Google Protocol Buffers 编码(Encoding)
1. 概述
前三篇文章《Google Protocol Buffers 概述》《Google Protocol Buffers 入门》《Protocol Buffers 语法指南》 一步一步将大家带入Protocol Buffers的世界,我们已经基本能够使用Protocol Buffers生成代码,编码,解析,输出级读入序列化数据。该篇主要讲述PB message的底层二进制格式。不了解该部分内容,并不影响我们在项目中使用Protocol Buffers,但是了解一下PB格式是如何做到smaller这一层,确实是很有必要的。Protobuf 序列化后所生成的二进制消息非常紧凑,这得益于 Protobuf 采用的非常巧妙的 Encoding 方法。
2. 一个简单的例子
.proto文件定义一条简单的message:
|
1
2
3
|
message Test1 { required int32 a = 1; } |
使用该.proto生成相应类并写入一条message到一个文件中,这里我写入test.txt文件:
|
1
2
3
4
5
6
|
public static void main(String[] args) throws IOException { Simple simple = Simple.newBuilder().setId(150).build(); FileOutputStream output = new FileOutputStream("abc.txt"); simple.writeTo(output); output.close(); } |
使用UltraEdit打开,二进制格式查看,发现只占用了三个字节:
![]()
整条message存储只用了三个字节,甚至小于一个整形的大小,这是什么意思?怎么做到的?Protobuf 序列化后所生成的二进制消息非常紧凑,这得益于 Protobuf 采用的非常巧妙的 Encoding 方法。
3. Varint
在了解PB encoding之前,我们先来了解一下varint。Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为 1,表示后续的 byte 也是该数字的一部分,如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。因此小于 128 的数字都可以用一个 byte 表示。大于 128 的数字,会用两个字节。
例如整数1的表示,仅需一个字节:
0000 0001
例如300的表示,需要两个字节:
1010 1100 0000 0010
采 用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息。
下图演示了 Google Protocol Buffer 如何解析两个 bytes。注意到最终计算前将两个 byte 的位置相互交换过一次,这是因为 Google Protocol Buffer 字节序采用 little-endian 的方式。
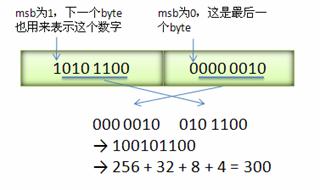
4. Message 格式
消息经过序列化后会成为一个二进制数据流,该流中的数据为一系列的 Key-Value 对。如下图所示:
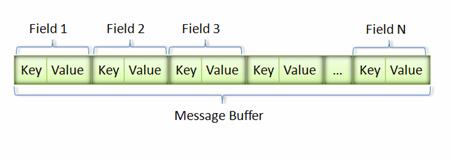
采用这种 Key-Pair 结构无需使用分隔符来分割不同的 Field。对于可选的 Field,如果消息中不存在该 field,那么在最终的 Message Buffer 中就没有该 field,这些特性都有助于节约消息本身的大小。
二进制格式的message使用数字标签作为key,Key 用来标识具体的 field,在解包的时候,Protocol Buffer 根据 Key 就可以知道相应的 Value 应该对应于消息中的哪一个 field。
将 message编码后,key-values被编码成字节流存储。在message解码时,PB 解析器会跳过(忽略)不能够识别的字段,所以,message即使增加新的字段,也不会影响老程序代码,因为老程序代码根本就不能识别这些新添加的字段。 为此,该处,key需要特殊设计。
上边我们说,“二进制格式的message使用数字标签作为key”,此处的数字标签,并非单纯的数字标签,而是数字标签与传输类型的组合,根据传输类型能够确定出值的长度。
key的定义:
(field_number << 3) | wire_type
可以看到 Key 由两部分组成。第一部分是 field_number,第二部分为 wire_type。表示 Value 的传输类型。也就是说,key中的后三位,是值得传输类型。有关移位操作简单知识,可以参见:Java位操作基本知识
Wire Type 可能的类型如下表所示:
| Type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimi | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | Groups (deprecated) |
| 4 | End group | Groups (deprecated) |
| 5 | 32-bit | fixed32, sfixed32, float |
5. 分析产生数据
在第二部分简单的例子中,写入message后,我们看到最终输出文件中包含三个数字:08 96 01,这是如何得来的呢?
如图:

至此我们知道数字标签是1,值类型为varint。使用第四部分我们分析的,来解码96 01,即为150:
|
1
2
3
4
|
96 01 = 1001 0110 0000 0001 → 000 0001 ++ 001 0110 (drop the msb and reverse the groups of 7 bits) → 10010110 → 2 + 4 + 16 + 128 = 150 |
注意:数值部分,低位在前,高位在后。
6. 其他数值类型
6.1 有符号整数
细 心的读者或许会看到在 Type 0 所能表示的数据类型中有 int32 和 sint32 这两个非常类似的数据类型。Google Protocol Buffer 区别它们的主要意图也是为了减少 encoding 后的字节数。这部分,主要是针对负数来设计的。
在计 算机内,一个负数一般会被表示为一个很大的整数,因为计算机定义负数的符号位为数字的最高位。如果采用 Varint 表示一个负数,那么一定需要 10 个 byte长度。为此 Google Protocol Buffer 定义了 sint32 这种类型,采用 zigzag 编码。将所有整数映射成无符号整数,然后再采用varint编码方式编码,这样,绝对值小的整数,编码后也会有一个较小的varint编码值。
Zigzag映射函数为:
Zigzag(n) = (n << 1) ^ (n >> 31), n为sint32时
Zigzag(n) = (n << 1) ^ (n >> 63), n为sint64时
按照这种方法,-1将会被编码成1,1将会被编码成2,-2会被编码成3,如下表所示:
| Signed Original | Encoded As |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 3 |
| 2 | 4 |
| -3 | 5 |
| … | … |
| 2147483647 | 4294967294 |
| -2147483648 | 4294967295 |
6.2 Non-varint 数字
Non-varint数字比较简单,double 、fixed64 的线路类型为 1,在解析式告诉解析器,该类型的数据需要一个64位大小的数据块即可。同理,float和fixed32的线路类型为5,给其32位数据块即可。两种情况下,都是高位在后,低位在前。
6.3 String
线路类型为2的数据,是一种指定长度的编码方式:key+length+content,key的编码方式是统一的,length采用varints编码方式,content就是由length指定长度的Bytes。定义如下的message格式:
|
1
2
3
4
5
|
message Test2 { required string b = 2; } |
设置该值为"testing",二进制格式查看:
12 07 74 65 73 74 69 6e 67
红色字节为“testing”的UTF8代码。
此处,key是16进制表示的,所以展开是:
12 -> 0001 0010,后三位010为wire type = 2,0001 0010右移三位为0000 0010,即tag=2。
length此处为7,后边跟着7个bytes,即我们的字符创"testing"。
6.4 嵌套message
定义如下嵌套消息:
|
1
2
3
|
message Test3 { required Test1 c = 3; } |
同第二部分一样,设置字段为整数150,编码后的字节为:
1a 03 <span style="color: red;">08 96 01</span>
我们发现,后三个字节跟我们第一个例子中的一摸一样(08 96 01),他们前边有一个长度限制03,课件嵌套消息跟string是一摸一样的,其wire type 也为2。
6.5 wire type = 3、4
该两个字段已经废弃不再使用,故忽略吧~
7. 可选字段和重复字段
假 如定义的message中有repeated元素并且该声明后并未使用[packed=true]选项,编码后的message有一个或者多个包含相同 tag数字的key-value对。这些重复的value不需要连续的出现;他们可能与其他的字段间隔的出现。尽管他们是无序的,但是在解析时,他们是需 要有序的。
对于可选字段,编码后的message中,拥有该数字标签的key-value对可有可无。
通常,编码后的 message,其required字段和optional字段最多只有一个实例。但是解析器却需要处理多余一个的情况。对于数字类型和string类 型,如果同一值出现多次,解析器接受最后一个它收到的值。对于内嵌字段,解析器合并(merge)它接收到的同一字段的多个实例。就如MergeFrom 方法一样,所有单数的字段,后来的会替换先前的,所有单数的内嵌message都会被合并(merge),所有的repeated字段,都会串联起来。这 样的规则的结果是,解析两个串联的编码后的message,与分别解析两个message然后merge,结果是一样的。例如:
|
1
2
|
MyMessage message; message.ParseFromString(str1 + str2); |
这种做法,等价于:
|
1
2
3
4
|
MyMessage message, message2; message.ParseFromString(str1); message2.ParseFromString(str2); message.MergeFrom(message2); |
这种方法有时是非常有用的。比如,即使不知道message的类型,也能够将其合并。
7.1 设置了[packed = true]的repeated字段
在 2.1.0后,PB引入了该种类型,其与repeated字段一样,只是在末尾声明了[packed=true]。类似repeated字段却又不同。对 于packed repeated字段,如果message中没有赋值,则不会出现在编码后的数据中。否则的话,该字段所有的元素会被打包到单一一个key-value对 中,且它的wire type=2,长度确定。每个元素正常编码,只不过其前没有标签。例如有如下message类型:
|
1
2
3
|
message Test4 { repeated int32 d = 4 [packed=true]; } |
构造一个Test4字段,并且设置repeated字段d两个值:3、270和86942,编码后:
|
1
2
3
4
5
6
7
8
9
|
22 // tag 0010 0010(field number 010 0 = 4, wire type 010 = 2) 06 // payload size (设置的length = 6 bytes) 03 // first element (varint 3) 8E 02 // second element (varint 270) 9E A7 05 // third element (varint 86942) |
仅有原子数字类型(varint, 32-bit, or 64-bit)可以被声明为“packed”
有一点需要注意,对于packed的repeated字段,尽管通常没有理由将其编码为多个key-value对,编码器必须有接收多个key-pair对的准备。这种情况下,payload 必须是串联的,每个pair必须包含完整的元素。
8. 字段顺序
简单来说只有两点:
- 编码/解码与字段顺序无关,这一点由key-value机制就能保证
- 对于未知的字段,编码的时候会把它写在序列化完的已知字段后面。
推荐阅读顺序,希望给你带来收获~