上一篇我们以 Excel 文件数据集为例,介绍了如何把 Excel 的数据透视表嵌入到俺的应用程序中。爱学习的同学会问了,Excel 数据透视表可以使用 Excel 里取到的任何数据,比如数据库取数,你们能直接从数据库取数做分析吗?Yes,I Can!
俺的程序支持对任何数据库做 SQL 数据集多维分析,只需先把数据源配置好,然后程序猿啪啪几下敲下需要进行多维分析的 SQL 语句就可以,灵活便捷!
好了,言归正传,正文马上开始!
定义物理数据源
添加 SQL 数据集时首要任务就是先在 [web 应用根目录]/WEB-INF/raqsoftConfig.xml 中定义好要使用的物理数据源。
<DBList> <DB name="dqldemo"> <property name="url" value="jdbc:hsqldb:hsql://127.0.0.1/demo" ></property> <property name="driver" value="org.hsqldb.jdbcDriver" ></property> <property name="type" value="13" ></property> <property name="user" value="sa" ></property> <property name="password" ></property> … … </DB> … … </DBList>
界面添加 SQL 数据集
物理数据源创建好后,接下来最重要的一步就是添加 SQL 数据集了。只需选择物理数据源,写上 SQL 语句,点击查询数据,缓存入文件保存就 ok 了!没错,就是这么方便!

数据集创建完成后万事俱备只欠东风,接下来就可以开始多维分析的体验之旅了。
点击【添加报表】,选择数据集,填写报表名称【确定】,齐活!

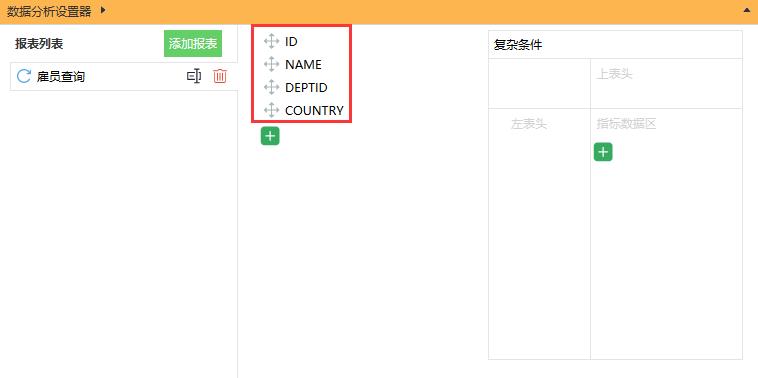
数据集有了,分析指标有了,现在就可以任性拖拽你想要查询的指标了,对 SQL 数据集的分析也能像文件分析从单机一步跃升 WEB 环境了,是不是又找到了倍儿爽的感觉?哈哈
先拖拽几个指标找找手感:
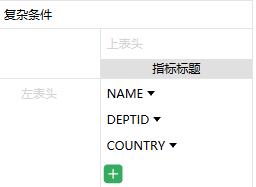
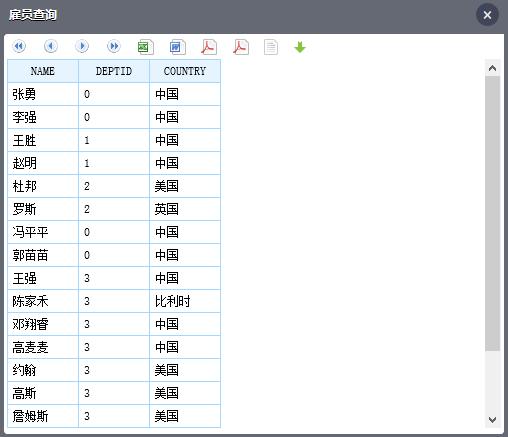
咦?咋列名都是代码,不是中文?这样感觉不友好!同学,这个问题提的好,其实答案很简单,分析出来的报表列名就是用的 SQL 数据集的字段名,所以只要使 SQL 数据集返回的字段名是中文就行!
利用 AS 返回中文字段名
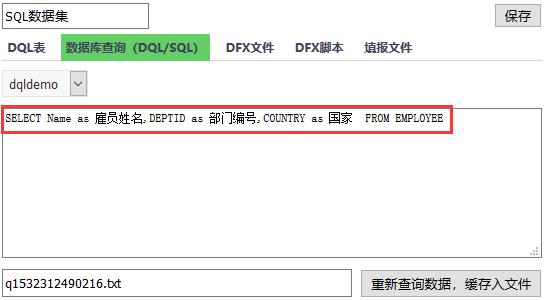
修改数据集 SQL 后,点击重新查询数据,缓存入文件,再次添加报表,发现字段名变成中文了吧!
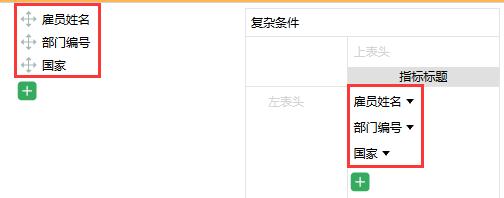
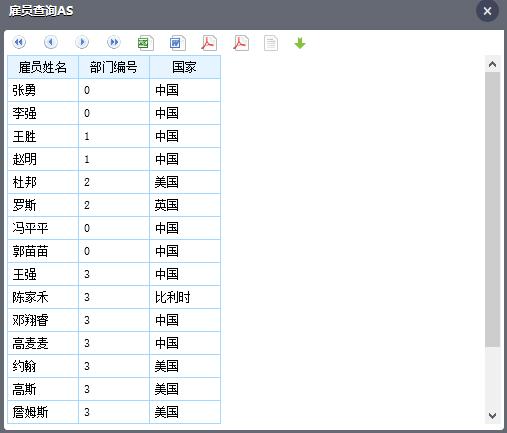
怎么样,看着舒服了吧,一不小心又 get 到新技能!不过看了上面的结果爱提问的同学可能又有想法了:部门怎么显示的是编号,这 0123 代表啥俺又不知道,那咋做分析?哈哈,小编猜到你的想法,早有准备,啧啧。。。
LEFT JOIN 搞定编号代码显示
把部门编号显示成部门名称,百变不离其中,还是取决于 SQL 数据集的 SQL 语句。通过 LEFT JOIN 做多表关联就可以轻松搞定!
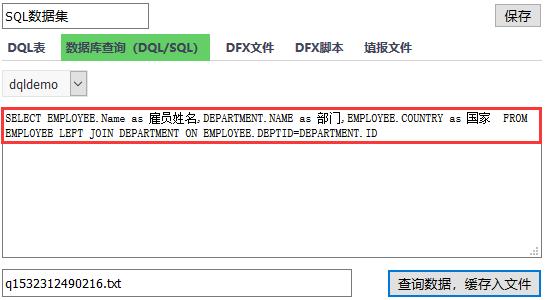
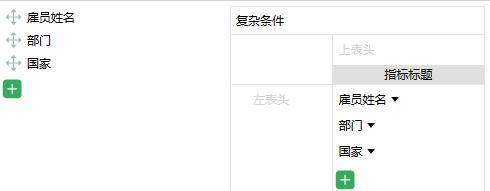

好了,通过上面的学习有没有发现其实数据集全是由 SQL 语句决定的,这里的 SQL 语句只要符合 SQL 标准语法就行,比如可以通过 AS 对字段重命名,LEFT JOIN 多表关联实现名称的显示等等,总之一句话:一切向 SQL 看齐!
利用 Tag 标签添加 SQL 数据集
除了上述这种在界面上添加 SQL 数据集的方式外,其实还可以通过 Tag 标签添加。
SQL 数据集和文件数据集在 Tag 标签的使用大同小异,只是属性略有不同。
Tag 标签添加 SQL 数据集:
<raqsoft:analysev2 dataSource="dqldemo" //指定SQL需要使用的物理数据源 sql="select * from EMPLOYEE" //SQL语句 … … >
在 Tag 标签中添加 SQL 数据集,访问多维分析页面时会将该数据集默认作为初始数据集,并直接将结果集以明细的形式展现在页面中。

注重细节的同学是不是又发现了端倪?怎么使用 Tag 标签添加数据集时没有点击【查询数据,缓存入文件】结果也能正常展现呢?难道这两种添加数据集的方式还有什么不同吗?
哈哈,迷糊了吧,烟雾弹扔的真奏效
其实这两种方式的底层对数据的处理机制是一样的,唯一的不同点就是 Tag 标签添加数据集可以理解为是直接为分析页面设置了初始数据集,这个时候程序会自动生成临时文件,然后将计算结果存入,这样一来就不用劳您大驾再动手缓存了。不过如果您还需要继续在页面上对初始数据集修改或者添加新的数据集,那就还得按最开始讲的那样儿,每次修改 SQL 语句后,都需要点击 【查询数据,缓存入文件】 重新生成了临时文件了。默认临时文件命名规则是以时间毫秒数组合而成。
怎么样,SQL 数据集在俺自己的应用程序里用起来是不是也超便捷?不论是在页面数据集菜单中添加还是在 Tag 标签里添加,其实都是先让集算器通过 SQL 取数,然后将返回的结果集缓存入临时文件,之后在页面上的多维分析就都是基于这个临时数据文件取数了。这样一来,借用集算器的计算能力,在界面上就能做拖拽分组、聚合、过滤等等数据分析动作了。
关于缓存文件的生命周期小编还是要多唠叨几句,简单分为如下三点:
1、当缓存文件的父目录路径中包含”temp”字样时,如:/Raqsofttemp/.txt 或 /temp/.txt,程序会在 Session 超时时自动清理该缓存文件
2、生成缓存文件时,如果发现缓存文件不存在,则会自动根据数据集的配置重新生成缓存文件
3、如果缓存文件路径中没有 temp 字样,则不会对缓存文件做任何删除处理,由客户的系统自己管理这些缓存文件的生命周期
缓存文件的后缀是.txt,聪明的你肯定就能猜润乾报表是用 TXT 文件作为中介的,但 TXT 文件的性能有点差,而且数据类型也不那么精确,个别情况会出点小错。其实从 SQL 中读出来的数据已经是二进制格式,再转成文本保存有点费时费力不讨好。
那么,还能怎么弄?
润乾报表提供了二进制格式的缓存文件,不过,这时候我得说一句不过了,这个功能需要收费的集成集算器才能支持了。如果已经有了这个功能组件,那么就简单了。
二进制缓存文件提升性能
打开 [WEB 应用根目录]/raqsoft/guide/jsp/olap.jsp 添加如下 JS API 脚本:
<script> guideConf.dataFileType = 'binary'; //binary是二进制文件,会以游标方式读取,能支持超出内存的数据集;该属性的默认为text文本文件类型。 </script>
好了,设置完了,再缓存时就是以二进制文件的类型保存临时文件了。
咋样,是不是超简单?超便利?超喜欢?
不过话又说回来,上面这种缓存入文件的方式对于数据量不大的情况没问题,但有时候我们希望利用数据库的计算能力(毕竟数据库还可以集群分布等),那又该怎么办呢?
不要慌,润乾报表帮你忙!
非缓存 SQL 数据集
在 JSP 脚本中添加不需要缓存数据的 SQL 数据集。操作起来也不难,只先敲上一个做原始查询的 SQL 语句就行。
将 SQL 语句传递给数据库做查询,查询后分析界面会直接将结果集中的字段列出,进行拖拽就可以了。
下面以一个多表查询做举例,在 [demo 应用根目录]/raqsoft/guide/jsp/olap.jsp 添加 JS API 进行设置。
<script>
guideConf.sqlId="<%=sqlId%>";//指定sqlid
var sqlDatasets =
[
{
sqlId:"sqlId1" //指定数据集名称,不可重复
,dataSource:"dqldemo" //指定SQL语句所使用的数据源
,sql:"SELECT EMPLOYEE.Name as 雇员姓名,DEPARTMENT.NAME as 部门,EMPLOYEE.COUNTRY as 国家 FROM EMPLOYEE LEFT JOIN DEPARTMENT ON EMPLOYEE.DEPTID=DEPARTMENT.ID" //指定数据集SQL语句
,fields:null
},
… …
]
… …
</script>
脚本添加完成后,访问分析页面时只需要在 URL 里为 sqlId 参数传入数据集名称,如下图所示,使用名称为 sqlId1 的数据集: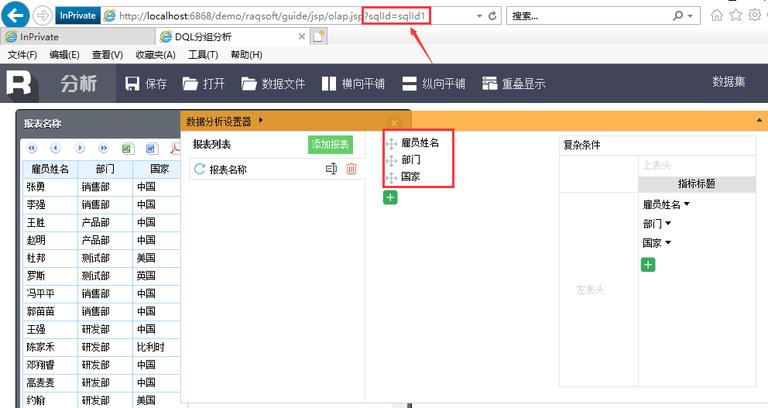

将 SQL 数据集作为数据来源设置后,就能针对这个数据集分析了,但分析过程不会像缓存入文件类型的数据集那样预先加载这个数据集的数据,而是通过在这个 SQL 上追加更多的查询条件、分组、聚合子句方式实时在数据库中查询的,如: select f1 , sum(f2) from (${ 原始 sql}) t where … group by …. having ….
简单 SQL 提升性能
基于上面这种做法,对性能有高要求的同学估计会有情绪了,很多 DB 不会优化,这样做就会搞的很慢,体验并不好。
哈哈,莫捉急,为了提高性能我们针对简单 SQL 还有更智能的自动改善性能的手段,所谓简单 SQL 就是单表无分组的 SQL 语句。SQL 会在被解析后再重组 SQL,而不是用比较慢的子查询语句。不过当 SQL 中包含 JOIN、分组、子查询、UNION 等复杂查询功能时,由于无法进行拆解,因此程序还是会自动选用子查询方式进行处理。
设置单表无分组的简单 SQL:
<script>
guideConf.sqlId="<%=sqlId%>";//指定sqlid
var sqlDatasets =
[
{
sqlId:"sqlId1" //指定数据集名称,不可重复
,dataSource:"dqldemo" //指定SQL语句所使用的数据源
,sql:"SELECT * from 客户" //指定数据集SQL语句
,fields:null
},
… …
]
… …
</script>
访问分析页面,拖拽指标,如下图所示:
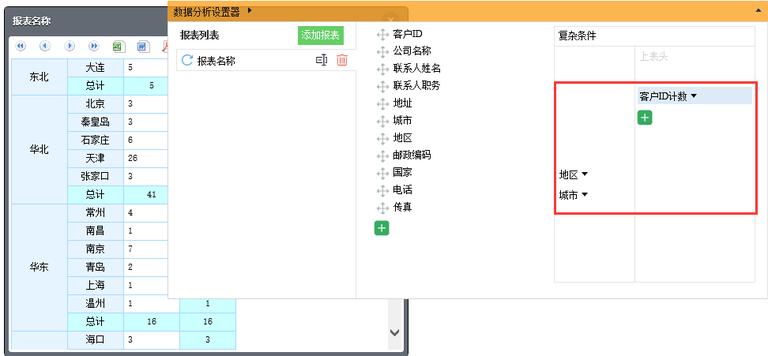
像上面例子这样最终拖拽后基于原始 SQL"select * from 客户" 生成的 SQL 语句为:SELECT 地区 地区, 城市 城市,count(客户 ID) 客户 ID 计数 FROM 客户 t GROUP BY 地区, 城市。
好了,对 SQL 数据集多维分析的介绍就告于段落了,现在我们来回顾一下心路历程:

可以看到我们从可以缓存的少量数据,到利用数据库计算能力的大量数据都有很好的解决方案,同时还提供了相应的性能提升手段。不过,俺们 WEB 多维分析的超能力可不仅仅如此,比如还能随意修改报表分析的表格样式、通过建模来读取维度和指标信息等等,想要学习润乾报表多维分析更多知识,欢迎访问乾学院(c.raqsoft.com.cn)。
作者:sln
链接:http://c.raqsoft.com.cn/article/1534823034618?r=IBelieve
来源:乾学院
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。