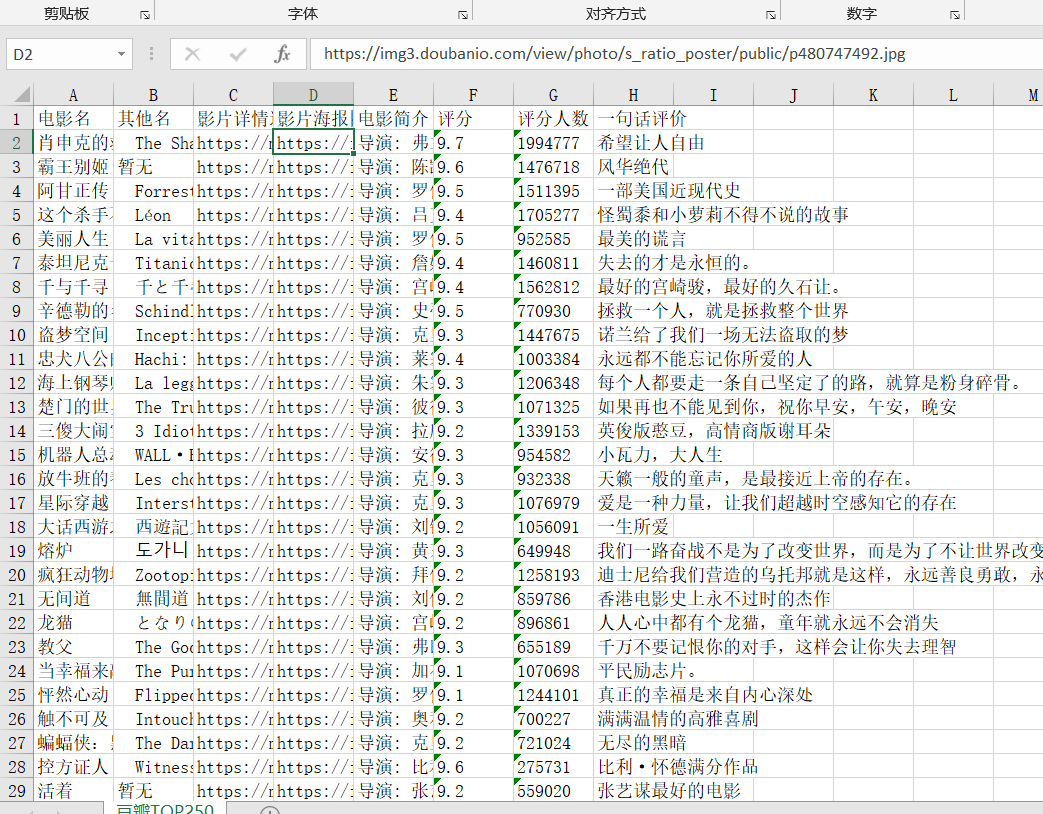
from bs4 import BeautifulSoup import openpyxl import re import urllib.request import urllib.error # 访问url def ask_url(url): # 伪装浏览器 head = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'} req = urllib.request.Request(url, headers=head) # 包装 try: response = urllib.request.urlopen(req, timeout=3) # 访问 超时3s结束 html = response.read().decode('utf-8') # 解码 return html # 返回url网页html源码 except urllib.request.HTTPError as e: if hasattr(e, 'code'): print(e.code) except urllib.error.URLError as e: if hasattr(e, 'reason'): print(e.reason) # 爬取网页 def crawl_web(base_url): data_list = [] # re电影名 re_movie_name = re.compile(r'<span class="title">(.*?)</span>') # re影片详情连接 re_movie_link = re.compile(r'<a class="" href="(.*?)">') # re影片海报图片 re_movie_img = re.compile(r'<img.*src="(.*?)".*?>', re.S) # re电影简介 re_movie_introduction = re.compile(r'<p class="">(.*?)</p>', re.S) # re评分 re_movie_score = re.compile( r'<span class="rating_num" property="v:average">(.*?)</span>') # re评分人数 re_movie_judge = re.compile(r'<span>(.*?)人评价</span>') # re一句话评价 re_moive_inq = re.compile(r'<span class="inq">(.*?)。*</span>') for i in range(10): url = base_url + str(i * 25) html = ask_url(url) # 获取网页源码 soup = BeautifulSoup(html, 'html.parser') # 解析源码 for item in soup.find_all(class_='item'): item = str(item).replace(u'xa0', ' ') # 获取的页面中有奇妙代码(●'◡'●),所以要去掉 data = [] # 获取需要的信息 movie_name = re.findall(re_movie_name, item) if len(movie_name) > 1: data.append(movie_name[0]) data.append(movie_name[1].replace('/', '')) else: # 没有外语名也要空出来,方便后续储存 data.append(movie_name[0]) data.append('暂无') movie_link = re.findall(re_movie_link, item)[0] data.append(movie_link) movie_img = re.findall(re_movie_img, item)[0] data.append(movie_img) movie_introduction = re.findall(re_movie_introduction, item)[0] movie_introduction = re.sub( r'<br(.*)?>', ' ', movie_introduction).strip() # 存入简介时要去掉含有的html标签 data.append(movie_introduction) movie_score = re.findall(re_movie_score, item)[0] data.append(movie_score) movie_judge = re.findall(re_movie_judge, item)[0] data.append(movie_judge) moive_inq = re.findall(re_moive_inq, item) if len(moive_inq) == 0: # 有时候没有一句话短评,同上要空出 data.append('暂无') else: data.append(moive_inq[0]) # 添加到data_list data_list.append(data) return data_list def save_data(save_path, data_list): wb = openpyxl.Workbook() ws = wb.active ws.title = '豆瓣TOP250' first_row = ("电影名", "其他名", "影片详情连接", "影片海报图片", "电影简介", "评分", "评分人数", "一句话评价") temp = 1 for i in first_row: # 生成表头 ws.cell(1, temp, i) temp += 1 row = 1 for i in data_list: # 存入数据 row += 1 column = 1 for j in i: ws.cell(row, column, j) column += 1 wb.save(save_path+'豆瓣TOP250.xlsx') return None if __name__ == "__main__": base_url = 'https://movie.douban.com/top250?start=' save_path = 'D:\MyProject\Python学习\爬虫\' data_list = crawl_web(base_url) save_data(save_path, data_list) print('Crawl over')