【简述】
Xml文件出了给开发者看,更多情况使用程序读取xml文件里的内容,这叫做xml解析。
根据解析方式分为:DOM解析 和 SAX解析
【解析工具】
(一). 使用DOM解析原理的工具:
1.JAXP(Oracle-Sun公司官方)
2.JDOM工具(非官方)
3.Dom4J工具(非官方,使用者最多,也是SSH三大框架默认读取xml的工具)
(二). 使用SAX解析原理的工具:
1.SAX官方解析工具(Oracle-Sun官方)
....
【什么是DOM解析】
DOM解析原理:Xml解析器一次性把整个Xml文档加载进内存,然后在内存中构建一个Document对象树,通过Document对象,得到树上的节点对象,通过节点对象访问(操作)到Xml文档的内容。
【使用dom4j读取xml文件】
【工程截图】
【提示】

【person.xml】
<?xml version="1.0" encoding="UTF-8"?> <students> <student id="88888" phone="15888888888" sex="男"> <name>张三</name> <age>18</age> <school>HDU</school> </student> <student> <name>李四</name> <age>28</age> <school>ZKU</school> </student> <AAAA> <aa1>aa111</aa1> <aa2>aa222</aa2> </AAAA> <BBBB></BBBB> </students>
【1.读取节点信息】
@Test public void testNode() throws DocumentException{ //1.读取XMl文件,返回一个Document对象 SAXReader saxReader=new SAXReader(); Document doc=saxReader.read(new File("./src/person.xml")); //nodeIterator:得到当前节点的下的所有子节点对象(不会遍历孙节点及以下节点) Iterator<Node> it=doc.nodeIterator(); while(it.hasNext()){ //判断是否还有下一个元素 Node node=it.next(); //取出元素 System.out.println(node.getName()); //得到节点的名称 //System.out.println("-------"); /* * 继续取出当前节点的子节点 * 只有标签节点Element才有子节点 * 判断当前节点是否是标签节点 */ if(node instanceof Element){ Element elem=(Element) node; Iterator<Node> it2=elem.nodeIterator(); while(it2.hasNext()){ Node node2=it2.next(); System.out.println(node2.getName()); System.out.println("--------"); } } } }
【1.运行结果】

【2.遍历获取Xml文档的所有标签】
【2.1公用方法: 递归获取传入标签下的所有子节点】
/** * 【公用方法】获取传入标签下的所有子节点 */ private void getChildNodes(Element elem){ System.out.println(elem.getName()); //得到子节点 Iterator<Node> it=elem.nodeIterator(); while(it.hasNext()){ Node node=it.next(); //判断是否是标签节点 if(node instanceof Element){ Element el=(Element) node; //递归 getChildNodes(el); } } }
【2.2 testAllNode:遍历获取Xml文档的所有标签】
/** * 遍历获取Xml文档的所有标签 */ @Test public void testAllNode() throws DocumentException{ //读取Xml文件,返回Document对象 SAXReader saxReader =new SAXReader(); Document doc=saxReader.read(new File("./src/person.xml")); //得到根标签节点 在一个xml文档中,有且仅有一个根标签 Element roorElem=doc.getRootElement(); getChildNodes(roorElem); }
【2.运行结果】

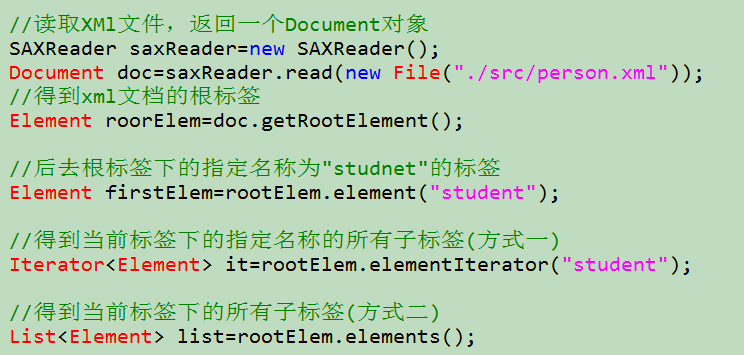
【3.获取标签名】
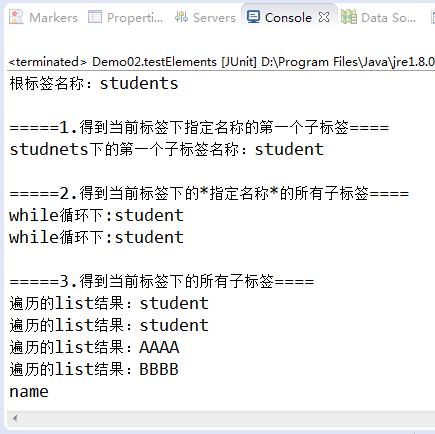
/** * 获取标签名 */ @Test public void testElements() throws DocumentException{ //读取xml文档,返回一个Document对象 SAXReader saxReader =new SAXReader(); Document doc=saxReader.read(new File("./src/person.xml")); //得到根标签 Element rootElem=doc.getRootElement(); //得到根标签名称 String name=rootElem.getName(); System.out.println("根标签名称:"+name); System.out.println(" =====1.得到当前标签下指定名称的第一个子标签===="); //得到当前标签下指定名称的第一个子标签 Element firstElem=rootElem.element("student"); System.out.println("studnets下的第一个子标签名称:"+firstElem.getName()); System.out.println(" =====2.得到当前标签下的*指定名称*的所有子标签===="); //得到当前标签下的指定名称的所有子标签 Iterator<Element> it=rootElem.elementIterator("student"); while(it.hasNext()){ Element elem=it.next(); System.out.println("while循环下:"+elem.getName()); } System.out.println(" =====3.得到当前标签下的所有子标签===="); //得到当前标签下的所有子标签 List<Element> list=rootElem.elements(); //遍历list for(Element e:list){ System.out.println("遍历的list结果:"+e.getName()); } //获取更深层次的标签(方法只能一层层的获取) Element nameElem=doc.getRootElement().element("student").element("name"); System.out.println(nameElem.getName()); //打印的标签名 }
【3.运行结果】
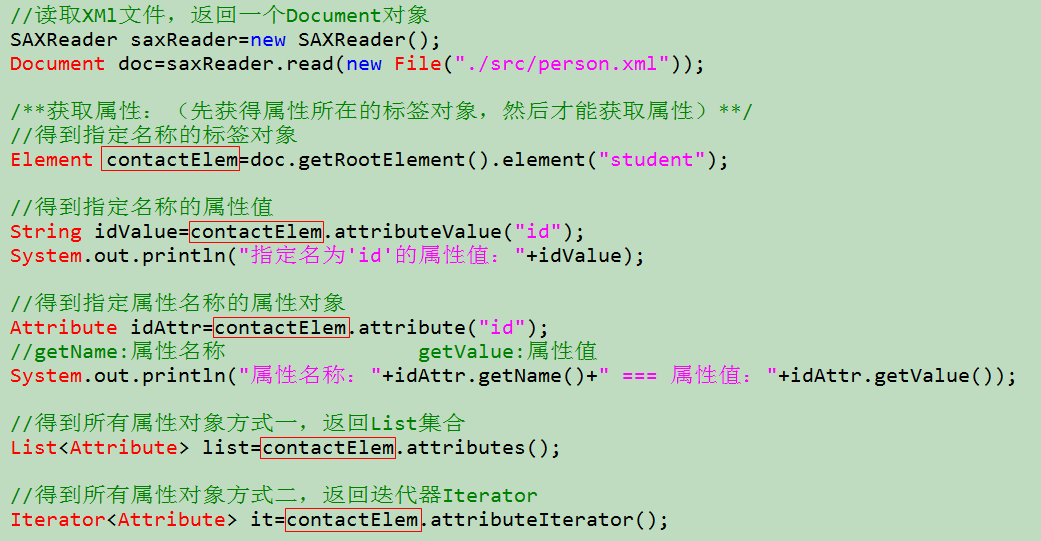
【4.获取属性值】
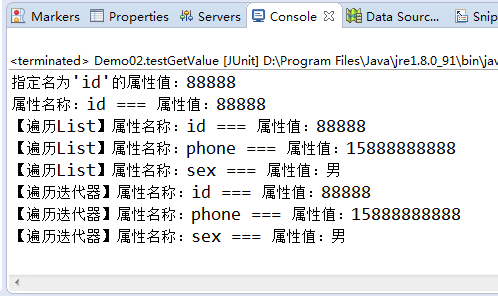
/** * 获取属性值 */ @Test public void testGetValue() throws DocumentException{ //1.读取xml文档,返回Document对象 SAXReader saxReader=new SAXReader(); Document doc=saxReader.read(new File("./src/person.xml")); /**获取属性:(先获得属性所在的标签对象,然后才能获取属性)**/ //1.得到指定名称的标签对象 Element contactElem=doc.getRootElement().element("student"); //2.得到属性 //2.1得到指定名称的属性值 String idValue=contactElem.attributeValue("id"); System.out.println("指定名为'id'的属性值:"+idValue); //2.2得到指定属性名称的属性对象 Attribute idAttr=contactElem.attribute("id"); //getName:属性名称 getValue:属性值 System.out.println("属性名称:"+idAttr.getName()+" === 属性值:"+idAttr.getValue()); //2.3 得到所有属性对象,返回List集合 List<Attribute> list=contactElem.attributes(); //遍历属性 for(Attribute attr:list){ System.out.println("【遍历List】属性名称:"+attr.getName()+" === 属性值:"+attr.getValue()); } //2.3得到所有属性对象,返回迭代器Iterator Iterator<Attribute> it=contactElem.attributeIterator(); while(it.hasNext()){ Attribute attr=it.next(); System.out.println("【遍历迭代器】属性名称:"+attr.getName()+" === 属性值:"+attr.getValue()); } }
【4.运行结果】
【5.获取标签体内容(文本)】
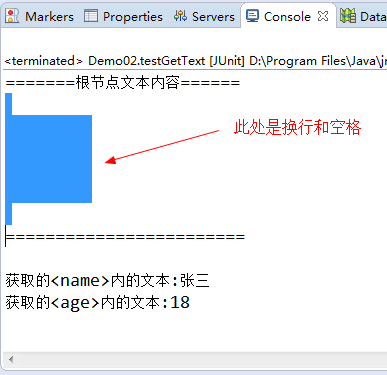
/** * 获取文本 */ @Test public void testGetText() throws DocumentException{ //读取Xml文档,返回Document对象 SAXReader saxReader=new SAXReader(); Document doc=saxReader.read(new File("./src/person.xml")); /** * 注意:空格和换行也是xml的文本内容 */ String contact=doc.getRootElement().getText(); //获取根节点的文本内容 System.out.println("=======根节点文本内容======"); System.out.println(contact); System.out.println("======================== "); //获取文本值方式一(先获取标签,再获取标签上的文本) Element nameElem =doc.getRootElement().element("student").element("name"); //获取学生姓名 System.out.println("获取的<name>内的文本:"+nameElem.getText()); //方式二 String ageText=doc.getRootElement().element("student").elementText("age"); System.out.println("获取的<age>内的文本:"+ageText); }
【5.运行结果】
【小结】
1.获取节点对象 Node

2.获取标签 Element
3.获取属性
4.获取文本
