卷积神经网络(Convolutional Neural Network)
1、什么是CNN
2、为什么用CNN
3、CNN实现步骤
4、如何用keras搭建一个CNN
1、什么是CNN
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)”。
1、卷积本质上是“加权求和”,在信号处理中是时间上的“加权求和”,在图像处理中是空间上的“加权求和”
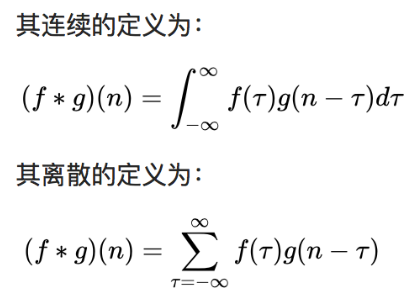
2、在信号处理中,系统的响应不仅与当前时刻系统的输入有关,也跟之前若干时刻的输入有关,比如在t3时刻的响应Y(3)=Y(0)+Y(1)+Y(2),但常常系统中不是这样的,因为0时刻的响应不太可能在1时刻仍旧未变化,那么怎么表述这种变化呢,就通过h(t)这个响应函数与x(0)相乘来表述,表述为x(m)×h(t-m),公式里的m指的 t 的变化量

2、为什么用CNN
机器识图的过程:机器识别图像并不是一下子将一个复杂的图片完整识别出来,而是将一个完整的图片分割成许多个小部分,把每个小部分里具有的特征提取出来(也就是识别每个小部分),再将这些小部分具有的特征汇总到一起,就可以完成机器识别图像的过程了。
如下图的识别过程,其实是每层都分别提取不同的特征,比如第一层先提取颜色或者条纹,第二层再判别属于哪种条纹等,以此类推,直至结果。

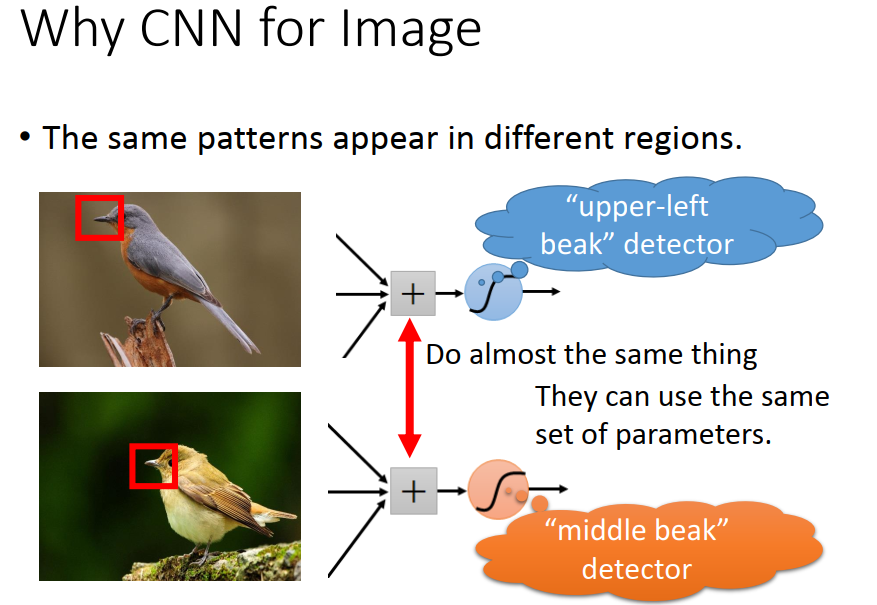
CNN的参数比全连接神经网络少得多,为什么CNN只用较少的参数就可以用于处理图像呢?这是因为图像具有以下三点特征:
- 一些特征比整张图片小得多,不用CNN的话会看完整幅图片才能确定一个特征,用CNN会认为只需要看图片的局部就可以了;
- 同样的特征可能出现在图像的不同区域,不用CNN的话会认为这两个不同位置的同一个特征是不同的特征,用CNN会认为它们是同一个;
- 对图像的降采样不会改变图像中的物体。
CNN的卷积层的设计对应着前两点,池化层的设计对应着第三点。


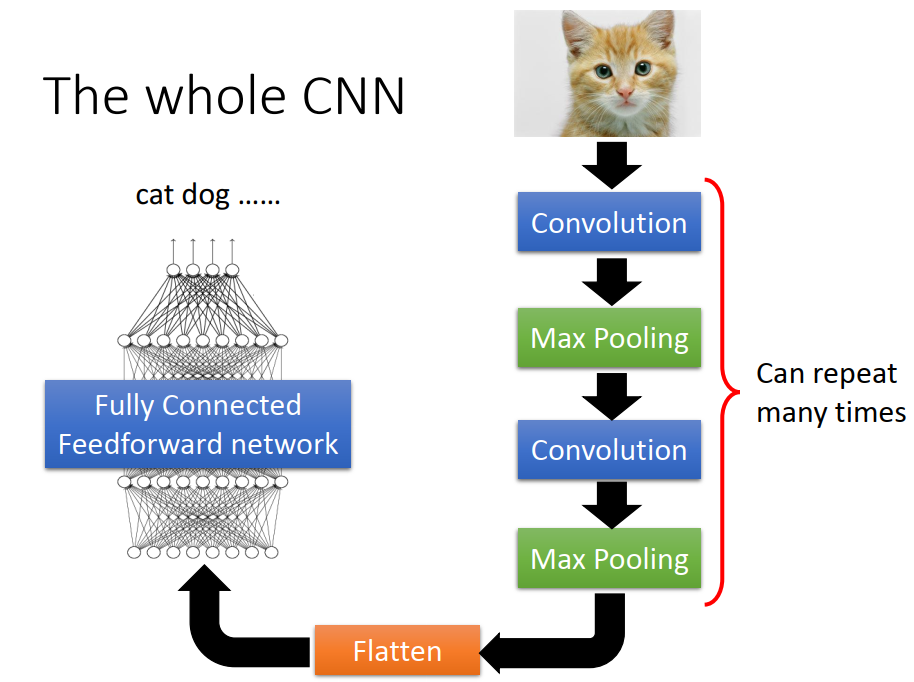
3、CNN实现步骤
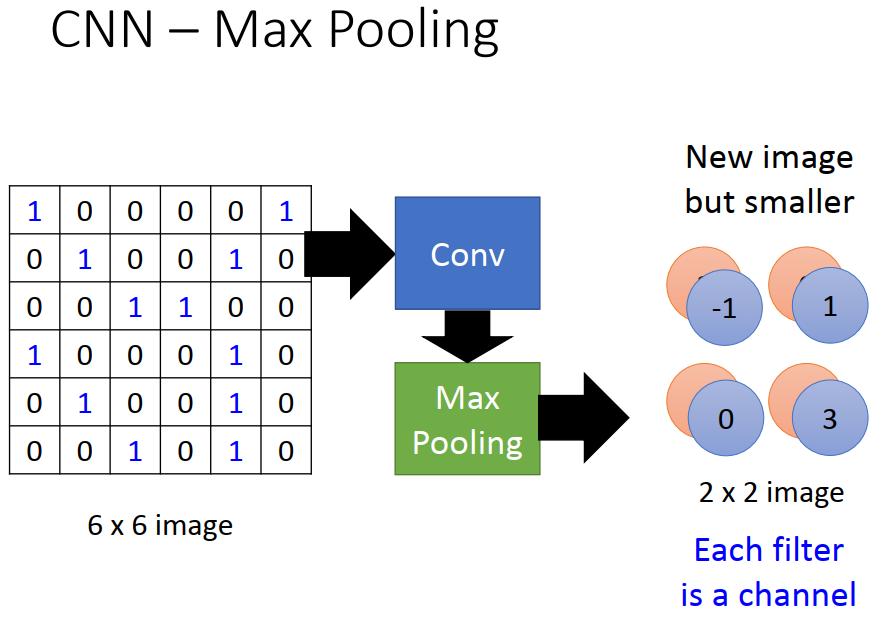
input——>convolution(卷积)——>max pooling(最大池)——>...——>convolution——>max pooling——>flatten(扁平化)——>fully connected network——>output
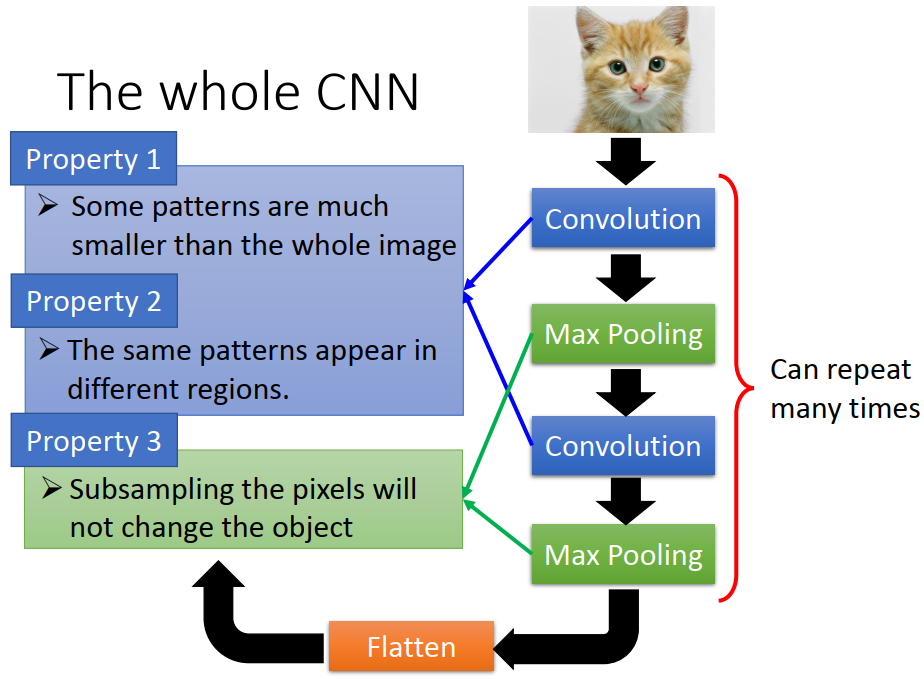
1)卷积层 (减少训练参数)
- 对应上图Property1:每一个Filter(待训练的参数)代表一个局部特征探测器,假设现在两个特征探测器(Filter1和Filter2)
- 对应上图Property2:用Filter1就能探测出在不同位置的同一个flatten,而不需要用不同的Filter
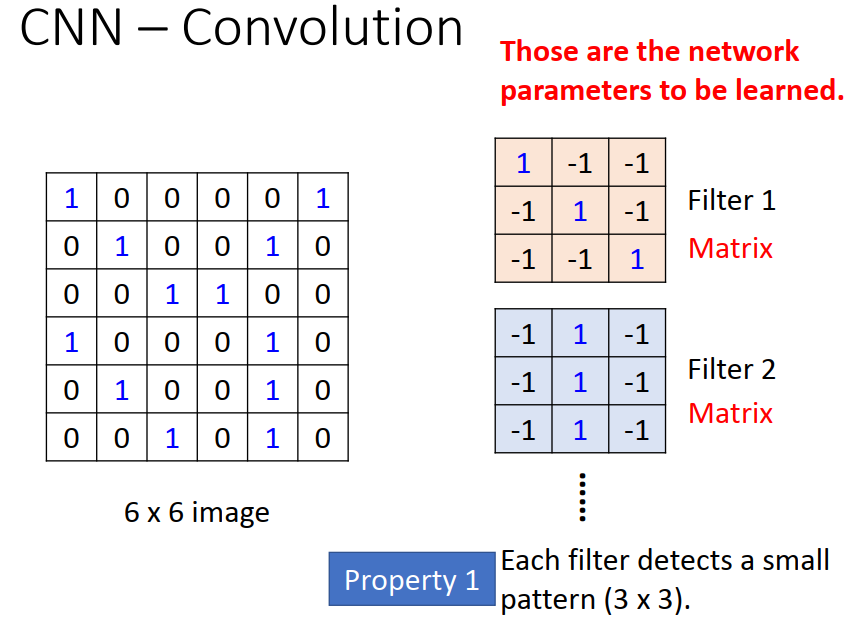

如上图,从左上方开始,用 Filter 与 image 中的部分做内积,便可以得到一个新的数字,然后向右移动移动距离(其中 stride 即表示步长,需自行设置),继续做内积。
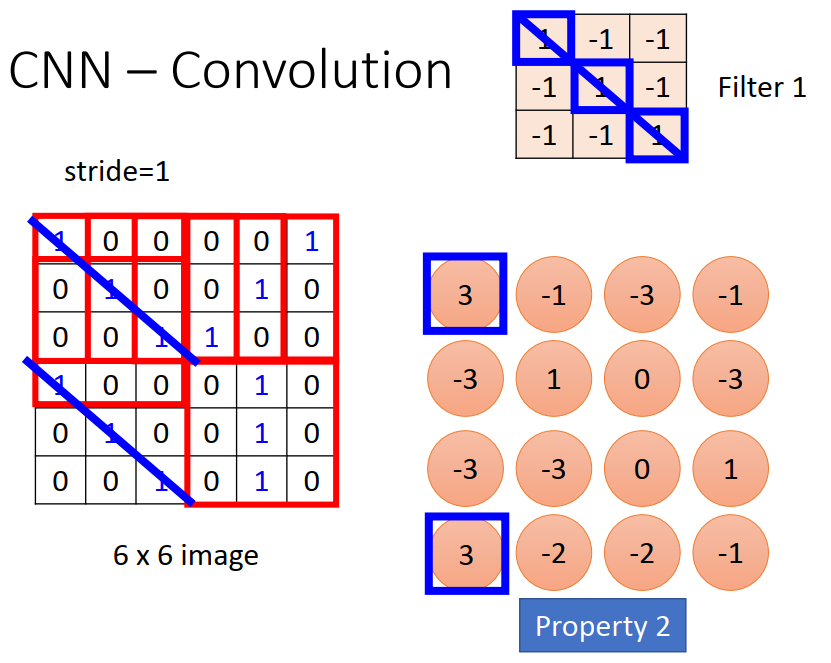

按照上述步骤,将Filter 与 image全部做完内积之后,得到上图橙色的 new matrix,其中数字相同,即代表此处具有相同的特征。
然后用下一个 Filter 继续与 image 做内积,得到新的 matrix,如上图蓝色矩阵。
- 如果图片是彩色的,也就是说它是三通道的,还没卷积之前,可以说有3个通道,意味着每一个像素由3个数值表示(RGB)。
如图所示,注意,此时做内积,并不是三层分别做内积,而是直接用立方体做内积。其他步骤同上。

与全连接方式的对比:
- convolution的事情,就是把fully connected的部分参数拿掉
- 拿掉部分参数以后,剩下的参数权值共享



在fully connected中,每个input都有对应的weight,convolution则只连接了部分input,因此节省了很多参数;同时一些weight是被共用的,更进一步节省了参数。
2)池化层
目的是减少每一个特征的维度,也就是减少后面flatten的输入特征数量
将这一层的output为几个部分,每个部分都选取最大的留下,其余的省略,将得到的新矩阵继续作为下一层的input。
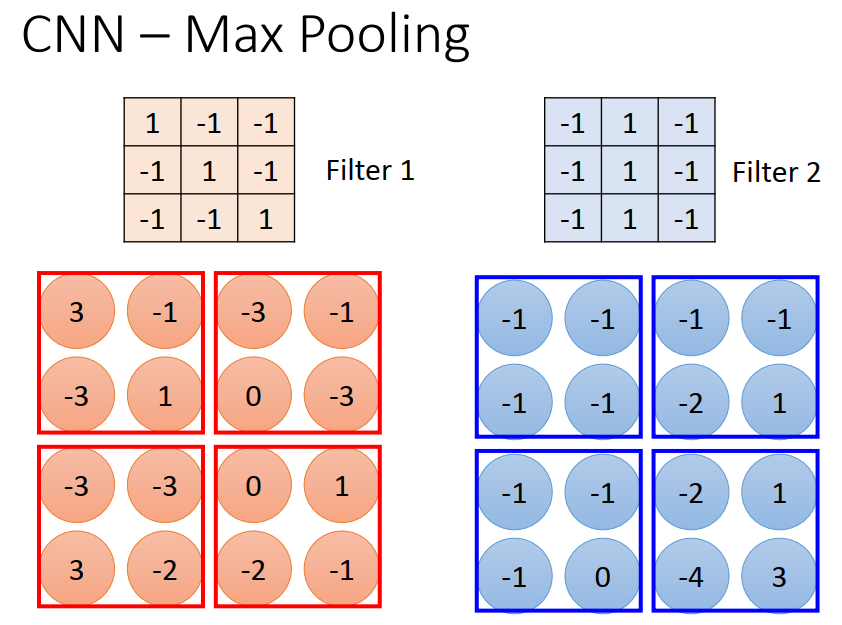
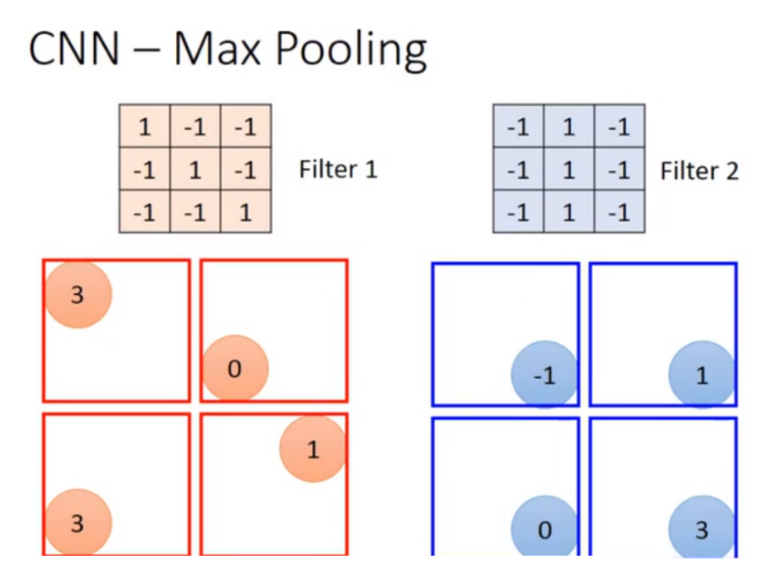
效果
3)重复卷积、池化
重复 1)2)的步骤

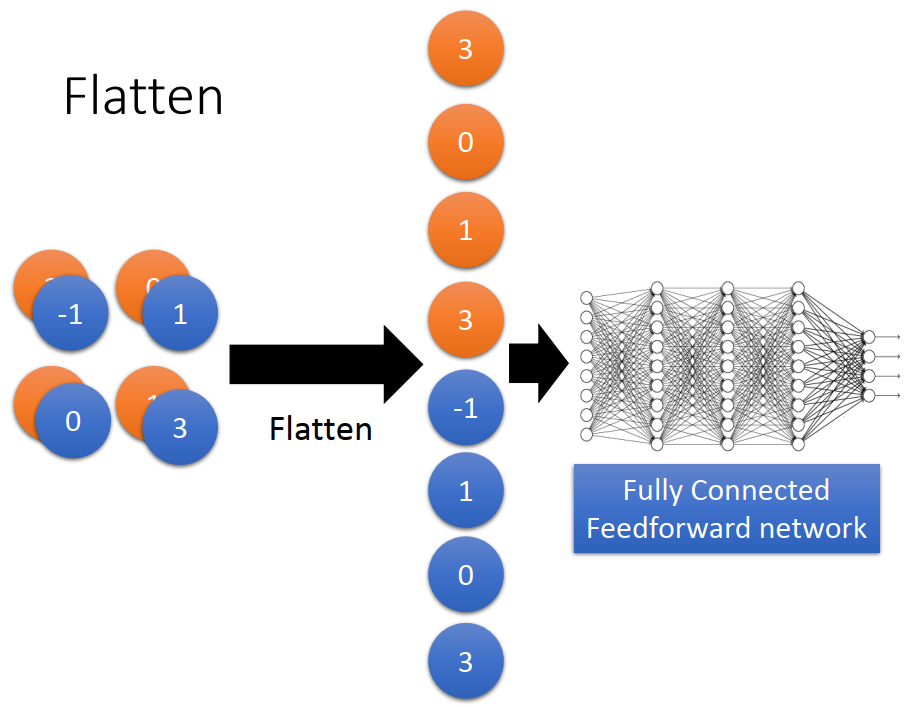
4)Flatten
将重复多次后得到的矩阵展开为一维向量,做DNN的输入。
4、如何用keras搭建一个CNN
/**************学过python和keras之后再来加***************/