最近老是能遇到零拷贝的问题,对于操作系统这块总时很怕,现在抽出时间来攻关
1. 直接内存
先铺垫一些必要的知识点,然后再由浅入深地去认识零拷贝
1.1 什么是直接内存
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是《Java虚拟机规范》中定义的内存区域。但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError异常出现 ——《深入理解Java虚拟机》
显然,从上面得知本机直接内存的分配不会受到Java堆大小的限制,但这里要注意直接内存也是物理内存的一部分,也受到真实内存的限制,所以当直接内存占用过多时,使Java堆分配不到足够的内存空间也就抛出OOM异常了
因此我们要限制直接内存的大小 -XX:MaxDirectMemorySize,当达到指定大小后会触发 Full GC
1.2 如何使用直接内存
在 JDK1.4 中新加入了NIO,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O方式,它可以使用Native函数直接分配堆外内存,然后通过一个存储在Java堆里面的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据 ——《深入理解Java虚拟机》
我们可用 NIO 中的缓冲区(Buffer)来使用直接内存,不幸的是直接内存只支持 Byte 类型的缓冲区,所以我们只能使用 ByteBuffer类型的缓冲区了
其中:
ByteBuffer 是普通的缓冲区,还是在Java堆中分配空间的
DirectByteBuffer 才是我们所找的,其父类是 MappedByteBuffer(内存映射),再父类才是 ByteBuffer,是在直接内存分配空间
创建方法
// allocateDirect()本质是 return new DirectByteBuffer(capacity);
// 因 DirectByteBuffer 的构造方法是私有的才需这样返回
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024);
1.3 为什么使用直接内存
使用直接内存是为了提高读写性能,适用于经常读写的场景,下面用例子说明:写入读出1000个整数,进行10万次
1.3.1 不使用直接内存
final int EVERY_TIME_COUNT = 1000;
final int TOTAL_TIME_COUNT = 100000;
long starTime = System.currentTimeMillis();
// 1000个整数占用32000个byte
ByteBuffer byteBuffer = ByteBuffer.allocate(32000);
for (int i = 0; i < TOTAL_TIME_COUNT; i++) {
for (int j = 1; j < EVERY_TIME_COUNT; j++) {
byteBuffer.putInt(j);
}
byteBuffer.flip();
for (int j = 1; j < EVERY_TIME_COUNT; j++) {
byteBuffer.get();
}
byteBuffer.clear();
}
System.out.println("不用直接内存的毫秒是:" + (System.currentTimeMillis() - starTime));
-----------------------------------------------------------------------------------------------
// 250ms
1.3.2 使用直接内存
final int EVERY_TIME_COUNT = 1000;
final int TOTAL_TIME_COUNT = 100000;
long starTime = System.currentTimeMillis();
// 1000个整数占用32000个byte
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(32000);
for (int i = 0; i < TOTAL_TIME_COUNT; i++) {
for (int j = 1; j < EVERY_TIME_COUNT; j++) {
byteBuffer.putInt(j);
}
byteBuffer.flip();
for (int j = 1; j < EVERY_TIME_COUNT; j++) {
byteBuffer.get();
}
byteBuffer.clear();
}
System.out.println("直接内存的毫秒是:" + (System.currentTimeMillis() - starTime));
-----------------------------------------------------------------------------------------------
// 160ms
1.3.3 创建销毁的性能
创建销毁直接内存的消耗远远大于普通的ByteBuffer
final int TOTAL_COUNT = 100000;
long starTime = System.currentTimeMillis();
for (int i = 0; i < TOTAL_COUNT; i++) {
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
}
System.out.println("不用直接内存的毫秒是:" + (System.currentTimeMillis() - starTime));
-----------------------------------------------------------------------------------------------
// 38ms
final int TOTAL_COUNT = 100000;
long starTime = System.currentTimeMillis();
for (int i = 0; i < TOTAL_COUNT; i++) {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024);
}
System.out.println("不用直接内存的毫秒是:" + (System.currentTimeMillis() - starTime));
-----------------------------------------------------------------------------------------------
// 145ms
1.3.4 综上使用总结
缺点:
- 创建销毁 DirectByteBuffer 更消耗性能
- 内存泄漏排查难度大了
- 只能用byte[] 数组来接收
优点:
- 避免堆与直接内存的来回复制提高性能
- 可以做JVM进程间共享
2. 零拷贝
为什么使用直接内存就能如此提高读写性能?因为使用了零拷贝技术。心心念的零拷贝终于出现了,还是老话,先进行铺垫,然后才轮到零拷贝的内容(笔者最怕操作系统,所以这方面的知识讲得会细一些)
2.1 内存
硬盘与CPU的速度差距太大,当CPU处理完数据,硬盘还没把数据准备好,使CPU处于空闲状态,严重拉低了CPU的处理性能。那么我们在二者中间增加了内存(速度介于硬盘和CPU之间)来进行平衡,这样我们就得先将数据从硬盘写入内存,然后CPU才去内存读取数据
2.2 内核态、用户态
内核态:可执行任何指令,访问所有寄存器和存储区
用户态:只能执行和访问特定的指令和寄存器
区分内核态,用户态主要是为了系统安全,因为有些指令会危害系统(清内存,设置时钟),这些指令只允许操作系统及其相关模块使用。当用户需要使用这些功能时,调用内核提供的API,陷入内核(即切换成内核态),让内核去执行
举例32位的操作系统,最大支持4G大小的线程,其中的3G大小是用户使用的(用来执行我们写的普通代码),剩下的1G分配给了内核(而且这分配的1G大小是共享的,存放了内核的代码和内核的功能模块)。当执行自己写的代码时则使用分配的3G空间,当调用内核API时(比如文件操作,网络传输等),切换成内核态(转去共享的内核空间,去执行内核代码),就是去使用所分配的1G空间
用户态切换内核态时,因为二者属于不同的内存空间,那么对线程的大量上下文环境进行保存
内核态切换用户态时,也要对这些上下文环境进行还原,这是一个十分耗能的操作
2.3 内核、用户、硬盘缓冲区
这些缓冲区有什么作用呢?我们使用ByteBuffer时都要先开辟一块空间,目的是为了不用一次又一次的传输4个字节(32位系统),而是填满一个缓冲区大小,然后再一次性传输数据。否则用户读取硬盘文件,一次就4个字节,那得读取多少次,进行多少次用户态、内核态的切换
2.4 传统的数据交互
举例Web服务器下的传统数据交互,数据从硬盘到网卡

读数据过程:
- Web服务器要读取硬盘数据(数据库操作),调用read()从用户态切换到内核态
- CPU将数据从硬盘缓冲区拷贝到内核缓冲区
- CPU将数据从内核缓冲区拷贝到服务器缓冲区
- CPU完成拷贝,read()返回从内核态切换回用户态
写数据过程:
- Web服务器要往网卡写数据(response响应),调用write()从用户态切换到内核态
- CPU将数据从服务器缓冲区拷贝到套接字缓冲区
- CPU将数据从套接字缓冲区拷贝到网卡缓冲区
- CPU完成拷贝,write()返回从内核态切换回用户态
综上:
- 读过程有2次状态切换、2次CPU拷贝
- 写过程有2次状态切换、2次CPU拷贝
在传统模式下,CPU负责了4次的数据拷贝,浪费了CPU的时间片,那么就出现了下面的DMA
2.5 DMA
直接内存访问,是一种硬件设备可绕开CPU独立直接访问内存。所以有了DMA在一定程度上解放了CPU,把之前CPU的杂活让硬件直接自己做了,提高了CPU效率,增添了DMA的流程图就变成下面这样:
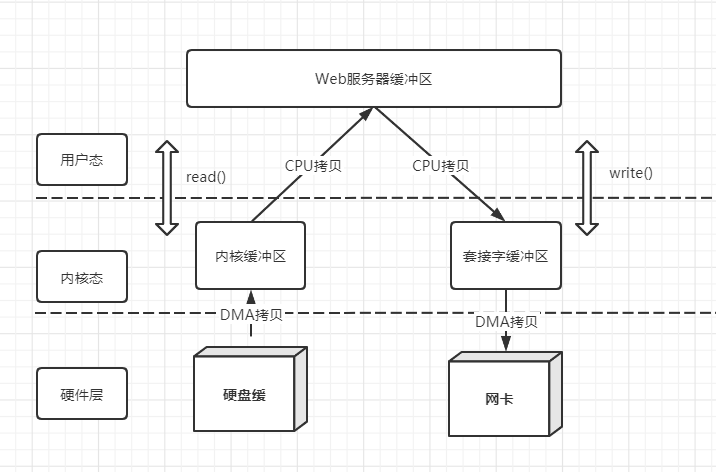
综上:
- 读过程有2次状态切换、1次DMA拷贝、1次CPU拷贝
- 写过程有2次状态切换、1次DMA拷贝、1次CPU拷贝
增添了DMA硬件,总计还是有4次状态切换,2次的CPU拷贝,有优化空间,那么此时零拷贝就出现了
2.6 零拷贝
零拷贝可以减少CPU拷贝和状态切换的次数,这样显然可以提高性能
其实现方式有:(顺便提一下NIO的直接内存使用的是mmap方式)
- mmap + write
- sendFile
- sendFile + DMA收集
- splice
2.6.1 mmap
mmap是Linux提供的一种内存映射文件机制,可以将内核缓冲区和用户缓冲区的部分空间实现共享,这样可以减少一次用户态与内核态的CPU拷贝(总计4次状态切换,2次DMA拷贝,1次CPU拷贝)

2.6.2 sendFile
sendFile建立了两个文件间的传输通道,一个函数完成mmap+write的功能,可以减少两次状态切换。(总计两次状态切换,2次DMA拷贝,1次CPU拷贝)
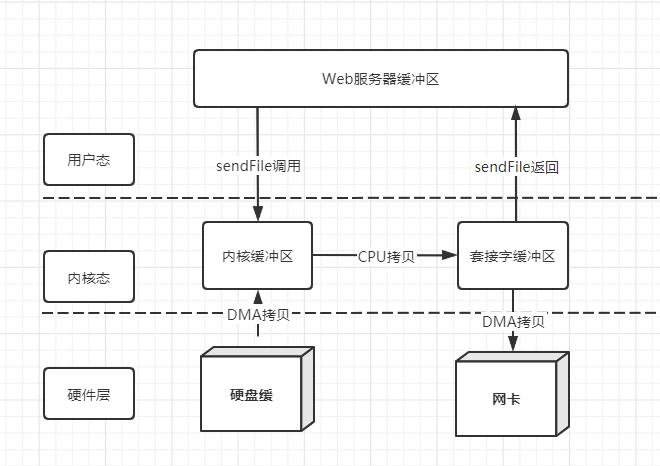
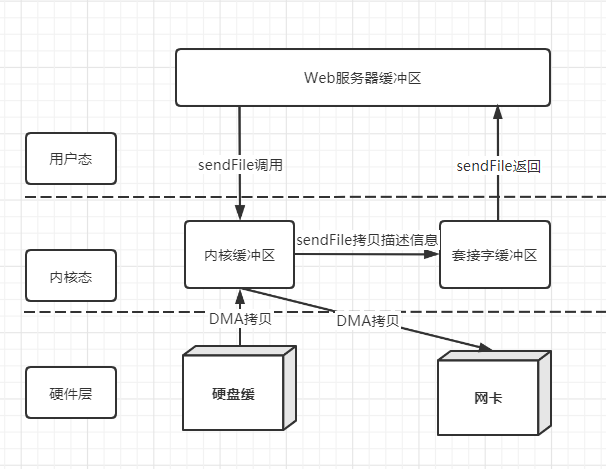
2.6.3 sendFile + DMA收集
sendFile将内核空间缓冲区中数据的描述信息拷贝到套接字缓冲区中
DMA控制器根据套接字缓冲区的描述信息,将数据从内核缓冲区直接拷贝到网卡
可以减少一次CPU拷贝(总计2次状态切换,2次DMA拷贝,0次CPU拷贝)
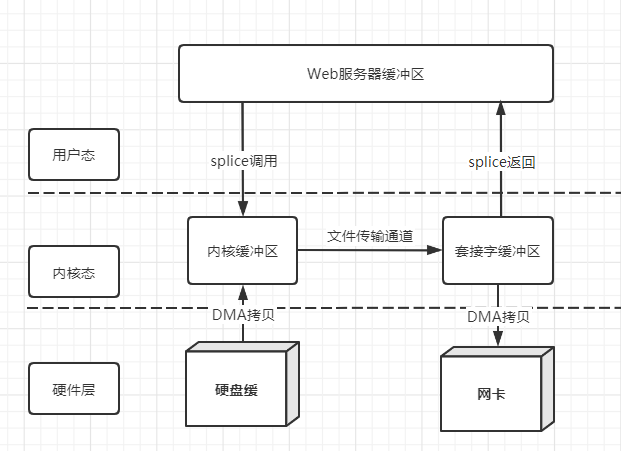
2.6.4 splice
在内核缓冲区和套接字缓冲区之间建立管道来传输数据,免去了CPU拷贝(总计两次状态切换,2次DMA拷贝,0次CPU拷贝)
3. 总结
在网络应用中经常涉及到读写过程,而读写过程又要多次状态切换和CPU拷贝,这是一个十分耗能的操作
为了提高读写性能,零拷贝技术出现了,其减少了状态切换的次数,与避免了CPU拷贝,大大提高了读写性能
在Netty这样高性能网络通信框架中,也是经常读写的,所以其底层也涉及到了零拷贝技术
缺点:
读过程中要将数据拷贝到用户缓冲区我们才能进行修改的,而缺失这一环(直接拷贝到套接字缓冲区或网卡)那么我们就不能对数据进行修改
参考
《操作系统》
《深入理解Java虚拟机》