两种运行python程序的方式
1:交互式
优点:输入内容立刻就有对应的返回结果
缺点:无法永久保存数据
2:命令行(文件的形式)
优点:可以永久保存数据
缺点:暂时来看运行该文件优点麻烦
运行一个py文件需要走的步骤
1.将python解释器代码从硬盘读到内存(就等价于双击了word图标)
2.将你写好的py文件有硬盘读到内存(就等价于你双击了一个word文档)
3.解释器解释读取py文件中的内容,解释成计算机能够识别的语句
(如果是一个普通文本文件,仅仅只会将文件内容展示到屏幕上给用户查看,不会检测翻译文件内容)
ps:python解释器于普通的文本编辑器前面两步是一毛一样的,仅仅第三步不一样(一个是解释语法,一个是文本展示)
变量:
量:衡量/记录事物的状态/特征
变:状态/特征是可以变化的
变量的三要素
1.id():返回的是一串数字,这一串数字你可以直接理解为内存地址
2.type():返回的是该变量对应的数据的类型
3.value:该变量指向的内存当中数据的值
变量名的命名规则:
1:只能用字母数字下划线
2:不能以数字开头
3:不能用关键字命名变量名
关键字不能声明为变量名
""" ['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del',
'elif', 'else', 'except',
'exec', 'finally', 'for', 'from', 'global', 'if', 'import',
'in', 'is', 'lambda', 'not', 'or', 'pass', 'print',
'raise', 'return', 'try', 'while', 'with', 'yield'] """
#命名尽量一看就知其意有具体的含义,尽量别用拼音或中文#
命名规则流派:驼峰体和下划线(JS前端推荐:userName python强烈使用:user_Name_out)
常量:不可变更的量 Eg:pai=3.1415926 python里默认纯大写的变量名为常量改写需慎重
“==”和“is“的区别
#1 等号比较的是value, #2 is比较的是id id相等value一定相等,但value相等id不一定相等 #强调: #1. id相同,意味着type和value必定相同 #2. value相同type肯定相同,但id可能不同,如下
垃圾回收机制
1.引用计数:内存中的数据如果没有任何的变量名与其有绑定关系,那么会被自动回收
2.标记清除:当内存快要被某个应用程序占满的时候,会自动触发
3.分代回收:根据值得存活时间的不同,划为不同的等级,等级越高垃圾回收机制扫描的频率越低
常量(不可变的量)
python里面压根没有常量
通常将全大写的变量名看作常量(python程序员约定俗成的)
垃圾回收机制
我们定义变量会申请内存空间来存放变量的值,而内存的容量是有限的,当一个变量值没有用了(称为垃圾),就应该将其占用的内存给回收掉。变量名是访问到变量的唯一方式,所以当一个变量值没有任何关联的变量名时,我们就无法访问到该变量了,该变量就是一个垃圾,会被python解释的垃圾回收机制自动回收。
一、什么是垃圾回收机制
垃圾回收机制(简称GC)是python解释器自带的一种机制,专门用来回收不可用的变量值所占用的内存空间
二、为什么要有垃圾回收机制
程序运行过程中会申请大量的内存空间,而对于一些无用的内存空间,如果不及时清理的话,会导致内存使用完(内存溢出),导致程序崩溃,因此,内存管理是一件重要且繁杂的事情,而python解释器自带的垃圾回收机制把程序员从繁杂的内存管理中解放出来。
三、垃圾回收机制原理分析
python的GC模块主要采用了‘引用计数’来跟踪和回收垃圾。在引用计数的基础上,还可以通过‘标记-清除’来解决容器对象可能产生的循环引用的问题,并且通过‘分代回收’来以空间换取时间的方式进一步提高垃圾回收的效率。
1,引用计数
引用计数就是:变量值被变量名关联的次数
如:
引用计数增加
x=10(此时,变量值10的引用次数为1)
y=x(此时,把x的内存地址给了y,此时,变量值10 的引用计数为2)
引用计数减少
x=3(此时,x和10解除关系,与3建立关系,变量值10的引用计数为1)
del y(del是解除变量名y与变量值10之间的关系,变量值10的引用计数为0),变量值10的引用计数为0,其占用的内存空间就会被回收
2,循环引用
引用计数机制执行效率问题:变量值被关联次数的增加或减少,都会引发引用计数机制的执行,这明显存在效率问题,这就是引用计数的一个软肋,但引用计数还存在一个致命弱点,即循环引用(也称交叉引用)。
现在列表1和列表2都没被其他变量名关联,但引用计数不为0,所以不会被回收,这就是循环引用的危害,为解决这问题,python引进了‘标记-清除’,‘分代回收’。
3,标记-清除
容器对象(list,set,dict,class,instance)都可以包含其他对象的引用,所以都可能产生循环引用。在了解‘标记-清除’之前,先得知道一个知识点:内存中有两块区域:堆区与栈区,在定义变量时,变量名放在栈区,变量值放在堆区,内存管理是对堆区的管理。
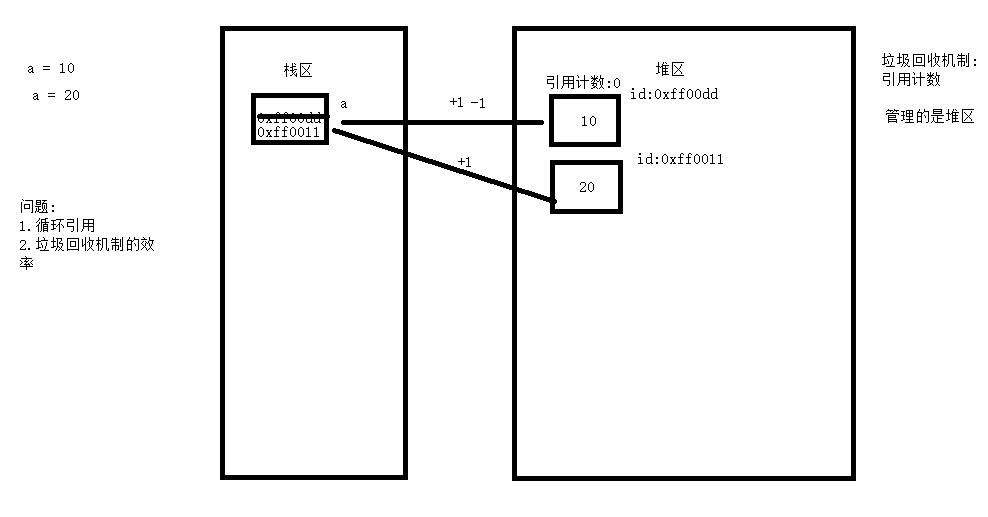
当有效内存空间被耗尽的时候,就会停止整个程序,然后进行两项工作,第一是标记,第二是清除
标记:遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots对象可以直接访问或间接访问的对象标记为存活对象。
清除:遍历堆区中所有的对象,将没有标记的对象全部清除
4,分代回收
基于引用计数的回收机制,每次回收内存,需要把所有的对象的引用计数都遍历一遍,这是非常耗费时间的,于是引入分代回收提高回收效率,采用‘空间换取时间的策略’。
分代:在多次扫描的情况下,都没有被回收的变量值,GC机制会认为,该变量值的级别会增高,对其扫描的频率会降低。
分代指的是根据存活时间来划分变量值的等级(也就是不同的代)
新定义的变量值,会放在新生代中,假设每隔1分钟扫描一次,如果发现变量值依然存活,那该变量值的等级会提高,当权重大于3(假设为3),会放到青春代中,每隔5分钟扫描一次,继续存活下去,权重继续增高,当权重大于10(假设为10),会被放到老年代中,次时每隔10分钟扫描一次,以此类推。等级越高,被垃圾回收扫描的频率越低。
回收:依然是引用计数作为回收依据