爬取更多的items,例如名字,主演,播放次数,电影海报,并进行多页爬取。
items.py
1 import scrapy 2 3 class YoukumoiveItem(scrapy.Item): 4 # define the fields for your item here like: 5 moiveName = scrapy.Field() 6 actors=scrapy.Field() 7 views=scrapy.Field() 8 img=scrapy.Field()
youkuMoiveSpider.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from youkuMoive.items import YoukumoiveItem 4 5 class YoukumoivespiderSpider(scrapy.Spider): 6 name = 'youkuMoiveSpider' 7 allowed_domains = ['list.youku.com'] 8 pages=list(range(1,11)) 9 start_urls = [] 10 for page in pages: 11 start_urls.append('http://list.youku.com/category/show/c_96_s_1_d_1_p_'+str(page)+'.html?spm=a2h1n.8251845.0.0') 12 13 def parse(self, response): 14 subSelector=response.css('li.yk-col4') 15 items=[] 16 for sub in subSelector: 17 item=YoukumoiveItem() 18 item['moiveName']=sub.css("ul.info-list li.title a::attr(title)").extract()[0] 19 item['actors']=sub.css("ul.info-list li.actor a::attr(title)").extract() 20 if len(item['actors'])>1: 21 item['actors']=str(",".join(item['actors'])) 22 item['views']=sub.css("ul.info-list li.actor+li ::text").extract()[0] 23 item['img']=sub.css("img.quic::attr(src)").extract()[0] 24 items.append(item) 25 return items
pipelines.py
1 import time 2 import os.path 3 import urllib.request 4 5 class YoukumoivePipeline(object): 6 def process_item(self, item, spider): 7 today=time.strftime('%Y%m%d',time.localtime()) 8 filename=today+'.txt' 9 with open(filename,'a') as fp: 10 fp.write(str(item['moiveName'])+' ') 11 fp.write(str(item['actors'])+' ') 12 fp.write(str(item['views'])+' ') 13 imgName=os.path.basename(str(item['img'])+".jpg") 14 fp.write(imgName+' ') 15 if os.path.exists(imgName): 16 pass 17 else: 18 with open(imgName,'wb') as fp: 19 response=urllib.request.urlopen(str(item['img'])) 20 fp.write(response.read()) 21 22 return item
setting.py
1 BOT_NAME = 'youkuMoive' 2 3 SPIDER_MODULES = ['youkuMoive.spiders'] 4 NEWSPIDER_MODULE = 'youkuMoive.spiders' 5 6 # Obey robots.txt rules 7 ROBOTSTXT_OBEY = True 8 9 ITEM_PIPELINES={'youkuMoive.pipelines.YoukumoivePipeline':1}
当然,过程中还是出了不少bug,一部分是不同文件间的类名拼写错误(哎呀,细心细心啊)
一部分是因为python的语法不熟悉,以致于出现某些类型错误。下面挑选几个典型报错:
- 报错1:

将 fp.write(item['moiveName']+' ') 改写成 fp.write(str(item['moiveName'][0])+' ') 即可
-
报错2:
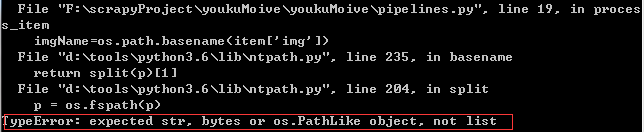
依然是字符串的问题,将 imgName=os.path.basename(item['img']) 改为 imgName=os.path.basename(str(item['img'][0])) ,又因为优酷网站上的图片没有JPG后缀,所以加上 ".jpg" ,这样就可以用图片软件直接打开了。当然,没加时也是可以打开的,但是可能需要自己选择打开方式啦
- 报错3:
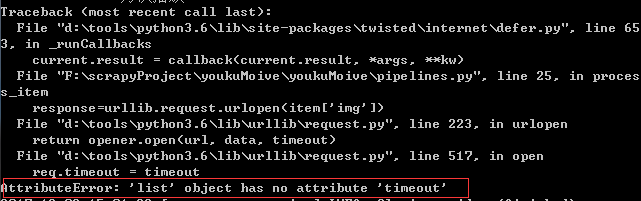
惭愧,这个说到底依然是字符串问题,因为 item['img'] 返回的是数组,所以将其转成字符串就可以顺利打开啦。
将爬取结果保存为json文件
添加pipelines2json.py文件,内容如下:
1 import time 2 import json 3 import codecs 4 5 class YoukumoivePipeline(object): 6 def process_item(self, item, spider): 7 today=time.strftime('%Y%m%d',time.localtime()) 8 filename=today+'.json' 9 with codecs.open(filename,'a') as fp: 10 line=json.dumps(dict(item),ensure_ascii=False)+' ' 11 fp.write(line) 12 13 return item
同时,在setting.py文件中的ITEM_PIPELINES字典修改如下:
ITEM_PIPELINES={'youkuMoive.pipelines.YoukumoivePipeline':1,
'youkuMoive.pipelines2json.YoukumoivePipeline':2}
再次执行,就可以得到json文件啦!
将爬取结果保存为到MySQL数据库中
首先,在数据库中创建表。在CMD执行以下代码
create database scrapyDB character set 'utf8' collate 'utf8_general_Ci'; use scrapyDB; create table moive( id INT AUTO_INCREMENT, moiveName char(20), actors char(20), views char(20), img char(80), primary key(id)) engine=InnoDB default charset=utf8;
查看创建的表 show columns from moive;

然后,安装MySQLdb模块
本来要安装MySQL-python的,然后报错
running build_ext
building "_mysql" extension
error: microsoft visual C++ 14.0 is required
去https://www.lfd.uci.edu/~gohlke/pythonlibs/这个网站找对应的whl安装文件,然而都是python2.7的,而我是3.6!!!
于是寻找MySQL-python的替代品,找到了PyMySQL,安装一下 pip install PyMySQL
PyMySQL的用法跟MySQL-python基本上是一样的。更详细的PyMySQL用法见 https://www.cnblogs.com/hank-chen/p/6624299.html
最后,便是编写导入MySQL的文件pipelines2mysql.py咯
1 import pymysql.cursors 2 import os.path 3 4 class YoukumoivePipeline(object): 5 def process_item(self, item, spider): 6 moiveName=item['moiveName'] 7 actors=item['actors'] 8 views=item['views'] 9 img=os.path.basename(item['img']) 10 11 conn=pymysql.Connect( 12 host='localhost', 13 port=3306, 14 user='crawlUSER', 15 password='123123', 16 db='scrapyDB', 17 charset='utf8') 18 cur=conn.cursor() 19 cur.execute("insert into moive(moiveName,actors,views,img) values(%s,%s,%s,%s)",(moiveName,actors,views,img)) 20 cur.close() 21 conn.commit() 22 conn.close() 23 24 return item
记得在setting.py添加相应的字典条目。执行爬虫脚本,再次刷新数据库,便可看到数据啦!
如此,便是本次爬虫的全部内容啦。
补充:
后来发现,如果在youkuMoiveSpider文件中,将item在extract之后用[0]提取出来,则此时的item['moiveName']便是字符串了。也许就不会有后面的如此多的bug啦。
So,建议以后在为item赋值时用以下形式: item['moiveName']=sub.css("ul.info-list li.title a::attr(title)").extract()[0] ,应该对大部分情况很适用。