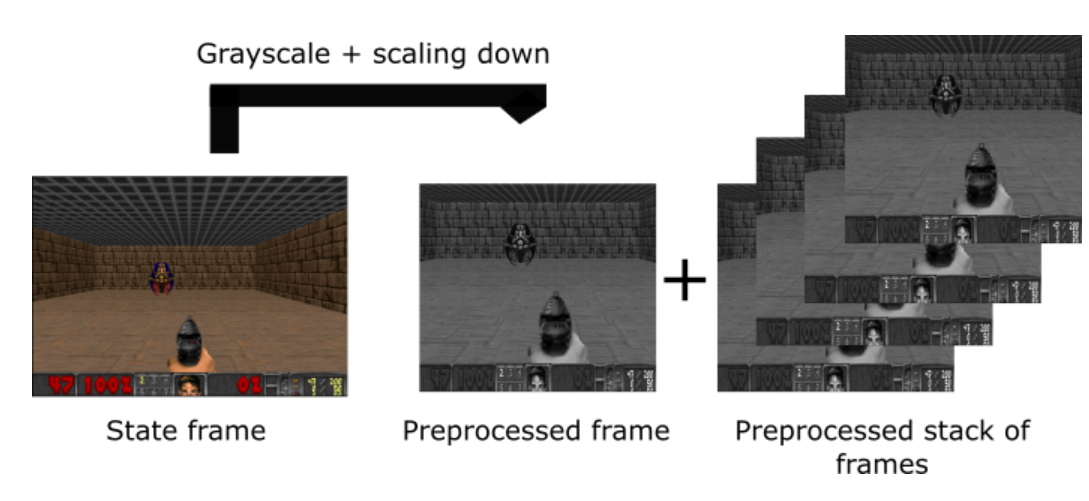
首先对当前的状态帧进行grayscale,然后对frame进行修剪(这个例子中是对途中的屋顶进行裁剪),减少frame的大小,再堆叠四帧图像。
Our steps:
- Grayscale each of our frames (because color does not add important information ).
- Crop the screen (in our case we remove the part below the player because it does not add any useful information)
- We normalize pixel values
- Finally we resize the preprocessed frame
网络三个concolution layers(act=“Relu”) + FC(act=“Relu”) + output layer(act=linear)构成,之前说过在每个time step,都可以得到a tuple (state, action, reward, new_state),该元组会反馈给网络。
但是如果单纯地把与环境交互作用的连续样本给神经网络,它往往会忘记以前的经历,因为它会被新的经验所覆盖。所以需要新加一个replay buffer用于存储经验元组(当和环境进行交互的时候),然后从中(可能是随机)sample一部分作为网络的输入,从而防止网络只学到当前的经验。
还有一个问题就是需要减少经验之间的相关性,因为每一个动作都会影响到下一个状态,输出可能高度相关,从replay buffer中随机采样即可解决这个问题。
Stacking frames is really important because it helps us to give have a sense of motion to our Neural Network.
BUT, we don't stack each frames, we skip 4 frames at each timestep. This means that only every fourth frame is considered. And then, we use this frame to form the stack_frame.
The frame skipping method is already implemented in the library.
- First we preprocess frame
- Then we append the frame to the deque that automatically removes the oldest frame
- Finally we build the stacked state
This is how work stack:
- For the first frame, we feed 4 frames
- At each timestep, we add the new frame to deque and then we stack them to form a new stacked frame
- If we're done, we create a new stack with 4 new frames (because we are in a new episode).
这里同样使用Bellman equation来更新给定state-action的Q value,并更新网络权重以减少误差(TD error)。

创建模型如下:
- We take a stack of 4 frames as input
- It passes through 3 convnets
- Then it is flatened
- Finally it passes through 2 FC layers
- It outputs a Q value for each actions
训练agent:
Our algorithm:
Initialize the weights
Init the environment
Initialize the decay rate (that will use to reduce epsilon)
For episode to max_episode do
Make new episode
Set step to 0
Observe the first state (s_0)
While step < max_steps do:
- Increase decay_rate
- With (epsilon) select a random action (a_t), otherwise select (a_t = mathrm{argmax}_a Q(s_t,a))
- Execute action (a_t) in simulator and observe reward (r_{t+1}) and new state (s_{t+1})
- Store transition (lt s_t, a_t, r_{t+1}, s_{t+1}gt) in memory (D)
- Sample random mini-batch from (D):(lt s, a, r, s' gt)
- Set (hat{Q} = r) if the episode ends at (+1), otherwise set (hat{Q} = r + gamma max_{a'}{Q(s', a')})
- Make a gradient descent step with loss ((hat{Q} - Q(s, a))^2)
endfor
endfo
4. Environment Problems
pip install baselines
pip install gym
pip install cmake
pip install --no-index -f https://github.com/Kojoley/atari-py/releases atari_py
出现...ale_c.dll' (or one of its dependencies). Try using the full path with constructor syntax时:
首先尝试:
- Uninstall gym and atari-py (If already installed):
pip uninstall atari-py
pip uninstall gym[atari]- Download VS build tools here: https://visualstudio.microsoft.com/thank-you-downloading-visual-studio/?sku=BuildTools&rel=16
- Run the VS build setup and select "C++ build tools" and install it.
- Restart PC.
- Install cmake, atari-py and gym
pip install cmake
pip install atari-py
pip install gym[atari]- Now run the following code:
import atari_py
print(atari_py.list_games())不行再尝试:
pip uninstall atari-py
pip install --no-index -f https://github.com/Kojoley/atari-py/releases atari_py
pip install gym

5. Reference
[1]https://simoninithomas.github.io/deep-rl-course/
[2]Mnih, Volodymyr, et al. “Human-level control through deep reinforcement learning." nature 518.7540 (2015): 529-533.
[3]https://gym.openai.com/envs/#atari