之前已经在CentOS 6.7上安装部署Hadoop 2.7.2(http://blog.csdn.net/noob_f/article/details/53366756),并正常启动Hadoop集群。
master
安装Scala
[root@master ~]# wget http://downloads.lightbend.com/scala/2.10.6/scala-2.10.6.tgz
[root@master ~]# tar -zxvf scala-2.10.6.tgz
[root@master ~]# mv scala-2.10.6 /usr/local/
Scala环境变量
[root@master ~]# vi /etc/profile.d/scala.sh添加
export SCALA_HOME=/usr/local/scala-2.10.6
export PATH=$PATH:$SCALA_HOME/bin
保存退出
[root@master ~]# source /etc/profile.d/scala.sh
[root@master ~]# scala -version
Scala code runner version 2.10.6 -- Copyright 2002-2013, LAMP/EPFL
安装Spark
[root@master ~]# wget http://archive.apache.org/dist/spark/spark-1.5.2/spark-1.5.2-bin-hadoop2.6.tgz
[root@master ~]# tar -zxvf spark-1.5.2-bin-hadoop2.6.tgz
[root@master ~]# mv spark-1.5.2-bin-hadoop2.6 /usr/local/
Spark环境变量
[root@master ~]# vi /etc/profile.d/spark.sh添加
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR==$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/usr/local/spark-1.5.2-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin
保存退出
[root@master ~]# source /etc/profile.d/spark.sh[root@master ~]# cp /usr/local/spark-1.5.2-bin-hadoop2.6/conf/spark-env.sh.template /usr/local/spark-1.5.2-bin-hadoop2.6/conf/spark-env.sh
[root@master ~]# vi /usr/local/spark-1.5.2-bin-hadoop2.6/conf/spark-env.sh
添加
export JAVA_HOME=/usr/local/jdk1.7.0_79
export SCALA_HOME=/usr/local/scala-2.10.6
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
保存退出
[root@master ~]# cp /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slaves.template /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slaves
[root@master ~]# vi /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slaves
删除localhost,将内容修改为
master
slave
保存退出
验证Spark安装
[root@master spark-1.5.2-bin-hadoop2.6]# cd /usr/local/spark-1.5.2-bin-hadoop2.6/
[root@master spark-1.5.2-bin-hadoop2.6]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster lib/spark-examples*.jar 10
16/11/26 03:35:07 INFO yarn.Client: Application report for application_1480118541212_0002 (state: FINISHED)
16/11/26 03:35:07 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.229.131
ApplicationMaster RPC port: 0
queue: default
start time: 1480160059605
final status: SUCCEEDED
tracking URL: http://master:8088/proxy/application_1480118541212_0002/
user: root
16/11/26 03:35:07 INFO util.ShutdownHookManager: Shutdown hook called
16/11/26 03:35:07 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-e29afacf-58e9-4805-a59b-6fb5223ec872
[root@master spark-1.5.2-bin-hadoop2.6]# ssh slave
Last login: Sat Nov 26 02:30:33 2016 from 192.168.229.1
[root@slave ~]# cd /usr/local/hadoop-2.7.2/logs/userlogs/application_1480118541212_0002/
[root@slave application_1480118541212_0002]# cat container_1480118541212_0002_01_000001/stdout
Pi is roughly 3.142008
Spark安装正常
浏览器中访问http://master:8088/proxy/application_1480118541212_0002,可看到Spark作业界面。
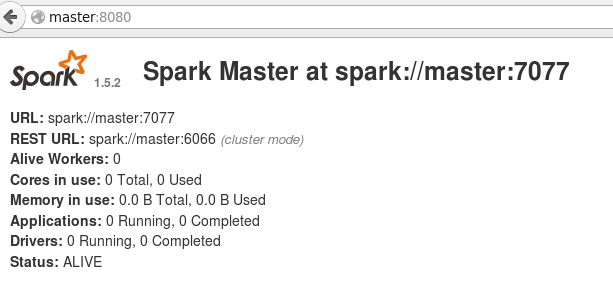
[root@master spark-1.5.2-bin-hadoop2.6]# vi sbin/start-master.sh发现
SPARK_MASTER_WEBUI_PORT=8080[root@master spark-1.5.2-bin-hadoop2.6]# sbin/start-master.sh浏览器可访问master:8080,查看Spark Master
[root@master ~]# ls /usr/local/spark-1.5.2-bin-hadoop2.6/bin/
beeline pyspark.cmd spark-class.cmd spark-shell.cmd
beeline.cmd run-example sparkR spark-sql
load-spark-env.cmd run-example2.cmd sparkR2.cmd spark-submit
load-spark-env.sh run-example.cmd sparkR.cmd spark-submit2.cmd
pyspark spark-class spark-shell spark-submit.cmd
pyspark2.cmd spark-class2.cmd spark-shell2.cmd
[root@master ~]# /usr/local/spark-1.5.2-bin-hadoop2.6/bin/spark-shell
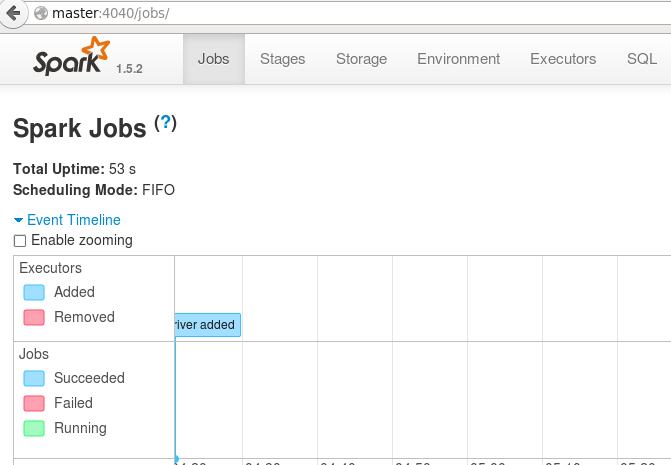
浏览器中访问master:4040
scala> exit
[root@master ~]#