国内源真香
Syntactic sugar(语法糖)
ODPS => 开放数据处理服务 =》 maxcompute
AutoCAD Drawing Database => AutoCAD 绘图数据库
three.js =》 3d 渲染引擎
UML ==> Unified Modeling Language
VPC ==> Virtual Private Cloud
MPP ==> Massively Parallel Processing
LDAP(Light Directory Access Portocol)
exactly-once 精确一次语义
DSL (Domain Specific Language)
elasticsearch 安装使用
1.编辑 /etc/security/limits.conf,追加以下内容(这几个步骤执行完毕后可能需要重新登录,直接切换一次用户即可)
* soft nofile 65535
* hard nofile 65535
* soft nproc 4096
* hard nproc 4096
2.编辑 /etc/sysctl.conf,追加以下内容
vm.max_map_count=655350
# 生效
sysctl -p
# exit 退出,重新登录生效
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.1/elasticsearch-analysis-ik-5.5.1.zip
写操作在主节点
读操作可以直接在从节点,从而达到负载均衡
bin/elasticsearch -d =》 daemon
9200 为 默认 Restful 访问端口
9300 为各个节点内部通信端口
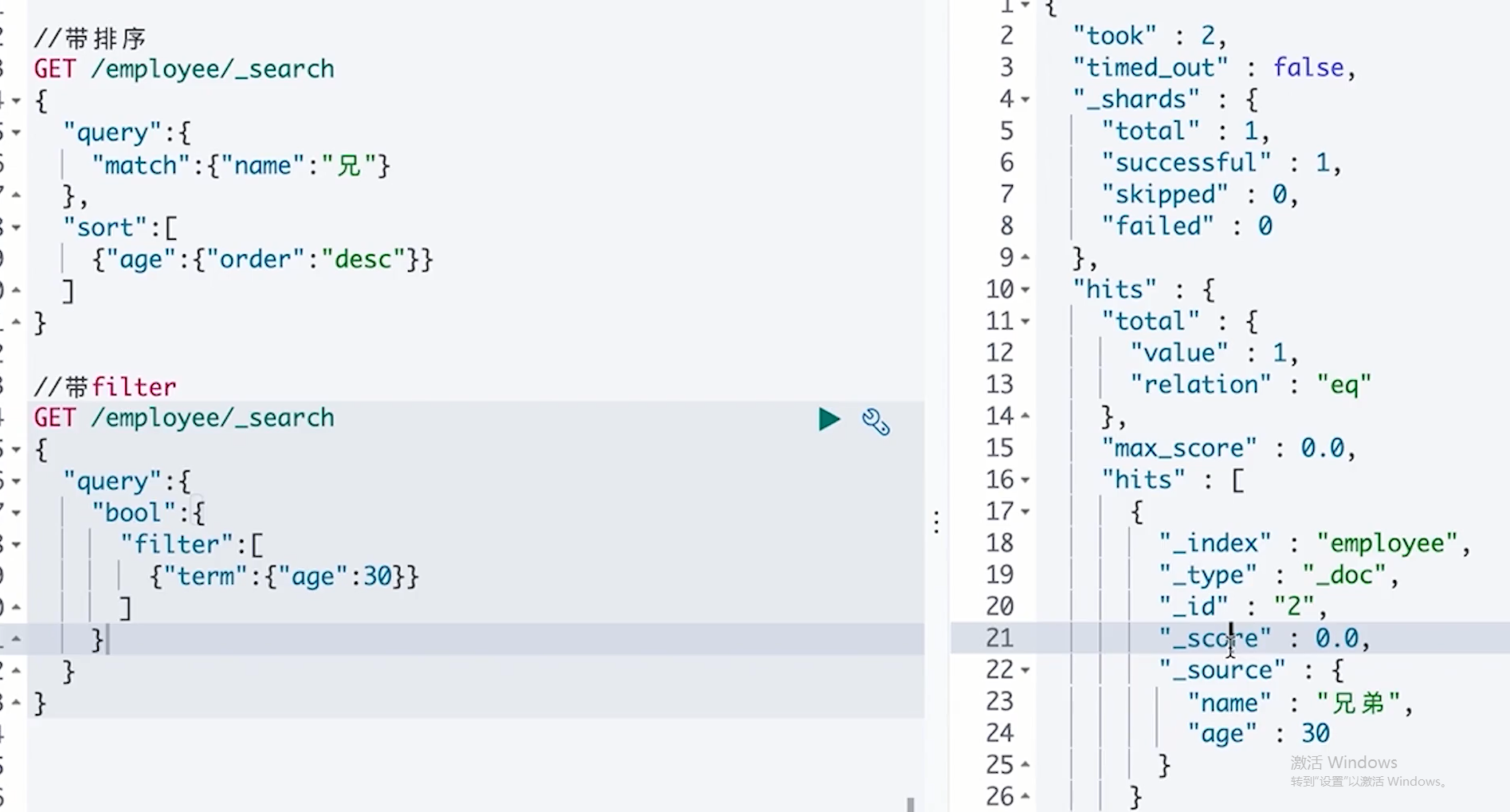
GET /tnbs/_search
{
"query":{
"match_all":{}
}
}
DELETE /tnbs
kibana 安装使用
sudo rpm -ivh xxx.rpm
/usr/share/kibana
/etc/kibana/kibana.yml
安装Kibana时出现:
default index Error: Please specify a default index pattern
KbnError@http://localhost:5601/
解决的方法:
将配置文件kibana.yml中下面一项的配置放开(#注释符去掉)即可:
kibana.index: ".kibana"
curl -X PUT "http://kylin:9200/index_20201114"
也可以在 kibana 上执行下面的命令创建, 查询
查看节点健康情况
GET /_cat/health?v
查看cluster中有哪些index:
GET /_cat/indices?v
GET _search
{
"query": {
"match_all": {}
}
}
PUT /accounts
{
"settings":{
"number_of_shards":1,
"number_of_replicas":0
}
}
PUT /accounts/person/1
{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}
PUT /index/type/id--->/索引名/类型名/doucument_Id/{document内容}
{
"json数据"
}
PUT /hr/emp/0
{
"name":"James Bond",
"gender": 100
}
GET /hr/emp/0
# 结构化创建
PUT /employee
{
"settings": {
"number_of_shards":1,
"number_of_replicas": 1
},
"mappings": {
"properties":{
"name":{"type":"text"},
"age":{"type":"integer"}
}
}
}
# hr 带 body 体 查询
GET /hr/_search
{
"query": {
"match_all": {}
}
}
PUT /movie/doc_type/1
{
"name":"Eating an apple a day & keeps the doctor away"
}
GET /movie/_search
{
"query":{
"match":{"name":"Eating"}
}
}
# 使用 api 分词接口查看分词
GET /movie/_analyze
{
"field": "name",
"text":"Eating an apple a day & keeps the doctor away"
}
PUT /movie_2
{
"settings":{
"number_of_shards":1,
"number_of_replicas":1
},
"mappings":{
"products":{
"properties":{
"name":{"type":"text", "analyzer":"english"}
}
}
}
}
PUT /movie_2/doc_type/1
{
"name":"Eating an apple a day & keeps the doctor away"
}
GET /movie_2/_search
{
"query":{
"match":{"name":"eat"}
}
}
Text: 被分析索引的字符串类型
Keyword: 不能被分析只能被精确匹配的字符串类型
Date: 日期类型, 可以配合 format 一起使用
数字类型: long, integer, short , double 等
boolean: true false
Array:["one", "two"]
Object:json 嵌套
Ip 类型
Geo_point:地理位置
TF IDF TENORM
TF: token frequency, basketball 这样的一个分词在 document(待搜索的字段) 中出现的次数
IDF: inverse document frequency,逆文档频率, 代表 basketball 这样的一个分词在整个文档中出现的频率
TFNORM: token frequency normalized 词频归一化
logstash 安装使用
mysql ip 访问
设置允许任意IP访问,执行语句:
mysql> update mysql.user set host = '%' where user = 'root';
mysql> flush privileges;
create database employees;
use employees;
create table DEPT
(
DEPTNO int(2) not null,
DNAME varchar(14),
LOC varchar(13)
);
alter table DEPT add constraint PK_DEPT primary key (DEPTNO);
create table EMP
(
EMPNO int(4) not null,
ENAME varchar(10),
JOB varchar(9),
MGR int(4),
HIREDATE date,
SAL int(7 ),
COMM int(7 ),
DEPTNO int(2)
);
alter table EMP add constraint PK_EMP primary key (EMPNO);
alter table EMP add constraint FK_DEPTNO foreign key (DEPTNO) references DEPT (DEPTNO);
insert into DEPT (DEPTNO, DNAME, LOC) values (10, 'ACCOUNTING', 'NEW YORK');
insert into DEPT (DEPTNO, DNAME, LOC) values (20, 'RESEARCH', 'DALLAS');
insert into DEPT (DEPTNO, DNAME, LOC) values (30, 'SALES', 'CHICAGO');
insert into DEPT (DEPTNO, DNAME, LOC) values (40, 'OPERATIONS', 'BOSTON');
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) values (7369, 'SMITH', 'CLERK', 7902, str_to_date('17-12-1980', '%d-%m-%Y'), 800,null,20);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)values (7499, 'ALLEN', 'SALESMAN', 7698, str_to_date('20-02-1981', '%d-%m-%Y'),1600, 300, 30);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)values (7521, 'WARD', 'SALESMAN', 7698, str_to_date('22-02-1981', '%d-%m-%Y'),1250, 500, 30);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)values (7566, 'JONES', 'MANAGER', 7839, str_to_date('02-04-1981', '%d-%m-%Y'),2975, null, 20);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)values (7654, 'MARTIN', 'SALESMAN', 7698, str_to_date('28-09-1981', '%d-%m-%Y'),1250, 1400, 30);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)values (7698, 'BLAKE', 'MANAGER', 7839, str_to_date('01-05-1981', '%d-%m-%Y'),2850, null, 30);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)values (7782, 'CLARK', 'MANAGER', 7839, str_to_date('09-06-1981', '%d-%m-%Y'),2450, null, 10);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)values (7788, 'SCOTT', 'ANALYST', 7566, str_to_date('19-04-1987', '%d-%m-%Y'),3000,null, 20);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)values (7839, 'KING', 'PRESIDENT', null, str_to_date('17-11-1981', '%d-%m-%Y'),5000,null, 10);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)values (7844, 'TURNER', 'SALESMAN', 7698, str_to_date('08-09-1981', '%d-%m-%Y'),1500, 0, 30);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)values (7876, 'ADAMS', 'CLERK', 7788, str_to_date('23-05-1987', '%d-%m-%Y'),1100,null, 20);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)values (7900, 'JAMES', 'CLERK', 7698, str_to_date('03-12-1981', '%d-%m-%Y'),950,null, 30);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)values (7902, 'FORD', 'ANALYST', 7566, str_to_date('03-12-1981', '%d-%m-%Y'),3000,null, 20);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)values (7934, 'MILLER', 'CLERK', 7782, str_to_date('23-01-1982', '%d-%m-%Y'),1300,null, 10);
create table salgrade (
grade numeric primary key,
losal numeric,
hisal numeric
);
insert into salgrade values (1, 700, 1200);
insert into salgrade values (2, 1201, 1400);
insert into salgrade values (3, 1401, 2000);
insert into salgrade values (4, 2001, 3000);
insert into salgrade values (5, 3001, 9999);
kylin 启动顺序
${HADOOP_HOME}/sbin/start-dfs.sh
${HADOOP_HOME}/sbin/start-yarn.sh
${ZK_HOME}/bin/zkServer.sh start
${HBASE_HOME}/bin/start-hbase.sh
${KYLIN_HOME}/bin/kylin.sh start
内网离线安装 docker 并运行
https://blog.csdn.net/zz_aiytag/article/details/101905750
使用 docker 安装
docker 仓库 pull 镜像:
docker pull apachekylin/apache-kylin-standalone:3.1.0
pull 成功后,执行以下命令启动容器:
docker run -d
-m 8G
-p 7070:7070
-p 8088:8088
-p 50070:50070
-p 8032:8032
-p 8042:8042
-p 16010:16010
apachekylin/apache-kylin-standalone:3.1.0
在容器启动时,会自动启动以下服务:
NameNode, DataNode
ResourceManager, NodeManager
HBase
Kafka
Kylin
并自动运行 $KYLIN_HOME/bin/sample.sh 及在 Kafka 中创建 “kylin_streaming_topic” topic 并持续向该 topic 中发送数据。这是为了让用户启动容器后,就能体验以批和流的方式的方式构建 Cube 并进行查询。
容器启动后,我们可以通过 “docker exec -it <container_id> bash” 命令进入容器内。当然,由于我们已经将容器内指定端口映射到本机端口,我们可以直接在本机浏览器中打开各个服务的页面,如:
Kylin 页面:http://127.0.0.1:7070/kylin/login
HDFS NameNode 页面:http://127.0.0.1:50070
YARN ResourceManager 页面:http://127.0.0.1:8088
HBase 页面:http://127.0.0.1:16010
# 修改为国内镜像源
vim /etc/docker/daemon.json
{
"registry-mirrors":["https://pee6w651.mirror.aliyuncs.com"]
}
# 重启 docker
sudo systemctl daemon-reload
sudo systemctl restart docker
docker save -o xxx.tar /xxx/xxx.jar
内网 load
docker load -i xxx.tar
hue
http://archive.cloudera.com/cdh5/cdh/5/hue-3.9.0-cdh5.7.0.tar.gz
kudu + impala => TiDB
kylin + hudi
druid
clickhouse
influxdb + grafana
zepplin 需要 jdk 1.8_151 +
官网下载
kettle 安装
一、系统7.2
sudo wget ftp://ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home:/matthewdva:/build:/EPEL:/el7/RHEL_7/x86_64/webkitgtk-2.4.9-1.el7.x86_64.rpm
sudo yum install webkitgtk-2.4.9-1.el7.x86_64.rpm
二、系统Centos6.7
./kitchen.sh
#######################################################################
WARNING: no libwebkitgtk-1.0 detected, some features will be unavailable
Consider installing the package with apt-get or yum.
e.g. 'sudo apt-get install libwebkitgtk-1.0-0'
#######################################################################
yum install libwebkitgtk
yum install libwebkitgtk
已加载插件:fastestmirror, security
设置安装进程
Loading mirror speeds from cached hostfile
* base: mirrors.cn99.com
* extras: mirrors.cn99.com
* updates: mirrors.huaweicloud.com
No package libwebkitgtk available.
错误:无须任何处理
yum list *webkit*|grep webkit
yum list *webkit*|grep webkit
libproxy-webkit.x86_64 0.3.0-10.el6 base
pywebkitgtk.x86_64 1.1.6-4.el6 base
webkitgtk.i686 1.4.3-9.el6_6 base
webkitgtk.x86_64 1.4.3-9.el6_6 base
webkitgtk-devel.i686 1.4.3-9.el6_6 base
webkitgtk-devel.x86_64 1.4.3-9.el6_6 base
webkitgtk-doc.x86_64 1.4.3-9.el6_6 base
然后按照提示yum
再执行:./kitchen.sh
没有错误提示即为安装成功
pan 是执行转换的。
1
Pan.bat /file C: est.ktr /logfile c:log.txt /level Basic
kitchen是执行job的。
1
kitchen.bat /file C: est.kjb /logfile c:log.txt /level Basic
安装 otter
springboot项目读取mysql的binlog日志,在去年的时候,我就遇到一个需求,需要把mysql数据库中的数据的增、删、改的数据准实时做数据清洗,也就是ETL工作,同步到公司的数据仓库greenplum中(数据库数据变化的监听从而同步缓存(如Redis)数据等)。现在将整个详细的操作过程记录如下:
(1)、修改mysql数据库的my.cnf配置文件:
[mysqld]
log-bin=mysql-bin #开启binlog
binlog-format=ROW #选择ROW模式
server_id=1 #配置mysql replication需要定义,不能和canal的slaveId重复
(2)、重启mysql,确认mysql正常启动
(3)、查看binlog是否开启:
show variables like "%log_bin%"
确认log_bin----->ON
sql_log_bin----->ON
(4)、查看binlog日志状态
show master status
(5)、刷新binlog日志文件
flush logs #刷新之后会新建立一个binlog日志
(6)、清空日志文件
reset master
(7)、授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
以上每一步都操作完成后,就开启了binlog日志了,数据库方面的准备工作就算是完成了。 本周会更新剩下的操作每一步。
datax
StreamSets Data Collector
NiFi
解决问题
- 安装 hive jdbc 本地jar 包到 仓库
mvn install:install-file -DgroupId=org.apache.hive -DartifactId=hive-jdbc -Dversion=1.1.0-cdh5.7.0 -Dpackaging=jar -Dfile=D:\software\hive-jdbc-1.1.0-cdh5.7.0.jar
beeline -u jdbc:hive2://kylin:10000/default
create table psn (
id int,
name string,
hobbies ARRAY <string>,
address MAP <string, string>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':';
cron 表达式
0 1 * * * /home/testuser/test.sh
每天晚上1点调用/home/testuser/test.sh
*/10 * * * * /home/testuser/test.sh
每10钟调用一次/home/testuser/test.sh
30 21 * * * /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每晚的21:30重启apache。
45 4 1,10,22 * * /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每月1、10、22日的4 : 45重启apache。
10 1 * * 6,0 /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每周六、周日的1 : 10重启apache。
0,30 18-23 * * * /usr/local/etc/rc.d/lighttpd restart
上面的例子表示在每天18 : 00至23 : 00之间每隔30分钟重启apache。
0 23 * * 6 /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每星期六的11 : 00 pm重启apache。
* */1 * * * /usr/local/etc/rc.d/lighttpd restart
每一小时重启apache
* 23-7/1 * * * /usr/local/etc/rc.d/lighttpd restart
晚上11点到早上7点之间,每隔一小时重启apache
0 11 4 * mon-wed /usr/local/etc/rc.d/lighttpd restart
每月的4号与每周一到周三的11点重启apache
0 4 1 jan * /usr/local/etc/rc.d/lighttpd restart
一月一号的4点重启apache
*/30 * * * * /usr/sbin/ntpdate 210.72.145.44
每半小时同步一下时间0 1 * * * /home/testuser/test.sh
每天晚上1点调用/home/testuser/test.sh
*/10 * * * * /home/testuser/test.sh
每10钟调用一次/home/testuser/test.sh
30 21 * * * /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每晚的21:30重启apache。
45 4 1,10,22 * * /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每月1、10、22日的4 : 45重启apache。
10 1 * * 6,0 /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每周六、周日的1 : 10重启apache。
0,30 18-23 * * * /usr/local/etc/rc.d/lighttpd restart
上面的例子表示在每天18 : 00至23 : 00之间每隔30分钟重启apache。
0 23 * * 6 /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每星期六的11 : 00 pm重启apache。
* */1 * * * /usr/local/etc/rc.d/lighttpd restart
每一小时重启apache
* 23-7/1 * * * /usr/local/etc/rc.d/lighttpd restart
晚上11点到早上7点之间,每隔一小时重启apache
0 11 4 * mon-wed /usr/local/etc/rc.d/lighttpd restart
每月的4号与每周一到周三的11点重启apache
0 4 1 jan * /usr/local/etc/rc.d/lighttpd restart
一月一号的4点重启apache
*/30 * * * * /usr/sbin/ntpdate 210.72.145.44
每半小时同步一下时间
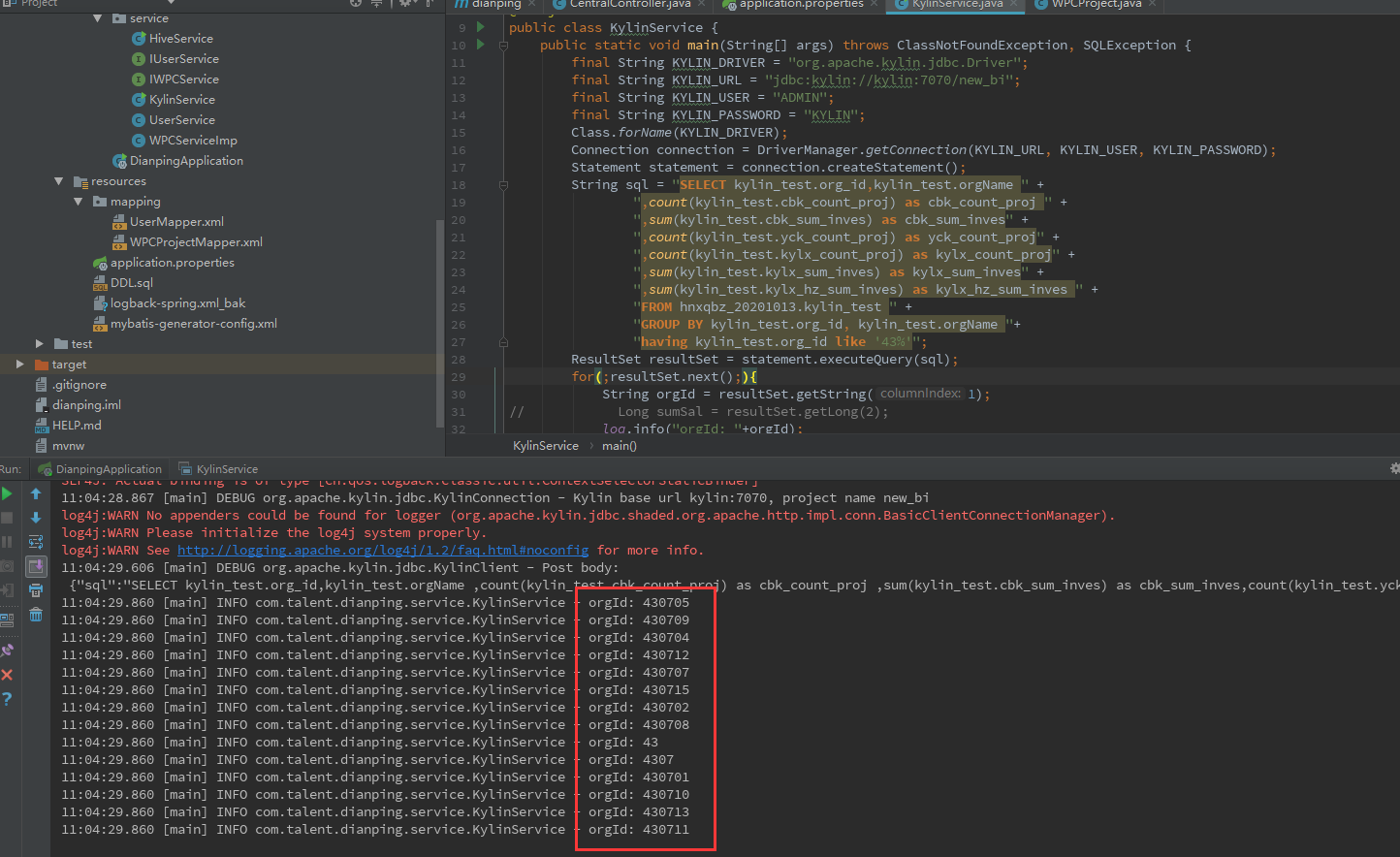
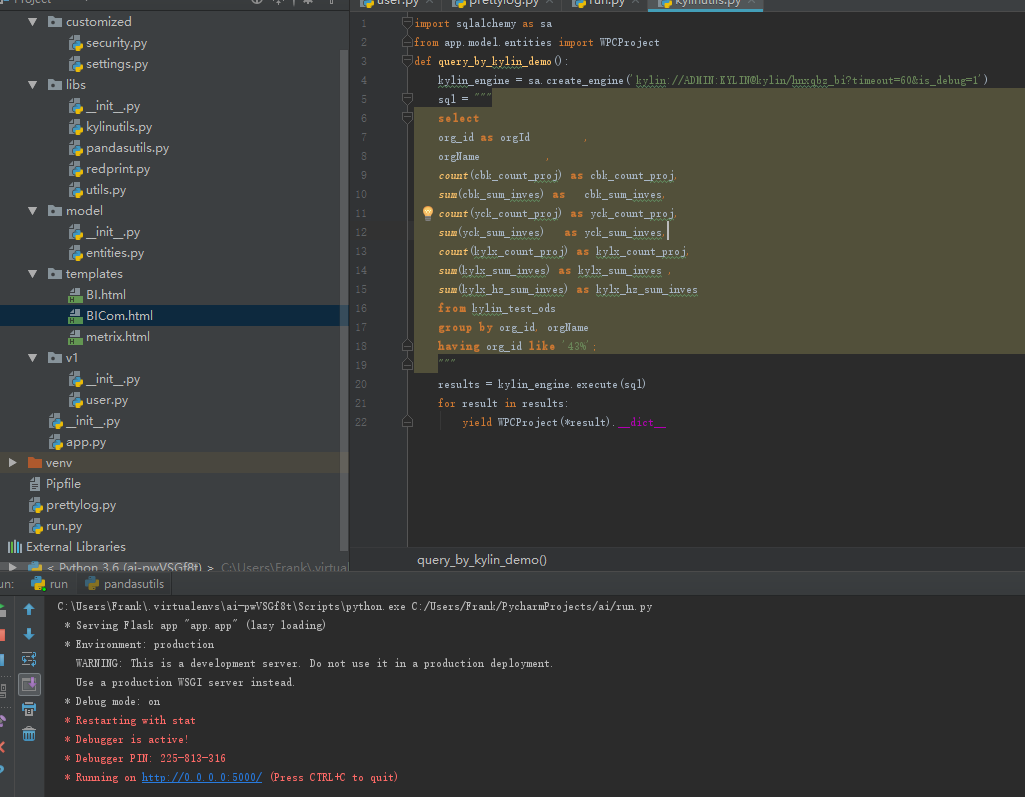

kylin + kafka 流式构建只支持JSON的数据格式。
对接 kafka 步骤, 安装完 kafka,配置好环境变量,进入 $KAFKA_HOME 目录
bin/kafka-server-start.sh config/server.properties &
如果报错缺少 jar 包
cp $KAFKA_HOME/libs/kafka-clients-2.6.0.jar $KYLIN_HOME/lib
然后照着官网来就可以成功了
flume
wget -c http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.7.0.tar.gz
下载 数据库驱动
https://github.com/keedio/flume-ng-sql-source
然后配置 mysql_kafka_kylin.conf 文件
agent.sources = sql-source
agent.sinks = k1
agent.channels = ch
#这个是flume采集mysql的驱动,git地址https://github.com/keedio/flume-ng-sql-source,
#需要自己编译,编译完成后,将flume-ng-sql-source-1.x.x.jar包放到FLUME_HOME/lib下,
#如果是CM下CDH版本的flume,则放到/opt/cloudera/parcels/CDH-xxxx/lib/flume-ng/lib下
agent.sources.sql-source.type= org.keedio.flume.source.SQLSource
# URL to connect to database (currently only mysql is supported)
#?useUnicode=true&characterEncoding=utf-8&useSSL=false参数需要加上
agent.sources.sql-source.hibernate.connection.url=jdbc:mysql://kylin:3306/hnxqbz?useUnicode=true&characterEncoding=utf-8&useSSL=false
# Database connection properties
agent.sources.sql-source.hibernate.connection.user=root
agent.sources.sql-source.hibernate.connection.password =root
agent.sources.sql-source.hibernate.dialect = org.hibernate.dialect.MySQLDialect
#需要将mysql-connector-java-X-bin.jar放到FLUME_HOME/lib下,
#如果是CM下CDH版本的flume,则放到/opt/cloudera/parcels/CDH-xxxx/lib/flume-ng/lib下
#此处直接提供5.1.48版本(理论mysql5.x的都可以用)的
#wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.48.tar.gz
#注意,mysql驱动版本太低会报错:
#org.hibernate.exception.JDBCConnectionException: Error calling DriverManager#getConnection
agent.sources.sql-source.hibernate.driver_class = com.mysql.jdbc.Driver
agent.sources.sql-source.hibernate.connection.autocommit = true
#填写你需要采集的数据表名字
agent.sources.sql-source.table = kylin_test_ods
agent.sources.sql-source.columns.to.select = *
# Query delay, each configured milisecond the query will be sent
agent.sources.sql-source.run.query.delay=10000
# Status file is used to save last readed row
#储存flume的状态数据,因为是增量查找
agent.sources.sql-source.status.file.path = /home/kylin/opt/installed/apache-flume-1.6.0-cdh5.7.0-bin/status
agent.sources.sql-source.status.file.name = sql-source.status
#kafka.sink配置,此处是集群,需要zookeeper和kafka集群的地址已经端口号,不懂的,看后面kafka的配置已经介绍
agent.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.k1.topic = kafka_kylin
agent.sinks.k1.brokerList = kylin:9092
agent.sinks.k1.batchsize = 200
agent.sinks.kafkaSink.requiredAcks=1
agent.sinks.k1.serializer.class = kafka.serializer.StringEncoder
#此处的zookeeper端口根据配置来,我配的是2180,基本应该是2181
agent.sinks.kafkaSink.zookeeperConnect=kylin:2180
agent.channels.ch.type = memory
agent.channels.ch.capacity = 10000
agent.channels.ch.transactionCapacity = 10000
agent.channels.hbaseC.keep-alive = 20
agent.sources.sql-source.channels = ch
agent.sinks.k1.channel = ch
./flume-ng agent -n agent -c ./ -f ../conf/mysql-flume-kafka.conf -Dflume.root.logger=DEBUG,console
# kafka 创建 topic
./kafka-server-start.sh ../config/server.properties
./kafka-topics.sh --create --topic kafka_kylin --partitions 3 --replication-factor 1 --zookeeper kylin:2181
新版本 替代 --zookeeper 参数 --bootstrap-server kylin:9092
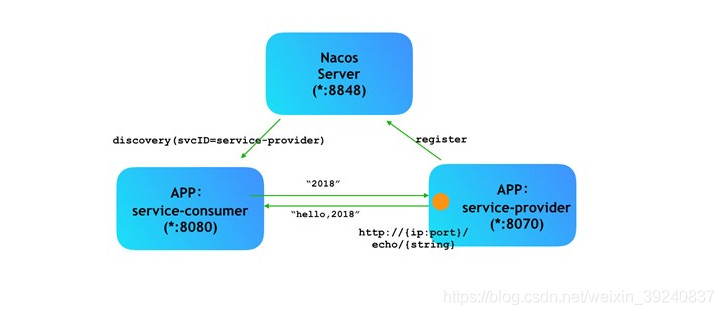
nacos
Nacos是阿里巴巴集团开源的一个易于使用的平台,专为动态服务发现,配置和服务管理而设计。它可以帮助您轻松构建云本机应用程序和微服务平台。
bin/startup.sh -m standalone
# es 下载
wget -c https://mirrors.huaweicloud.com/elasticsearch/7.8.0/elasticsearch-7.8.0-linux-x86_64.tar.gz
# kibana 下载
wget -c https://mirrors.huaweicloud.com/kibana/7.8.0/kibana-7.8.0-linux-x86_64.tar.gz
数据
FormData和Payload是浏览器传输给接口的两种格式,这两种方式浏览器是通过Content-Type来进行区分的(了解Content-Type),如果是 application/x-www-form-urlencoded的话,则为formdata方式,如果是application/json或multipart/form-data的话,则为 request payload
微服务 , 单体服务
注册中心ZooKeeper、Eureka、Consul 、Nacos对比
大数据优化
1. HDFS
1. 设置HDFS多个存储目录
原理:将数据分不到多个磁盘,不会只占用某个磁盘,导致某些磁盘频繁使用,某些磁盘空闲。
优化:dfs.datanode.data.dir 添加dfs不同磁盘存储位置
2. 设置Namenode与Datanode通讯的线程数量 :
原理:过小会导致Datanode延迟或者断开,集群规模大时必须设置,默认为10,通常需要重新配置。
优化:dfs.namenode.handler.count = 20 * log2N
N为集群规模,比如:集群规模为8台时,此参数设置为60
3. 设置编辑日志存储与镜像文件存储不同路径
原理:将两者储路径分开,将达到最低写入延迟
优化:编辑日志存储路径 dfs.namenode.edits.dir
镜像文件存储路径 dfs.namenode.name.dir
2. Yarn
1. Yarn节点可使用的内存 :yarn.nodemanager.resource.memory-mb
原理: 合理设置内存分配,提高资源利用,防止oom
优化:默认是8G,一般会根据节点将节点上,除了其他组件需要的内存,其余内存全部分配给YARN
2. Yarn单个任务可申请的最小/最大物理内存量 :yarn.scheduler.minimum-allocation-mb / maximum
原理:合理设置内存分配,提高资源利用,防止oom
优化:最小默认1G,一般默认
最大默认8G,一般调整为64G或更大,不能超过设置(yarn节点可用内存*节点数)的总和
3. Yarn节点可用虚拟CPU数量 :yarn.nodemanager.resource.cpu-vcores
原理:该节点上Yarn可使用的虚拟CPU个数,充分利用CPU资源,增加计算效率
优化:默认是各节点核心数(CDH),其他默认8个,一般会调整为节点核心75%左右
4. Yarn单个任务可申请的最小/最大虚拟CPU数量 :yarn.scheduler.minimum-allocation-vcores /maximum
原理:合理设置,充分利用CPU资源,增加计算效率
优化:最小默认1个,一般默认
最大默认节点核心数(CDH),其他默认32个,一般为集群总核心数的75%左右
5. Yarn为MR App Master分配的内存 :yarn.app.mapreduce.am.resource.mb
原理:设定MR AppMaster使用的内存,因为AppMaster是由Container开启,所以不能超过Container最小内存
优化:最小默认1G,少于Container最小内存
即:少于yarn.scheduler.minimum-allocation-mb
6. Yarn为MR App Master分配的虚拟CPU数量 :yarn.app.mapreduce.am.resource.cpu-vcores
原理:设定MR AppMaster使用的cpu数量
优化:最小默认1个,根据实际情况调整,可不变动
3. Flume
1. Flume内存参数设置及优化
原理:根据服务器配置适当增大Flume堆内存,提高执行效率和稳定性
优化:调整Flume GC overhead
编辑配置文件
/opt/cloudera/parcels/CDH/lib/flume/conf/flume-env.sh
添加
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
一般设置为4G或更高
-Xmx与-Xms最好设置一致,减少内存抖动带来的性能影响,如果设置不一致容易导致频繁full gc。
2. 设置Flume batchSize大小
原理:Event 数据量达到多大时处理一次
优化:默认为100,例如:Event 1K左右时,调整为500-1000
3. Source选择
原理:Taildir Source支持断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
Exec Source可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
Spooling Directory Source监控目录,不支持断点续传。
优化:防止数据丢失,选择Taildir Source
实时需求,选择Exec Source
3. Channel类型选择
原理:Memory Channel传输数据速度更快,但因为数据保存在JVM的堆内存中,Agent进程挂掉会导致数据丢失,
适用于对数据质量要求不高的需求。
File Channel传输速度相对于Memory慢,但数据安全保障高,Agent进程挂掉也可以从失败中恢复数据。
Kafka Channel省去Flume Sink,提高了效率
优化:数据要求高,选择File Channel
数据要求不严格,但要求速度,选择Memory Channel
Flume连接Kafka,选择Kafka Channel
4. FileChannel优化
优化:1.通过配置dataDirs指向多个路径,每个路径对应不同的硬盘,增大Flume吞吐量
2.checkpointDir和backupCheckpointDir配置在不同硬盘对应的目录中,保证checkpoint如果损坏,
可以使用backupCheckpointDir快速恢复数据
5. HDFS Sink
原理:HDFS存入大量小文件的影响
元数据层面:每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属组,权限,
创建时间等,这些信息都保存在Namenode内存中。所以小文件过多,会占用Namenode服务器大量内存,
影响Namenode性能和使用寿命
计算层面:默认情况下MR会对每个小文件启用一个Map任务计算,非常影响计算性能。同时也影响磁盘寻址时间。
优化:HDFS小文件处理,合理设置以下参数
hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount =0
hdfs.roundValue=10,hdfs.roundUnit= second
设置文件内容达到128M,或者一定时间生成文件,减少小文件生产数量。
6. Fiume小文件合并
优化:调整hdfs.rollInterval 按时间生成文件
hdfs.rollSize 按大小生成
hdfs.rollCount 按数量生成
4. Kafka
如果写入文件过量造成NameNode宕机,调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。
高峰期的时候用Kafka进行缓存,高峰期过去数据同步会自动跟上。
5. Hive
1. 输出合并小文件
SET hive.merge.mapfiles = true; 默认true,在Map任务结束时合并小文件
SET hive.merge.mapredfiles = true; 默认false,在MapReduce任务结束时合并小文件
SET hive.merge.size.per.task = 268435456; 默认256M,每次合并的文件大小
SET hive.merge.smallfiles.avgsize = 16777216;
当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行小文件合并
2. Hive基于MR时的优化
1. 增加Maptask和Reducetask运行内存:
默认1G,开发调到4-6G,实际配置的内存需要根据自己机器内存大小及应用情况进行修改
mapreduce.map.memory.mb=2048
mapreduce.map.java.opts=-Xmx1024M
mapreduce.reduce.memory.mb=3072
mapreduce.reduce.java.opts=-Xmx2560M
2. shuffle优化:环形缓冲区大小默认100M,调整为200M或更大。
默认阈值80%,调整为90-95
原因:减少溢写文件个数
3. reduce优化:拉取个数默认5个,可以设置10个或更大,拉取内存可以设置调大
原因:增加并行度
*. 运行内存不足容易导致的情况:
Hive使用过多内存而被NodeManager kill
即从节点上运行的Container试图使用过多的内存,而被NodeManager kill掉
应调整Yarn和maptask/reduceTask内存参数
Maptask运行内存应大于或者等于Container的最小内存,即
mapreduce.map.memory.mb >= yarn.scheduler.minimum-allocation-mb
3. 尽量使用MapJoin
原理:不指定MapJoin,Hive解析器会将Join操作转换为Common Join,即在Reduce阶段完成Join
优化:指定MapJoin,在Map端进行Join,避免Reduce端Join
4. 行列过滤
原理:select * 会全表扫描,降低效率
分区取数据时,使用外连接,如果将副表过滤条件写到where后面,会先关联全表再过滤
优化:select中指定需要的列,如果有分区尽量使用分区过滤
分区取数据使用外连接时,先对副表过滤,再关联
6. Sqoop
1. Hive和MySQL导出导入存在Null值
原理:Hive的Null底层是以"N"存储,MySQL底层是以Null存储
优化:Sqoop导出时加参数 --input-null-string、--input-null-non-string
导入时加 --null-string、--null-non-string
2. 数据一致性
原理:如果导入过程中Map任务失败,导致只导入部分数据
优化:建立临时表,导入完成再从临时表导入目标表
添加参数 --staging-table、--clear-staging
7. 其他优化
1. 元数据备份
原理:如数据损坏,可能整个集群无法运行
优化:至少要保证每日零点之后备份到其它服务器两个复本
Apache Flink® 1.11.2 是我们最新的稳定版本。
Spark 3.x
https://www.cnblogs.com/xiaodf/p/12841476.html
内网穿透
ngrok 与 frp
mysql 连接
url=jdbc:mysql://ip:port/xxx?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&useSSL=false
driverClassName=com.mysql.cj.jdbc.Driver
windows 后台进程 或者 将 bat 封装为 windows 服务
set ws=WScript.CreateObject("WScript.Shell")
ws.Run "test.cmd",0
将bat文件或exe程序注册成windows服务
命令行使用sc命令.
关于sc命令的详解,请自行查看帮助(sc /?),在此只简单提及如何加入系统服务功能.
加入服务:
sc create ServiceName binPath= 路径 start= auto
(等号后面的空格必须)
删除服务:
sc delete ServiceName
例一:
将Tomcat加入到系统服务中:
sc create Tomcat binPath= F:/apache-tomcat/bin/startup.bat start= auto
将Tomcat服务删除:
sc delete Tomcat
注意:等号和值之间应该有一个空格
例二:
sc create MyService binPath= "cmd.exe /c start c:a.exe" start= auto displayname= "AutoStartOracle Services"
附: sc命令详解——
SC命令详解(一个很有用的command)
作为一个命令行工具,SC.exe可以用来测试你自己的系统,你可以设置一个批处理文件来使用不同的参数调用 SC.exe来控制服务。
一.SC使用这样的语法:
1. SC [Servername] command Servicename [Optionname= Optionvalues]
2. SC [command]
这里使用第一种语法使用SC,使用第二种语法显示帮助。
下面介绍各种参数。
Servername
可选择:可以使用双斜线,如\myserver,也可以是\192.168.1.223来操作远程计算机。如果在本地计算机上操作
就不用添加任何参数。
Command
下面列出SC可以使用的命令。
config----改变一个服务的配置。(长久的)
continue--对一个服务送出一个继续控制的要求。
control----对一个服务送出一个控制。
create----创建一个服务。(增加到注册表中)
delete----删除一个服务。(从注册表中删除)
EnumDepend--列举服务的从属关系。
GetDisplayName--获得一个服务的显示名称。
GetKeyName--获得一个服务的服务键名。
interrogate--对一个服务送出一个询问控制要求。
pause----对一个服务送出一个暂停控制要求。
qc----询问一个服务的配置。
query----询问一个服务的状态,也可以列举服务的状态类型。
start----启动一个服务。
stop----对一个服务送出一个停止的要求。
Servicename
在注册表中为service key制定的名称。注意这个名称是不同于显示名称的(这个名称可以用net start和服务控
制面板看到),而SC是使用服务键名来鉴别服务的。
Optionname
这个optionname和optionvalues参数允许你指定操作命令参数的名称和数值。注意,这一点很重要在操作名称和等
号之间是没有空格的。一开始我不知道,结果………………,比如,start= optionvalues,这个很重要。
optionvalues可以是0,1,或者是更多的操作参数名称和数值对。
如果你想要看每个命令的可以用的optionvalues,你可以使用sc command这样的格式。这会为你提供详细的帮助。
Optionvalues
为optionname的参数的名称指定它的数值。有效数值范围常常限制于哪一个参数的optionname。如果要列表请用
sc command来询问每个命令。
Comments
很多的命令需要管理员权限,所以我想说,在你操作这些东西的时候最好是管理员。呵呵!
当你键入SC而不带任何参数时,SC.exe会显示帮助信息和可用的命令。当你键入SC紧跟着命令名称时,你可以得
到一个有关这个命令的详细列表。比如,键入sc create可以得到和create有关的列表。
但是除了一个命令,sc query,这会导出该系统中当前正在运行的所有服务和驱动程序的状态。
当你使用start命令时,你可以传递一些参数(arguments)给服务的主函数,但是不是给服务进程的主函数。
二.SC create
这个命令可以在注册表和服务控制管理数据库建立一个入口。
语法1
sc [servername] create Servicename [Optionname= Optionvalues]
这里的servername,servicename,optionname,optionvalues和上面的一样,这里就不多说了。这里我们详细说
明一下optionname和optionvalues。
Optionname--Optionvalues
描述
type=----own, share, interact, kernel, filesys
关于建立服务的类型,选项值包括驱动程序使用的类型,默认是share。
start=----boot, sys tem, auto, demand, disabled
关于启动服务的类型,选项值包括驱动程序使用的类型,默认是demand(手动)。
error=----normal, severe, critical, ignore
当服务在导入失败错误的严重性,默认是normal。
binPath=--(string)
服务二进制文件的路径名,这里没有默认值,这个字符串是必须设置的。
group=----(string)
这个服务属于的组,这个组的列表保存在注册表中的ServiceGroupOrder下。默认是nothing。
tag=----(string)
如果这个字符串被设置为yes,sc可以从CreateService call中得到一个tagId。然而,SC并不显示这个标签,所
以使用这个没有多少意义。默认是nothing
depend=----(space separated string)有空格的字符串。
在这个服务启动前必须启动的服务的名称或者是组。
obj=----(string)
账号运行使用的名称,也可以说是登陆身份。默认是localsys tem
Displayname=--(string)
一个为在用户界面程序中鉴别各个服务使用的字符串。
password=--(string)
一个密码,如果一个不同于localsystem的账号使用时需要使用这个。
Optionvalues
Optionname参数名称的数值列表。参考optionname。当我们输入一个字符串时,如果输入一个空的引用这意味着
一个空的字符串将被导入。
Comments
The SC CREATE command perFORMs the operations of the CreateService API function.
这个sc create命令执行CreateService API函数的操作。详细请见CreateService。
例子1
下面这个例子在计算机上建立叫“mirror”的服务建立的一个注册表登记,是自动运行服务,从属于TDI组和NetBios服务。
C:WINDOWSsystem32>sc create mirror binPath= "D:Ftp新建文件夹mirror.exe" type= own start= auto
[SC] CreateService SUCCESS
重启后生效
例子2 删除Mirror服务
C:WINDOWSsystem32>sc delete mirror binPath= "D:Ftp新建文件夹mirror.exe" type= own start= auto
[SC] DeleteService SUCCESS
三. SC QC
这个SC QC“询问配置”命令可以列出一个服务的配置信息和QUERY_SERVICE_CONFIG结构。
语法1
sc [Servername] qc Servicename [Buffersize]
Parameters
servername和servicename前面已经介绍过了,这里不再多说。
Buffersize,可选择的,列出缓冲区的尺寸。
Comments
SC QC命令显示了QUERY_SERVICE_CONFIG结构的内容。
以下是QUERY_SERVICE_CONFIG相应的区域。
TYPE------dwServiceType
START_TYPE----dwStartType
ERROR_CONTROL----dwErrorControl
BINARY_PATH_NAME--lpBinaryPathName
LOAD_ORDER_GROUP--lpLoadOrderGroup
TAG------dwTagId
DISPLAY_NAME----lpDisplayName
DEPENDENCIES----lpDependencies
SERVICE_START_NAME--lpServiceStartName
例1
下面这个例子询问了在上面例子中建立的“mirror”服务的配置:
sc qc
sc显示下面的信息:
SERVICE_NAME: mirror
TYPE : 10 WIN32_OWN_PROCESS
START_TYPE : 2 AUTO_START
ERROR_CONTROL : 1 NORMAL
BINARY_PATH_NAME : D:Ftp
LOAD_ORDER_GROUP :
TAG : 0
DISPLAY_NAME : mirror
DEPENDENCIES :
SERVICE_START_NAME : LocalSystem
mirror有能力和其他的服务共享一个进程。这个服务 不依靠与其它的的服务,而且运行在lcoalsystem的安全上下关系中。这些都是调用QueryServiceStatus基本的返回,如果还需要更多的细节届时,可以看看API函数文件。 mirror
四.SC QUERY
SC QUERY命令可以获得服务的信息。
语法:
sc [Servername] query { Servicename | ptionname= Optionvalues... }
参数:
servername, servicename, optionname, optionvalues不在解释。只谈一下这个命令提供的数值。
Optionname--Optionvalues
Description
type=----driver, service, all
列举服务的类型,默认是service
state=----active, inactive, all
列举服务的状态,默认是active
bufsize=--(numeric values)
列举缓冲区的尺寸,默认是1024 bytes
ri=----(numeric values)
但开始列举时,恢复指针的数字,默认是0
Optionvalues
同上。
Comments
SC QUERY命令可以显示SERVICE_STATUS结构的内容。
下面是SERVICE_STATUS结构相应的信息:
TYPE------dwServiceType
STATE------dwCurrentState, dwControlsAccepted
WIN32_EXIT_CODE----dwWin32ExitCode
SERVICE_EXIT_CODE--dwServiceSpecificExitCode
CHECKPOINT----dwCheckPoint
WAIT_HINT----dwWaitHint
在启动计算机后,使用SC QUERY命令会告诉你是否,或者不是一个启动服务的尝试。如果这个服务成功启动,WIN32_EXIT_CODE区间会将会包含一个0,当尝试不成功时,当它意识到这个服务不能够启动时,这个区间也会提供一个退出码给服务。
例子
查询“mirror'服务状态,键入:
sc query mirror
显示一下信息:
SERVICE_NAME: mirror
TYPE : 10 WIN32_OWN_PROCESS
STATE : 1 STOPPED
(NOT_STOPPABLE,NOT_PAUSABLE,IGNORES_SHUTDOWN
WIN32_EXIT_CODE : 0 (0x0)
SERVICE_EXIT_CODE : 0 (0x0)
CHECKPOINT : 0x0
WAIT_HINT : 0x0
注意,这里存在一个给这个服务的退出码,即使这个服务部不在运行,键入net helpmsg 1077,将会得到对1077错误信息的说明:
上次启动之后,仍未尝试引导服务。
所以,这里我想说一句,希望大家可以活用net helpmsg,这会对你的学习有很大的帮助。
下面在对SC query的命令在说明一下:
列举活动服务和驱动程序状态,使用以下命令:
sc query
显示messenger服务,使用以下命令:
sc query messenger
只列举活动的驱动程序,使用以下命令:
sc query type= driver
列举Win32服务,使用以下命令:
sc query type= service
列举所有的服务和驱动程序,使用以下命令:
sc query state= all
用50 byte的缓冲区来进行列举,使用以下命令:
sc query bufsize= 50
在恢复列举时使用index=14,使用以下命令:
sc query ri=14
列举所有的交互式服务,使用以下命令:
sc query type= service type= interact
五、sc命令启动已经禁用的服务,例如:启动telnet服务
sc config tlntsvr start= auto
net start tlntsvr
开源堡垒机
https://www.jumpserver.org/
https://github.com/jumpserver/jumpserver
ruoyi
Bootstrap 3.3.7前端框架
mdlib
https://gitee.com/tinylab/markdown-lab/blob/master/README.md