非阻塞算法:使用底层的原子机器指令(例如比较并交换指令)代替锁来确保数据在并发访问中的一致性
- 应用于在操作系统和JVM中实现线程 / 进程调度机制、垃圾回收机制以及锁和其他并发数据结构
- 可伸缩性和活跃性上拥有巨大的优势,不存在死锁
原子变量:提供了与volatile类型变量相同的内存语义,并支持原子的更新操作,比基于锁的方法提供更高的可伸缩性
一、锁的劣势
锁:独占方式访问共享变量,对变量的操作对其他获得同一个锁的线程可见
劣势:
- 请求锁失败,一些线程将被挂起并且在稍后恢复运行
- 恢复执行时必须等其他的线程的执行时间片用完
- 挂起和恢复的开销很大
- 锁竞争存在开销
- 优先级反转:被阻塞线程的优先级较高,而持有锁的线程优先级较低
Volatile更轻量级,保证可见性,不会发生山下文切换和线程调度,但没有办法完成原子操作
二、硬件对并发的支持
乐观的解决方法:借助冲突检查机制来判断在更新过程中是否存在来自其他线程的干扰,如果存在,这个操作将失败,并且可以重试(也可以不重试)
针对多处理器操作而设计的处理器中提供了一些特殊指令:支持原子的测试并设置(Test-and-Set),获取并递增(Fetch-and-Increment)以及交换(Swap)等指令
1、比较并交换CAS——乐观技术
CAS的含义是:“我认为V的值应该为A,如果是,那么将V的值更新为B,否则不修改并告诉V的值实际为多少”
1 public class SimulatedCAS {//模拟CAS操作 2 @GuardedBy("this") private int value; 3 4 public synchronized int get() { return value; } 5 6 public synchronized int compareAndSwap(int expectedValue, 7 int newValue) {//相当于处理器的CAS原子化操作 8 int oldValue = value; 9 if (oldValue == expectedValue) 10 value = newValue; 11 return oldValue; 12 } 13 14 public synchronized boolean compareAndSet(int expectedValue, 15 int newValue) { 16 return (expectedValue 17 == compareAndSwap(expectedValue, newValue)); 18 } 19 }
当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其他线程都将失败(而不是挂起)
竞争中失败,并且可以再次尝试,也可以放弃
由于CAS能检测到来自其他线程的干扰(干扰结果为失败),因此即使不使用锁也能够实现原子的读-改-写操作序列
2、非阻塞的计数器
- 1 @ThreadSafe 2 public class CasCounter { 3 private SimulatedCAS value; 4 5 public int getValue() { 6 return value.get(); 7 } 8 9 public int increment() { 10 int v; 11 do { 12 v = value.get(); 13 } 14 while (v != value.compareAndSwap(v, v + 1)); 15 return v + 1; 16 } 17 }
- CasCount不会发生阻塞,如果多个线程同时更新计数器,那么可能产生失败,并执行多次重试操作
- 为避免活锁,每次失败时,可以等一段时间再执行
- 当竞争程度不高时,CasCount性能远高于基于锁的计数器
3、JVM对CAS的支持
在原子变量类(例如java.util.concurrent.atomic中的AutomicXxx)中使用了这些底层的JVM支持为数字类型和引用类型提供了一种高效的CAS操作,而在java.util.concurrent中的大多数类在实现时则直接或间接地使用了这些原子变量类
三、原子变量类
原子变量比锁的粒度更细,量级更轻,直接利用硬件对并发的支持,性能比锁更好。原子变量相当于一种泛化的volatile变量,能够支持原子的和有条件的读-改-写操作
共有12个原子变量类,可分为4组:标量类(Scalar)、更新器类、数组类以及复合变量类
- 标量类(AtomicInteger、AutomicLong、AutomicBoolean以及AtomicReference):模拟其他基本类型的原子变量,可以将short或byte等类型与int类型进行转换,以及使用floatToIntBits或doubleToLongBits来转换浮点数
- 原子数组类(AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray<E>):volatile类型的数组仅在数组引用上具有volatile语义,而在其元素则没有
基本类型的包装类是不可修改的,而原子变量类是可修改的
1、原子变量是一种“更好的volatile”


1 public class CasNumberRange { 2 private static class IntPair{ 3 // 不变性条件: lower <= upper 4 final int lower; 5 final int upper; 6 7 public IntPair(int lower, int upper) { 8 this.lower = lower; 9 this.upper = upper; 10 } 11 } 12 13 private AtomicReference<IntPair> values = new AtomicReference<>(); 14 15 public int getLower(){ 16 return values.get().lower; 17 } 18 19 public int getUpper(){ 20 return values.get().upper; 21 } 22 23 public void setLower(int i){ 24 while (true){ 25 IntPair oldv = values.get(); 26 if (i > oldv.upper){ 27 throw new IllegalArgumentException("lower can't > upper"); 28 } 29 IntPair newv = new IntPair(i, oldv.upper); 30 if (values.compareAndSet(oldv, newv)){ 31 return; 32 } 33 } 34 } 35 }
实现对多变量的非阻塞的先检查在执行操作
2、性能比较:锁与原子变量
1 public class ReentrantLockPseudoRandom extends PseudoRandom { 2 private final Lock lock = new ReentrantLock(false); 3 private int seed; 4 5 ReentrantLockPseudoRandom(int seed) { 6 this.seed = seed; 7 } 8 9 public int nextInt(int n) { 10 lock.lock(); 11 try { 12 int s = seed; 13 seed = calculateNext(s); 14 int remainder = s % n; 15 return remainder > 0 ? remainder : remainder + n; 16 } finally { 17 lock.unlock(); 18 } 19 } 20 }
1 public class AtomicPseudoRandom extends PseudoRandom { 2 private AtomicInteger seed; 3 4 AtomicPseudoRandom(int seed) { 5 this.seed = new AtomicInteger(seed); 6 } 7 8 public int nextInt(int n) { 9 while (true) { 10 int s = seed.get(); 11 int nextSeed = calculateNext(s); 12 if (seed.compareAndSet(s, nextSeed)) { 13 int remainder = s % n; 14 return remainder > 0 ? remainder : remainder + n; 15 } 16 } 17 } 18 }
如果线程本地的计算量较少,那么在锁和原子变量上的竞争将非常激烈。如果线程本地的计算量较多,那么在锁和原子变量上的竞争会降低
在高度竞争的情况下,锁的性能将超过原子变量的性能(失败重试导致更激烈的竞争),但在更真实的情况下,原子变量的性能将超过锁的性能
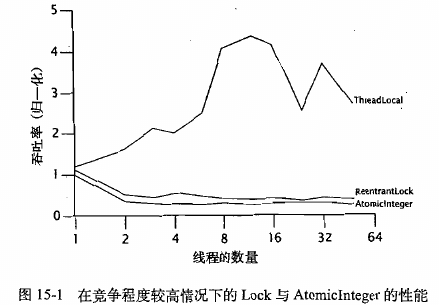
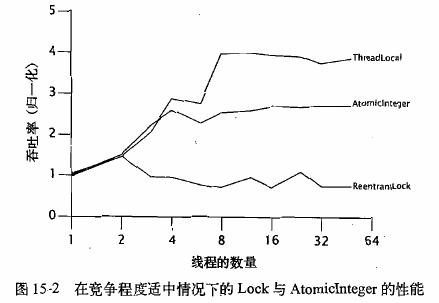
四、非阻塞算法——一个线程的失败或挂起不会导致其他线程也失败或挂起
无锁算法——算法的每个步骤中都存在某个线程能够执行下去
在非阻塞算法中通常不会出现死锁和优先级反转问题(但可能会出现饥饿和活锁问题,因为在算法中会反复地重试)
创建非阻塞算法的关键在于,找出如何将原子修改的范围缩小到单个变量上,同时还要维护数据的一致性
非阻塞算法的特性:某项工作的完成具有不确定性,必须重新执行
非阻塞算法中能确保线程安全性,因为compareAndSet像锁定机制一样,既能提供原子性,又能提供可见性
1、非阻塞的栈——Treiber算法
1 public class ConcurrentStack<E> {//非阻塞栈 2 //栈顶元素,永远指向栈顶,入栈与出栈都只能从栈顶开始 3 AtomicReference<Node<E>> top = new AtomicReference<Node<E>>(); 4 5 //非阻塞的入栈操作 6 public void push(E item) { 7 //创建新的元素 8 Node<E> newHead = new Node<E>(item); 9 Node<E> oldHead; 10 do { 11 //当前栈顶元素,也即这次操作的基准点,操作期间不能改变 12 oldHead = top.get(); 13 newHead.next = oldHead;//让新元素成为栈顶 14 //如果基准点被其他线程修改后就会失败,失败后再重试 15 } while (!top.compareAndSet(oldHead, newHead)); 16 } 17 18 //非阻塞的出栈操作 19 public E pop() { 20 Node<E> oldHead; 21 Node<E> newHead; 22 do { 23 oldHead = top.get();//取栈顶元素,即基准点 24 if (oldHead == null) 25 return null; 26 newHead = oldHead.next; 27 //如果基准点没有变化,则成功 28 } while (!top.compareAndSet(oldHead, newHead)); 29 return oldHead.item;//返回栈顶元素值 30 } 31 32 //节点元素 33 private static class Node<E> { 34 public final E item; 35 public Node<E> next; 36 37 public Node(E item) { 38 this.item = item; 39 } 40 } 41 }
2、非阻塞的链表
一个链表队列比栈更加复杂,因为它需要支持首尾(从尾插入,从首取出)的快速访问,为了实现,它会维护独立的队首指针和队尾指针。
有两个指针指向位于尾部的节点:当前最后一个元素的next指针,以及尾节点。当成功地插入一个新元素时,这两个指针都需要采用原子操作来更新。
1 public class LinkedQueue<E> { 2 private static class Node<E> { 3 final E item; 4 final AtomicReference<Node<E>> next; 5 6 public Node(E item, Node<E> next) { 7 this.item = item; 8 this.next = new AtomicReference<Node<E>>(next); 9 } 10 } 11 12 //哑元,用于区分队首与队尾,特别是在循环队列中 13 private final Node<E> dummy = new Node<E>(null, null); 14 private final AtomicReference<Node<E>> head = new AtomicReference<Node<E>>( 15 dummy);//头指针,出队时用 16 private final AtomicReference<Node<E>> tail = new AtomicReference<Node<E>>( 17 dummy);//尾指针,入队时用 18 19 public boolean put(E item) {//入队 20 Node<E> newNode = new Node<E>(item, null); 21 while (true) {//在除尾插入新的元素直到成功 22 //当前队尾元素 23 Node<E> curTail = tail.get(); 24 /* 25 * 当前队尾元素的next域,一般为null,但有可能不为null, 26 * 因为有可能其他线程已经上一语句与下一语句间添加了新 27 * 的元素,即此时队列处于中间状态 28 */ 29 Node<E> tailNext = curTail.next.get(); 30 /* 31 * 再一次检查上面两行语句的操作还是否有效,因为很有可在此刻尾指针已经 32 * 向后移动了(比如其他线程已经执行了B 或 D 处语句),所以下面的操作都 33 * 是要基于尾节点是curTail才可以。(想了一下,其实这里不需要这个判断 34 * 也是可以的,因为下面执行到 B 或 C 时自然会失败,这样做只是为了提高 35 * 成功的效率) 36 */ 37 if (curTail == tail.get()) { 38 39 if (tailNext != null) {// A 40 /* 41 * 队列处于中间状态,尝试调整队尾指针,这里 42 * 需要使用compareAndSet原子操作来进行,因为 43 * 有可以在进行时 D 处已经调整完成 44 */ 45 tail.compareAndSet(curTail, tailNext);// B 46 } else { 47 // 队列处于稳定状态,尝试在队尾插入新的节点 48 if (curTail.next.compareAndSet(null, newNode)) {// C 49 /* 50 * 插入尝试成功,再开始尝试调整队尾指针,这里完全 51 * 有可能不需要再调整了,因为上面 B 行已经帮这里调 52 * 整过了 53 */ 54 tail.compareAndSet(curTail, newNode);// D 55 return true; 56 } 57 } 58 } 59 } 60 } 61 }
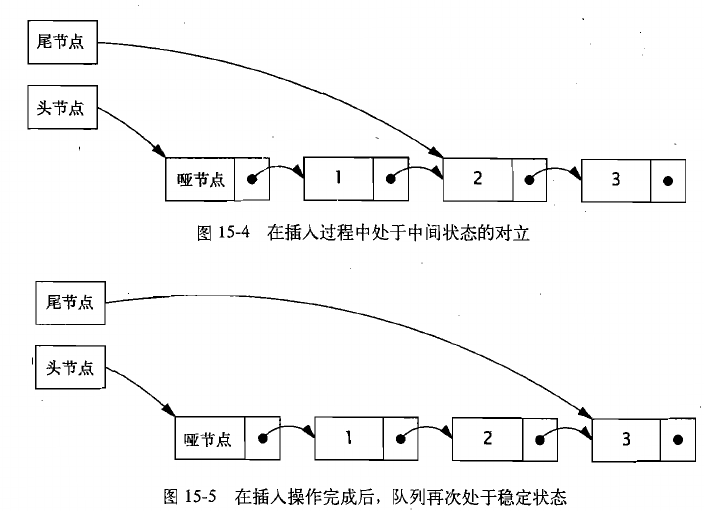
原理:对队列处于稳定状态时,尾节点的next域将为空,如果队列处于中间状态,那么tail.next将为非空。
LinkedQueue.put方法在插入新元素之前,将首先检查队列是否处于中间状态(步骤A),如果是,那么有另一个线程正在插入元素(在步骤C和D之间)。此时线程不会等待其他线程执行完成,而是帮助它完成操作,并将尾节点向前推进一个节点(步骤B)。然后,它将重复执行这种检查,以免另一个线程已经开始插入新元素,并继续推进尾节点,直到它发现队列处于稳定状态后,才会开始执行自己的插入操作。
由于步骤C中的CAS将把新节点链接到队列尾部,因此如果两个线程同时插入元素,那么这个CAS将失败。在这样的情况下,并不会造成破坏:不会发生任何变化,并且当前的线程只需重新读取尾节点并再次重试。如果步骤C成功了,那么插入操作将生效,第二个CAS(步骤D)被认为是一个“清理操作”因为它既可以由执行插入操作的线程来执行,也可以由其他任何线程来执行。如果步骤D失败,那么执行插入操作的线程将返回,而不是重新执行CAS,因为不再需要重试——另一个线程已经在步骤B中完成了这个工作。这种方式能够工作,因为在任何线程尝试将一个新节点插入到队列之前,都会首先通过检查tail.next是否非空来判断是否需要清理队列。如果是,它首先会推进为尾节点(可能需要执行多次),知道队列处于稳定状态。

3、原子的域更新器
原子的域更新器类表示现有volatile域的一种基于反射的“视图”,从而能够在已有的volatile域上使用CAS
private static AtomicReferenceFieldUpdater<Node, Node> nextUpdater//用来对next字段进行更新
= AtomicReferenceFieldUpdater.newUpdater(Node.class, Node.class, "next");
4、ABA问题
在某些算法中,如果V的值首先由A变成B,再由B变成A,那么仍然应该被认为是发生了变化,并需要重新执行算法中的某些步骤
解决方案:不只更新某个引用的值,而是更新两个值,包括一个引用和一个版本号