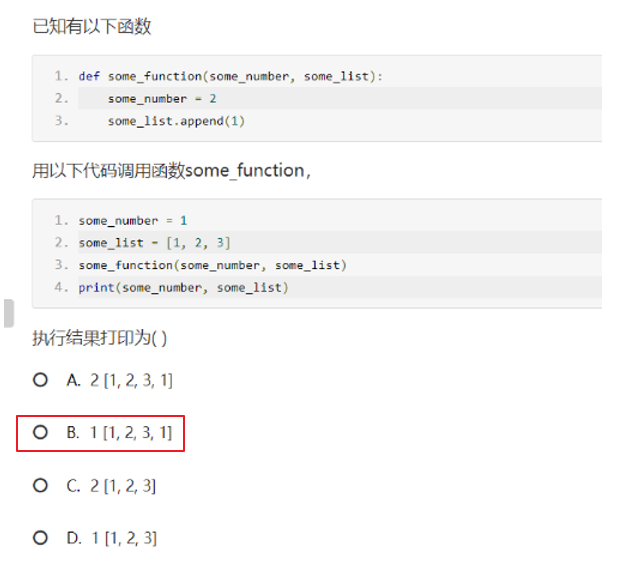
1.函数的默认参数只初始化一次
函数的默认值只会创建一次,之后不会再变了,使用对象(列表、字典、实例)作为默认值,会导致函数混乱,如下面的函数在后续调用中积累传递给它的参数
def f(a, L=[]):
L.append(a)
return L
if __name__ == '__main__':
print(f(1))
print(f(1))
print(f(1))
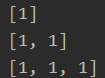
可以使用下面的办法进行规避:
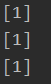
def f1(a, t=None):
t = t or []
t.append(a)
return t
2. is与==
- == 是比较两个对象的内容是否相等,即两个对象的“值“”是否相等,不管两者在内存中的引用地址是否一样。
- is 比较的是两个实例对象是不是完全相同,它们是不是同一个对象,占用的内存地址是否相同。即is比较两个条件:1.内容相同。2.内存中地址相同。
- 使用is注意python对于小整数使用对象池存储问题,和字符串的intern机制存储问题,并且命令行运行和Pycharm运行有点不一样,因为Pycharm对解释器进行了优化。
- python中对于None值的比较:使用is,即,要用is或is not none: she is none; she is not None;
-
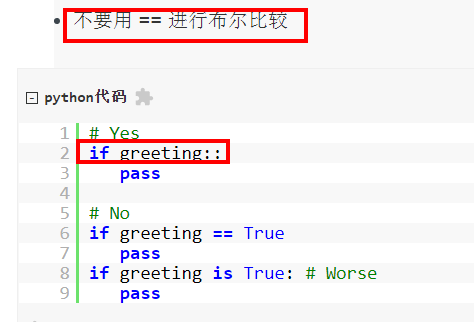
布尔值:不要用==比较布尔值,
-
Python中,万物皆对象!万物皆对象!万物皆对象!(很重要,重复3遍)
每个对象包含3个属性,id,type,value
id就是对象地址,可以通过内置函数id()查看对象引用的地址。
type就是对象类型,可以通过内置函数type()查看对象的类型。
value就是对象的值。
# is和==的区别
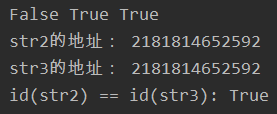
str1 = 'aaaa'
str2 = 'bbbbb'
str3 = 'bbbbb'
str4 = str3
print(str1 == str2, str2 == str3, str3 == str4)
print("str2的地址:", id(str2), "
str3的地址:", id(str3), "
id(str2) == id(str3):", id(str2) == id(str3))
# 引用地址不一样,但是只要值一样即可==成立。
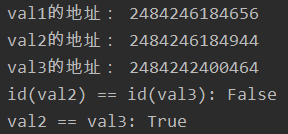
val1 = 2000
val2 = 2001
val3 = val1 + 1
print("val1的地址:", id(val1), "
val2的地址:", id(val2), "
val3的地址:", id(val3),
"
id(val2) == id(val3):", id(val2) == id(val3), "
val2 == val3:", val2 == val3)
# 3.对于类的实例比较
class Student(object):
def __init__(self,name,age):
self.name = name
self.age = age
def run(self):
print("can run")
stu1 = Student("tom",19)
stu2 = Student("tom",19)
stu3 = stu2
print(id(stu1)==id(stu2),stu1 == stu2) #False False
#注意这里stu1和stu2的值是不等的,虽然初始化创建对象格式一样。
print(id(stu2)==id(stu3),stu2 == stu3) # True True
关于is
1.is成立的前提要是内容相同,内存中地址相同 st1 ='aaaaa' st2 = 'bbbbb' st3 = 'bbbbb' st4 = st3 print(st1 is st2, st2 is st3,st3 is st4)#False True True print(id(st1),id(st2),id(st3),id(st4))


以上两题涉及到对象,用is
3.类型判断用isinstance,不用type
type()不会认为子类是一种父类类型。isinstance()会认为子类是一种父类类型。
class Foo(object):
pass
class Bar(Foo):
pass
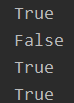
if __name__ == '__main__':
print(type(Foo()) == Foo)
print(type(Bar()) == Foo)
print(isinstance(Foo(), Foo))
print(isinstance(Bar(), Foo))
4.对子类继承的变量,要显式定义和赋初值
class A(object):
x = 1
class B(A):
pass
class C(A):
pass
if __name__ == '__main__':
B.x = 2
print(A.x, B.x, C.x)



如果希望类C中的x不引用自A类,可以在C类中重新定义属性x,这样C类就不会引用A类的属性x了,它们之间值的变化就不会相互影响了

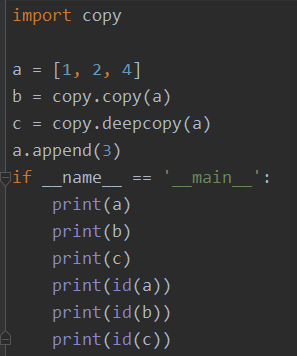
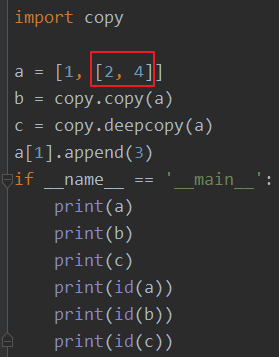
5. 赋值、浅拷贝和深拷贝
- =: 跟原对象完全相同,原对象改了啥,新对象也改了啥;
- deepcopy: 原对象改了啥,新对象都不变
- copy: 列表的列表会被修改

copy浅拷贝:拷贝一个对象,但是对象的属性还是引用原来的,对于可变类型,比如列表和字典,只是复制其引用。基于引用所作的改变会影响到被引用对象。只要原来的对象改变,被浅拷贝的就会改变。
deepcopy深拷贝:创建一个新的容器对象,包含原有对象元素(引用)全新拷贝的引用。外围和内部元素都是拷贝对象本身,而不是引用。原来的对象改变了,不会影响到新的深拷贝的。


注意:对于数字,字符串和其他原子类型等,没有被拷贝的说法。如果对其重新赋值,也只是新创建一个对象,替换掉旧的而已。使用copy和deepcopy时,需要了解其使用场景,避免错误。
运行结果:
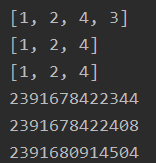
运行结果:
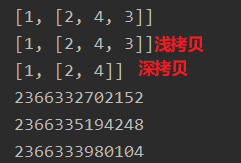
6. 字符串处理,字符集
7. 正则表达式的使用
7.1 re.match()
尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。


7.2 re.search()
扫描整个字符串并返回第一个成功的匹配。


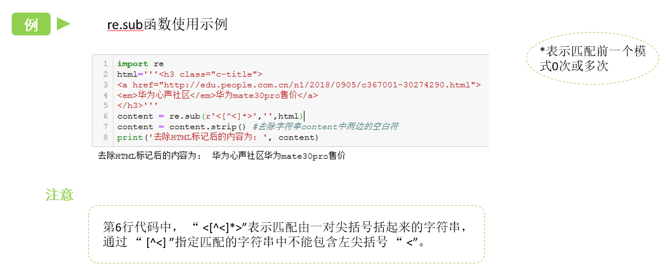
7.3 re.sub()
替换字符串中的匹配项。
re.sub(pattern, repl, string, count=0, flags=0)
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 编译时用的匹配模式,数字形式。

7.4 re.group()
re.group(0)与re.group()相同返回全部字符串,1以后才是re.groups()中的各个组。
import re
m = re.match('(www)-(d?)', 'abc-123')
sentence = 'we are humans'
matched = re.match(r'(.*) (.*) (.*)', sentence)
if __name__ == '__main__':
print(m.group()) # abc-1
print(m.groups()) # ('abc', '1')
print(m.group(0)) # abc-1
print(m.group(1)) # abc
print(m.group(2)) # 1
print(matched.group()) # we are humans
print(matched.groups()) # ('we', 'are', 'humans')
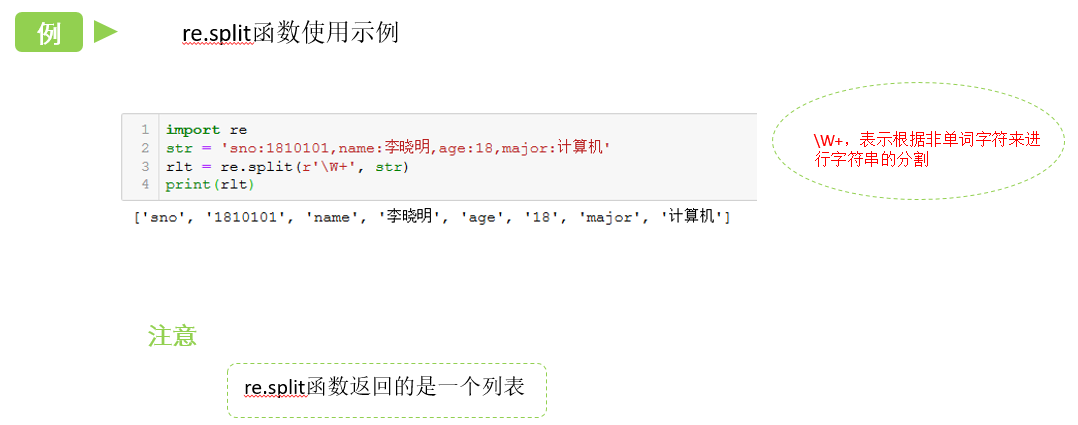
7.5 re.split()
split 方法按照能够匹配的子串将字符串分割后返回列表。Python自带的split函数只能指定一个分割符,需要使用多个分割符时,可以使用re.split()。

7.6 re.findall()
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。注意: match 和 search 是匹配一次 findall 匹配所有。


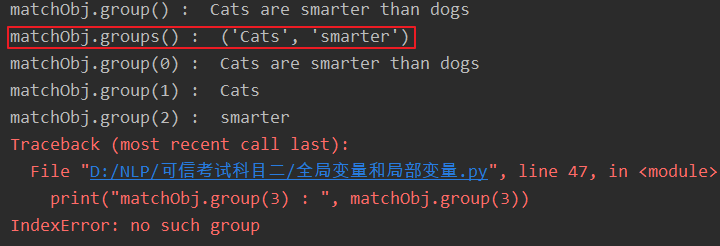
import re
line = "Cats are smarter than dogs"
# .* 表示任意匹配除换行符( 、 )之外的任何单个或多个字符
matchObj = re.match(r'(.*) are (.*?) .*', line, re.M | re.I)
if matchObj:
print("matchObj.group() : ", matchObj.group())
print("matchObj.groups() : ", matchObj.groups())
print("matchObj.group(0) : ", matchObj.group(0))
print("matchObj.group(1) : ", matchObj.group(1))
print("matchObj.group(2) : ", matchObj.group(2))
print("matchObj.group(3) : ", matchObj.group(3))
else:
print("No match!!")