Surviving the Release Version
Introduction
OK, your program works. You've tested everything in sight. It's time to ship it. So you make a release version.
And the world crumbles to dust.
You get memory access failures, dialogs don't come up, controls don't work, results come out incorrectly, or any or all of the above. Plus a few more problems that are specific to your application.
Now what?
That's what this essay is all about.
Some background
A bit of background: I have been working with optimizing compiler since 1969. My PhD dissertation (1975) was on the automatic generation of sophisticated optimizations for an optimizing compiler. My post-doctoral work involved the use of a highly optimizing compiler (Bliss-11) in the construction of a large (500K line source) operating system for a multiprocessor. After that, I was one of the architects of the PQCC (Production Quality Compiler-Compiler) effort at CMU, which was a research project to simplify the creation of sophisticated optimizing compilers. In 1981 I left the University to join Tartan Laboratories, a company that developed highly-optimizing compilers, where I was one of the major participants in the tooling development for the compilers. I've lived with, worked with, built, debugged, and survived optimizing compilers for over 30 years.
Compiler bugs
The usual first response is "the optimizer has bugs". While this can be true, it is actually a cause-of-last-resort. It is more likely that there is something else wrong with your program. We'll come back to the "compiler bugs" question a bit later. But the first assumption is that the compiler is correct, and you have a different problem. So we'll discuss those problems first.
Storage Allocator Issues
The debug version of the MFC runtime allocates storage differently than the release version. In particular, the debug version allocates some space at the beginning and end of each block of storage, so its allocation patterns are somewhat different. The changes in storage allocation can cause problems to appear that would not appear in the debug version--but almost always these are genuine problems, as in bugs in your program, which somehow managed to not be detected in the debug version. These are usually rare.
Why are they rare? Because the debug version of the MFC allocator initializes all storage to really bogus values, so an attempt to use a chunk of storage that you have failed to allocate will give you an immediate access fault in the debug version. Furthermore, when a block of storage is freed, it is initialized to another pattern, so that if you have retained any pointers to the storage and try to use the block after it is freed you will also see some immediately bogus behavior.
The debug allocator also checks the storage at the start and end of the block it allocated to see if it has been damaged in any way. The typical problem is that you have allocated a block of n values as an array and then accessed elements 0 through n, instead of 0 through n-1, thus overwriting the area at the end of the array. This condition will cause an assertion failure most of the time. But not all of the time. And this leads to a potential for failure.
Storage is allocated in quantized chunks, where the quantum is unspecified but is something like 16, or 32 bytes. Thus, if you allocated a
DWORD array of six elements (size = 6 *
sizeof(DWORD) bytes = 24 bytes) then the allocator will actually deliver 32 bytes (one 32-byte quantum or two 16-byte quanta). So if you write element [6] (the seventh element) you overwrite some of the "dead space" and
the error is not detected. But in the release version, the quantum might be 8 bytes, and three 8-byte quanta would be allocated, and writing the [6] element of the array would overwrite a part of the storage allocator data structure that belongs to the next
chunk. After that it is all downhill. There error might not even show up until the program exits! You can construct similar "boundary condition" situations for any size quantum. Because the quantum size is the same for both versions of the allocator, but the
debug version of the allocator adds hidden space for its own purposes, you will get different storage allocation patterns in debug and release mode.
Uninitialized Local Variables
Perhaps the greatest single cause of release-vs-debug failures is the occurrence of uninitialized local variables. Consider a simple example:
thing * search(thing * something) BOOL found; for(int i = 0; i < whatever.GetSize(); i++) { if(whatever[i]->field == something->field) { /* found it */ found = TRUE; break; } /* found it */ } if(found) return whatever[i]; else return NULL; }
Looks pretty straightforward, except for the failure to initialize the found variable to
FALSE. But this bug was never seen in the debug version! But what happens in the release version is that the
whatever array, which holds n elements, has whatever[n] returned, a clearly invalid value, which later causes some other part of the program to fail horribly. Why didn't this show up in the debug version? Because in the
debug version, due entirely to a fortuitous accident, the value of found was always initially 0 (FALSE), so when the loop exited without finding anything, it was correctly reporting that nothing was found, and
NULL was returned.
Why is the stack different? In the debug version, the frame pointer is always pushed onto the stack at routine entry, and variables are almost always assigned locations on the stack. But in the release version, optimizations of the compiler may detect that the frame pointer is not needed, or variable locations be inferred from the stack pointer (a technique we called frame pointer simulation in compilers I worked on), so the frame pointer is not pushed onto the stack. Furthermore, the compiler may detect that it is by far more efficient to assign a variable, such as i in the above example, to a register rather than use a value on the stack, so the initial value of a variable may depend on many factors (the variable i is clearly initially assigned, but what if found were the variable?
Other than careful reading of the code, and turning on high levels of compiler diagnostics, there is absolutely no way to detect uninitialized local variables without the aid of a static analysis tool. I am particularly fond of Gimpel Lint (see http://www.gimpel.com/), which is an excellent tool, and one I highly recommend.
Bounds Errors
There are many valid optimizations which uncover bugs that are masked in the debug version. Yes, sometimes it is a compiler bug, but 99% of the time it is a genuine logic error that just happens to be harmless in the absence of optimization, but fatal when it is in place. For example, if you have an off-by-one array access, consider code of the following general form
void func() { char buffer[10]; int counter; lstrcpy(buffer, "abcdefghik"); // 11-byte copy, including NULL ...
In the debug version, the NULL byte at the end of the string overwrites the high-order byte of counter, but unless
counter gets > 16M, this is harmless even if counter is active. But in the optimizing compiler,
counter is moved to a register, and never appears on the stack. There is no space allocated for it. The
NULL byte overwrites the data which follows buffer, which may be the return address from the function, causing an access error when the function returns.
Of course, this is sensitive to all sorts of incidental features of the layout. If instead the program had been
void func() { char buffer[10]; int counter; char result[20]; wsprintf(result, _T("Result = %d"), counter); lstrcpy(buffer, _T("abcdefghik")); // 11-byte copy, including NUL
then the NUL byte, which used to overlap the high order byte of counter (which doesn't matter in this example because
counter is obviously no longer needed after the line using it is printed) now overwrites the first byte of
result, with the consequence that the string result now appears to be an empty string, with no explanation of why it is so. If
result had been a char * variable or some other pointer you would be getting an access fault trying to access through it. Yet the program "worked in the debug version"! Well, it didn't, it was wrong, but
the error was masked.
In such cases you will need to create a version of the executable with debug information, then use the break-on-value-changed feature to look for the bogus overwrite. Sometimes you have to get very creative to trap these errors.
Been there, done that. I once got a company award at the monthly company meeting for finding a fatal memory overwrite error that was a "seventh-level bug", that is, the pointer that was clobbered by overwriting it with another valid (but incorrect) pointer caused another pointer to be clobbered which caused an index to be computed incorrectly which caused...and seven levels of damage later it finally blew up with a fatal access error. In that system, it was impossible to generate a release version with symbols, so I spent 17 straight hours single-stepping instructions, working backward through the link map, and gradually tracking it down. I had two terminals, one running the debug version and one running the release version. It was obvious in the debug version what had gone wrong, after I found the error, but in the unoptimized code the phenomenon shown above masked the actual error.
Linkage Errors
Linkage Types
Certain functions require a specific linkage type, such as __stdcall. Other functions require correct parameter matching. Perhaps the most common errors are in using incorrect linkage types. When a function specifies a
__stdcall linkage you must specify the __stdcall for the function you declare. If it does
not specify __stdcall, you must not use the
__stdcall linkage. Note that you rarely if ever see a "bare" __stdcall linkage declared as such. Instead, there are many linkage type macros, such as
WINAPI, CALLBACK, IMAGEAPI, and even the hoary old (and distinctly obsolete)
PASCAL which are macros which are all defined as __stdcall. For example, the top-level thread function for an
AfxBeginThread function is defined as a function whose prototype uses the
AFX_THREADPROC linkage type.
UINT (AFX_CDECL * AFX_THREADPROC)(LPVOID);
which you might guess as being a CDECL (that is, non-__stdcall) linkage. If you declared your thread function as
UINT CALLBACK MyThreadFunc(LPVOID value)
and started the thread as
AfxBeginThread((AFX_THREAD_PROC)MyThreadFunc, this);
then the explicit cast (often added to make a compiler warning go away!) would fool the compiler into generating code. This often results in the query "My thread function crashes the app when the thread completes, but only in release mode". Exactly why it doesn't do this in debug mode escapes me, but most of the time when we look at the problem it was a bad linkage type on the thread function. So when you see a crash like this, make sure that you have all the right linkages in place. Beware of using casts of function types; instead. write the function as
AfxBeginThread(MyThreadFunc, (LPVOID)this);
which will allow the compiler to check the linkage types and parameter counts.
Parameter counts
Using casts will also result in problems with parameter counts. Most of these should be fatal in debug mode, but for some reason some of them don't show up until the release build. In particular, any function with a
__stdcall linkage in any of its guises must have the correct number of arguments. Usually this shows up instantly at compile time unless you have used a function-prototype cast (like the
(AFX_THREADPROC) cast in the previous section) to override the compiler's judgment. This almost always results in a fatal error when the function returns.
The most common place this shows up is when user-defined messages are used. You have a message which doesn't use the
WPARAM and LPARAM values, so you write
wnd->PostMessage(UWM_MY_MESSAGE);
to simply send the message. You then write a handler that looks like
afx_msg void OnMyMessage(); // incorrect!
and the program crashes in release mode. Again, I've not investigated why this doesn't cause a problem in debug mode, but we've seen it happen all the time when the release build is created. The correct signature for a user-defined message is always, without exception,
afx_msg LRESULT OnMyMessage(WPARAM, LPARAM);
You must return a value, and you must have the parameters as specified (and you
must use the types WPARAM and LPARAM if you want compatibility into the 64-bit world; the number of people who "knew" that
WPARAM meant WORD and simply wrote (WORD, LONG) in their Win16 code paid the penalty when they went to Win32 where it is actually
(UNSIGNED LONG, LONG), and it will be different again in Win64, so why do it wrong by trying to be cute?)
Note that if you don't use the parameter values, you don't provide a name for the parameters. So your handler for
OnMyMessage is coded as
LRESULT CMyClass::OnMyMessage(WPARAM, LPARAM)
{
...do something here...
return 0; // logically void, 0, always
}
Compiler "Bugs"
An optimizing compiler makes several assumptions about the reality it is dealing with. The problem is that the compiler's view of reality is based entirely on a set of assumptions which a C programmer can all too readily violate. The result of these misrepresentations of reality are that you can fool the compiler into generating "bad code". It isn't, really; it is perfectly valid code providing the assumptions the compiler made were correct. If you have lied to your compiler, either implicitly or explicitly, all bets are off.
Aliasing bugs
An alias to a location is an address to that location. Generally, a compiler assumes that unless otherwise instructed, aliasing exists (it is typical of C programs). You can get tighter code if you tell the compiler that it can assume no aliasing, and therefore, values that it has computed will remain constant across function calls. Consider the following example:
int n; int array[100]; int main(int argc, char * argv) { n = somefunction(); array[0] = n; for(int i = 1; i < 100; i++) array[i] = f(i) + array[0]; }
This looks pretty easy; it computes a function of i, f(i), which at the moment we won't bother to define, and adds the array entry value to it. So a clever compiler says, "Look,
array[0] isn't modified at all in the loop body, so we can change the code to store the value in a register and rearrange the code:
register int compiler_generated_temp_001 =somefunction(); n = compiler_generated_temp_001; array[0] = compiler_generated_temp_001; for(int i = 1; i < 100; i++) array[i] = f(i) + compiler_generated_temp_001;
This optimization, which is a combination of loop invariant optimization and value propagation, works only if the assumption that
array[0]is not modified by f(i). But if we later define
int f(int i) { array[0]++; return i; }
Note that we have now violated the assumption that array[0] is constant; there is an
alias to the value. Now this alias is fairly easy to see, but when you have complex structures with complex pointers you can get exactly the same thing, but it is not detectable at compile time, or by static analysis of the program.
Note that the VC++ compiler, by default, assumes that aliasing exists. You have to take explicit action to override this assumption. It is a Bad Idea to do this except in very limited contexts; see the discussion of optimization pragmas.
const and volatile
These are attributes you can add to declarations. For variable declarations, the
const declaration says "this never changes" and the
volatile declaration says "this changes in ways you can't possibly guess". While these have very little impact when you compile in debug mode, they have a profound effect when you compile for release, and if you have failed to use them, or used
them incorrectly, You Are Doomed.
The const attribute on a variable or function states that the value is constant. This allows the optimizing compiler to make certain assumptions about the value, and allows such optimizations as
value propagation and constant propagation to be used. For example
int array[100]; void something(const int i) { ... = array[i]; // usage 1 // other parts of the function ... = array[i]; // usage 2 }
The const declaration allows the compiler to assume that the value
i is the same at points usage 1 and usage 2. Furthermore, since
array is statically allocated, the address of array[i] need only be computed once; and the code can be generated as if it had been written:
int array[100]; void something(const int i) { int * compiler_generated_temp_001 = &array[i]; ... = *compiler_generated_temp_001; // usage 1 // other parts of the function ... = *compiler_generated_temp_001; // usage 2 }
In fact, if we had the declaration
const int array[100] = {.../* bunch of values */ }
the code could be generated as if it were
void something(const int i) { int compiler_generated_temp_001 = array[i]; ... = compiler_generated_temp_001; // usage 1 // other parts of the function ... = compiler_generated_temp_001; // usage 2 }
Thus const not only gives you compile-time checking, but can allow the compiler to generate smaller, faster code. Note that you can force violations of const by explicit casts and various devious programming techniques.
The volatile declaration is similar, and says the direct opposite: that no assumption of the constancy of a value can be made. For example, the loop
// at the module level or somewhere else global to the function int n; // inside some function while(n > 0) { count++; }
will be readily transformed by an optimizing compiler as
if(n > 0) for(;;) count++;
and this is a perfectly valid translation. Because there is nothing in the loop that can change the value of n, there is no reason to ever test it again! This optimization is an example of a loop invariant computation, and an optimizing compiler will "pull this out" of the loop.
But what if the rest of the program looked like this:
registerMyThreadFlag(&n); while(n > 0) { count++; }
and the thread used the variable registered by the registerMyThreadFlag call to set the value of the variable whose address was passed in? It would fail utterly; the loop would never exit!
Thus, the way this would have to be declared is by adding the volatile attribute to the declaration of
n:
volatile int n;
This informs the compiler that it does not have the freedom to make the assumption about constancy of the value. The compiler will generate code to test the value n on every iteration through the loop, because you've explicitly told it that it is not safe to assume the value n is loop-invariant.
ASSERT and VERIFY
Many programmers put ASSERT macros liberally throughout their code. This is usually a good idea. The nice thing about the ASSERT macro is that using it costs you nothing in the release version because the macro has an empty body. Simplistically, you can imagine the definition of the ASSERT macro as being
#ifdef _DEBUG #define ASSERT(x) if( (x) == 0) report_assert_failure() #else #define ASSERT(x) #endif
(The actual definition is more complex, but the details don't matter here). This works fine when you are doing something like
ASSERT(whatever != NULL);
which is pretty simple, and omitting the computation of the test from the release version doesn't hurt. But some people will write things like
ASSERT( (whatever = somefunction() ) != NULL);
which is going to fail utterly in the release version because the assignment is never done, because there is no code generated (we will defer the discussion of embedded assignments being fundamentally evil to some other essay yet to be written. Take it as given that if you write an assignment statement within an if-test or any other context you are committing a serious programming style sin!)
Another typical example is
ASSERT(SomeWindowsAPI(...));
which will cause an assertion failure if the API call fails. But in the release version of the system the call is never made!
That's what VERIFY is for. Imagine the definitions of VERIFYas being
#ifdef _DEBUG #define VERIFY(x) if( (x) == 0) report_assert_failure() #else #define VERIFY(x) (x) #endif
Note this is a very different definition. What is dropped out in the release version is the
if-test, but the code is still executed. The correct forms of the above incorrect examples would be
VERIFY((whatever = somefunction() ) != NULL); VERIFY(SomeWindowsAPI(...));
This code will work correctly in both the debug and release versions, but in the release version there will be no
ASSERT failure if the test comes out FALSE. Note that I've also seen code that looks like
VERIFY( somevalue != NULL);
which is just silly. What it effectively means is that it will, in release mode, generate code to compute the expression but ignore the result. If you have optimizations turned on, the compiler is actually clever enough to determine that you are doing something
that has no meaning and discard the code that would have been generated (but only if you have the Professional or Enterprise versions of the compiler!). But as we also discuss in this essay, you can create an
unoptimized release version, in which case the preceding VERIFY would simply waste time and space.
Compiler Bugs (again)
Optimizing compilers are very sophisticated pieces of code. They are so complex that generally no one person understands all of the compiler. Furthermore, optimization decisions can interact in subtle and unexpected ways. Been There, Done That.
Microsoft has done a surprisingly good job of QA on their optimizing compilers. This is not to say that they are perfect, but they are actually very, very good. Much better than many commercial compilers I've used in the past (I once used a compiler that
"optimized" a constant if-test by doing the
else if the value was TRUE and the
then if the value was FALSE, and they told us "We'll fix that in the next release, sometime next year". Actually, I think they went out of business before the next compiler release, which surprised no one who had ever been a customer).
But it is more likely that a "compiler bug" is the result of your violating the compiler assumptions rather than a genuine compiler bug. That's been my experience.
Furthermore, it may not even be a bug that affects your code. It might be in the MFC shared DLL, or the MFC statically-linked library, where a programmer committed an error that doesn't show up in the debug versions of these libraries but shows up in the release versions. Again, Microsoft has done a surprisingly good job of testing these, but no testing procedure is perfect.
Nonetheless, the Windows Developer's Journal (http://www.wdj.com/) has a monthly feature, "Bug++ of the Month", which features actual, genuine compiler optimization bugs.
How do you get around such bugs? The simplest technique is to turn off all the compiler optimizations (see below). There is an excellent chance that if you do this you will perceive no difference in the performance of your program. Optimization matters only when it matters. The rest of the time, it is a waste of effort (see my MVP Tips essay on this topic!). And in almost all cases, for almost all parts of almost all programs, classic optimization no longer matters!
DLL Hell
The phenomenon of inconsistent mixes of DLLs leads to a condition known affectionately as "DLL Hell". Even Microsoft calls it this. The problem is that if Microsoft DLL A requires Microsoft DLL B, it is essential that it have the correct version of DLL B. Of course, all of this stems from a desire to not rename the DLLs on every release with a name that includes the rev level and version number or other useful indicators, but the result is that life becomes quite unbearable.
Microsoft has a Web site that allows you to determine if you have a consistent mix of DLLs. Check out http://msdn.microsoft.com/library/techart/dlldanger1.htm for articles about this. One of the nice features is that much of this is going away in Win2K and WinXP. However, some of it is still with us. Sometimes the release version of your code will be done in by a mismatch whereas the debug version is more resilient, for all the reasons already given.
However, there is one other lurking problem: a mix of DLLs that use the shared MFC library, and are both debug and release. If you are using DLLs of your own, that use the shared MFC library, make certain that all your DLLs are either debug or release! This means you should never, ever, under any circumstances rely on PATH or the implicit search path to locate DLLs (I find the whole idea of search paths to be a ill-thought-out kludge which is guaranteed to induce this sort of behavior; I never rely on the DLL load path except to load the standard Microsoft DLLs from %SYSTEM32%, and if you are using any kind of search path beyond that you deserve whatever happens to you! Note also that you must not, ever, under any circumstances imaginable, ever, put a DLL of your own in the %SYSTEM32% directory. For one thing, Win2K and WinXP will delete it anyway, because of "System32 Lockdown", a good idea that should have been forcefully implemented a decade ago).
Do not think that doing "static linking" of the MFC library is going to solve this problem! In fact, it actually makes the problem much worse, because you can end up with n disjoint copies of the MFC runtime, each one of which thinks it owns the world. A DLL must therefore either use the shared MFC library or use no MFC at all (the number of problems that occur if you have a private copy of the MFC library are too horrible to mention in an otherwise G-rated Web page, and in the interest of preserving keyboards I won't describe them in case any of you are eating when you read this. Well, how about one: the MFC Window Handle Map. Do you really want two or more copies of a handle map, each one of which can have disjoint images of what the window handle mapping, and try to reconcile the behavior of your program? I thought not).
However, it is very important to not have a mix of debug and release DLLs using MFC (note that a "straight", non-MFC release DLL can be called from a debug version of an MFC program; this happens all the time with the standard Microsoft libraries for OLE, WinSock, multimedia, etc.). The debug and release DLLs also have sufficiently different interfaces to MFC (I've not looked in detail, but I've had reports about problems) that you will get LoadLibrary failures, access faults, etc.
Not A Pretty Sight.
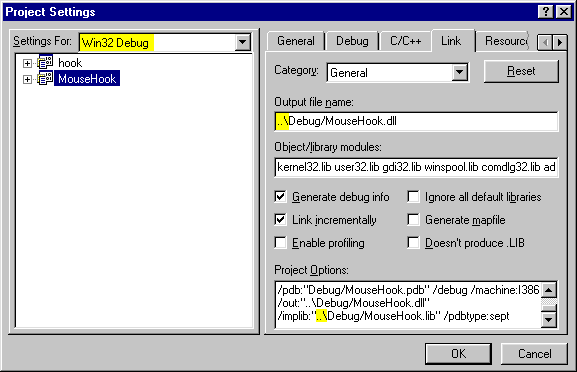
One way to avoid this is to have your DLL subprojects compile the DLLs into the main program's Debug and Release directories. The way I do this is to go into the DLL subproject, select Project Settings, select the Link tab, and put ".." in front of the path that is there. You have to do this independently in the Debug and Release configurations (and any custom configurations you may have).
I also hand-edit the command line to put the ".." in front of the path for the .lib file, making it easier to link as well.
Note the yellow areas highlighted in the image below. The top left shows the fact that I am working in the Debug configuration. The middle right shows the edit I made to the output file, and the lower right shows the hand-edit I made to redirect the .lib file.
Diagnostic Techniques
So the program fails, and you haven't a clue as to why. Well, there's some tricks you can try.
Turn off optimizations
One thing you can do is turn off all the optimizations in the release version. Go to the Project | Settings for the release version, choose the C/C++ tab, select Optimizations in the combo box, and simply turn off everything. Then do Build | Rebuild All and try again. If the bug went away, then you have a clue. No, you still don't know if it was an optimization bug in the strict sense, but you now know that the bug in your program is a consequence of an optimization transformation, which can be as simple as an uninitialized stack variable whose non-initialized value is sensitive to the optimization of the code. Not a lot of help, but you now know something more than you did before.
Turn on symbols
You can debug a release version of the program; just go into the C/C++ tab, select the General category, and select Program Database for Edit and Continue. You must also select the Link tab, and under the General category, check the Generate Debug Information box. In particular, if you have turned off optimization you have the same debugging environment that you had for the debug version, except you are running with the non-debug MFC shared library, so you can't single-step into the library functions. If you have not turned optimizations off, there are ways in which the debugger will lie to you about variable values, because the optimizations may make copies of variables in registers and not tell the debugger. Debugging optimized code can be hard, because you really can't be sure of what the debugger is telling you, but you can be further ahead with symbols (and line backtrace) than without them. Note that statements can be reordered, pulled out of loops, never computed, etc. in an optimized version, but the goal is that the code is semantically identical to the unoptimized version. You hope. But the rearrangement of the code makes it very difficult sometimes for the debugger to tell the exact line on which the error occurred. Be prepared for this. Generally, you'll find the errors are so blindingly obvious once you know more-or-less where to look that more detailed debugger information is not critical.
Enable/Disable Optimizations Selectively
You can use the Project | Settings to change the characteristics of a project selectively, on a file-by-file basis. My usual strategy is to disable all optimizations globally (in the release version), then selectively turn them back on only in those modules that matter, one at a time, until the problem reappears. At that point, you've got a good idea where the problem is. You can also apply pragmas to the project for very close optimization control.
Don't optimize
Here's a question to ask: does it matter? Here you are with a product to ship, a customer base, a deadline, and some really obscure bug that appears only in the release version! Why optimize at all? Does it really matter? If it doesn't, why are you wasting your time? Just turn off optimizations in the release version and recompile. Done. No fuss, no muss. A bit larger, a bit slower, but does it matter? Read my essay about optimization being your worst enemy.
Optimize only what counts
Generally, GUI code needs little or no optimization, for the reasons given in my essay. But as I point out in that essay, the inner loops really, really matter. Sometimes you can even selectively enable optimizations in the inner loop that you wouldn't dare enable globally in your program, such as telling a certain routine that no aliasing is possible. To do this, you can apply optimization pragmas around the routine.
For example, look in the compiler help under "pragmas", and the subtopic "affecting optimization". You will find a set of pointers into detailed discussions.
inline functions
You can cause any function to be expanded inline if the compiler judges this to have a suitable payoff. Just add the attribute inline to a function declaration. For C/C++, this requires that the function body be defined in the header file, e.g.,
class whatever { public: inline getPointer() { return p; } protected: something * p; }
A function will normally not be compiled inline unless the compiler has been asked to compile inline functions inline, and it has decided it is OK to do so. Go read the discussion in the manual. The compiler switches which enable optimization of inline expansion are set from the Project | Settings, select the C/C++ tab, select the Optimizations category, and select the type of optimization under the Inline function expansion dropdown. Usually doing /Ob1 is sufficient for a release version. Note that if your bug comes back, you've got a really good idea where to look.
intrinsic functions
The compiler knows that certain functions can be directly expanded as code. Functions that are implicitly inlineable include the following
_lrotl, _lrotr, _rotl, _rotr, _strset, abs, fabs, labs, memcmp, memcpy, memset, strcat, strcmp, strcpy, and
strlen
Note that there is very little advantage to implicitly expanding one of these to code unless it is already in a time-critical part of the program. Remember the essay: measure, measure, measure.
An intrinsic function often makes the code size larger, although the code is faster. If you need it, you can simply declare
#pragma intrinsic(strcmp)
and all invocations of strcmp which follow will be expanded as inline code. You can also use the /Oi compiler switch, which is set by Project | Settings, C/C++ tab, category Optimizations, and if you select Custom, select Generate Intrinsic Functions. You will probably never see a bug which occurs in optimized code because of intrinsic expansions.
Note that coding strcmp as a function call in your code can be a seriously losing idea anyway, if you ever think you might build a Unicode version of your app. You should be writing _tcscmp, which expands to strcmp in ANSI (8-bit character) applications and _wcscmp in Unicode (16-bit character) applications.
Really Tight Control
If you have a high-performance inner loop, you may want to tell the compiler that everything is safe. First, apply any const or volatile modifiers that would be necessary. Then turn on individual optimizations, such as
#pragma optimize("aw", on)
This tells the compiler that it can make a lot of deep assumptions about aliasing not being present. The result will be much faster, much tighter code. Do NOT tell the compiler, globally, to assume no aliasing! You are very likely to do yourself in because you have systematically violated this limitation all over the place (it is easy to do, and hard to find if you've done it). That's why you only want to do this sort of optimization in very restricted contexts, where you know you have total control over what is going on.
When I have to do this, I usually move the function to a file of its own, and only the function I want to optimize can therefore be affected.
Summary
This outlines some rationale and strategies for coping with the debug-vs-release problems that sometimes come up. The simplest one is often the best: just turn off all the optimizations in the release version. Then selectively turn on optimizations for that 1% of your code that might matter. Assuming there is that much of your code that matters. For a lot of the applications we write, so little code matters that you get virtually the same performance for optimized and unoptimized code.
Other References
Check out http://www.cygnus-software.com/papers/release_debugging.html for some additional useful insights by Bruce Dawson. A particularly nice point he makes here is that you should always generate debug symbol information with your release version, so you can actually debug problems in the product. I don't know why I never thought of this, but I didn't!
The views expressed in these essays are those of the author, and in no way represent, nor are they endorsed by, Microsoft.
Send mail to newcomer@flounder.com with questions or comments about this article.
Copyright © 1999 All Rights Reserved
www.flounder.com/mvp_tips.htm
License
This article has no explicit license attached to it but may contain usage terms in the article text or the download files themselves. If in doubt please contact the author via the discussion board below.
A list of licenses authors might use can be found here
Release和Debug模式下成员变量初始化问题 2012-07-10 20:28:03
分类: C/C++
原文:http://www.cppblog.com/lai3d/archive/2009/07/08/89514.html
未初始化的bool成员变量在Debug下默认值为false,Test下默认true。一个bug查了一晚上,原因就是这个.
人物创建的场景在Debug下正常,在Test和Release下不正常,就是镜头不对。然后就盯着这个载入场景的配置文件的代码看,ini不用了,换成xml看看,还是有问题!直接在代码里赋值,不用配置文件还是有问题!(之所以盯着这里看,是因为在Test下调试时发现读配置文件出来的值不对,但是用log打印出来却是对的!)于是否定了配置文件的问题,然后一想,既然是镜头的问题,就在setCamera(...)函数上打个断点不就行了,看哪里不该调用的时候调用了这个函数,Bingo!问题就找到了!丫的一未初始化的bool成员变量在Test下默认是true,我靠!
出来混,迟早要还的!写了成员变量,立马初始化才是正道,千万别偷懒或者忘了初始化!
另可参考:
[转]DEBUG和RELEASE版本差异及调试相关问题
Debug和Release有什么区别?怎么把Debug转成Release ?
1。Debug和Release有什么区别,为什么要使用Release版本!
2。怎么把Debug转成Release
转载:
Debug版本包括调试信息,所以要比Release版本大很多(可能大数百K至数M)。至于是否需要DLL支持,主要看你采用的编译选项。如果是基于ATL的,则Debug和Release版本对DLL的要求差不多。如果采用的编译选项为使用MFC动态库,则需要MFC42D.DLL等库支持,而Release版本需要MFC42.DLL支持。Release Build不对源代码进行调试,不考虑MFC的诊断宏,使用的是MFC Release库,编译十对应用程序的速度进行优化,而Debug Build则正好相反,它允许对源代码进行调试,可以定义和使用MFC的诊断宏,采用MFC
Debug库,对速度没有优化。
一、Debug 和 Release 编译方式的本质区别
Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序。Release 称为发布版本,它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户很好地使用。
Debug 和 Release 的真正秘密,在于一组编译选项。下面列出了分别针对二者的选项(当然除此之外还有其他一些,如/Fd /Fo,但区别并不重要,通常他们也不会引起 Release 版错误,在此不讨论)
Debug 版本:
/MDd /MLd 或 /MTd 使用 Debug runtime library(调试版本的运行时刻函数库)
/Od 关闭优化开关
/D "_DEBUG" 相当于 #define _DEBUG,打开编译调试代码开关(主要针对
assert函数)
/ZI 创建 Edit and continue(编辑继续)数据库,这样在调试过
程中如果修改了源代码不需重新编译
/GZ 可以帮助捕获内存错误
/Gm 打开最小化重链接开关,减少链接时间
Release 版本:
/MD /ML 或 /MT 使用发布版本的运行时刻函数库
/O1 或 /O2 优化开关,使程序最小或最快
/D "NDEBUG" 关闭条件编译调试代码开关(即不编译assert函数)
/GF 合并重复的字符串,并将字符串常量放到只读内存,防止
被修改
实际上,Debug 和 Release 并没有本质的界限,他们只是一组编译选项的集合,编译器只是按照预定的选项行动。事实上,我们甚至可以修改这些选项,从而得到优化过的调试版本或是带跟踪语句的发布版本。
二、哪些情况下 Release 版会出错
有了上面的介绍,我们再来逐个对照这些选项看看 Release 版错误是怎样产生的
1. Runtime Library:链接哪种运行时刻函数库通常只对程序的性能产生影响。调试版本的 Runtime Library 包含了调试信息,并采用了一些保护机制以帮助发现错误,因此性能不如发布版本。编译器提供的 Runtime Library 通常很稳定,不会造成 Release 版错误;倒是由于 Debug 的 Runtime Library 加强了对错误的检测,如堆内存分配,有时会出现 Debug 有错但 Release
正常的现象。应当指出的是,如果 Debug 有错,即使 Release 正常,程序肯定是有 Bug 的,只不过可能是 Release 版的某次运行没有表现出来而已。
2. 优化:这是造成错误的主要原因,因为关闭优化时源程序基本上是直接翻译的,而打开优化后编译器会作出一系列假设。这类错误主要有以下几种:
(1) 帧指针(Frame Pointer)省略(简称 FPO ):在函数调用过程中,所有调用信息(返回地址、参数)以及自动变量都是放在栈中的。若函数的声明与实现不同(参数、返回值、调用方式),就会产生错误————但 Debug 方式下,栈的访问通过 EBP 寄存器保存的地址实现,如果没有发生数组越界之类的错误(或是越界“不多”),函数通常能正常执行;Release 方式下,优化会省略 EBP 栈基址指针,这样通过一个全局指针访问栈就会造成返回地址错误是程序崩溃。C++
的强类型特性能检查出大多数这样的错误,但如果用了强制类型转换,就不行了。你可以在 Release 版本中强制加入 /Oy- 编译选项来关掉帧指针省略,以确定是否此类错误。此类错误通常有:
● MFC 消息响应函数书写错误。正确的应为
afx_msg LRESULT OnMessageOwn(WPARAM wparam, LPARAM lparam);
ON_MESSAGE 宏包含强制类型转换。防止这种错误的方法之一是重定义 ON_MESSAGE 宏,把下列代码加到 stdafx.h 中(在#include "afxwin.h"之后),函数原形错误时编译会报错
#undef ON_MESSAGE
#define ON_MESSAGE(message, memberFxn)
{ message, 0, 0, 0, AfxSig_lwl,
(AFX_PMSG)(AFX_PMSGW)(static_cast< LRESULT (AFX_MSG_CALL
CWnd::*)(WPARAM, LPARAM) > (&memberFxn) },
(2) volatile 型变量:volatile 告诉编译器该变量可能被程序之外的未知方式修改(如系统、其他进程和线程)。优化程序为了使程序性能提高,常把一些变量放在寄存器中(类似于 register 关键字),而其他进程只能对该变量所在的内存进行修改,而寄存器中的值没变。如果你的程序是多线程的,或者你发现某个变量的值与预期的不符而你确信已正确的设置了,则很可能遇到这样的问题。这种错误有时会表现为程序在最快优化出错而最小优化正常。把你认为可疑的变量加上 volatile 试试。
(3) 变量优化:优化程序会根据变量的使用情况优化变量。例如,函数中有一个未被使用的变量,在 Debug 版中它有可能掩盖一个数组越界,而在 Release 版中,这个变量很可能被优化调,此时数组越界会破坏栈中有用的数据。当然,实际的情况会比这复杂得多。与此有关的错误有:
● 非法访问,包括数组越界、指针错误等。例如
void fn(void)
{
int i;
i = 1;
int a[4];
{
int j;
j = 1;
}
a[-1] = 1;//当然错误不会这么明显,例如下标是变量
a[4] = 1;
}
j 虽然在数组越界时已出了作用域,但其空间并未收回,因而 i 和 j 就会掩盖越界。而 Release 版由于 i、j 并未其很大作用可能会被优化掉,从而使栈被破坏。
3. _DEBUG 与 NDEBUG :当定义了 _DEBUG 时,assert() 函数会被编译,而 NDEBUG 时不被编译。除此之外,VC++中还有一系列断言宏。这包括:
ANSI C 断言 void assert(int expression );
C Runtime Lib 断言 _ASSERT( booleanExpression );
_ASSERTE( booleanExpression );
MFC 断言 ASSERT( booleanExpression );
VERIFY( booleanExpression );
ASSERT_VALID( pObject );
ASSERT_KINDOF( classname, pobject );
ATL 断言 ATLASSERT( booleanExpression );
此外,TRACE() 宏的编译也受 _DEBUG 控制。
所有这些断言都只在 Debug版中才被编译,而在 Release 版中被忽略。唯一的例外是 VERIFY() 。事实上,这些宏都是调用了 assert() 函数,只不过附加了一些与库有关的调试代码。如果你在这些宏中加入了任何程序代码,而不只是布尔表达式(例如赋值、能改变变量值的函数调用 等),那么 Release 版都不会执行这些操作,从而造成错误。初学者很容易犯这类错误,查找的方法也很简单,因为这些宏都已在上面列出,只要利用 VC++ 的 Find in
Files 功能在工程所有文件中找到用这些宏的地方再一一检查即可。另外,有些高手可能还会加入 #ifdef _DEBUG 之类的条件编译,也要注意一下。
顺便值得一提的是 VERIFY() 宏,这个宏允许你将程序代码放在布尔表达式里。这个宏通常用来检查 Windows API 的返回值。有些人可能为这个原因而滥用 VERIFY() ,事实上这是危险的,因为 VERIFY() 违反了断言的思想,不能使程序代码和调试代码完全分离,最终可能会带来很多麻烦。因此,专家们建议尽量少用这个宏。
4. /GZ 选项:这个选项会做以下这些事
(1) 初始化内存和变量。包括用 0xCC 初始化所有自动变量,0xCD ( Cleared Data ) 初始化堆中分配的内存(即动态分配的内存,例如 new ),0xDD ( Dead Data ) 填充已被释放的堆内存(例如 delete ),0xFD( deFencde Data ) 初始化受保护的内存(debug 版在动态分配内存的前后加入保护内存以防止越界访问),其中括号中的词是微软建议的助记词。这样做的好处是这些值都很大,作为指针是不可能的(而且
32 位系统中指针很少是奇数值,在有些系统中奇数的指针会产生运行时错误),作为数值也很少遇到,而且这些值也很容易辨认,因此这很有利于在 Debug 版中发现 Release 版才会遇到的错误。要特别注意的是,很多人认为编译器会用 0 来初始化变量,这是错误的(而且这样很不利于查找错误)。
(2) 通过函数指针调用函数时,会通过检查栈指针验证函数调用的匹配性。(防止原形不匹配)
(3) 函数返回前检查栈指针,确认未被修改。(防止越界访问和原形不匹配,与第二项合在一起可大致模拟帧指针省略 FPO )
通常 /GZ 选项会造成 Debug 版出错而 Release 版正常的现象,因为 Release 版中未初始化的变量是随机的,这有可能使指针指向一个有效地址而掩盖了非法访问。
除此之外,/Gm /GF 等选项造成错误的情况比较少,而且他们的效果显而易见,比较容易发现。
--------------------------------------------------------------
Release是发行版本,比Debug版本有一些优化,文件比Debug文件小
Debug是调试版本,包括的程序信息更多
Release方法:
build->batch build->build就OK.
-----------------------------------------------------
一、"Debug是调试版本,包括的程序信息更多"
补充:只有DEBUG版的程序才能设置断点、单步执行、使用TRACE/ASSERT等调试输出语句。REALEASE不包含任何调试信息,所以体积小、运行速度快。
二、一般发布release的方法除了hzh_shat(水) 所说的之外,还可以project->Set Active Config,选中release版本。此后,按F5或F7编译所得的结果就是release版本。
Trackback: http://tb.donews.net/TrackBack.aspx?PostId=131016
----------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
VC下关于debug和release的不同的讨论
在使用VC开发软件的过程中,正当要享受那种兴奋的时候突然发现:release与debug运行结果不一致,甚至出错,而release又不方便调试,真的是当头一棒啊,可是疼归疼,问题总要解决,下面将讲述一下我的几点经验,看看是不是其中之一:
1. 变量。
大家都知道,debug跟release在初始化变量时所做的操作是不同的,debug是将每个字节位都赋成0xcc(注1),而release的赋值近似于随机(我想是直接从内存中分配的,没有初始化过)。这样就明确了,如果你的程序中的某个变量没被初始化就被引用,就很有可能出现异常:用作控制变量将导致流程导向不一致;用作数组下标将会使程序崩溃;更加可能是造成其他变量的不准确而引起其他的错误。所以在声明变量后马上对其初始化一个默认的值是最简单有效的办法,否则项目大了你找都没地方找。代码存在错误在debug方式下可能会忽略而不被察觉到,如debug方式下数组越界也大多不会出错,在release中就暴露出来了,这个找起来就比较难了:(
还是自己多加注意吧
2. 自定义消息的消息参数。
MFC为我们提供了很好的消息机制,更增加了自定义消息,好处我就不用多说了。这也存在debug跟release的问题吗?答案是肯定的。在自定义消息的函数体声明时,时常会看到这样的写法:afx_msg LRESULT OnMessageOwn(); Debug情况下一般不会有任何问题,而当你在Release下且多线程或进程间使用了消息传递时就会导致无效句柄之类的错误。导致这个错误直接原因是消息体的参数没有添加,即应该写成:afx_msg LRESULT OnMessageOwn(WPARAM wparam, LPARAM
lparam); (注2)
3. release模式下不出错,但debug模式下报错。
这种情况下大多也是因为代码书写不正确引起的,查看MFC的源码,可以发现好多ASSERT的语句(断言),这个宏只是在debug模式下才有效,那么就清楚了,release版不报错是忽略了错误而不是没有错误,这可能存在很大的隐患,因为是Debug模式下,比较方便调试,好好的检查自己的代码,再此就不多说了。
4. ASSERT, VERIFY, TRACE……….调试宏
这种情况很容易解释。举个例子:请在VC下输入ASSERT然后选中按F12跳到宏定义的地方,这里你就能够发现Debug中ASSERT要执行AfxAssertFailedLine,而Release下的宏定义却为”#define ASSERT(f) ((void)0)”。所以注意在这些调试宏的语句不要用程序相关变量如i++写操作的语句。VERIFY是个例外,”#define VERIFY(f) ((void)(f))”,即执行,这里的作用就不多追究了,有兴趣可自己研究:)。
总结:
Debug与Release不同的问题在刚开始编写代码时会经常发生,99%是因为你的代码书写错误而导致的,所以不要动不动就说系统问题或编译器问题,努力找找自己的原因才是根本。我从前就常常遇到这情况,经历过一次次的教训后我就开始注意了,现在我所写过的代码我已经好久没遇到这种问题了。下面是几个避免的方面,即使没有这种问题也应注意一下:
1. 注意变量的初始化,尤其是指针变量,数组变量的初始化(很大的情况下另作考虑了)。
2. 自定义消息及其他声明的标准写法
3. 使用调试宏时使用后最好注释掉
4. 尽量使用try - catch(…)
5. 尽量使用模块,不但表达清楚而且方便调试。
注1:
afc(afc) 网友提供:
debug版初始化成0xcc是因为0xcc在x86下是一条int 3单步中断指令,这样程序如果跑飞了遇到0xcc就会停下来,这和单片机编程时一般将没用的代码空间填入jmp 0000语句是一样地
注2:
不知大家有没有遇到过这种情况,具体原因我也不太清楚,是不是调用时按着默认的参数多分配了WPARAM+LPARAM的空间而破坏了应用程序的内存空间?还请高手来补充。
NightWolf 网友提供:我遇见过,好像是在函数调用的时候参数入栈的问题。因为MFC的消息使用宏写的,所以如果定义了OnMessage()的函数,编译能够通过,但是调用一次后,堆栈指针发生了偏移。然后就。。。
------------------------------------------------------------
_________________________________________________________
---------------------------------------------------------
[转]DEBUG和RELEASE版本差异及调试相关问题
1. 变量未初始化。下面的程序在debug中运行的很好。
thing * search(thing * something)
BOOL found;
for(int i = 0; i < whatever.GetSize(); i++)
{
if(whatever[i]->field == something->field)
{ /* found it */
found = TRUE;
break;
} /* found it */
}
if(found)
return whatever[i];
else
return NULL;
而在release中却不行,因为debug中会自动给变量初始化found=FALSE,而在release版中则不会。所以尽可能的给变量、类或结构初始化。
2. 数据溢出的问题
如:char buffer[10];
int counter;
lstrcpy(buffer, "abcdefghik");
在debug版中buffer的NULL覆盖了counter的高位,但是除非counter>16M,什么问题也没有。但是在release版中,counter可能被放在寄存器中,这样NULL就覆盖了buffer下面的空间,可能就是函数的返回地址,这将导致ACCESS ERROR。
3. DEBUG版和RELEASE版的内存分配方式是不同的 。如果你在DEBUG版中申请 ele 为 6*sizeof(DWORD)=24bytes,实际上分配给你的是32bytes(debug版以32bytes为单位分配), 而在release版,分配给你的就是24bytes(release版以8bytes为单位),所以在debug版中如果你写ele[6],可能不会有什么问题,而在release版中,就有ACCESS VIOLATE。
II. ASSERT和VERIFY
1. ASSERT在Release版本中是不会被编译的。
ASSERT宏是这样定义的
#ifdef _DEBUG
#define ASSERT(x) if( (x) == 0) report_assert_failure()
#else
#define ASSERT(x)
#endif
实际上复杂一些,但无关紧要。假如你在这些语句中加了程序中必须要有的代码
比如
ASSERT(pNewObj = new CMyClass);
pNewObj->MyFunction();
这种时候Release版本中的pNewObj不会分配到空间
所以执行到下一个语句的时候程序会报该程序执行了非法操作的错误。这时可以用VERIFY :
#ifdef _DEBUG
#define VERIFY(x) if( (x) == 0) report_assert_failure()
#else
#define VERIFY(x) (x)
#endif
这样的话,代码在release版中就可以执行了。
III. 参数问题:
自定义消息的处理函数,必须定义如下:
afx_msg LRESULT OnMyMessage(WPARAM, LPARAM);
返回值必须是HRESULT型,否则Debug会过,而Release出错
IV. 内存分配
保证数据创建和清除的统一性:如果一个DLL提供一个能够创建数据的函数,那么这个DLL同时应该提供一个函数销毁这些数据。数据的创建和清除应该在同一个层次上。
V. DLL的灾难
人们将不同版本DLL混合造成的不一致性形象的称为 “动态连接库的地狱“(DLL Hell) ,甚至微软自己也这么说http://msdn.microsoft.com/library/techart/dlldanger1.htm)。
如果你的程序使用你自己的DLL时请注意:
1. 不能将debug和release版的DLL混合在一起使用。debug都是debug版,release版都是release版。
解决办法是将debug和release的程序分别放在主程序的debug和release目录下
2. 千万不要以为静态连接库会解决问题,那只会使情况更糟糕。
VI. RELEASE板中的调试 :
1. 将ASSERT() 改为 VERIFY() 。找出定义在"#ifdef _DEBUG"中的代码,如果在RELEASE版本中需要这些代码请将他们移到定义外。查找TRACE(...)中代码,因为这些代码在RELEASE中也不被编译。 请认真检查那些在RELEASE中需要的代码是否并没有被便宜。
2. 变量的初始化所带来的不同,在不同的系统,或是在DEBUG/RELEASE版本间都存在这样的差异,所以请对变量进行初始化。
3. 是否在编译时已经有了警告?请将警告级别设置为3或4,然后保证在编译时没有警告出现.
VII. 将Project Settings" 中 "C++/C " 项目下优化选项改为Disbale(Debug)。编译器的优化可能导致许多意想不到的错误,请参http://www.pgh.net/~newcomer/debug_release.htm
1. 此外对RELEASE版本的软件也可以进行调试,请做如下改动:
在"Project Settings" 中 "C++/C " 项目下设置 "category" 为 "General" 并且将"Debug Info"设置为 "Program Database"。
在"Link"项目下选中"Generate Debug Info"检查框。
"Rebuild All"
如此做法会产生的一些限制:
无法获得在MFC DLL中的变量的值。
必须对该软件所使用的所有DLL工程都进行改动。
另:
MS BUG:MS的一份技术文档中表明,在VC5中对于DLL的"Maximize Speed"优化选项并未被完全支持,因此这将会引起内存错误并导致程序崩溃。
2. http://www.sysinternals.com/有一个程序DebugView,用来捕捉OutputDebugString的输出,运行起来后(估计是自设为system debugger)就可以观看所有程序的OutputDebugString的输出。此后,你可以脱离VC来运行你的程序并观看调试信息。
3. 有一个叫Gimpel Lint的静态代码检查工具,据说比较好用http://www.gimpel.com/ 不过要化$的。
参考文献:
1) http://www.cygnus-software.com/papers/release_debugging.html
2) http://www.pgh.net/~newcomer/debug_release.htm
常有人问DEBUG和RELEASE的区别以及RELEASE版难以调试。找到一篇总结文章。稍作修改。大家学习。
有不正确的地方大家补充。
DEBUG和RELEASE 版本差异及调试相关问题- -
I. 内存分配问题
1. 变量未初始化。下面的程序在debug中运行的很好。
thing * search(thing * something)
BOOL found;
for(int i = 0; i < whatever.GetSize(); i++)
{
if(whatever[i]->field == something->field)
{ /* found it */
found = TRUE;
break;
} /* found it */
}
if(found)
return whatever[i];
else
return NULL;
而在release中却不行,因为debug中会自动给变量初始化found=FALSE,而在release版中则不会。所以尽可能的给变量、类或结构初始化。
2. 数据溢出的问题
如:char buffer[10];
int counter;
lstrcpy(buffer, "abcdefghik");
在debug版中buffer的NULL覆盖了counter的高位,但是除非counter>16M,什么问题也没有。但是在release版中,counter可能被放在寄存器中,这样NULL就覆盖了buffer下面的空间,可能就是函数的返回地址,这将导致ACCESS ERROR。
3. DEBUG版和RELEASE版的内存分配方式是不同的 。如果你在DEBUG版中申请 ele 为 6*sizeof(DWORD)=24bytes,实际上分配给你的是32bytes(debug版以32bytes为单位分配), 而在release版,分配给你的就是24bytes(release版以8bytes为单位),所以在debug版中如果你写ele[6],可能不会有什么问题,而在release版中,就有ACCESS VIOLATE。
II. ASSERT和VERIFY
1. ASSERT在Release版本中是不会被编译的。
ASSERT宏是这样定义的
#ifdef _DEBUG
#define ASSERT(x) if( (x) == 0) report_assert_failure()
#else
#define ASSERT(x)
#endif
实际上复杂一些,但无关紧要。假如你在这些语句中加了程序中必须要有的代码
比如
ASSERT(pNewObj = new CMyClass);
pNewObj->MyFunction();
这种时候Release版本中的pNewObj不会分配到空间
所以执行到下一个语句的时候程序会报该程序执行了非法操作的错误。这时可以用VERIFY :
#ifdef _DEBUG
#define VERIFY(x) if( (x) == 0) report_assert_failure()
#else
#define VERIFY(x) (x)
#endif
这样的话,代码在release版中就可以执行了。
III.参数问题:
自定义消息的处理函数,必须定义如下:
afx_msg LRESULT OnMyMessage(WPARAM, LPARAM);
返回值必须是HRESULT型,否则Debug会过,而Release出错、同时,WPARAM,LPARAM这两个参数一定要申明,否则Release版本能运行,但肯定错误。切记。
IV. 内存分配
保证数据创建和清除的统一性:如果一个DLL提供一个能够创建数据的函数,那么这个DLL同时应该提供一个函数销毁这些数据。数据的创建和清除应该在同一个层次上。
V. DLL的灾难
人们将不同版本DLL混合造成的不一致性形象的称为 "动态连接库的地狱"(DLL Hell) ,甚至微软自己也这么说(http://msdn.microsoft.com/library/techart/dlldanger1.htm)。
如果你的程序使用你自己的DLL时请注意:
1. 不能将debug和release版的DLL混合在一起使用。debug都是debug版,release版都是release版。
解决办法是将debug和release的程序分别放在主程序的debug和release目录下
2. 千万不要以为静态连接库会解决问题,那只会使情况更糟糕。
VI. RELEASE板中的调试 :
1. 将ASSERT() 改为 VERIFY() 。找出定义在"#ifdef _DEBUG"中的代码,如果在RELEASE版本中需要这些代码请将他们移到定义外。查找TRACE(...)中代码,因为这些代码在RELEASE中也不被编译。 请认真检查那些在RELEASE中需要的代码是否并没有被便宜。
2. 变量的初始化所带来的不同,在不同的系统,或是在DEBUG/RELEASE版本间都存在这样的差异,所以请对变量进行初始化。
3. 是否在编译时已经有了警告?请将警告级别设置为3或4,然后保证在编译时没有警告出现.
VII. 将Project Settings" 中 "C++/C " 项目下优化选项改为Disbale(Debug)。编译器的优化可能导致许多意想不到的错误,请参考http://www.pgh.net/~newcomer/debug_release.htm
1. 此外对RELEASE版本的软件也可以进行调试,请做如下改动:
在"Project Settings" 中 "C++/C " 项目下设置 "category" 为 "General" 并且将"Debug Info"设置为 "Program Database"。
在"Link"项目下选中"Generate Debug Info"检查框。
"Rebuild All"
如此做法会产生的一些限制:
无法获得在MFC DLL中的变量的值。
必须对该软件所使用的所有DLL工程都进行改动。
另:
MS BUG:MS的一份技术文档中表明,在VC5中对于DLL的"Maximize Speed"优化选项并未被完全支持,因此这将会引起内存错误并导致程序崩溃。
2. www.sysinternals.com有一个程序DebugView,用来捕捉OutputDebugString的输出,运行起来后(估计是自设为system debugger)就可以观看所有程序的OutputDebugString的输出。此后,你可以脱离VC来运行你的程序并观看调试信息。
3. 有一个叫Gimpel Lint的静态代码检查工具,据说比较好用。http://www.gimpel.com 不过要化$的。
参考文献:
1) http://www.cygnus-software.com/papers/release_debugging.html
2) http://www.pgh.net/~newcomer/debug_release.htm
//z 2013-07-16 19:09:30 IS2120@BG57IV3.T40682136 .K[T83,L895,R28,V1279]
Debug 运行正常,Release版本不能正常运行 收藏
http://blog.csdn.net/ruifangcui7758/archive/2010/10/18/5948611.aspx
引言
如果在您的开发过程中遇到了常见的错误,或许您的Release版本不能正常运行而Debug版本运行无误,那么我推荐您阅读本文:因为并非如您想象的那样,Release版本可以保证您的应用程序可以象Debug版本一样运行。 如果您在开发阶段完成之后或者在开发进行一段时间之内从来没有进行过Release版本测试,然而当您测试的时候却发现问题,那么请看我们的调试规则1:
规则1:
经常性对开发软件进行Debug和Release版本的常规测试. 测试Release版本的时间间隔越长,排除问题的难度越大,至少对Release版本进行每周1次的测试,可以使您在紧凑的开发周期内节省潜在的排故时间. 不要随意删除Release版本需要的代码这点看起来似乎再明显不过,但却是开发人员无意中经常犯的错误,原因在于编译器编译Release版本时候会主动排除在代码中存在的宏,例如ASSERT和TRACE在Release版本会自动排除,这样导致的问题是您在这些宏当中运行的代码也被随之删除,这是非常危险的事情J,例如:
ASSERT(m_ImageList.Create(MAKEINTRESOURCE(IDB_IMAGES), 16, 1, RGB(255,255,255))); 这样的代码在Debug模式不会出错,图像列表也自动创建了,然而在Release版本呢?后继使用m_ImageList对象只会造成程序的Crash!,因此ASSERT宏中尽量使用逻辑运算符作为验证。
规则 2:
不要将代码放置在仅在某种编译选项中执行的地方,对于使用_DEBUG等编译选项宏内部的代码必须不影响整个程序的使用。
规则 3:
不要使用规则2作为评判标准来删除ASSERT宏,ASSERT宏是个有用的工具,但容易使用错误. 使Debug编译模式接近Release模式如果您的Release版本存在的问题是由代码被编译器自动排除造成的,那么通过这个方法您的问题可能会重现. 一些问题的产生可能是由于不同编译选项之间预定义符号造成的,因此您可以更改编译模式下的预定义符号,从而使您的Debug模式接近Release模式,观察错误是否产生,更改编译预定义符号方法如下: a.. Alt-F7打开项目设置,在C++/C
页面,选择"General"类别,更改"_DEBUG"符号为"NDEBUG". b.. 在C++/C 页面, 选择"Preprocessor"类别,添加预定义符号"_DEBUG"到"Undefined Symbols"栏. c.. 使用"Rebuild All"重新编译如果通过上面设置,您在Release编译模式下面的问题在Debug模式下重现,那么请您依据以下步骤对您的代码进行修改: a.. 查找ASSERT排除其中的所有重要执行语句,或者将ASSERT修改为VERIFY. b.. 检查"#ifdef _DEBUG"
内所有代码,排除Release模式使用的代码. c.. 查找TRACE 排除其中的所有重要执行语句. TRACE和ASSERT一样,仅在Debug模式下编译. 如果通过上面修改更正了您在Debug模式下的问题,那么您可以重新编译Release模式,非常有可能您可以解决先前存在的问题!. 错误的假定造成编译模式错误您是否经常性的假定您的变量或者对象被初试化成某个指定的值(可能0)?您是否假定你所有关联到的资源在应用程序中都存在?这些也是Debug和Release模式下不同问题产生的原因。
规则 4:
除非您在代码中对变量进行初始化,否则不能作出如上假定. 包括全局变量,自动变量,申请对象和new对象. 这种情况还常常发生在内存顺序的问题,记得原来使用结构体的时候为了使用方便,比较两个结构体对象使用memcmp,在Debug版本工作正常,而Release版本计算出错误的解,看来的确不能进行错误的假定!
规则 5:
确保删除资源的所有引用都被删除,例如resource.h中的定义. 软件开发中,不同编译版本对变量和内存的初始化是不同的. 如果您假定变量初始化为0,那么在Win9x系统的Release模式下,会出现异常现象。因此对所有变量,内存显式清0是较为安全的做法. 如果您引用了已经被删除的资源,您的Debug版本可以正常工作,但是Release版本可能会crash. 您是否相信编译器? 编译器警告级别和编译噪音有着相当大的关系. 通过提高编译器警告级别可增加程序隐藏问题暴露的机会.通常设置警告级别在"Level
3"或者 "Level 4".编译并解决所有警告,这是发布Release版本应用程序的一个很好的建议.这能暴露会使您的应用程序出现问题的很多初始化问题和其它潜在的错误.
规则 6:
开始项目之前先将编译警告级别设置在"Level 3" 或者 "Level 4" ,登记代码之前确保消灭所有警告!. 总结报告编译模式下的调试曾经不止一次的听到一些VC开发者说Release模式下面不能进行调试, 规则 7:
当前面所有的方法都无效的时候,在Release模式下面进行调试. Release模式可以进行调试,第一步是打开符号表: a.. Alt-F7打开项目设置,在C++/C 页面,选择"General"类,修改Debug Info setting 为 "Program Database". b.. 在"Link" 页面,选择"Generate Debug Info". c.. "Rebuild All" 这些设置将允许您在Release模式下保留符号表,您也可以同时考虑以下设置: a.. 调试Release版本应用程序,您可以关闭优化选项. b.. 如果在Release模式下面不能设置断点,添加指令"__asm {int 3}" 可以使您的应用程序在该行停止(确定在发布应用程序时候排除这些代码). 在Release模式进行调试的几个限制. a. b.. 同上,想要调试调用的dll,您必须给它们全部加上调试信息和符号表. 编译器生成了错误的代码? 或许有的时候您会发现VC++编译器生成了’问题代码’,. 如果这个操作解决了您的问题,. 举个例子,下面的代码在Debug模式似乎一切’正常’,而在Release模式下面却会出错!
#include int* func1()
{
int retval = 5;
return &retval;
}
int main(int argc, char* argv[])
{
printf("%d ", *func1());
return 0;
}
我相信大多数程序员尤其是初学者容易遇到此类情况的。
规则 8:
。
规则 9:
如果您已经彻底检查了您的代码,并且没有发现问题,那么您最好逐个打开优化选项将产生错误的原因限制在某个范围之内. BTW- 以上问题代码由C++编译器自动检出. 如果您已经遵循 规则 6 您或许在前面环节中已经解决了这些问题. 凭我的开发经验,编译器极少会产生错误的代码(当然要注意接口程序边界对齐的问题).通常在使用模板类时候VC6编译器或许会产生断言ASSERT错误,这种情况您只需更新补丁即可解决。
最后的思考在日常编码中只需稍微增加一点严格的检测,便能有效的避免新的Debug -v- Release模式问题的产生,以下是我的一些经验。
1. 取出(check out)需要修改的代码。
2. 修改代码,排除所有警告,编译Debug和Release版本.
3. 详细测试新代码,即单步调试新代码段之后进入工作代码,确保代码无误.
4. 更正所有问题.
5. 确认无误之后将新代码登记入库(check in).
6. 对登记入库的代码进行全新的编译,确保新登记代码与其它代码融合.
7. 重新详细测试代码.
8. 更正新问题(或许可以发现登记入库代码存在的问题) 严格按照以上步骤,您在设计开发过程中即可解决大量问题,避免在最后发布应用程序时候产生新的难以定位的问题. 后记本文是在我的开发历程中遇到Release版本应用程序发布,产生错误的时候苦苦求索得到的一些经验,原文来自于,经过本人润色,改写成为适合国内开发者的文章,希望能对大家有用,谢谢! 转载: Debug版本包括调试信息,所以要比Release版本大很多(可能大数百K至数M)。至于是否需要DLL支持,主要看你采用的编译选项。如果是基于ATL的,则Debug和Release版本对DLL的要求差不多。如果采用的编译选项为使用MFC动态库,则需要MFC42D.DLL等库支持,而Release版本需要MFC42.DLL支持。Release
Build不对源代码进行调试,不考虑MFC的诊断宏,使用的是MFC Release库,编译十对应用程序的速度进行优化,而Debug Build则正好相反,它允许对源代码进行调试,可以定义和使用MFC的诊断宏,采用MFC Debug库,对速度没有优化。
一、Debug 和 Release 编译方式的本质区别 Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序。Release 称为发布版本,它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户很好地使用。 Debug 和 Release 的真正秘密,在于一组编译选项。下面列出了分别针对二者的选项(当然除此之外还有其他一些,如/Fd /Fo,但区别并不重要,通常他们也不会引起 Release 版错误,在此不讨论) Debug 版本: /MDd /MLd 或 /MTd
使用 Debug runtime library(调试版本的运行时刻函数库) /Od 关闭优化开关 /D "_DEBUG" 相当于 #define _DEBUG,打开编译调试代码开关(主要针对 assert函数) /ZI 创建 Edit and continue(编辑继续)数据库,这样在调试过 程中如果修改了源代码不需重新编译 /GZ 可以帮助捕获内存错误 /Gm 打开最小化重链接开关,减少链接时间 Release 版本: /MD /ML 或 /MT 使用发布版本的运行时刻函数库 /O1 或 /O2 优化开关,使程序最小或最快
/D "NDEBUG" 关闭条件编译调试代码开关(即不编译assert函数) /GF 合并重复的字符串,并将字符串常量放到只读内存,防止 被修改 实际上,Debug 和 Release 并没有本质的界限,他们只是一组编译选项的集合,编译器只是按照预定的选项行动。事实上,我们甚至可以修改这些选项,从而得到优化过的调试版本或是带跟踪语句的发布版本。
二、哪些情况下 Release 版会出错 有了上面的介绍,我们再来逐个对照这些选项看看 Release 版错误是怎样产生的 1. Runtime Library:链接哪种运行时刻函数库通常只对程序的性能产生影响。调试版本的 Runtime Library 包含了调试信息,并采用了一些保护机制以帮助发现错误,因此性能不如发布版本。编译器提供的 Runtime Library 通常很稳定,不会造成 Release 版错误;倒是由于 Debug 的 Runtime Library 加强了对错误的检测,如堆内存分配,有时会出现
Debug 有错但 Release 正常的现象。应当指出的是,如果 Debug 有错,即使 Release 正常,程序肯定是有 Bug 的,只不过可能是 Release 版的某次运行没有表现出来而已。 2. 优化:这是造成错误的主要原因,因为关闭优化时源程序基本上是直接翻译的,而打开优化后编译器会作出一系列假设。这类错误主要有以下几种:
(1) 帧指针(Frame Pointer)省略(简称 FPO ):在函数调用过程中,所有调用信息(返回地址、参数)以及自动变量都是放在栈中的。若函数的声明与实现不同(参数、返回值、调用方式),就会产生错误――――但 Debug 方式下,栈的访问通过 EBP 寄存器保存的地址实现,如果没有发生数组越界之类的错误(或是越界“不多”),函数通常能正常执行;Release 方式下,优化会省略 EBP 栈基址指针,这样通过一个全局指针访问栈就会造成返回地址错误是程序崩溃。C++ 的强类型特性能检查出大多数这样的错误,但如果用了强制类型转换,就不行了。你可以在
Release 版本中强制加入 /Oy- 编译选项来关掉帧指针省略,以确定是否此类错误。此类错误通常有: ● MFC 消息响应函数书写错误。正确的应为 afx_msg LRESULT OnMessageOwn(WPARAM wparam, LPARAM lparam); ON_MESSAGE 宏包含强制类型转换。防止这种错误的方法之一是重定义 ON_MESSAGE 宏,把下列代码加到 stdafx.h 中(在#include "afxwin.h"之后),函数原形错误时编译会报错 #undef ON_MESSAGE
#define ON_MESSAGE(message, memberFxn) { message, 0, 0, 0, AfxSig_lwl, (AFX_PMSG)(AFX_PMSGW)(static_cast< LRESULT (AFX_MSG_CALL CWnd::*)(WPARAM, LPARAM) > (&memberFxn) }, (2) volatile 型变量:volatile 告诉编译器该变量可能被程序之外的未知方式修改(如系统、其他进程和线程)。优化程序为了使程序性能提高,常把一些变量放在寄存器中(类似于
register 关键字),而其他进程只能对该变量所在的内存进行修改,而寄存器中的值没变。如果你的程序是多线程的,或者你发现某个变量的值与预期的不符而你确信已正确的设置了,则很可能遇到这样的问题。这种错误有时会表现为程序在最快优化出错而最小优化正常。把你认为可疑的变量加上 volatile 试试。
(3) 变量优化:优化程序会根据变量的使用情况优化变量。例如,函数中有一个未被使用的变量,在 Debug 版中它有可能掩盖一个数组越界,而在 Release 版中,这个变量很可能被优化调,此时数组越界会破坏栈中有用的数据。当然,实际的情况会比这复杂得多。与此有关的错误有: ● 非法访问,包括数组越界、指针错误等。例如 void fn(void) { int i; i = 1; int a[4]; { int j; j = 1; } a[-1] = 1;//当然错误不会这么明显,例如下标是变量 a[4] = 1;
} j 虽然在数组越界时已出了作用域,但其空间并未收回,因而 i 和 j 就会掩盖越界。而 Release 版由于 i、j 并未其很大作用可能会被优化掉,从而使栈被破坏。 3. _DEBUG 与 NDEBUG :当定义了 _DEBUG 时,assert() 函数会被编译,而 NDEBUG 时不被编译。除此之外,VC++中还有一系列断言宏。这包括: ANSI C 断言 void assert(int expression ); C Runtime Lib 断言 _ASSERT( booleanExpression
); _ASSERTE( booleanExpression ); MFC 断言 ASSERT( booleanExpression ); VERIFY( booleanExpression ); ASSERT_VALID( pObject ); ASSERT_KINDOF( classname, pobject ); ATL 断言 ATLASSERT( booleanExpression ); 此外,TRACE() 宏的编译也受 _DEBUG 控制。 所有这些断言都只在 Debug版中才被编译,而在 Release
版中被忽略。唯一的例外是 VERIFY() 。事实上,这些宏都是调用了 assert() 函数,只不过附加了一些与库有关的调试代码。如果你在这些宏中加入了任何程序代码,而不只是布尔表达式(例如赋值、能改变变量值的函数调用 等),那么 Release 版都不会执行这些操作,从而造成错误。初学者很容易犯这类错误,查找的方法也很简单,因为这些宏都已在上面列出,只要利用 VC++ 的 Find in Files 功能在工程所有文件中找到用这些宏的地方再一一检查即可。另外,有些高手可能还会加入 #ifdef _DEBUG
之类的条件编译,也要注意一下。 顺便值得一提的是 VERIFY() 宏,这个宏允许你将程序代码放在布尔表达式里。这个宏通常用来检查 Windows API 的返回值。有些人可能为这个原因而滥用 VERIFY() ,事实上这是危险的,因为 VERIFY() 违反了断言的思想,不能使程序代码和调试代码完全分离,最终可能会带来很多麻烦。因此,专家们建议尽量少用这个宏。 4. /GZ 选项:这个选项会做以下这些事 (1) 初始化内存和变量。包括用 0xCC 初始化所有自动变量,0xCD ( Cleared Data
) 初始化堆中分配的内存(即动态分配的内存,例如 new ),0xDD ( Dead Data ) 填充已被释放的堆内存(例如 delete ),0xFD( deFencde Data ) 初始化受保护的内存(debug 版在动态分配内存的前后加入保护内存以防止越界访问),其中括号中的词是微软建议的助记词。这样做的好处是这些值都很大,作为指针是不可能的(而且 32 位系统中指针很少是奇数值,在有些系统中奇数的指针会产生运行时错误),作为数值也很少遇到,而且这些值也很容易辨认,因此这很有利于在 Debug 版中发现
Release 版才会遇到的错误。要特别注意的是,很多人认为编译器会用 0 来初始化变量,这是错误的(而且这样很不利于查找错误)。 (2) 通过函数指针调用函数时,会通过检查栈指针验证函数调用的匹配性。(防止原形不匹配) (3) 函数返回前检查栈指针,确认未被修改。(防止越界访问和原形不匹配,与第二项合在一起可大致模拟帧指针省略 FPO ) 通常 /GZ 选项会造成 Debug 版出错而 Release 版正常的现象,因为 Release 版中未初始化的变量是随机的,这有可能使指针指向一个有效地址而掩盖了非法访问。
除此之外,/Gm /GF 等选项造成错误的情况比较少,而且他们的效果显而易见,比较容易发现。
在使用VC开发软件的过程中,正当要享受那种兴奋的时候突然发现: release与debug运行结果不一致,甚至出错,而release又不方便调试,真的是当头一棒啊,可是疼归疼,问题总要解决,下面将讲述一下我的两点经验,看看是不是其中之一:
1. 变量。大家都知道,debug跟release在初始化变量时所做的操作是不同的,debug是将每个字节位都赋成0xcc,而release的赋值近似于随机(我想是直接从内存中分配的,没有初始化过,但debug为什么不是0xff或0x00或其他什么的就不得而知了)。这样就明确了,如果你的程序中的某个变量没被初始化就被引用,就很有可能出现异常:用作控制变量将导致流程导向不一致;用作数组下标将会使程序崩溃;更加可能是造成其他变量的不准确而引起其他的错误。所以在声明变量后马上对其初始化一个默认的值是最简单有效的办法,否则项目大了你找都没地方找。代码存在错误在debug方式下可能会忽略而不被察觉到,如debug方式下数组越界也大多不会出错,在release中就暴露出来了,这个找起来就比较难了:( 还是自己多加注意吧 2. 自定义消息的消息参数。 MFC为我们提供了很好的消息机制,更增加了自定义消息,好处我就不用多说了。这也存在debug跟release的问题吗?答案是肯定的。在自定义消息的函数体声明时,时常会看到这样的写法:afx_msg LRESULT OnMessageOwn(); 当你在多线程或进程间使用了消息传递时就会导致无效句柄之类的错误。这个原因就是消息体的参数没有添加,即应该写成:afx_msg LRESULT OnMessageOwn(WPARAM wparam, LPARAM lparam); (具体原因我也不太清楚,是不是因为调用时按着默认的参数多分配了WPARAM+LPARAM的空间而破坏了应用程序的内存空间?还请高手多指点)
避免的方法:
1. 注意变量的初始化
2. 自定义消息的标准写法
3. 使用调试语句TRACE等时使用后最好注释掉
4. 尽量使用try - catch(...)
VERIFY 和 ASSERT 的区别:一个在Release下面可以执行,一个不可以
DEBUG和RELEASE 版本差异及调试相关问题: 内存分配问题 1. 变量未初始化。下面的程序在debug中运行的很好。
thing * search(thing * something)
BOOL found;
for(int i = 0; i < whatever.GetSize(); i++)
{
if(whatever[i]->field == something->field)
{ /* found it */ found = TRUE; break; }
/* found it */
}
if(found)
return whatever[i];
else
return NULL;
而在release中却不行,因为debug中会自动给变量初始化found=FALSE,而在release版中则不会。所以尽可能的给变量、类或结构初始化。
2. 数据溢出的问题 如:char buffer[10]; int counter; lstrcpy(buffer, "abcdefghik"); 在debug版中buffer的NULL覆盖了counter的高位,但是除非counter>16M,什么问题也没有。但是在release版中,counter可能被放在寄存器中,这样NULL就覆盖了buffer下面的空间,可能就是函数的返回地址,这将导致ACCESS ERROR。
3. DEBUG版和RELEASE版的内存分配方式是不同的 。如果你在DEBUG版中申请 ele 为 6*sizeof(DWORD)=24bytes,实际上分配给你的是32bytes(debug版以32bytes为单位分配), 而在release版,分配给你的就是24bytes(release版以8bytes为单位),所以在debug版中如果你写ele[6],可能不会有什么问题,而在release版中,就有ACCESS VIOLATE。 II. ASSERT和VERIFY 1. ASSERT在Release版本中是不会被编译的。 ASSERT宏是这样定义的 #ifdef _DEBUG #define ASSERT(x) if( (x) == 0) report_assert_failure() #else #define ASSERT(x) #endif 实际上复杂一些,但无关紧要。假如你在这些语句中加了程序中必须要有的代码 比如 ASSERT(pNewObj = new CMyClass); pNewObj->MyFunction(); 这种时候Release版本中的pNewObj不会分配到空间 所以执行到下一个语句的时候程序会报该程序执行了非法操作的错误。这时可以用VERIFY : #ifdef _DEBUG #define VERIFY(x) if( (x) == 0) report_assert_failure() #else #define VERIFY(x) (x) #endif 这样的话,代码在release版中就可以执行了。 III. 参数问题: 自定义消息的处理函数,必须定义如下: afx_msg LRESULT OnMyMessage(WPARAM, LPARAM); 返回值必须是HRESULT型,否则Debug会过,而Release出错 IV. 内存分配 保证数据创建和清除的统一性:如果一个DLL提供一个能够创建数据的函数,那么这个DLL同时应该提供一个函数销毁这些数据。数据的创建和清除应该在同一个层次上。 V. DLL的灾难 人们将不同版本DLL混合造成的不一致性形象的称为 “动态连接库的地狱“(DLL Hell) ,甚至微软自己也这么说(http://msdn.microsoft.com/library/techart/dlldanger1.htm)。 如果你的程序使用你自己的DLL时请注意: 1.不能将debug和release版的DLL混合在一起使用。debug都是debug版,release版都是release版。 解决办法是将debug和release的程序分别放在主程序的debug和release目录下 2.千万不要以为静态连接库会解决问题,那只会使情况更糟糕。 VI. RELEASE板中的调试 : 1.将ASSERT() 改为 VERIFY() 。找出定义在"#ifdef _DEBUG"中的代码,如果在RELEASE版本中需要这些代码请将他们移到定义外。查找TRACE(...)中代码,因为这些代码在RELEASE中也不被编译。 请认真检查那些在RELEASE中需要的代码是否并没有被便宜。 2.变量的初始化所带来的不同,在不同的系统,或是在DEBUG/RELEASE版本间都存在这样的差异,所以请对变量进行初始化。 3.是否在编译时已经有了警告?请将警告级别设置为3或4,然后保证在编译时没有警告出现. VII. 将Project Settings" 中 "C++/C " 项目下优化选项改为Disbale(Debug)。编译器的优化可能导致许多意想不到的错误,请参考http://www.pgh.net/~newcomer/debug_release.htm 1Debug和Release区别
VC下Debug和Release区别
最近写代码过程中,发现 Debug 下运行正常,Release 下就会出现问题,百思不得其解,而Release 下又无法进行调试,于是只能采用printf方式逐步定位到问题所在处,才发现原来是给定的一个数组未初始化,导致后面处理异常。网上查找了些资料,在这 罗列汇总下,做为备忘~
一、Debug 和 Release 的区别
Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序。Release 称为发布版本,它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户很好地使用。
Debug 和 Release 的真正区别,在于一组编译选项。
Debug 版本
参数 含义
/MDd /MLd 或 /MTd 使用 Debug runtime library(调试版本的运行时刻函数库)
/Od 关闭优化开关
/D "_DEBUG" 相当于 #define _DEBUG,打开编译调试代码开关(主要针对assert函数)
/ZI
创建 Edit and continue(编辑继续)数据库,这样在调试过程中如果修改了源代码不需重新编译
GZ 可以帮助捕获内存错误
Release 版本 参数含义
/MD /ML 或 /MT 使用发布版本的运行时刻函数库
/O1 或 /O2 优化开关,使程序最小或最快
/D "NDEBUG" 关闭条件编译调试代码开关(即不编译assert函数)
/GF 合并重复的字符串,并将字符串常量放到只读内存,防止被修改
Debug 和 Release 并没有本质的界限,他们只是一组编译选项的集合,编译器只是按照预定的选项行动。
相关经验: 转自http://dev.csdn.net/article/17/17068.shtm
1. 变量。
大家都知道,debug跟release在初始化变量时所做的操作是不同的,debug是将每个字节位都赋成0xcc(注1),而release的赋值近 似于随机(我想是直接从内存中分配的,没有初始化过)。这样就明确了,如果你的程序中的某个变量没被初始化就被引用,就很有可能出现异常:用作控制变量将 导致流程导向不一致;用作数组下标将会使程序崩溃;更加可能是造成其他变量的不准确而引起其他的错误。所以在声明变量后马上对其初始化一个默认的值是最简 单有效的办法,否则项目大了你找都没地方找。代码存在错误在debug方式下可能会忽略而不被察觉到,如debug方式下数组越界也大多不会出错,在
release中就暴露出来了,这个找起来就比较难了:( 还是自己多加注意吧
呵呵,就是我犯的问题~~
2. 自定义消息的消息参数。
MFC为我们提供了很好的消息机制,更增加了自定义消息,好处我就不用多说了。这也存在debug跟release的问题吗?答案是肯定的。在自定义消息 的函数体声明时,时常会看到这样的写法:afx_msg LRESULT OnMessageOwn(); Debug情况下一般不会有任何问题,而当你在Release下且多线程或进程间使用了消息传递时就会导致无效句柄之类的错误。导致这个错误直接原因是消 息体的参数没有添加,即应该写成:afx_msg LRESULT OnMessageOwn(WPARAM wparam,
LPARAM lparam); (注2)
3. release模式下不出错,但debug模式下报错。
这种情况下大多也是因为代码书写不正确引起的,查看MFC的源码,可以发现好多ASSERT的语句(断言),这个宏只是在debug模式下才有效,那么就 清楚了,release版不报错是忽略了错误而不是没有错误,这可能存在很大的隐患,因为是Debug模式下,比较方便调试,好好的检查自己的代码,再此 就不多说了。
4. ASSERT, VERIFY, TRACE..........调试宏
这种情况很容易解释。举个例子:请在VC下输入ASSERT然后选中按F12跳到宏定义的地方,这里你就能够发现Debug中ASSERT要执行 AfxAssertFailedLine,而Release下的宏定义却为"#define ASSERT(f) ((void)0)"。所以注意在这些调试宏的语句不要用程序相关变量如i++写操作的语句。VERIFY是个例外,"#define VERIFY(f) ((void)(f))",即执行,这里的作用就不多追究了,有兴趣可自己研究:)。
Debug与Release不同的问题在刚开始编写代码时会经常发生,99%是因为你的代码书写错误而导致的,所以不要动不动就说系统问题或编译器问题, 努力找找自己的原因才是根本。我从前就常常遇到这情况,经历过一次次的教训后我就开始注意了,现在我所写过的代码我已经好久没遇到这种问题了。下面是几个 避免的方面,即使没有这种问题也应注意一下:
1. 注意变量的初始化,尤其是指针变量,数组变量的初始化(很大的情况下另作考虑了)。
2. 自定义消息及其他声明的标准写法
3. 使用调试宏时使用后最好注释掉
4. 尽量使用try - catch(...)
5. 尽量使用模块,不但表达清楚而且方便调试。
注1:
debug版初始化成0xcc是因为0xcc在x86下是一条int 3单步中断指令,这样程序如果跑飞了遇到0xcc就会停下来,这和单片机编程时一般将没用的代码空间填入jmp 0000语句是一样地转贴于:计算机二级考试_考试大【责编:drfcy 纠错】
[VC]DEBUG和RELEASE2007年08月26日 星期日 下午 04:33 I. 内存分配问题
1. 变量未初始化。下面的程序在debug中运行的很好。
thing * search(thing * something)
BOOL found;
for(int i = 0; i < whatever.GetSize(); i++)
{
if(whatever[i]->field == something->field)
{ /* found it */
found = TRUE;
break;
} /* found it */
}
if(found)
return whatever[i];
else
return NULL;
而在release中却不行,因为debug中会自动给变量初始化found=FALSE,而在release版中则不会。所以尽可能的给变量、类或结构初始化。
2. 数据溢出的问题
如:char buffer[10];
int counter;
lstrcpy(buffer, "abcdefghik");
在debug版中buffer的NULL覆盖了counter的高位,但是除非counter>16M,什么问题也没有。但是在release版 中,counter可能被放在寄存器中,这样NULL就覆盖了buffer下面的空间,可能就是函数的返回地址,这将导致ACCESS ERROR。
3. DEBUG版和RELEASE版的内存分配方式是不同的 。如果你在DEBUG版中申请 ele 为 6*sizeof(DWORD)=24bytes,实际上分配给你的是32bytes(debug版以32bytes为单位分配), 而在release版,分配给你的就是24bytes(release版以8bytes为单位),所以在debug版中如果你写ele[6],可能不会有 什么问题,而在release版中,就有ACCESS VIOLATE。
II. ASSERT和VERIFY
1. ASSERT在Release版本中是不会被编译的。
ASSERT宏是这样定义的
#ifdef _DEBUG
#define ASSERT(x) if( (x) == 0) report_assert_failure()
#else
#define ASSERT(x)
#endif
实际上复杂一些,但无关紧要。假如你在这些语句中加了程序中必须要有的代码
比如
ASSERT(pNewObj = new CMyClass);
pNewObj->MyFunction();
这种时候Release版本中的pNewObj不会分配到空间
所以执行到下一个语句的时候程序会报该程序执行了非法操作的错误。这时可以用VERIFY :
#ifdef _DEBUG
#define VERIFY(x) if( (x) == 0) report_assert_failure()
#else
#define VERIFY(x) (x)
#endif
这样的话,代码在release版中就可以执行了。
III. 参数问题:
自定义消息的处理函数,必须定义如下:
afx_msg LRESULT OnMyMessage(WPARAM, LPARAM);
返回值必须是HRESULT型,否则Debug会过,而Release出错
IV. 内存分配
保证数据创建和清除的统一性:如果一个DLL提供一个能够创建数据的函数,那么这个DLL同时应该提供一个函数销毁这些数据。数据的创建和清除应该在同一个层次上。
V. DLL的灾难
人们将不同版本DLL混合造成的不一致性形象的称为 “动态连接库的地狱“(DLL Hell) ,甚至微软自己也这么说http://msdn.microsoft.com/library/techart/dlldanger1.htm)。
如果你的程序使用你自己的DLL时请注意:
1. 不能将debug和release版的DLL混合在一起使用。debug都是debug版,release版都是release版。
解决办法是将debug和release的程序分别放在主程序的debug和release目录下
2. 千万不要以为静态连接库会解决问题,那只会使情况更糟糕。
VI. RELEASE板中的调试 :
1. 将ASSERT() 改为 VERIFY() 。找出定义在"#ifdef _DEBUG"中的代码,如果在RELEASE版本中需要这些代码请将他们移到定义外。查找TRACE(...)中代码,因为这些代码在RELEASE中 也不被编译。 请认真检查那些在RELEASE中需要的代码是否并没有被便宜。
2. 变量的初始化所带来的不同,在不同的系统,或是在DEBUG/RELEASE版本间都存在这样的差异,所以请对变量进行初始化。
3. 是否在编译时已经有了警告?请将警告级别设置为3或4,然后保证在编译时没有警告出现.
VII. 将Project Settings" 中 "C++/C " 项目下优化选项改为Disbale(Debug)。编译器的优化可能导致许多意想不到的错误,请参http://www.pgh.net/~newcomer/debug_release.htm
1. 此外对RELEASE版本的软件也可以进行调试,请做如下改动:
在"Project Settings" 中 "C++/C " 项目下设置 "category" 为 "General" 并且将"Debug Info"设置为 "Program Database"。
在"Link"项目下选中"Generate Debug Info"检查框。
"Rebuild All"
如此做法会产生的一些限制:
无法获得在MFC DLL中的变量的值。
必须对该软件所使用的所有DLL工程都进行改动。
另:
MS BUG:MS的一份技术文档中表明,在VC5中对于DLL的"Maximize Speed"优化选项并未被完全支持,因此这将会引起内存错误并导致程序崩溃。
2. http://www.sysinternals.com/有 一个程序DebugView,用来捕捉OutputDebugString的输出,运行起来后(估计是自设为system debugger)就可以观看所有程序的OutputDebugString的输出。此后,你可以脱离VC来运行你的程序并观看调试信息。
3. 有一个叫Gimpel Lint的静态代码检查工具,据说比较好用http://www.gimpel.com/ 不过要化$的。
I. 内存分配问题
1. 变量未初始化。下面的程序在debug中运行的很好。
thing * search(thing * something)
BOOL found;
for(int i = 0; i < whatever.GetSize(); i++)
{
if(whatever[i]->field == something->field)
{ /* found it */
found = TRUE;
break;
} /* found it */
}
if(found)
return whatever[i];
else
return NULL;
而在release中却不行,因为debug中会自动给变量初始化found=FALSE,而在release版中则不会。所以尽可能的给变量、类或结构初始化。
2. 数据溢出的问题
如:char buffer[10];
int counter;
lstrcpy(buffer, "abcdefghik");
在debug版中buffer的NULL覆盖了counter的高位,但是除非counter>16M,什么问题也没有。但是在release版中,counter可能被放在寄存器中,这样NULL就覆盖了buffer下面的空间,可能就是函数的返回地址,这将导致ACCESS ERROR。
3. DEBUG版和RELEASE版的内存分配方式是不同的 。如果你在DEBUG版中申请 ele 为 6*sizeof(DWORD)=24bytes,实际上分配给你的是32bytes(debug版以32bytes为单位分配), 而在release版,分配给你的就是24bytes(release版以8bytes为单位),所以在debug版中如果你写ele[6],可能不会有什么问题,而在release版中,就有ACCESS VIOLATE。
II. ASSERT和VERIFY
1. ASSERT在Release版本中是不会被编译的。
ASSERT宏是这样定义的
#ifdef _DEBUG
#define ASSERT(x) if( (x) == 0) report_assert_failure()
#else
#define ASSERT(x)
#endif
实际上复杂一些,但无关紧要。假如你在这些语句中加了程序中必须要有的代码
比如
ASSERT(pNewObj = new CMyClass);
pNewObj->MyFunction();
这种时候Release版本中的pNewObj不会分配到空间
所以执行到下一个语句的时候程序会报该程序执行了非法操作的错误。这时可以用VERIFY :
#ifdef _DEBUG
#define VERIFY(x) if( (x) == 0) report_assert_failure()
#else
#define VERIFY(x) (x)
#endif
这样的话,代码在release版中就可以执行了。
III. 参数问题:
自定义消息的处理函数,必须定义如下:
afx_msg LRESULT OnMyMessage(WPARAM, LPARAM);
返回值必须是HRESULT型,否则Debug会过,而Release出错
IV. 内存分配
保证数据创建和清除的统一性:如果一个DLL提供一个能够创建数据的函数,那么这个DLL同时应该提供一个函数销毁这些数据。数据的创建和清除应该在同一个层次上。
V. DLL的灾难
人们将不同版本DLL混合造成的不一致性形象的称为 “动态连接库的地狱“(DLL Hell) ,甚至微软自己也这么说http://msdn.microsoft.com/library/techart/dlldanger1.htm)。
如果你的程序使用你自己的DLL时请注意:
1. 不能将debug和release版的DLL混合在一起使用。debug都是debug版,release版都是release版。
解决办法是将debug和release的程序分别放在主程序的debug和release目录下
2. 千万不要以为静态连接库会解决问题,那只会使情况更糟糕。
VI. RELEASE板中的调试 :
1. 将ASSERT() 改为 VERIFY() 。找出定义在"#ifdef _DEBUG"中的代码,如果在RELEASE版本中需要这些代码请将他们移到定义外。查找TRACE(...)中代码,因为这些代码在RELEASE中也不被编译。 请认真检查那些在RELEASE中需要的代码是否并没有被便宜。
2. 变量的初始化所带来的不同,在不同的系统,或是在DEBUG/RELEASE版本间都存在这样的差异,所以请对变量进行初始化。
3. 是否在编译时已经有了警告?请将警告级别设置为3或4,然后保证在编译时没有警告出现.
VII. 将Project Settings" 中 "C++/C " 项目下优化选项改为Disbale(Debug)。编译器的优化可能导致许多意想不到的错误,请参http://www.pgh.net/~newcomer/debug_release.htm
1. 此外对RELEASE版本的软件也可以进行调试,请做如下改动:
在"Project Settings" 中 "C++/C " 项目下设置 "category" 为 "General" 并且将"Debug Info"设置为 "Program Database"。
在"Link"项目下选中"Generate Debug Info"检查框。
"Rebuild All"
如此做法会产生的一些限制:
无法获得在MFC DLL中的变量的值。
必须对该软件所使用的所有DLL工程都进行改动。
另:
MS BUG:MS的一份技术文档中表明,在VC5中对于DLL的"Maximize Speed"优化选项并未被完全支持,因此这将会引起内存错误并导致程序崩溃。
2.www.sysinternals.com有一个程序DebugView,用来捕捉OutputDebugString的输出,运行起来后(估计是自设为system debugger)就可以观看所有程序的OutputDebugString的输出。此后,你可以脱离VC来运行你的程序并观看调试信息。
3. 有一个叫Gimpel Lint的静态代码检查工具,据说比较好用http://www.gimpel.com 不过要化$的。
4. Visual C++ RTC示例: 运行时错误检查 http://msdn.microsoft.com/zh-cn/library/s9chhb36(VS.80).aspx
5. 使用VC(VC2005/VC2008)编译程序时,如果你启动了“/RTC1”(VC6使用/GZ)去编译调试模式的程序,那么程序运行时VC的运行库就会使用特定的值填充申请和释放的内存,在调试内存错误时非常有用。
0xCC:填充未初始化的栈变量。
0xCD:填充从堆中申请的内存。
0xDD:已经释放的内存。
0xFD:填充应用程序申请内存的前后的内存(前面4个字节,后面4个字节)。
文章出处:http://www.diybl.com/course/4_webprogram/asp.net/asp_netshl/2008611/124863.html
参考文献:
1) http://www.cygnus-software.com/papers/release_debugging.html
2) http://www.pgh.net/~newcomer/debug_release.htm
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/blade2001/archive/2009/07/09/4335348.aspx
【二】《简介vc中的release和debug版本的区别》
Debug通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序。Release称为发布版本,它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户很好地使用。
Debug 和 Release 的真正秘密,在于一组编译选项。下面列出了分别针对二者的选项(当然除此之外还有其他一些,如/Fd /Fo,但区别并不重要,通常他们也不会引起 Release 版错误,在此不讨论)
Debug 版本
参数 含义
/MDd /MLd 或 /MTd 使用 Debug runtime library (调试版本的运行时刻函数库)
/Od 关闭优化开关
/D "_DEBUG" 相当于 #define _DEBUG,打开编译调试代码开关 (主要针对assert函数)
/ZI 创建 Edit and continue(编辑继续)数据库,这样在调试过程中如果修改了源代码不需重新编译
/GZ 可以帮助捕获内存错误
/Gm 打开最小化重链接开关, 减少链接时间
Release 版本
参数 含义
/MD /ML 或 /MT 使用发布版本的运行时刻函数库
/O1 或 /O2 优化开关,使程序最小或最快
/D "NDEBUG" 关闭条件编译调试代码开关 (即不编译assert函数)
/GF 合并重复的字符串, 并将字符串常量放到只读内存, 防止被修改
实际上,Debug 和 Release 并没有本质的界限,他们只是一组编译选项的集合,编译器只是按照预定的选项行动。事实上,我们甚至可以修改这些选项,从而得到优化过的调试版本或是带跟踪语句的发布版本。
哪些情况下 Release 版会出错
有了上面的介绍,我们再来逐个对照这些选项看看 Release 版错误是怎样产生的
1、Runtime Library:链接哪种运行时刻函数库通常只对程序的性能产生影响。调试版本的 Runtime Library 包含了调试信息,并采用了一些保护机制以帮助发现错误,因此性能不如发布版本。编译器提供的 Runtime Library 通常很稳定,不会造成 Release 版错误;倒是由于 Debug 的 Runtime Library 加强了对错误的检测,如堆内存分配,有时会出现 Debug 有错但 Release 正常的现象。应当指出的是,如果 Debug 有错,即使 Release 正常,程序肯定是有 Bug 的,只不过可能是 Release 版的某次运行没有表现出来而已。
2、优化:这是造成错误的主要原因,因为关闭优化时源程序基本上是直接翻译的,而打开优化后编译器会作出一系列假设。这类错误主要有以下几种:
1. 帧指针(Frame Pointer)省略(简称FPO):在函数调用过程中,所有调用信息(返回地址、参数)以及自动变量都是放在栈中的。若函数的声明与实现不同(参数、返回值、调用方式),就会产生错误,但 Debug 方式下,栈的访问通过 EBP 寄存器保存的地址实现,如果没有发生数组越界之类的错误(或是越界“不多”),函数通常能正常执行;Release 方式下,优化会省略 EBP 栈基址指针,这样通过一个全局指针访问栈就会造成返回地址错误是程序崩溃。
C++ 的强类型特性能检查出大多数这样的错误,但如果用了强制类型转换,就不行了。你可以在 Release 版本中强制加入/Oy-编译选项来关掉帧指针省略,以确定是否此类错误。此类错误通常有:MFC 消息响应函数书写错误。正确的应为:
afx_msg LRESULT OnMessageOwn
(WPARAM wparam, LPARAM lparam);
ON_MESSAGE 宏包含强制类型转换。防止这种错误的方法之一是重定义 ON_MESSAGE 宏,把下列代码加到 stdafx.h 中(在#include "afxwin.h"之后),函数原形错误时编译会报错。
#undef ON_MESSAGE
#define ON_MESSAGE(message, memberFxn)
{
message, 0, 0, 0, AfxSig_lwl,
(AFX_PMSG)(AFX_PMSGW)
(static_cast< LRESULT (AFX_MSG_CALL
CWnd::*)(WPARAM, LPARAM) > (&memberFxn)
},
2. volatile 型变量:volatile 告诉编译器该变量可能被程序之外的未知方式修改(如系统、其他进程和线程)。优化程序为了使程序性能提高,常把一些变量放在寄存器中(类似于 register 关键字),而其他进程只能对该变量所在的内存进行修改,而寄存器中的值没变。
如果你的程序是多线程的,或者你发现某个变量的值与预期的不符而你确信已正确的设置了,则很可能遇到这样的问题。这种错误有时会表现为程序在最快优化出错而最小优化正常。把你认为可疑的变量加上 volatile 试试。
3. 变量优化:优化程序会根据变量的使用情况优化变量。例如,函数中有一个未被使用的变量,在 Debug 版中它有可能掩盖一个数组越界,而在 Release 版中,这个变量很可能被优化调,此时数组越界会破坏栈中有用的数据。当然,实际的情况会比这复杂得多。与此有关的错误有非法访问,包括数组越界、指针错误等。例如:
void fn(void)
{
int i;
i = 1;
int a[4];
{
int j;
j = 1;
}
a[-1] = 1;
//当然错误不会这么明显,例如下标是变量
a[4] = 1;
}
j 虽然在数组越界时已出了作用域,但其空间并未收回,因而 i 和 j 就会掩盖越界。而 Release 版由于 i、j 并未其很大作用可能会被优化掉,从而使栈被破坏。
3. DEBUG 与 NDEBUG :当定义了 _DEBUG 时,assert() 函数会被编译,而 NDEBUG 时不被编译。此外,TRACE() 宏的编译也受 _DEBUG 控制。
所有这些断言都只在 Debug版中才被编译,而在 Release 版中被忽略。唯一的例外是 VERIFY()。事实上,这些宏都是调用了assert()函数,只不过附加了一些与库有关的调试代码。如果你在这些宏中加入了任何程序代码,而不只是布尔表达式(例如赋值、能改变变量值的函数调用等),那么Release版都不会执行这些操作,从而造成错误。初学者很容易犯这类错误,查找的方法也很简单,因为这些宏都已在上面列出,只要利用 VC++ 的 Find in Files 功能在工程所有文件中找到用这些宏的地方再一一检查即可。另外,有些高手可能还会加入 #ifdef _DEBUG 之类的条件编译,也要注意一下。
顺便值得一提的是VERIFY()宏,这个宏允许你将程序代码放在布尔表达式里。这个宏通常用来检查 Windows API的返回值。有些人可能为这个原因而滥用VERIFY(),事实上这是危险的,因为VERIFY()违反了断言的思想,不能使程序代码和调试代码完全分离,最终可能会带来很多麻烦。因此,专家们建议尽量少用这个宏。
4. /GZ 选项:这个选项会做以下这些事:
1. 初始化内存和变量。包括用 0xCC 初始化所有自动变量,0xCD ( Cleared Data ) 初始化堆中分配的内存(即动态分配的内存,例如 new ),0xDD ( Dead Data ) 填充已被释放的堆内存(例如 delete ),0xFD( deFencde Data ) 初始化受保护的内存(debug 版在动态分配内存的前后加入保护内存以防止越界访问),其中括号中的词是微软建议的助记词。这样做的好处是这些值都很大,作为指针是不可能的(而且 32 位系统中指针很少是奇数值,在有些系统中奇数的指针会产生运行时错误),作为数值也很少遇到,而且这些值也很容易辨认,因此这很有利于在 Debug 版中发现 Release 版才会遇到的错误。要特别注意的是,很多人认为编译器会用0来初始化变量,这是错误的(而且这样很不利于查找错误)。
2. 通过函数指针调用函数时,会通过检查栈指针验证函数调用的匹配性。(防止原形不匹配)
3. 函数返回前检查栈指针,确认未被修改。(防止越界访问和原形不匹配,与第二项合在一起可大致模拟帧指针省略 FPO )通常 /GZ 选项会造成 Debug 版出错而 Release 版正常的现象,因为 Release 版中未初始化的变量是随机的,这有可能使指针指向一个有效地址而掩盖了非法访问。除此之外,/Gm/GF等选项造成错误的情况比较少,而且他们的效果显而易见,比较容易发现。
怎样“调试” Release 版的程序
遇到Debug成功但Release失败,显然是一件很沮丧的事,而且往往无从下手。如果你看了以上的分析,结合错误的具体表现,很快找出了错误,固然很好。但如果一时找不出,以下给出了一些在这种情况下的策略。
1. 前面已经提过,Debug和Release只是一组编译选项的差别,实际上并没有什么定义能区分二者。我们可以修改Release版的编译选项来缩小错误范围。如上所述,可以把Release 的选项逐个改为与之相对的Debug选项,如/MD改为/MDd、/O1改为/Od,或运行时间优化改为程序大小优化。注意,一次只改一个选项,看改哪个选项时错误消失,再对应该选项相关的错误,针对性地查找。这些选项在ProjectSettings...中都可以直接通过列表选取,通常不要手动修改。由于以上的分析已相当全面,这个方法是最有效的。
2. 在编程过程中就要时常注意测试 Release 版本,以免最后代码太多,时间又很紧。
3. 在 Debug 版中使用 /W4 警告级别,这样可以从编译器获得最大限度的错误信息,比如 if( i =0 )就会引起 /W4 警告。不要忽略这些警告,通常这是你程序中的 Bug 引起的。但有时 /W4 会带来很多冗余信息,如 未使用的函数参数 警告,而很多消息处理函数都会忽略某些参数。我们可以用:
#progma warning(disable: 4702)
//禁止
//...
#progma warning(default: 4702)
//重新允许来暂时禁止某个警告,或使用
#progma warning(push, 3)
//设置警告级别为 /W3
//...
#progma warning(pop)
//重设为 /W4
来暂时改变警告级别,有时你可以只在认为可疑的那一部分代码使用 /W4。
4. 你也可以像Debug一样调试你的Release版,只要加入调试符号。在Project/Settings... 中,选中 Settings for "Win32 Release",选中 C/C++ 标签,Category 选 General,Debug Info 选 Program Database。再在 Link 标签 Project options 最后加上 "/OPT:REF" (引号不要输)。这样调试器就能使用 pdb 文件中的调试符号。
但调试时你会发现断点很难设置,变量也很难找到??这些都被优化过了。不过令人庆幸的是,Call Stack窗口仍然工作正常,即使帧指针被优化,栈信息(特别是返回地址)仍然能找到。这对定位错误很有帮助。
Things I have encountered - most are already mentioned
Variable initialization by far the most common. In Visual Studio, debug builds explicitely initialize allocated memory to given values, see e.g. Memory Values here. These values are usually easy to spot, cause an out of bounds error when used as an index or an access violation when used as a pointer. An uninitialized boolean is true, however, and may cause uninitialized memory bugs going undetected for years.
In Release builds where memory isn't explicitely initialized it just keeps the contents that it had before. This leads to "funny values" and "random" crashes, but as often to deterministic crashes that require an apparently unrelated command to be executed before the command that actually crashes. This is caused by the first command "setting up" the memory location with specific values, and when the memory locations are recycled the second command sees them as initializations. That's more common with uninitialized stack variables than heap, but the latter has happened to me, too.
Raw memory initialization can also be different in a release build whether you start from visual studio (debugger attached) vs. starting from explorer. That makes the "nicest" kind of release build bugs that never appear under the debugger.
Valid Optimizations come second in my exeprience. The C++ standard allows lots of optimizations to take place which may be surprising but are entirely valid e.g. when two pointers alias the same memory location, order of initialization is not considered, or multiple threads modify the same memory locations, and you expect a certain order in which thread B sees the changes made by thread A. Often, the compiler is blamed for these. Not so fast, young yedi! - see below
Timing Release builds don't just "run faster", for a variety of reasons (optimizations, logging functions providing a thread sync point, debug code like asserts not executed etc.) also the relative timing between operations change dramatically. Most common problem uncovered by that is race conditions, but also deadlocks and simple "different order" execution of message/timer/event-based code. Even though they are timing problems, they can be surprisingly stable across builds and platforms, with reproductions that "work always, except on PC 23".
Guard Bytes. Debug builds often put (more) guard bytes around selected instances and allocations, to protect against index overflows and sometimes underflows. In the rare cases where the code relies on offsets or sizes, e.g. serializing raw structures, they are different.
Other code differences Some instructions - e.g asserts - evaluate to nothing in release builds. Sometimes they have different side effects. This is prevalent with macro trickery, as in the classic (warning: multiple errors)
#ifdef DEBUG
#define Log(x) cout << #x << x << "
";
#else
#define Log(x)
#endif
if (foo)
Log(x)
if (bar)
Run();Which, in a release build, evaluates to if (foo && bar)This type of error is very very rare with normal C/C++ code, and macros that are correctly written.
Compiler Bugs This really never ever happens. Well - it does, but you are for the most part of your career better off assuming it does not. In a decade of working with VC6, I found one where I am still convinced this is an unfixed compiler bug, compared to dozens of patterns (maybe even hundreds of instances) with insufficient understanding of the scripture (a.k.a. the standard).