线程:
进程:
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
进程对线程资源整合
并发:
并行:
进程与线程的区别?
- 线程共享创建它的进程的地址空间,进程有自己的地址空间
- 线程可以直接访问其进程的数据段;进程有自己的父进程数据段的副本
- 线程可以直接与同进程的其他线程通信,而进程间通信必须使用IPC(Interprocess communication)
- 很容易建立新的线程,新的进程的创建需要复制父进程
- 线程可以很大程度上控制同一进程的其他线程,但是进程只能控制子进程
- 更改主线程(取消,优先级更改等)可能会影响同一进程的其他线程;更改父进程不影响子进程
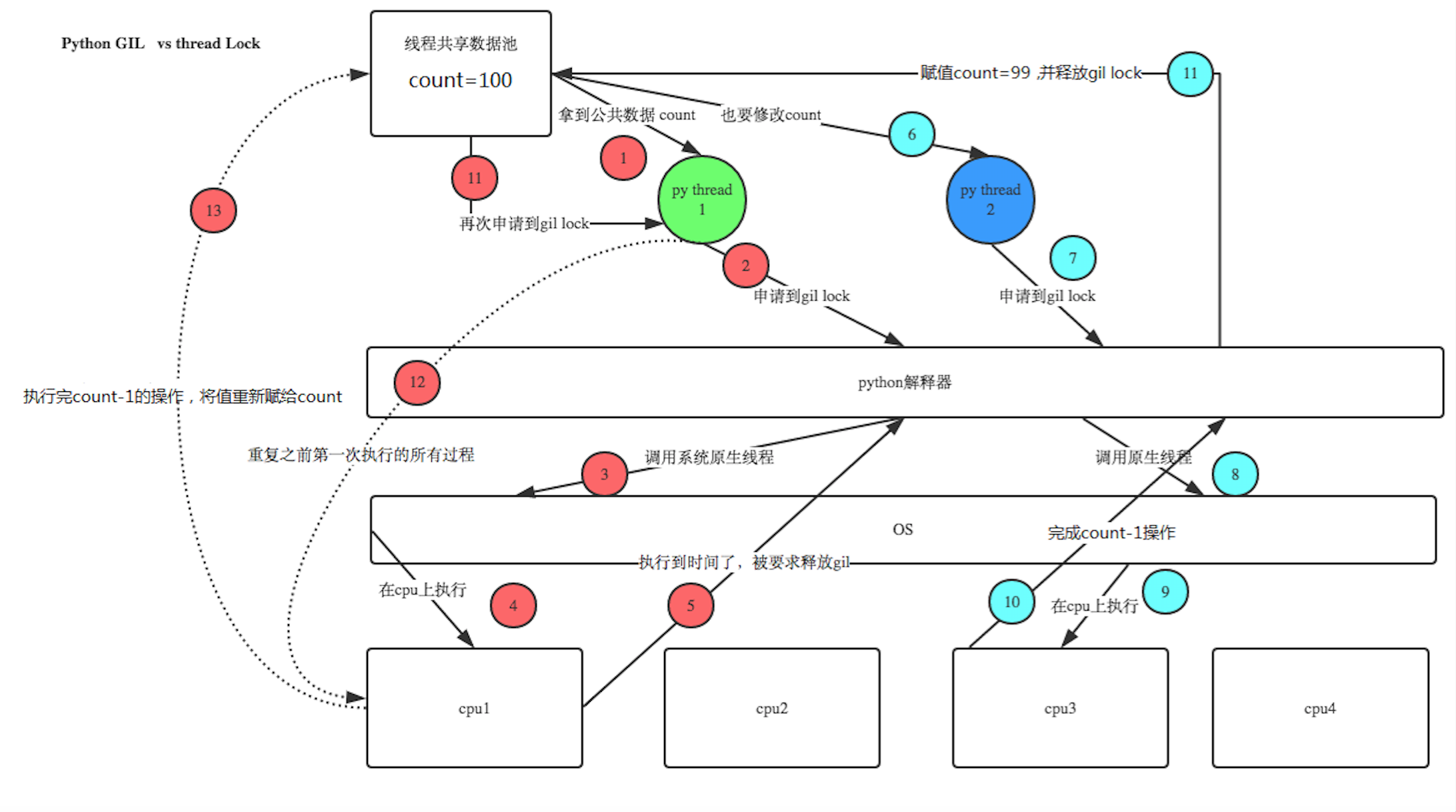
Python GIL(Global Interpreter Lock):它不是python的特性,它是用C语言实现python解释器Cpython时引入的一个概念。Python完全 可以不依赖GIL。
Python threading模块
threading通过对thread模块进行二次封装,提供了更方便的API来操作线程。
threading.Thread
Thread是threading模块中最重要的类之一,用于创建线程。共有两种方法:一通过继承Thread类,重写它的run方法;另一种是创建一个threading.Thread对象,在它的初始化函数中将可调用对象作为参数传入。
1 import threading, time, random 2 count = 0 3 class Counter(threading.Thread): 4 def __init__(self, lock, threadName): 5 ''' 6 继承父类__init__ 7 :param lock: 锁对象 8 :param threadName:线程名称 9 ''' 10 super(Counter, self).__init__(name=threadName) 11 self.lock = lock 12 13 def run(self): 14 ''' 15 重写父类run方法,在线程启动后执行该方法内的代码。 16 ''' 17 global count 18 self.lock.acquire()#不明白 19 for i in range(1000): 20 count = count + 1 21 self.lock.release() 22 lock = threading.Lock() 23 for i in range(5): 24 Counter(lock, "thread-" + str(i)).start() 25 time.sleep(2) 26 print(count)#5000
创建了一个Counter类,它继承了threading.Thread.初始化函数接收两个参数,一个是锁对象,另一是线程的名称。
重写了父类中的run方法,run方法将一个全局变量逐一加1000.
接着,创建了5个Counter对象,并且调用start方法,开启线程,最后打印结果。run方法和start方法都是从Thread继承而来,run方法在线程打开后执行,可以将相应的逻辑写到run方法中;start用于启动线程。
1 import threading, time, random 2 count = 0 3 lock = threading.Lock() 4 def doAdd(): 5 6 global count, lock 7 lock.acquire() 8 for i in range(1000): 9 count += 1 10 lock.release() 11 for i in range(5): 12 threading.Thread(target=doAdd, args=(), name="thread-" + str(i)).start() 13 time.sleep(2)#确保线程都执行完毕 14 print(count)#5000
定义了doAdd,它将全局变量count逐一加1000,然后创建了5个Thread对象,把函数对象doAdd作为参数传给它的初始化函数,在调用Thread对象的start方法,线程启动后执行doAdd函数。
def __init__(self, group=None, target=None, name=None, args=(), kwargs={})
- 参数group是预留的,用于将来的扩展;
- 参数target是一个可调用对象,在线程启动后执行;
- 参数name是线程的名字,默认值为“Thread-N”, N是一个数字。
- 参数args和kwargs分别表示调用target时的参数列表和关键字参数
Thread类还定义了以下常用方法与属性:
用于获取和设置线程的名称
- Thread.getName()
- Thread.setName()
- Thread.name
用于获取线程的标识符,线程标识符是一个非零整数,只有在调用了start()方法之后该属性才会有效,否则他只返回None
- Thread.ident
判断线程是否是激活的,从调用start()方法启动线程,到run()方法执行完毕或遇到未处理异常而中断这段时间内,线程是激活的。
- Thread.is_alive()
- Thread.isAlive()
调用Thread.join将会使主调线程阻塞,直到被调用线程运行结束或超时,参数timeout是一个数值类型,表示超时时间,如果未提供该参数,那么主调线程一直堵塞到被掉线程结束。
1 import threading, time 2 def doWaiting(): 3 print("start waiting:", time.strftime("%H:%M:%S")) 4 time.sleep(3) 5 print("stop waiting", time.strftime("%H:%M:%S")) 6 thread1 = threading.Thread(target=doWaiting) 7 thread1.start() 8 time.sleep(1) 9 print("start join") 10 # thread1.join() 11 print('end join') 12 #保证线程结束后,在向下执行 13 # start waiting: 09:17:40 14 # start join 15 # stop waiting 09:17:43 16 # end join 17 #没有用join 18 # start waiting: 09:25:38 19 # start join 20 # end join 21 # stop waiting 09:25:41
threading.RLock和threading.Lock
---同步锁(Lock)
应用背景:
1 import time, threading 2 3 def addNum(): 4 global num#获取到了全局变量num 5 # num -= 1#输出理想 6 temp = num 7 time.sleep(0.1)#假装执行被切换 8 num = temp - 1 9 print('---get num:', num) 10 11 num = 100 12 thread_list = [] 13 for i in range(100): 14 th = threading.Thread(target=addNum) 15 th.start()#启动100个线程,同时去拿资源num=100,num -= 1:可以按顺序来拿,但是sleep(0.1):这样的情况就不一样了,大家都取到的是100 16 thread_list.append(th) 17 18 for th in thread_list:#等待所有的线程结束 19 th.join() 20 21 print('final num:', num)
其执行过程可用以下图表示:
以上背景介绍的是---多个线程都在同时争夺一个共享资源num=100,所以造成了资源破坏;如果用join会把整个线程给停住,造成了串行,失去了多线程的意义。其实,我们只需要把公共数据串行执行。引出同步锁(Lock)
以上实例子再分析:
1 import time, threading 2 3 def addNum(): 4 global num 5 lock.acquire() 6 temp = num 7 time.sleep(0.1)#num = 100 被锁住后,这段内容完成后,才会执行下一步! 8 num = temp - 1 9 print('---get num:', num) 10 lock.release() 11 12 num = 100 13 thread_list = [] 14 lock = threading.Lock() 15 16 for i in range(100): 17 t = threading.Thread(target=addNum) 18 t.start() 19 thread_list.append(t) 20 21 for th in thread_list: 22 th.join() 23 24 print('final num:', num)#最终输出正常,但是明显有卡顿,不够流畅和sleep(0.1)有关!
---注:同步锁与解释器全局锁的关系?
Python的线程在GIL的控制之下,线程之间,对整个python解释器,对python提供的C API的访问都是互斥的,这可以看作是Python内核级的互斥机制。但是这种互斥是我们不能控制的,我们还需要另外一种可控的互斥机制———用户级互斥。内核级通过互斥保护了内核的共享资源,同样,用户级互斥保护了用户程序中的共享资源。
但是如果你有个操作比如 x += 1,这个操作需要多个bytecode操作,在执行这个操作的多条bytecode期间的时候可能中途就换线程了,这样就出现了data races的情况了。
---线程死锁和递归锁(RLock)
死锁:死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
在threading模块中,定义两种类型的锁,threading.Lock和threading.RLock,它们之间有一点细微区别,如下例
1 import threading
2 lock = threading.Lock()
3 lock.acquire()
4 lock.acquire()#产生了死锁,程序不能够正常结束,抢占同一资源acquire
5 lock.release()
6 lock.release()
7
8 import threading
9 rLock = threading.RLock()
10 rLock.acquire()
11 rLock.acquire()#在同一线程内,程序不会堵塞,程序能够正常结束
12 rLock.release()
13 rLock.release()
RLock允许在同一线程中被多次acquire,而Lock却不允许这种情况发生。注:使用RLock,那么acquire和release必须成对出现,即调用了n次acquire,必须调用n次的release才能真正释放所占用的锁。
为了支持在同一线程中多次请求同一资源,python提供了“可重入锁”:threading.RLock。RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次acquire。直到一个线程所有的acquire都被release,其他的线程才能获得资源。详见下例子:
信号量(Semaphore)
信号量用来控制线程并发数的,BoundedSemaphore或Semaphore管理一个内置的计数 器,每当调用acquire()时-1,调用release()时+1。
计数器不能小于0,当计数器为 0时,acquire()将阻塞线程至同步锁定状态,直到其他线程调用release()。(类似于停车位的概念)
BoundedSemaphore与Semaphore的唯一区别在于前者将在调用release()时检查计数 器的值是否超过了计数器的初始值,如果超过了将抛出一个异常。
数据库,连接,同时可以连接数据库。
---Condition(条件变量同步锁)
有一类线程需要满足条件之后才能够继续执行,Python提供了threading.Condition 对象用于条件变量线程的支持,它除了能提供RLock()或Lock()的方法外,还提供了 wait()、notify()、notifyAll()方法。
lock_con=threading.Condition([Lock/Rlock]): 锁是可选选项,不传人锁,对象自动创建一个RLock()。
- wait():条件不满足时调用,线程会释放锁并进入等待阻塞;
- notify():条件创造后调用,通知等待池激活一个线程;
- notifyAll():条件创建后调用,通知等待池激活所有线程;
---threading.Condition
它可以理解为一把高级锁,提供了比RLock、Lock更高级的功能,允许我们能够控制复杂的线程同步问题,threading.Condition在内部维护一个锁对象(默认RLock),可以在创建Condigtion对象的时候把锁对象作为参数传入。
Condition也提供了acquire,release方法,其含义与锁的acquire、release方法一致,其实它只是简单的调用内部锁对象的对应的方法而已。Condition还提供了如下方法。注意以下方法只有在占用锁(acquire)之后才能调用,否则将会报RuntimeError异常
------Condition.wait([timeout]):
wait方法释放内部所占用的锁,同时线程被挂起,直至接收到通知被唤醒或超时(如果提供了timeout参数的话)。当线程被唤醒并重新占有锁的时候,程序才会继续执行下去。
------Conditon.notify():
唤醒一个挂起的线程(如果存在挂起的线程)。注意:notify()方法不会释放所占用的锁。
------Condition.notify_all()
------Condition.notifyAll()
唤醒所有挂起的线程(如果存在挂起的线程),注意:这些方法不会释放所占用的锁
1 #----Condition 2 #----捉迷藏的游戏 3 import threading, time 4 class Hider(threading.Thread): 5 def __init__(self, cond, name): 6 super(Hider, self).__init__() 7 self.cond = cond 8 self.name = name 9 10 def run(self): 11 time.sleep(1)#确保先运行Seeker中的方法 12 13 self.cond.acquire()#b 14 print(self.name + ': 我已经把眼睛蒙上了') 15 self.cond.notify() 16 self.cond.wait()#c 17 #f 18 print(self.name + ": 我找到你了") 19 self.cond.notify() 20 self.cond.release() 21 #g 22 print(self.name + ": 我赢了")#h 23 24 25 class Seeker(threading.Thread): 26 def __init__(self, cond, name): 27 super(Seeker, self).__init__() 28 self.cond = cond 29 self.name = name 30 31 def run(self): 32 self.cond.acquire() 33 self.cond.wait()#a 释放对锁的占用,同时线程被挂起在这里,直到被notify重新占有锁 34 #d 35 print(self.name + ": 我已经藏好了,你快来找我吧") 36 self.cond.notify() 37 self.cond.wait()#e 38 #h 39 self.cond.release() 40 print(self.name + ": 被你找到了,哎。。") 41 42 cond = threading.Condition() 43 seeker = Seeker(cond, "seeker") 44 hider = Hider(cond, "hider") 45 seeker.start() 46 hider.start() 47 # hider: 我已经把眼睛蒙上了 48 # seeker: 我已经藏好了,你快来找我吧 49 # hider: 我找到你了 50 # hider: 我赢了 51 # seeker: 被你找到了,哎。。
threading.Event
Event实现与Condition类似的功能,不过比Condition简单一点,它通过维护内部的标识符来实现线程间的同步问题。
- Event.wait([timeout]):堵塞线程,直到Event对象内部标志位被设为True或超时(如果提供了参数timeout)
- Event.set():将标识位设为True
- Event.clear():将标识位设为False
- Event.isSet():判断标识位是否为Ture
threading.Timer
threading.Timer是threading.Thread的子类,可以在指定时间间隔后执行某个操作,下面是PYhon手册上提供的一个列子:
1 from threading import Timer 2 def hello(): 3 print("hello world") 4 t = Timer(3, hello) 5 t.start()#3秒后执行hello函数
模块中的其他方法:
threading.active_count()
threading.activeCount()
获取当前活动的(alive)线程的个数。
threading.current_thread()
threading.currentThread()
获取当前的线程对象(Thread object)。
threading.enumerate()
获取当前所有活动线程的列表。
threading.settrace(func)
设置一个跟踪函数,用于在run()执行之前被调用。
threading.setprofile(func)
设置一个跟踪函数,用于在run()执行完毕之后调用
本文部分参考:http://python.jobbole.com/81546/
Join & Daemon
join()阻塞: 在子线程完成运行之前,这个子线程的父线程将一直被阻塞
1 th = threading.Thread(target=thread_func, agrgs=[]) 2 th.join()
when your program quits, any daemon threads are killed automatically.:当程序退出时,被守护线程将被自动杀死
1 th = threading.Thread(target=thread_func, agrgs=[]) 2 th.setDaemon(True)
3 th.start()#必须在启动之前
将线程声明为守护线程,必须在start() 方法调用之前设置, 如果不设置为守护线程程序会被无限挂起。这个方法基本和join是相反的。当我们 在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程 就分兵两路,分别运行,那么当主线程完成想退出时,会检验子线程是否完成。如 果子线程未完成,则主线程会等待子线程完成后再退出。但是有时候我们需要的是 只要主线程完成了,不管子线程是否完成,都要和主线程一起退出,这时就可以 用setDaemon方法。