最近在写一个问答功能,类似于评论,几番找资料才有点感觉(主要是太菜了),为了加深印象就单独抽出来记下笔记,然后这篇写完就开始SpringBoot的复习了
1. 说明
网上看到有三种类型的评论,按照笔者的理解记下了过程(可能理解错了,望大神指出),所以列出的是笔者的理解,下面以模拟博客评论的场景来说明,(这些类型是笔者形容的,并没有这个词),总觉得很慌理解错了,希望大家评论指正
测试环境:SSM、JDK1.8
2. 没有互动型
这种类型只能评论,评论之间没有互动,类似于问答形式。提出问题,然后回答,一对多关系。这些回答之间没有任何联系

从图可以简单看出,这种类型的评论是比较简单的,设计一个评论表,其内部添加一个挂载的博客id字段即可
数据库设计
CREATE TABLE `comment` (
`comment_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '评论的id',
`nickname` varchar(255) DEFAULT NULL COMMENT '评论者的昵称',
`content` varchar(255) DEFAULT NULL COMMENT '评论的内容',
`blog_id` int(11) DEFAULT NULL COMMENT '评论挂载的博客id',
PRIMARY KEY (`comment_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
这里主要说明评论功能的实现,表会尽可能简单的设计,像点赞,分页,图像这些不再考虑范围内,另一个blog表也没有给出,可以自行理解
查询语句
SELECT * FROM comment WHERE blog_id = #{blog_id}
传入需要查询评论的博客id即可,将查询的内容放入其评论区完成,这种评论较为简单,评论之间没有互动,适用于少数场景(像笔者这次写的问答功能,但该问答有非法关键词,官方回答,锁定,审核,等功能,也不简单)
3. 套娃型
这种类型笔者见得比较少,因为像树状,评论多起来层级结构复杂,不人性化
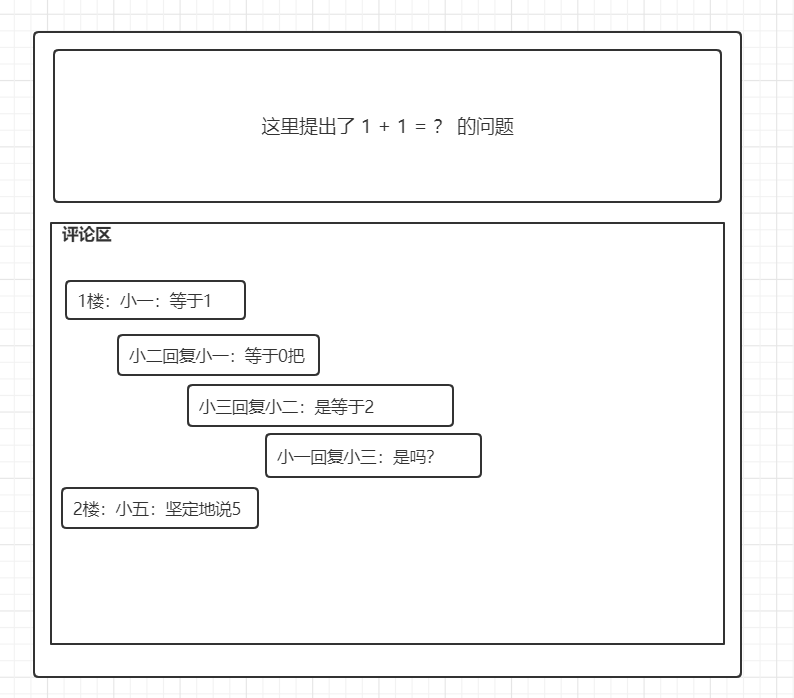
小一评论博客,小二紧接着回复小一的评论,小三又回复小二的评论,小一又回了小三的评论,像俄罗斯套娃层层套
数据库设计
这里笔者用单表来实现,笔者称评论与回复这二者为父子关系,评论为父级,回复为子级,这种关系在数据里增多一个parent_id字段来维护,默认为-1,表示没有父级
CREATE TABLE `blog` (
`comment_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '评论的id',
`nickname` varchar(255) DEFAULT NULL COMMENT '评论者的昵称',
`content` varchar(255) DEFAULT NULL COMMENT '评论的内容',
`blog_id` int(11) DEFAULT NULL COMMENT '评论挂载的博客id',
`parent_id` int(11) DEFAULT '-1' COMMENT '父级评论',
PRIMARY KEY (`comment_id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
博客评论多起来的时,可用blog_id作为索引(不想增加与功能无关内容,假装没看到)
Dto、映射文件、Service层
由于使用mybatis,所以把映射文件放上来一目了然
public class CommentDTO {
private int id;
private String nickname;
private String content;
private List<CommentDTO> children; // 存放子级的回复
// getter / setter
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.howl.dao.CommentDao">
<resultMap id="commentDTOMap" type="com.howl.dto.CommentDTO">
<id property="id" column="comment_id"></id>
<result property="nickname" column="nickname"></result>
<result property="content" column="content"></result>
<!-- 这里笔者使用分步查询,入参使用了@Param注解,名字有稍微变化 -->
<association property="children"
select="com.howl.dao.CommentDao.selectCommentById" column="{blogId=blog_id,parentId=comment_id}"
fetchType="lazy">
</association>
</resultMap>
<select id="selectCommentById" resultMap="commentDTOMap">
SELECT comment_id,nickname,content,blog_id,parent_id FROM blog WHERE blog_id = #{blogId} AND parent_id = #{parentId}
</select>
</mapper>
@Service
public class CommentService {
@Autowired
CommentDao commentDao;
public List<CommentDTO> selectCommentById(int blogId) {
// 默认传入-1,即找出父级评论先
return commentDao.selectCommentById(blogId, -1);
}
}
这样查询出来的语句是层层套的,不信你看
[{
"id": 1,
"nickname": "小二",
"content": "不错",
"children": [{
"id": 2,
"nickname": "小三",
"content": "支持",
"children": [{
"id": 3,
"nickname": "小四",
"content": "6666",
"children": []
}]
}]
}, {
"id": 4,
"nickname": "小五",
"content": "一般般把",
"children": []
}]
4. 两层型
即只有两层关系,比单层多了互动功能,比套娃简洁,看图
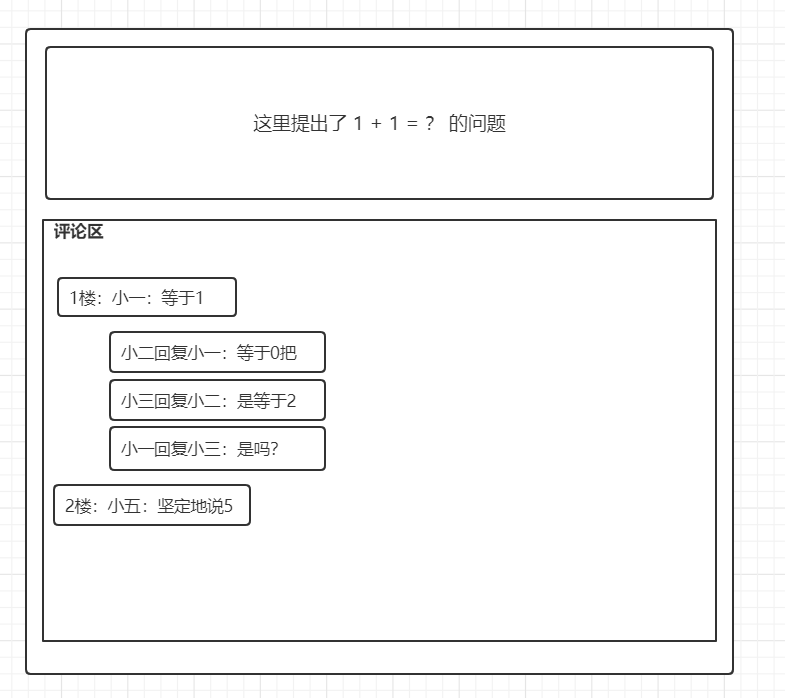
这种看起来舒服多了,怎么做到的呢? 其实和套娃型使用的是同一个表与查询,映射文件都不用改,不同之处在于查询出来的后期的逻辑处理,很多时候跨库也是如此,查完数据再进行逻辑的处理
处理逻辑
由套娃型转变成二层型
套娃的示意图:
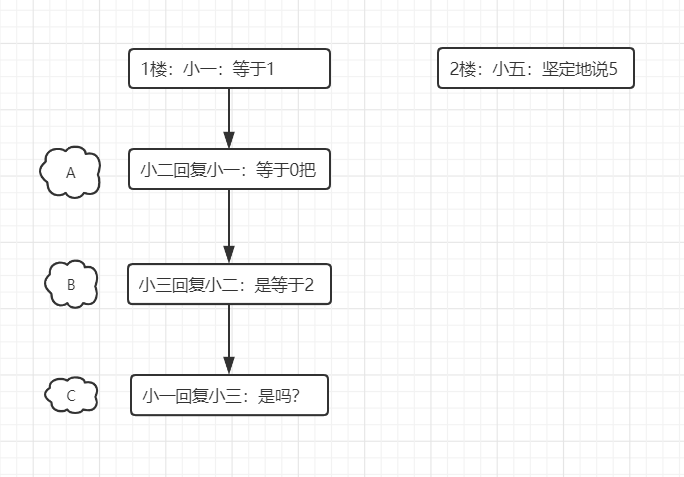
- 1楼和2楼同级,属于父级评论,直接挂载的博客下
- A属于1楼评论的子级
- B属于A的子级
- C属于B的子级
二层的示意图:
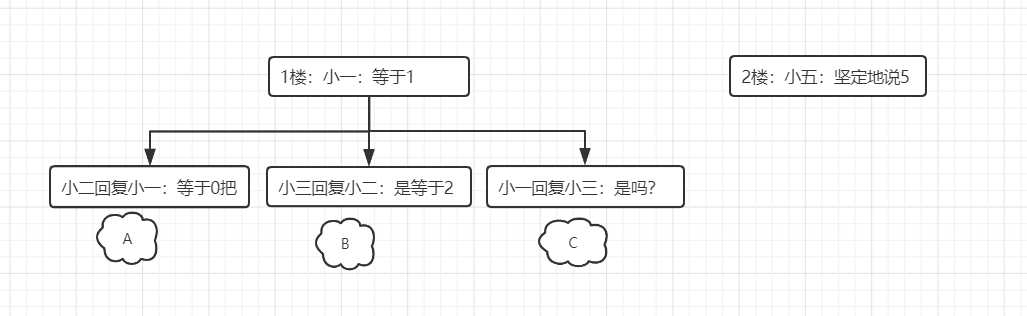
A,B,C 属于同级,直接属于1楼评论的子级
处理逻辑代码
业务逻辑在Service层,DTT测试
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class CommentServiceTest {
@Autowired
CommentDao commentDao;
@Test
public void selectCommentById() {
// 默认传入-1,找出父级的评论,假装查看博客id为7的评论
List<CommentDTO> comments = commentDao.selectCommentById(7, -1);
// 这里将套娃关系处理为二层关系
System.out.println(JSON.toJSONString(findParent(comments)));
}
// 处理每个父级评论的子级及其嵌套子级
public List<CommentDTO> findParent(List<CommentDTO> comments) {
for (CommentDTO comment : comments) {
// 防止checkForComodification(),而建立一个新集合
ArrayList<CommentDTO> fatherChildren = new ArrayList<>();
// 递归处理子级的回复,即回复内有回复
findChildren(comment, fatherChildren);
// 将递归处理后的集合放回父级的孩子中
comment.setChildren(fatherChildren);
}
return comments;
}
public void findChildren(CommentDTO parent, List<CommentDTO> fatherChildren) {
// 找出直接子级
List<CommentDTO> comments = parent.getChildren();
// 遍历直接子级的子级
for (CommentDTO comment : comments) {
// 若非空,则还有子级,递归
if (!comment.getChildren().isEmpty()) {
findChildren(comment, fatherChildren);
}
// 已经到了最底层的嵌套关系,将该回复放入新建立的集合
fatherChildren.add(comment);
// 容易忽略的地方:将相对底层的子级放入新建立的集合之后
// 则表示解除了嵌套关系,对应的其父级的子级应该设为空
comment.setChildren(new ArrayList<>());
}
}
}
注释清楚地说明了处理逻辑,但这种做法显然不是很好的,可以有更优雅的处理方法,只是笔者还没想到
输出结果
[{
"id": 1,
"nickname": "小二",
"content": "不错",
"children": [{
"id": 3,
"nickname": "小四",
"content": "6666",
"children": []
}, {
"id": 2,
"nickname": "小三",
"content": "支持",
"children": []
}]
}, {
"id": 4,
"nickname": "小五",
"content": "一般般把",
"children": []
}]
后记:后期逻辑处理部分花了大半天没滤清关系,没想到第二天醒来随手两分钟就搞定。原因:增强for底层使用了迭代器,修改结构会有快速失败机制、还有处理二层关系的时候,最底层往上解除套娃关系时,记得将孩子置空