[ import的使用,
time时间模块,
os模块日常应用,
Shutil 模块压缩和复制,
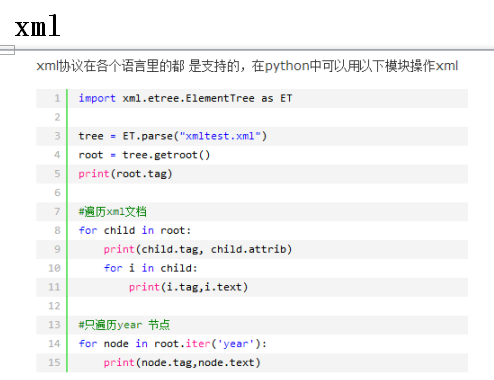
xml,
ConfigParser模块 (配置文件),
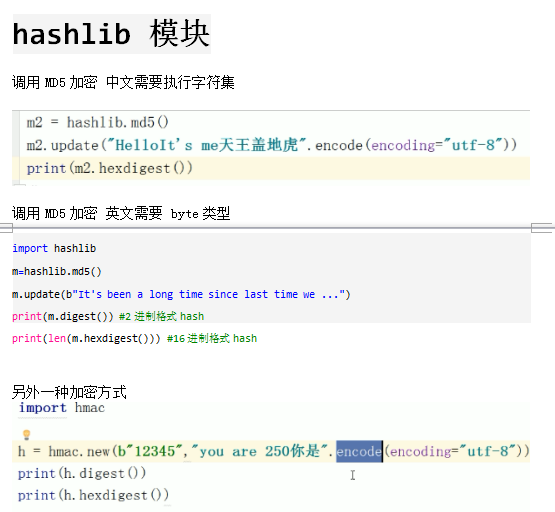
hashlib 模块(数据加密),
re模块 (正则表达式),
logging模块 日志
小贴士:
1.调用一个文件内的方法,会执行内部的 除其他方法以外的代码
2.两个文件,不能互相调用。a文件,b文件。如果a调用了b的方法,
b在调用a的方法会出错
3 如果导入的包没有使用,会报运行错误,删掉文件头导入的包即可
import
form a import * (不建议使用)
会把a.py文件内的方法 在当前文件 都执行一遍
如果在当前文件有定义相同名称的方法,a.py的方法会被覆盖
方法1
相当于把指定的方法 如q,的代码在当前文件执行一遍
给导入的方法定义别名
form a import q as w
导入多个
form a import q,a,c
导入方法2 直接import不写from
相当于把所有的方法都解释一遍当做一个变量传给a
import a
调用
a.方法名
导入其他目录(方法二)
在导入的时候会首先从当的目录中寻找
如果导入其他目录
sys.path 返回值是一个列表,导入的时候会查看列表中的路径里
是否有需要导入的包,如果没有则会报错
那么如果我们需要导入其他目录中的 函数,就需要
os.path.abspath(_file_) 打印当前的环境变量
然后使用 os.path.dirname 去掉后缀的 名称 可以进行多次嵌套
然后 把路径加入到环境变量列表中
如下

方法一,二的区别
由于二者的区别,所以在调用时的方式也不一样。
方法1 直接调用方法 或者 变量
方法2 导入文件的名子.方法或者变量
导入包(pychar)的本质就是 执行 导入包下的
_init_.py 文件
导入优化
如果有个模块的方法需要多次调用
那么上述 方法2 就不适用,因为调用多少次函数,他就会
去从这个py文件中搜索函数多少次。 效率低
方法1 中 直接给明了 需要调取函数的位置,不用去搜索,
效率更高
模块的分类
a 标准库(内置模块)
b 开源模块
c 自定义模块
标准库:
1.time ,datetime
hlep(time)查看time模块的说明
time.timezone 世界标准时间 和 本地时间的差值
time.time()获取时间戳
time.sleep()睡眠时间
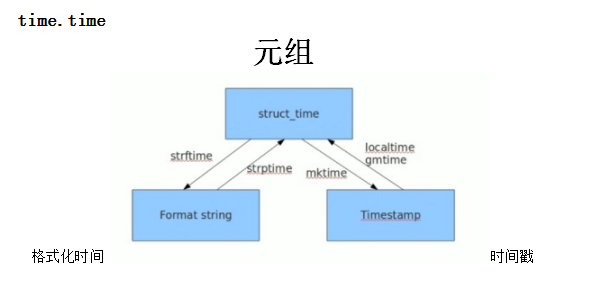
time.gmtime()把时间,转化成utc(世界标准时间)元组
time.localtime()转化成本地时间 元组
转化成元组调用时,如下图
里边还有很多变量,如一年的第几天
也可以传入参数

time.mktime(x) 将元组转化为时间戳
time.strfime( 字符串格式,元组) 将元组,格式化输出
如下图
%Y代表年,%m代表月,%d代表日 等等
中间‘-’只是分隔符,可以随意更换
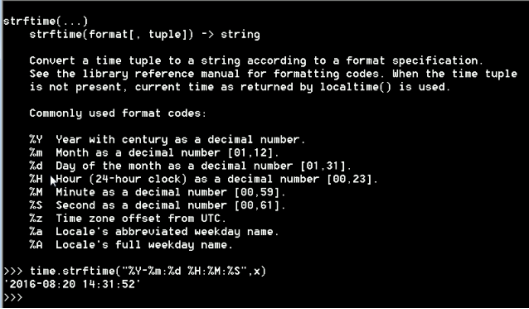
time.strptime(格式化的时间,格式) 将格式化时间转化为元组

%Y 等于 调用tm_year的方法
time.asctime(元组) 将元组转化为 格式化输出
如果不写参数,就把本地时间,按默认格式化输出
time.ctime(时间戳)将时间戳转化为 格式化输出
如果不写参数,就把本地时间,按默认格式化输出
#时间加减
import datetime
# print(datetime.datetime.now()) 返回当前时间
# 时间戳直接转成日期格式 2016-08-19
#print(datetime.date.fromtimestamp(time.time()) ) # print(datetime.datetime.now() )
# print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
# print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
# print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
# print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分
格式参照
%a 本地(locale)简化星期名称
%A 本地完整星期名称
%b 本地简化月份名称
%B 本地完整月份名称
%c 本地相应的日期和时间表示
%d 一个月中的第几天(01 - 31)
%H 一天中的第几个小时(24小时制,00 - 23)
%I 第几个小时(12小时制,01 - 12)
%j 一年中的第几天(001 - 366)
%m 月份(01 - 12)
%M 分钟数(00 - 59)
%p 本地am或者pm的相应符 一
%S 秒(01 - 61) 二
%U 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 三
%w 一个星期中的第几天(0 - 6,0是星期天) 三
%W 和%U基本相同,不同的是%W以星期一为一个星期的开始。
%x 本地相应日期
%X 本地相应时间
%y 去掉世纪的年份(00 - 99)
%Y 完整的年份
%Z 时区的名字(如果不存在为空字符)
os模块
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为" ",Linux下为" "
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间

Shutil 模块
复制文件 copyfile

不确定 8章复制文件和它的权限
Shutil.copymode()
复制文件的属性,和权限 到笔记三 不会创建新文件
Copystat()

复制文件和它的权限
Shutil.copy
Shutil.copy 2
拷贝目录
参数1.源目录 2 拷贝后的目录

删除目录

移动文件
Shutil.move(原位置,移动到哪)
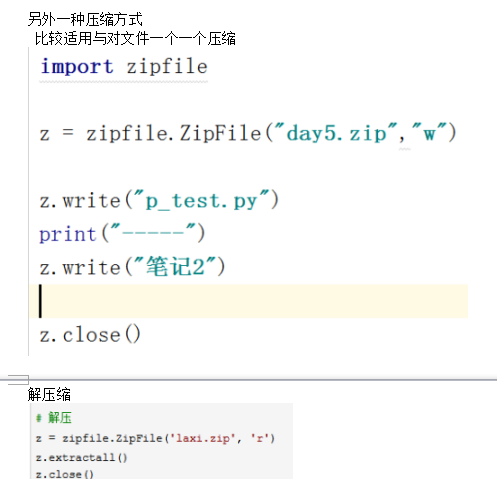
压缩文件
Shutil.make_archive(“a”,”zip”,”b”)
参数1 拷贝后的文件名,不写目录代表当前目录
参数2 代表压缩格式 有多种 zip,tar,bztar,gztar
参数3 源文件的地址,可以压缩目录
更多参数如下

Shelve模块(单个文件可存放多个对象)
在序列化对象的时候,注意只会序列化对象。不会把他的类也序列化,所以在取对象的时候,会报类似以下的错误
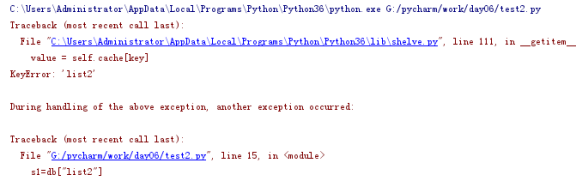
对上述问题的解决方法 把需要的类导进去 student是类名
from work.day06.tese_s import student
序列化pickle的封装 支持pickle的所有类型通过 Key:velue的方式 非常简单,清晰
Pickele 可以序列化所有类型 但只支持python读取
Josn 只能序列化简单类型 但是java c语言都可以反序列化
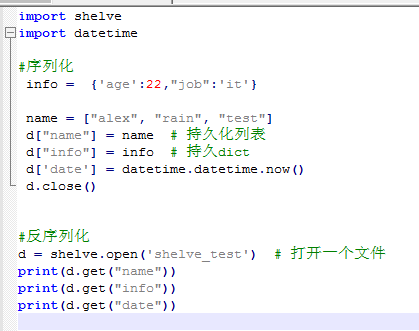
反序列化 对对象进行操作,新的操作 数据会遗失。
将writeback置为True 可解决问题.
close()方法,一定要用不然执行对对象的操作,依然无法保存



ConfigParser模块 (配置文件)
example.ini 文件名
内容:
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes
[bitbucket.org]
User = hg
[topsecret.server.com]
Port = 50022
ForwardX11 = no
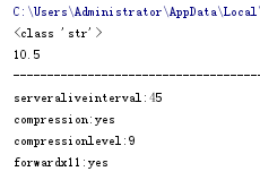
获取数据如下
import configparser
config = configparser.ConfigParser()
# config.sections()
config.read('example.ini')
topsecret = config['topsecret.server.com']
#直接取一个
a=topsecret['Port']
#取出来都是str类型,需要转义
print(type(a))
#将0.5字符串转成 小数计算
print(float(a)+10)
print("-----------------------------------------------")
#遍历获得多个
for key in config['DEFAULT']:
print(key+":"+config['bitbucket.org'][key])
输出如下:
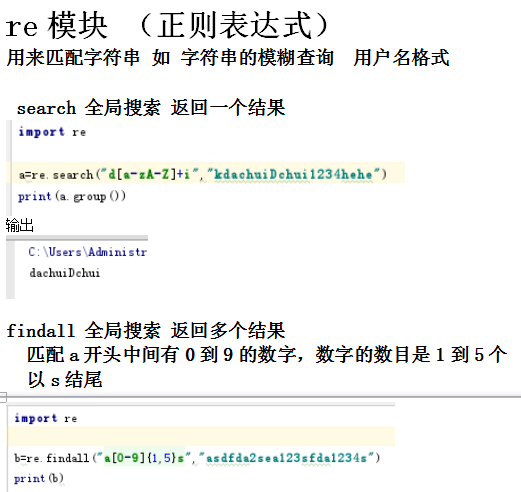


aal? 代表 匹配aa或者aal 最后的一个字符可以有或者没有
A等同于^ 代表开头
分组匹配 输出属性 字典
语法看起来复杂,其实是固定的
<自定义属性名称>正则表达式 两边的东西都不用管照搬

输出

忽略大小写


logging模块 日志
打印日志到文件
如下 4个参数 也可以更多
1:log文件的位置,自动创建
2:写入的日志级别 日志级别大小关系为:CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET
3:想要输出的日志 都包含什么 具体看图d5_1
4:加上日期 格式化字符串

图d5_1
|
%(name)s |
Logger的名字 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
|
%(filename)s |
调用日志输出函数的模块的文件名 |
|
%(module)s |
调用日志输出函数的模块名 |
|
%(funcName)s |
调用日志输出函数的函数名 |
|
%(lineno)d |
调用日志输出函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息 |
同时 打印和输入文件
# coding=utf-8
__author__ = 'liu.chunming'
import logging
# 第一步,创建一个logger
logger = logging.getLogger()
logger.setLevel(logging.INFO) # Log等级总开关
# 第二步,创建一个handler,用于写入日志文件
logfile = 'logger.txt'
fh = logging.FileHandler(logfile)
fh.setLevel(logging.DEBUG) # 输出到file的log等级的开关
# 第三步,再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.WARNING) # 输出到console的log等级的开关
# 第四步,定义handler的输出格式
formatter = logging.Formatter("%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s")
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 第五步,将logger添加到handler里面
logger.addHandler(fh)
logger.addHandler(ch)
# 日志
logger.debug('this is a logger debug message')
logger.info('this is a logger info message')
logger.warning('this is a logger warning message')
logger.error('this is a logger error message')
logger.critical('this is a logger critical message')