实践:用keras训练一个MLP用于MNIST数据集
总体思路:
- 数据预处理
- 构建神经网络模型
- 训练模型
- 验证模型的泛化能力,并调节超参数
1.数据预处理
- keras自带了MNIST数据集的例子,因此使用mnist.load_data读取数据集。
- x代表数据,y代表标签,数据的大小为(数据量,28,28)。由于我们采用多层感知机,因此输入数据应该是1维,即28*28=784,因此首先将数据维度变换为784
- 将数据标准化,每个像素均除以255
- 原数据中标签为0-9,需要转化为1-hot标签。keras提供了一个转化标签的函数to_categorical,将标签转化为1-hot标签
- 分配训练集与验证集
import keras import numpy as np from keras.datasets import mnist from keras.utils import to_categorical (x_train,y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape(-1, 784) x_train = x_train / 255 y_train = to_categorical(y_train) x_test = x_test.reshape(-1, 784) x_test = x_test / 255 y_test = to_categorical(y_test)
2.构建神经网络模型
Keras提供了两种建立神经网络的模型:
- Sequential序贯式:适用于没有分支结构的神经网络
- Functional函数式:适用于结构复杂的模型
2.1Sequential方法构建模型
- 导入模块keras.models.Sequential
- 建立空模型 model=Sequential()
- 逐层加入神经网络模块。第一层必须指定输入的尺寸。
from keras.models import Sequential from keras.layers import Dense model = Sequential() model.add(Dense(300, activation='sigmoid', input_shape=(784,))) model.add(Dense(100, activation='sigmoid')) model.add(Dense(10,activation='softmax'))
2.2 函数式方法
- 导入keras.models.Model模块
- 定义输入层并指定大小(Input层)
- 逐个添加层,每层之后加入(x)代表与x指代的层相连。
- 使用Model函数指定模型的输入和输出
from keras.models import Model from keras.layers import Input, Dense input_layer = Input((784,)) x = Dense(300, activation='sigmoid')(input_layer) x = Dense(100, activation='sigmoid')(x) x = Dense(10, activation='softmax')(x) model = Model(input_layer, x)
3.模型的训练
在开始训练之前,要指定模型训练的损失函数和参数的更新方法,利用complie方法将其整合到模型中。
- loss:指定损失函数。keras内置了很多损失函数,可以使用字符串形式指定。这里我们是多分类模型,因此使用交叉熵作为损失函数。
- optimizer:指定梯度优化算法。这里我们使用随机梯度下降法sgd
- metrics:可选参数,与训练过程无关,仅仅用于训练中观察训练情况。这里我们使用准确率
- 使用fit方法进行训练。Fit方法需要给定数据、标签、每批数据大小、训练轮数等参数
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['acc']) model.fit(x_train, y_train, batch_size=32, epochs=10)

4.模型验证

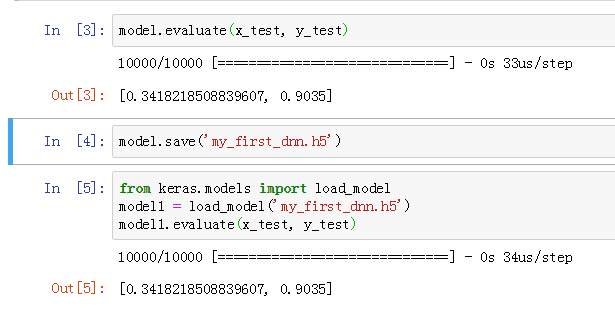
- 当我们在测试集中评价我们模型的泛化能力时,使用evaluate,指定数据与真实标签,输出在测试集上的损失函数loss值和metric值(准确率)。
- 当我们没有真实标签,仅仅用于预测时,使用predict,指定数据。
- 可见,仅仅经过10轮训练,我们的准确率就达到了90.35%.
- 存储模型:save(文件名) model.save('my_first_dnn.h5')
- 读取模型:load_model(文件名)
在keras框架下运行的第一个小程序完成~~~