看了之前几款采集器,发现了一些共同点
采集器一般由3个部分组成 主程序,采集规则,入库模块
主程序负责解析和采集规则
流程如下
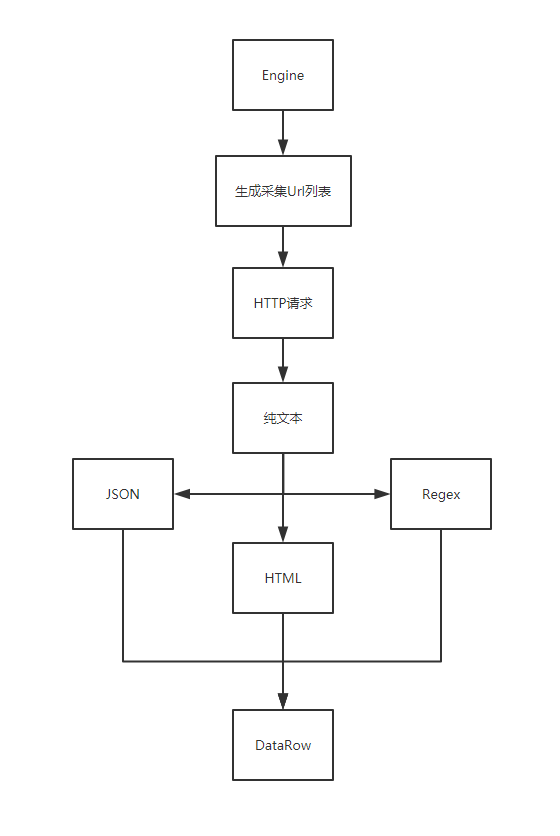
采集规则包含了需要采集网站的url,内容提取和处理,一般由正则表达式,xpath等组成
参数设置规则:url=http://xxx.html?page={$0}
http请求设置:编码=utf-8 Cookie=xxx
内容选择规则:json选择规则,regex匹配规则,xpath选择规则
数据处理:html解码,url解码,htm标签清除
入库模块将采集到的数据保存到数据库或发布到网站
数据库导出:sqlserver,mysql,sqlite,mongodb 发布到网站程序:dedecms,discuz,phpcms