1.环境
| 角色 | ip | 主机名 |
|---|---|---|
| 负载均衡节点 | 10.0.0.11 | nginx-lb01 |
| 可读写web01节点 | 10.0.0.12 | nginx-web01 |
| 只读web02节点 | 10.0.0.13 | nginx-web02 |
2.nginx-lb01的nginx配置文件如下
[root@nginx-lb01 ~]# cat /etc/nginx/nginx.conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream backend1 {
server 10.0.0.12;
}
upstream backend2 {
server 10.0.0.13;
}
server {
listen 80;
server_name localhost;
location / {
if ($request_method = POST ) {
proxy_pass http://backend1;
}
proxy_pass http://backend2;
}
}
}
3.nginx-web01和nginx-web02配置文件相同
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name localhost;
root html;
index index.php index.html index.htm;
location / {
}
location ~ .php$ {
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}
}
nginx-web01和nginx-web02区别只有nfs挂载的区别
nginx-web01的挂载参数为
mount -t nfs 10.0.0.11:/data wp-content/uploads
nginx-web02的挂载参数为
mount -t nfs -o ro 10.0.0.11:/data wp-content/uploads
上传图片测试,抓包结果如下
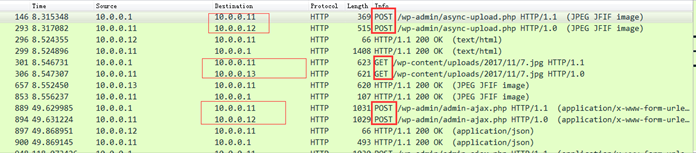
从上图可以看出,上传图片之后,先是post到负载均衡——> post到web01——>返回结果给负载均衡——>返回结果给用户
接着又发起了一个新的请求,这次是get请求,先get到负载均衡——>get到web02——>返回结果给负载均衡——>返回结果给用户
到这里,已经实现了POST请求方法走web01,GET请求方法走web02