首先,什么是爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。(百度)
爬虫就是在互联网中爬行的蜘蛛,它会遇到资源、选择资源、抓取资源,这个过程就是爬虫的全部。至于如何找到前进的路,如何选择路线,如何自我保护,如何穿过障碍,这些以后再慢慢说。现在我们先完成最简单的三步走,
- 访问——通过网站域名获取HTML数据;
- 分析——根据目标信息解析数据;
- 存储——存储目标信息。
我们来看看这个简单的功能通过Python是如何实现的:


import urllib.request response = urllib.request.urlopen('https://www.python.org') print(response.read())
你没有看错,这段代码只有三行,它的运行效果如下:
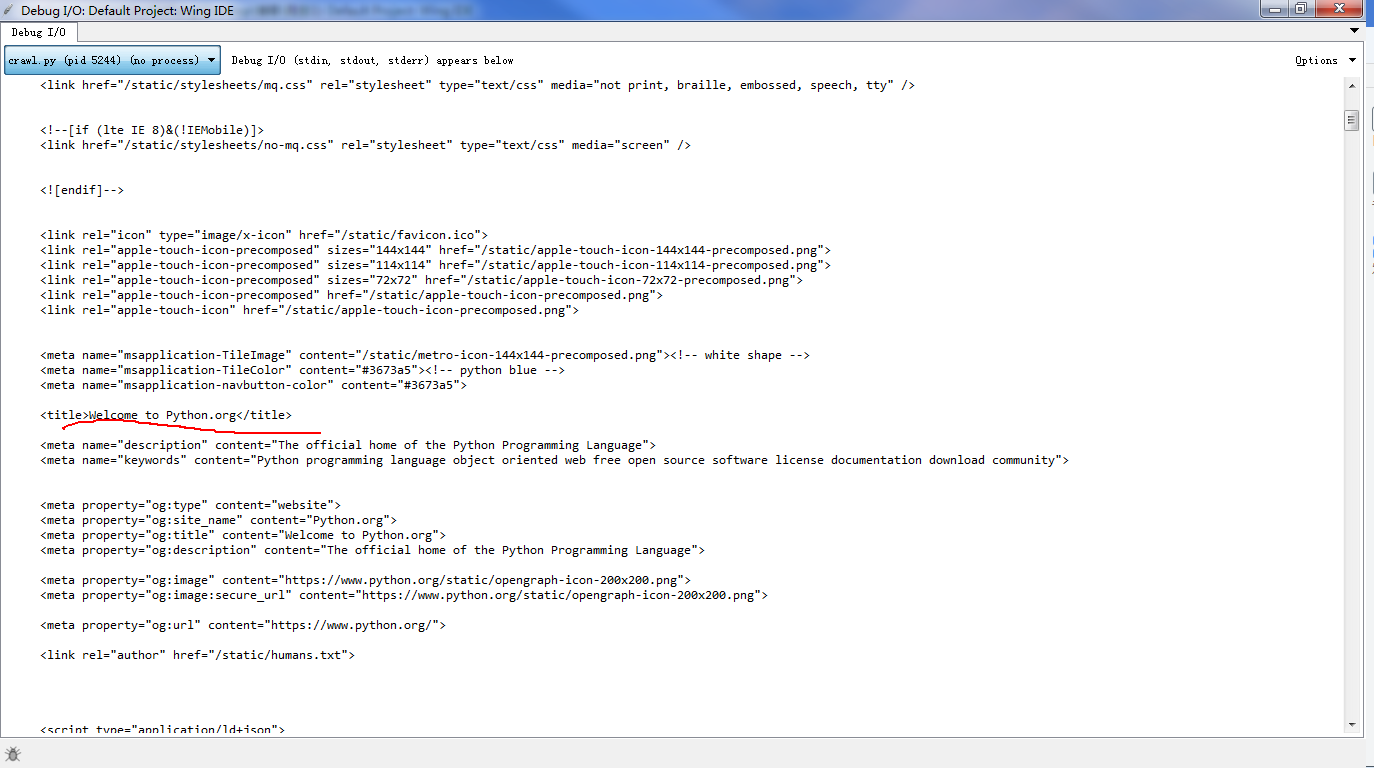
这段代码所做的是访问python的官网,获得网站页面的HTML数据,然后输出在控制台。可以看到,我们只是通过很简单的三行代码就得到了一个网页的页面内容。这个页面就是我们的爬虫所要搜寻的资源文件。利用python,很简单地我们就完成了这一步。
import urllib.request from bs4 import BeautifulSoup response = urllib.request.urlopen('https://www.zhihu.com') bsObj = BeautifulSoup(response.read()) print(bsObj.h1)
这段程序的输出结果是
也就是知乎网站的标题,我们可以用同样的方法访问网页中的任一结构。
import urllib.request from bs4 import BeautifulSoup response = urllib.request.urlopen('https://www.python.org') with open('test.txt','w+') as f: l = response.read().decode('utf-8') print(type(l)) print(f.writable()) f.write(l)
这段程序就是打开一个叫做text.txt的文本文档,然后把我得到的网页数据写进去。效果如下
到此为止,我们已经知道了如何设计爬虫——访问网络资源,解析数据,存储数据。
在后面的文章里,我会就这三个方面分别介绍python中的一些实用的库,以及其用法,中间会穿插一些简单的爬虫。
如果读者是在使用python2.7版本的话,我推荐大家去这个博客学习,这位博主的爬虫系列教程写的很是详细,应该可以帮助到大家。