一. Go语言并发编程
- 采用了CSP(Communication Seuential process)模型
- 不需要锁, 不需要callback
- 并发编程 vs 并行计算
1.1 CSP并发模型
CSP模型是上个世纪七十年代提出的,用于描述两个独立的并发实体通过共享的通讯 channel(管道)进行通信的并发模型。 CSP中channel是第一类对象,它不关注发送消息的实体,而关注与发送消息时使用的channel。
1.2 Golang CSP
Golang 就是借用CSP模型的一些概念为之实现并发进行理论支持,其实从实际上出发,go语言并没有,完全实现了CSP模型的所有理论,仅仅是借用了 process和channel这两个概念。process是在go语言上的表现就是 goroutine 是实际并发执行的实体,每个实体之间是通过channel通讯来实现数据共享。
1.3 不需要锁, 不需要callback
go使用CSP模型进行通信, 不需要使用锁, 其实, 这里不需要锁指的是用户在使用go语言进行并发通信的时候不需要使用锁. 也不需要使用callback. 但是, go底层其实还是使用了锁和callback的.2.1 模拟服务器启动, 打印内容到页面
package main import ( "fmt" "net/http" ) func main() { http.HandleFunc("/", func(writer http.ResponseWriter, request *http.Request) { fmt.Fprintf(writer, "<h1>Hello World %s</h1>", request.FormValue("name")) }) http.ListenAndServe(":8888", nil) }
这里面需要注意的是启动一个服务器的方式
2.2 主方法main和Hello world方法进行通信, 通信使用的是channel
package main import ( "fmt" "time" ) func main() { ch := make(chan string) for i := 0; i< 5000; i++ { go hello(i, ch) } for { str := <-ch fmt.Println(str) } time.Sleep(time.Millisecond) } func hello(i int, ch chan string) { for { ch <- fmt.Sprintf("hello world, %d", i) } }
2.3 内部排序
func main() { arr := []int {2, 5, 1, 9, 23, 01} sort.Ints(arr) for i, v := range arr { fmt.Printf("%d, %d ", i, v) } }
内部排序使用的是内建函数
2.4 go实现外部排序 pipeline
我们使用外部排序的时候,会用到归并排序, 先来看看什么是归并排序?
将数据分为左右两半, 分别归并排序, 再把两个有序数据归并

上图演示了归并排序中的二路归并. 其实归并排序还可以有三路归并, N路归并
有一个大的集合, 首先将其分为两个小的集合, 使用内部排序对两个小的集合进行内部排序
得到排好序的两个集合, 然后进行归并排序
第一步: 取出两个集合的首元素. 比较, 如果一样, 取左侧元素---->1
第二步: 再次取出两个集合的首元素, 比较, 右侧小--->1
第三步: 再次取出两个集合的首元素, 比较, 左侧小--->2
........
依次类推
接下来,我们的外部排序, 采用二路归并的方式实现.
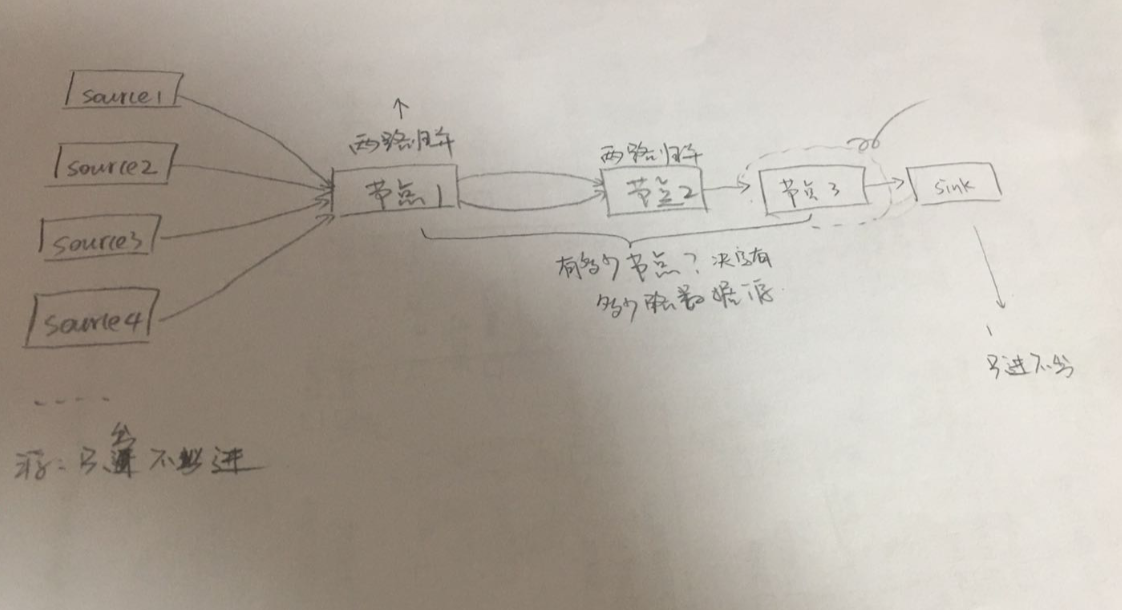
数据源,来自多方. 比如hadoop中的多个hdfs
然后将数据发送到节点1, 进行二路归并, 归并后的结果在发送到节点2, 再次进行二路归并.......一次类推,直到最后只有一路数据,就是我们要的结果
3. 代码实现
我们使用案例来说明管道的使用
3.1 channel是goroutine和goroutine之间的通信
首先, 将数据放入管道中.....这里有个疑问, 为什么要将数据放入管道中呢?
假如: 这每一个数组都是一个对象, 一个很大的对象, 处理链路比较长. 这时候, 放入管道中. 就可以并发处理了. 不影响后面的流程. 该怎么处理, 就怎么处理.
package pipeline func ArraySource(arr ...int) chan int { out := make(chan int) go func() { for a := range arr { out <- a } close(out) }() return out }
这是一个将数组放入管道的过程. 有两点
- 创建一个channel. 然后将这个channel return
- 记住: channel是goroutine和goroutine之间的通信. 我们在给channel赋值的时候, 不能直接赋值, 要将其放在一个单独的goroutine中.
- 注意: 这里有一个close, 意思是:我把数据向管道中放完了, 没有数据了. 后面取数据的人, 请不要再取了
所以, 这里定义了一个单独的goroutine,用来向管道中存数据
接下来写一个demo, 取数据
package main import ( "fmt" "test007/pipeline" "time" ) func main() { sourceChan := pipeline.ArraySource(1, 4, 8, 2, 19, 5) for { if data, ok := <- sourceChan; ok { fmt.Println("data:", data) } else { break } } time.Sleep(time.Second * 10) }
首先, 我将一个数组, 放入管道中.
然后, 从管道中持续不断的去取数据. 所以有一个for死循环. 循环的时候, 使用了ok来判断, 是否还有数据可以取出, 如果没有了, 就退出
注意: 这里使用了close关闭了管道, 所以, 我们就不会不停的取数据.
还有一种方式, 直接有数据取出, 不用我们手动判断
package main import ( "fmt" "test007/pipeline" "time" ) func main() { sourceChan := pipeline.ArraySource(1, 4, 8, 2, 19, 5) for v := range sourceChan { fmt.Println("data:", v) } time.Sleep(time.Second * 10) }
如果使用了range的方式, 从管道中取数据, 那么....必须要手动close, 否则, for循环不知道该何时退出, 将会发生死锁的现象.
为什么死锁呢?
因为, 这里的for循环不知道何时退出, 一直处于等待状态, 后面的代码没有办法执行, 所以就发生了死锁.
那么: 通常情况下, 我们的管道是不会手动close的. 当管道中有数据的时候, 我们就取出, 如果管道中没有数据, 我们就等待. 这个怎么做呢?
也就是说, 我们不会手动close, 如何才能让goroutine一直等待, 直到有数据到来呢? 接收方也使用单独的goroutine, 单独来接收数据.这样就不会阻塞主goroutine了.
package main import ( "fmt" "test007/pipeline" "time" ) func main() { sourceChan := pipeline.ArraySource(1, 4, 8, 2, 19, 5) go func() { for v := range sourceChan { fmt.Println("data:", v) } }() time.Sleep(time.Second * 10) }
加上一个单独的goroutine为什么不会发生死锁?
我猜: 因为单开一个goroutine去sourceChan中接收数据, 那么....他就不会阻塞主线程向下运行. 单独的goroutine的作用是: 如果有数据, 就处理, 没有, 就等待. 哪怕等一年,两年....它都可以等.
上面这个demo需要记住的重点:
1. channel是goroutine和goroutine之间的通信
2. 如果不想要发生死锁, 那么向channel中放数据和从channel中取数据都要在一个单独的goroutine中进行. 很有可能这两个goroutine永远都不工作, 但是活着, 不会影响主goroutine
3.2 管道是有方向的
管道的输入, 和管道的返回值都是有方向的.
还是上面的demo. 如果ArraySource的返回值是一个 <- chan int, 那么, 表示, 返回的是一个可以取数据的管道. 那么, 后面接收这个返回值的变量, 就不可以向其中放数据
package pipeline import "time" func ArraySource(arr ...int) <- chan int { out := make(chan int) go func() { for a := range arr { out <- a } time.Sleep(time.Second * 2) out <- 9 //close(out) }() return out }
注意, 这里的返回值类型的管道是可以取数据的管道.
那么像下面这样, 在管道里放数据是不ok的, 直接报错

3.3. 学习定义一个返回值为channel的func
学习老师写管道方法的模板
// 比如: 老师要进行一个sort排序 func Sort(in <-chan int) <- chan int{ // 第一步: 定义一个chan out := make(chan int) // 第三步: 向管道里放数据, 单独开一个goroutine go func() { }() // 第二步: return 这个channel return out }
第一步: 定义一个chan of int 类型的管道变量
第二步: 将这个管道变量返回
第三步: 向管道中放数据. 放什么样的数据, 那就是业务逻辑了.
这样定义, 就不会发生死锁. 因为,开一个goroutine是很快的.
3.4 定义排序方法
func InMemSort(in <-chan int) <-chan int { // 第一步: 定义一个channel变量 out := make(chan int) // 第三步: 向channel中放数据 go func() { var arr []int // 管道到这里会阻塞, 等待close以后, 才会退出这个for循环 // 如果没有close,就会发生死锁 for v := range in { arr = append(arr, v) } fmt.Println("arr: ",arr) sort.Ints(arr) fmt.Println("arr: ",arr) for _, v := range arr { out <- v } }() // 第二步: 返回这个channel return out }
这个排序方法, 就使用了老师定义一个channel 方法的三个步骤
在第三步: 处理业务. 首先, 从输入的in管道中, 取出数据.
取出数据使用的是for循环. 循环从管道中取数据. 这里会发生阻塞. 直到所有的数据全部都被取出, 且in管道close. 否则, 会无限循环等待下去.
3.5 归并算法, 将两个数组中的数据进行合并
func Merge(in1, in2 <-chan int) <-chan int { // 第一步: 定义一个管道变量 out := make(chan int) // 第三步: 向管道中放入数据 go func() { // 第四步: 从两个管道中取一个数据 v1, ok1 := <- in1 v2, ok2 := <- in2 // 第五步: 如果能够从任意一个管道中取出数据, 则处理 for ok1 || ok2 { if !ok2 || (ok1 && v1 <= v2) { out <- v1 v1, ok1 = <- in1 } else { out <- v2 v2, ok2 = <-in2 } } // 第六步: 没有数据可以取出来, close管道, 表示已经取完了 //close(out) }() // 第二步: 返回这个管道 return out }
这里业务逻辑在goroutine里面. 因为是管道. 所以,每次从管道中取一个数据出来, 循环从管道取数据比较.
然后, 我们造两个数组, 测试将两个数组合并
package main import ( "fmt" "test007/pipeline" "time" ) func main() { mergeChan := pipeline.Merge( pipeline.InMemSort(pipeline.ArraySource(1, 4, 8, 2, 19, 5)), pipeline.InMemSort(pipeline.ArraySource(0, 29, 43, 1, 7, 9))) go func() { for v := range mergeChan { fmt.Println("data:", v) } }() time.Sleep(time.Second * 10) }
输出结果:
GOROOT=/usr/local/go #gosetup GOPATH=/Users/luoxiaoli/go #gosetup /usr/local/go/bin/go build -o /private/var/folders/g2/74np978j3971l2864zdk7lgc0000gn/T/___go_build_main_go_darwin /Users/luoxiaoli/test007/pipeline/pipelinedemo/main.go #gosetup /private/var/folders/g2/74np978j3971l2864zdk7lgc0000gn/T/___go_build_main_go_darwin #gosetup arr: [1 4 8 2 19 5] arr: [0 29 43 1 7 9] arr: [1 2 4 5 8 19] arr: [0 1 7 9 29 43] data: 0 data: 1 data: 1 data: 2 data: 4 data: 5 data: 7 data: 8 data: 9 data: 19 data: 29 data: 43 Process finished with exit code 0
这里遇到一个问题:
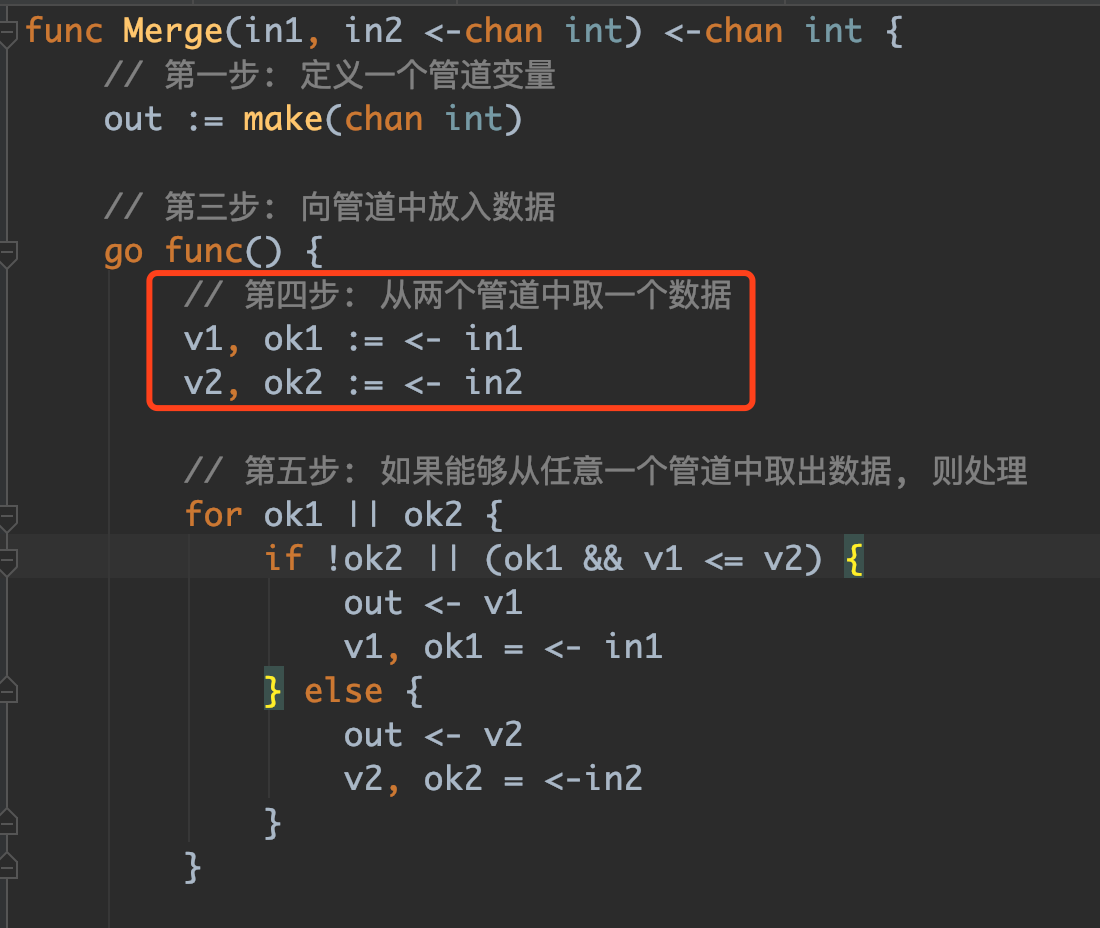
in1中的数据取完了, 发现, 后面的代码就不执行了. 虽然没有发生死锁, 但是, 阻止了后面数据的输出.
究其原因,在这里:
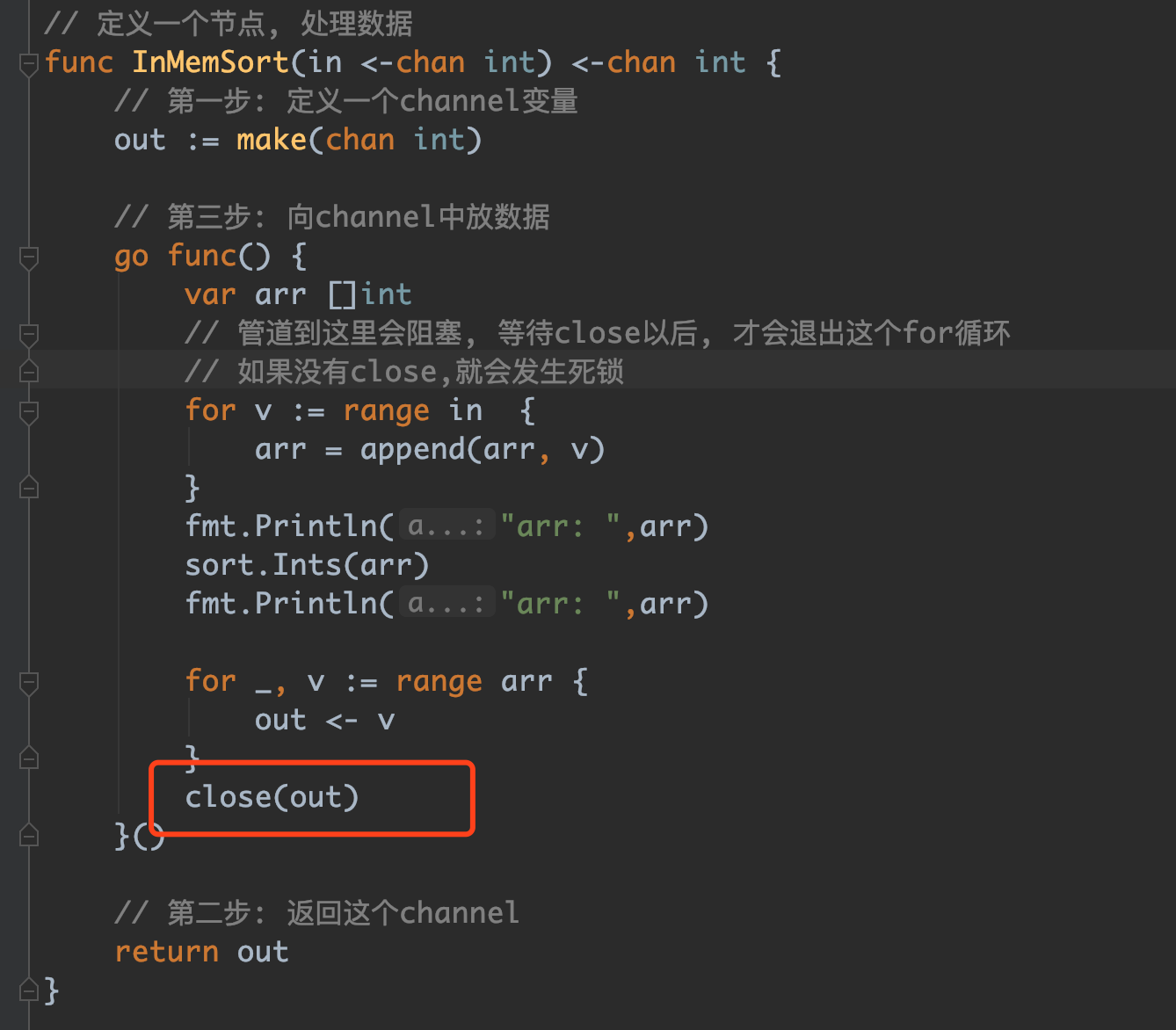
在做内部排序的时候, 排序完了, 没有close. 这样就导致, range 管道的时候, 如果没有数据, 就一直等待, 如果始终没有, 就卡在那里了.
3.6 改变数据源为从文件读取
之前,我们的数据源是自己定义的一个数组ArraySource. 传进来一个数组, 然后, 我们将数组放入管道中进行处理. 如下情况:func ArraySource(arr ...int) <- chan int { out := make(chan int) go func() { for _, a := range arr { out <- a } close(out) }() return out }
真实情况是. 我们通常是从文件读取数据源, 比如日志文件. 而且, 数据源可能不止一个. 比如: hdfs有n个, 我们要读取n个hdfs数据源.
下面, 我们从文件读取数据源. 这里定义一种通用读取的方式. 不管是什么数据源, 我们都使用reader来读取. 读取的内容, 放入管道中.
/** * 从redader中读取数据 */ func ReaderSource(reader io.Reader) <- chan int{ out := make(chan int) go func() { // 这里定义为8个字节, 原因是我的机器是64位的, 所以int也是64位, 那么对应的字节数就是8个字节 buffer := make([]byte, 8) for { // reader返回两个参数, 第一个是读取到的字节数, 第二个是err异常 n, err := reader.Read(buffer) if n > 0 { // 如果读到了, 就把读到的东西发给channel u := binary.BigEndian.Uint64(buffer) out <- int(u) } if err != nil { break } } close(out) }() return out }
接下来, 我们有读取数据源了, 还有最后只进不出的Sink, Sink从管道里读数据, 将读到的数据, 输出
/** * 只读数据, 不写数据的, 将读出来的数据打印出来 * 可以打印到控制台, 也可以写入到文件. 这里就写入到文件 */ func WriteSink(writer io.Writer, in <-chan int) { for v := range in { b := make([]byte, 8) binary.BigEndian.PutUint64(b, uint64(v)) writer.Write(b) } }
最后为了方便操作, 我们定义一个生成随机数的代码. 将随机数写入到文件中
/** * 生成一个随机数 */ func RandomSource(count int) chan int { out := make(chan int) go func() { // 生成count个随机数 for i := 0; i<count ; i++ { out <- rand.Int() } close(out) }() return out }
下面对以上操作进行一个整合. 整合代码如下:
func main() { // 第一步: 造数据, 生成100个随机数, 写入到文件 const fileName = "small.in" const count = 100 // 第一步: 将随机生产的数字保存到small.in文件 // 构造第一个数据源 file, e := os.Create(fileName) if e != nil { panic(e) } defer file.Close() dataSource := pipeline.RandomSource(count) writer := bufio.NewWriter(file) pipeline.WriteSink(writer, dataSource) writer.Flush() // 第二步: 从文件中读取文件内容, 在控制台打印 // 从第一个数据源读取出数据 f, e := os.Open(fileName) if e != nil { panic(e) } defer f.Close() readerSource := pipeline.ReaderSource(bufio.NewReader(f)) var num = 0 for rs := range readerSource{ fmt.Println(rs) num ++ if num > 100 { break } } }
最后,生成随机数, 就是一个造数据的过程. 我们可以利用这个main方法, 早两类数据, 一个是小数据, 一个是大数据.
其实, 这个部分,就是练习channel. go语言是如何通过channel进行通信的. 每一个部分, 都是channel
3.7 多路合并
/** * N个节点两两归并 */ func MergeN(inputs ... <-chan int) <-chan int{ if len(inputs) == 1 { return inputs[0] } middle := len(inputs) / 2 // 两个两个的合并 return Merge(MergeN(inputs[:middle]...), MergeN(inputs[middle:]...)) }
先将输入分为两半, 然后递归再去两半, 直到最后将两个通道数据合并.
3.8 单机外部排序
/** * @param fileName: 文件名 * @param fileSize: 文件大小 * @param chunkCount: 将文件分成多少块 */ func createPipeline(fileName string, fileSize, chunkCount int) <- chan int{ pipeline.Init() // 每次读取的内容的字节大小 chunkSize := fileSize/chunkCount sortResult := []<-chan int{} for i := 0; i < chunkCount; i++ { file, e := os.Open(fileName) if e != nil { panic(e) } // offset: 从文件的什么位置开始读 whence: 从第几个字符开始读 file.Seek(int64(chunkSize*i) , 0) // 读取文件的内容 source := pipeline.ReaderSource(bufio.NewReader(file), chunkSize) // 在内存中对内容进行排序 sortResult = append(sortResult, pipeline.InMemSort(source)) } // 合并所有的内部排序后的结果 return pipeline.MergeN(sortResult...) }
第二部分: 将数据写入到文件
/** * 将合并后的结果写入到文件 */ func writeToFile(p <- chan int, fileName string) { file, e := os.Create(fileName) if e != nil { panic(e) } defer file.Close() writer := bufio.NewWriter(file) defer writer.Flush() // 这一步是将读取的内容写入到文件 pipeline.WriteSink(writer, p) }
第三部分: 将文件中的数据打印到控制台
func printFile(fileName string) { file, e := os.Open(fileName) if e != nil { panic(e) } defer file.Close() reader := bufio.NewReader(file) source := pipeline.ReaderSource(reader, -1) count := 0 for v := range source { fmt.Println(v) count ++ if count > 100 { break } } }
这里, 我们在上面生成了一个512k的文件, 那么最后合并后的数据也应该是512k
大数据是8000000字节, 那么最后合并后也应该是80000000字节.
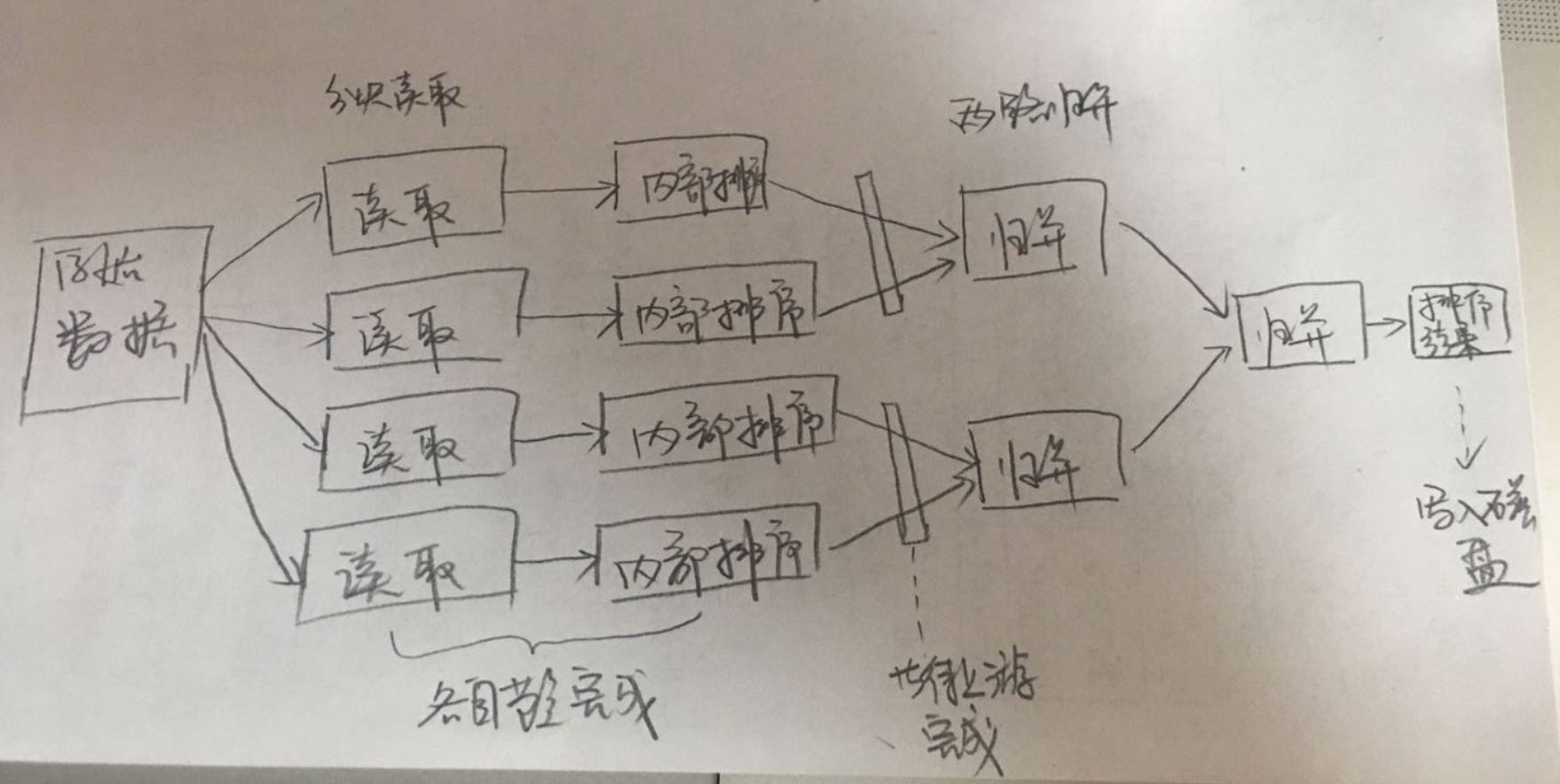
阶段总结:
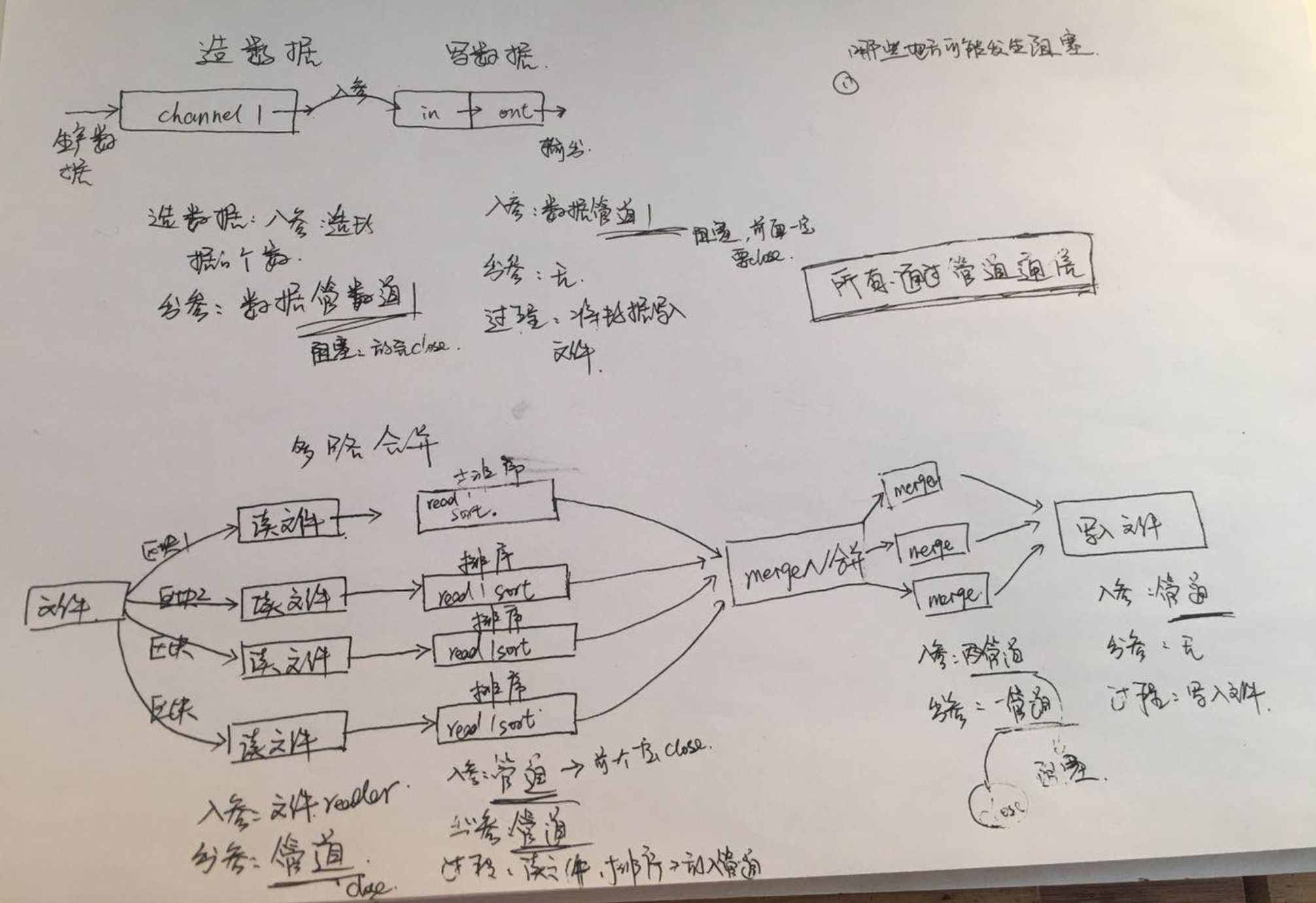
如上图分析:
可以看到, 基本都是使用管道进行的通信, 读取数据的时候, 并不是说, 最开始放入一个数据, 到最后, 输出一个数据, 中间有等待的过程.
只要有等待, 那么就可能发生死锁, 所以, 放完了数据, 一定要调用close. 这样, 取数据的一方就不会不停的等待.
这个就是搭建的管道通信方式
还有一个部分就是带有缓冲的管道. 发现,如果管道没有缓冲, 那就, 就要一直等待. 我放一个, 有人取走了,我再放一个, 走人再去走了, 我再放一个, 知道放数据的一边说, 我放完了. 然后, 取数据的一遍就结束了, 不在取了
这样1对1 效率有些低, 因此, 我们将给管道增加一个缓冲, 比如这里增加了1000个数据的缓冲, 也就是里面可以放1000个数据, 这样就大大提高了效率
// 定义一个节点, 处理数据 func InMemSort(in <-chan int) <-chan int { // 第一步: 定义一个channel变量 out := make(chan int, 1000) // 第三步: 向channel中放数据 go func() { var arr []int // 管道到这里会阻塞, 等待close以后, 才会退出这个for循环 // 如果没有close,就会发生死锁 for v := range in { arr = append(arr, v) } fmt.Println("read data: ", time.Now().Sub(startTime)) sort.Ints(arr) fmt.Println("sorted data: ", time.Now().Sub(startTime)) for _, v := range arr { out <- v } close(out) }() // 第二步: 返回这个channel return out } func Merge(in1, in2 <-chan int) <-chan int { // 第一步: 定义一个管道变量 out := make(chan int, 1000) // 第三步: 向管道中放入数据 go func() { // 第四步: 从两个管道中取一个数据 v1, ok1 := <- in1 v2, ok2 := <- in2 // 第五步: 如果能够从任意一个管道中取出数据, 则处理 for ok1 || ok2 { if !ok2 || (ok1 && v1 <= v2) { out <- v1 v1, ok1 = <- in1 } else { out <- v2 v2, ok2 = <-in2 } } // 第六步: 没有数据可以取出来, close管道, 表示已经取完了 close(out) fmt.Println("merged data: ", time.Now().Sub(startTime)) }() // 第二步: 返回这个管道 return out } /** * 从redader中读取数据 * 将reader改为分块读取, 每次读取指定字符长度 */ func ReaderSource(reader io.Reader, trunkSize int) <- chan int{ out := make(chan int, 1000) go func() { // 这里定义为8个字节, 原因是我的机器是64位的, 所以int也是64位, 那么对应的字节数就是8个字节 buffer := make([]byte, 8) readered := 0 for { // 记录已经读取的个数 // reader返回两个参数, 第一个是读取到的字节数, 第二个是err异常 n, err := reader.Read(buffer) readered += n if n > 0 { // 如果读到了, 就把读到的东西发给channel u := binary.BigEndian.Uint64(buffer) out <- int(u) } if err != nil || (trunkSize != -1 && readered >= trunkSize){ break } //fmt.Println("已读字符数", readered) } close(out) }() return out }
标红的部分, 增加了管道缓冲, 提高了管道处理的效率
3.9 网络版外部排序
通过上面的排序结果, 我们看到, 一个800M的文件排序时间大概是40-50秒. 其实这个时间并不快, 或者说, 如果不用管道, 那么会更快. 用了管道反而更慢了, 那我们为什么还要用管道呢?
首先, 用了管道为什么会变慢呢? 因为, 管道之间的通信, 有等待的过程. 肯定是要比直接处理要慢的.
第二: 虽然用管道会慢, 但我们依然用它,为什么么? 这里是开启了4路并行处理. 文件一共800M, 那么如果是8G呢?800G呢?我们能用一个线程单独去执行么? 显然不可以. 一定要用这种并行的方式.
----------------------------
通常服务器的日志都是放在不同的机器上的, 某几台机器接收日志文件. 然后传输给其他机器进行数据处理. 数据处理以后, 在发送给其他机器, 进行数据合并, 最后入库. 这几个步骤可能都发生在不同的机器上. 接下来, 我们就真实模拟一下, 服务器之间, 是如何传输这些数据的.
接下来我们要做的事情是这样的

将InMemSort在内存中排序和ReaderSource读取数据进行合并, 这两个步骤分开. 分别在两个服务器上执行.
原理: 有多少个节点, 就开多少个server, 然后merge节点去接这些server.
---------------------------
现在要做的有两件事情
1. 从文件读取到的数据, 放入到server中, 然后将数据通过网络发送里给连接到客户端的client
2. 客户端对数据进行Merge后输出到文件
提取第一部分: 将数据源的文件读取后发送到server中
func NetWorkSink(addr string, in <- chan int) { // 第一步: 开启服务器的监听端口 listener, e := net.Listen("tcp", addr) if e != nil { panic(e) } go func() { defer listener.Close() // 第二步: 等待客户端连接 conn, e := listener.Accept() if e != nil { panic(e) } defer conn.Close() // 第三步: 将数据通过网络发送出去 writer := bufio.NewWriter(conn) defer writer.Flush() WriteSink(writer, in) }() }
将数据发送给连接的客户端
第二部分: 客户端接收到数据后, 读取数据,并发送到通道里面
func NetWorkSource(addr string) <-chan int{ out := make(chan int) go func() { conn, e := net.Dial("tcp", addr) if e != nil { panic(e) } defer conn.Close() reader := bufio.NewReader(conn) source := ReaderSource(reader, -1) for s := range source { out <- s } close(out) }() return out }
接下来创建一个网络pipeline
/** * @param fileName: 文件名 * @param fileSize: 文件大小 * @param chunkCount: 将文件分成多少块 */ func createNetWorkPipeline(fileName string, fileSize, chunkCount int) <- chan int{ pipeline.Init() // 每次读取的内容的字节大小 chunkSize := fileSize/chunkCount sortResult := []<-chan int{} sortAddr := []string{} for i := 0; i < chunkCount; i++ { file, e := os.Open(fileName) if e != nil { panic(e) } // offset: 从文件的什么位置开始读 whence: 从第几个字符开始读 file.Seek(int64(chunkSize*i) , 0) // 读取文件的内容 source := pipeline.ReaderSource(bufio.NewReader(file), chunkSize) sort := pipeline.InMemSort(source) addr := ":" + strconv.Itoa(7000 + i) pipeline.NetWorkSink(addr, sort) // 在内存中对内容进行排序 //sortResult = append(sortResult, pipeline.InMemSort(source)) sortAddr = append(sortAddr, addr) } for _, s := range sortAddr { sortResult = append(sortResult, pipeline.NetWorkSource(s)) } // 合并所有的内部排序后的结果 return pipeline.MergeN(sortResult...) }
最后测试:网络版的文件接收通信,
func main() { // 第一步: 生成pipeline文件 p := createNetWorkPipeline("large.in", 800000000, 4) //time.Sleep(time.Hour) // 第二步: 写入到文件 writeToFile(p, "large.out") // 第三步: 打印出来 printFile("large.out") }
运行结果:

总结:
网络版这一块做的事情, 是在讲什么? 在模拟真实的使用场景.
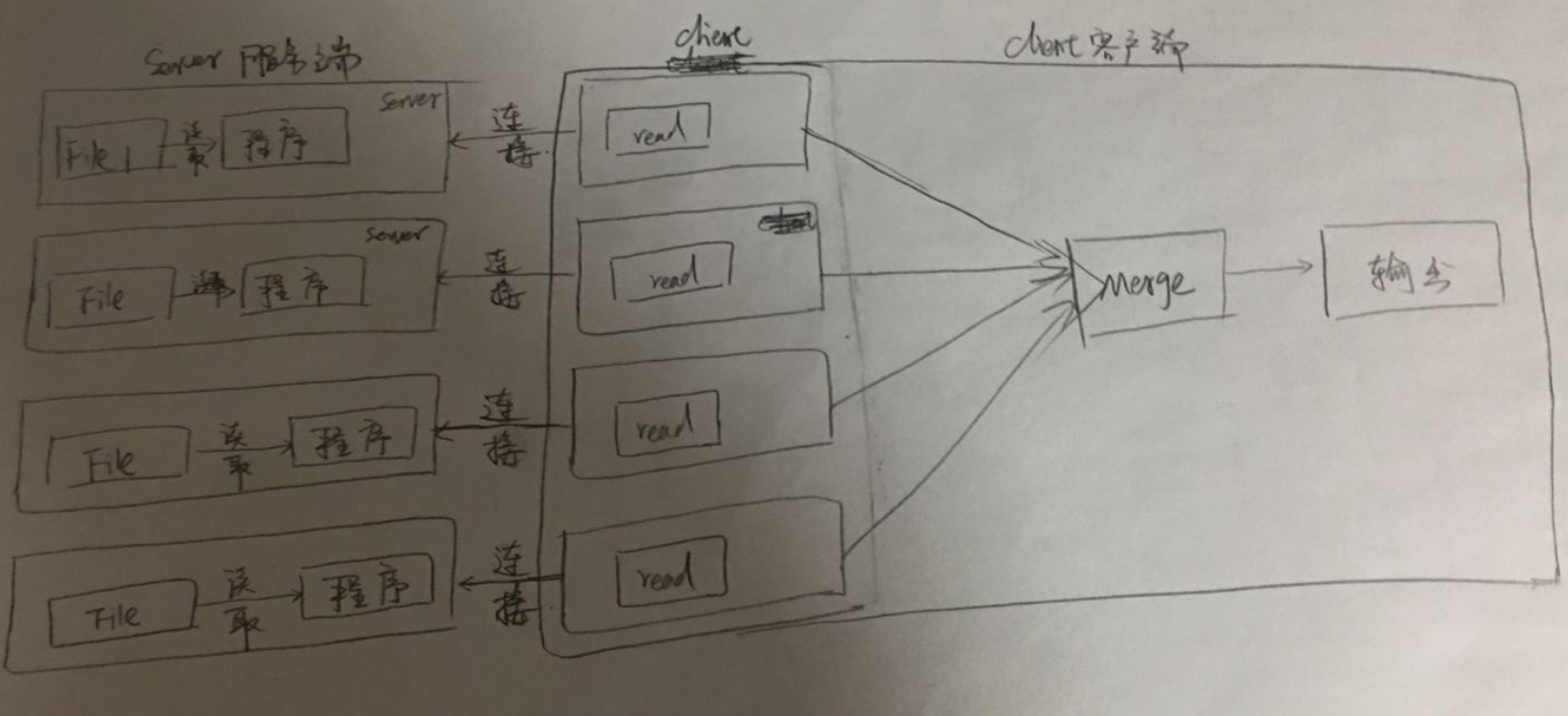
总结: 再次体验了整个go是如何使用chan进行通信的. 几乎每一部都是在使用chan进行通信.
最后这个网络版的的排序, 只是一个简单的模拟, 不过, 真实情况也许就是这样的. 修改一下就可以使用在客户端和服务端了.
3.10 附源码
项目结构
1. nodes.go
package pipeline import ( "encoding/binary" "fmt" "io" "math/rand" "sort" "time" ) var startTime time.Time func Init() { startTime = time.Now() } func ArraySource(arr ...int) <- chan int { out := make(chan int, 1000) go func() { for _, a := range arr { out <- a } close(out) }() return out } // 定义一个节点, 处理数据 func InMemSort(in <-chan int) <-chan int { // 第一步: 定义一个channel变量 out := make(chan int, 1000) // 第三步: 向channel中放数据 go func() { var arr []int // 管道到这里会阻塞, 等待close以后, 才会退出这个for循环 // 如果没有close,就会发生死锁 for v := range in { arr = append(arr, v) } fmt.Println("read data: ", time.Now().Sub(startTime)) sort.Ints(arr) fmt.Println("sorted data: ", time.Now().Sub(startTime)) for _, v := range arr { out <- v } close(out) }() // 第二步: 返回这个channel return out } func Merge(in1, in2 <-chan int) <-chan int { // 第一步: 定义一个管道变量 out := make(chan int, 1000) // 第三步: 向管道中放入数据 go func() { // 第四步: 从两个管道中取一个数据 v1, ok1 := <- in1 v2, ok2 := <- in2 // 第五步: 如果能够从任意一个管道中取出数据, 则处理 for ok1 || ok2 { if !ok2 || (ok1 && v1 <= v2) { out <- v1 v1, ok1 = <- in1 } else { out <- v2 v2, ok2 = <-in2 } } // 第六步: 没有数据可以取出来, close管道, 表示已经取完了 close(out) fmt.Println("merged data: ", time.Now().Sub(startTime)) }() // 第二步: 返回这个管道 return out } /** * 从redader中读取数据 * 将reader改为分块读取, 每次读取指定字符长度 */ func ReaderSource(reader io.Reader, trunkSize int) <- chan int{ out := make(chan int, 1000) go func() { // 这里定义为8个字节, 原因是我的机器是64位的, 所以int也是64位, 那么对应的字节数就是8个字节 buffer := make([]byte, 8) readered := 0 for { // 记录已经读取的个数 // reader返回两个参数, 第一个是读取到的字节数, 第二个是err异常 n, err := reader.Read(buffer) readered += n if n > 0 { // 如果读到了, 就把读到的东西发给channel u := binary.BigEndian.Uint64(buffer) out <- int(u) } if err != nil || (trunkSize != -1 && readered >= trunkSize){ break } //fmt.Println("已读字符数", readered) } close(out) }() return out } /** * 只读数据, 不写数据的, 将读出来的数据打印出来 * 可以打印到控制台, 也可以写入到文件. 这里就写入到文件 */ func WriteSink(writer io.Writer, in <-chan int) { for v := range in { b := make([]byte, 8) binary.BigEndian.PutUint64(b, uint64(v)) writer.Write(b) } } /** * 生成一个随机数 */ func RandomSource(count int) chan int { out := make(chan int, 1000) go func() { // 生成count个随机数 for i := 0; i<count ; i++ { out <- rand.Int() } close(out) }() return out } /** * N个节点两两归并 */ func MergeN(inputs ... <-chan int) <-chan int{ if len(inputs) == 1 { return inputs[0] } middle := len(inputs) / 2 // 两个两个的合并 return Merge(MergeN(inputs[:middle]...), MergeN(inputs[middle:]...)) }
2. main.go
package main import ( "bufio" "fmt" "os" "test007/pipeline" "time" ) func main() { // 第一步: 造数据, 生成100个随机数, 写入到文件 const fileName = "large.in" const count = 100000000 // 第一步: 将随机生产的数字保存到small.in文件 // 构造第一个数据源 file, e := os.Create(fileName) if e != nil { panic(e) } defer file.Close() dataSource := pipeline.RandomSource(count) writer := bufio.NewWriter(file) pipeline.WriteSink(writer, dataSource) writer.Flush() // 第二步: 从文件中读取文件内容, 在控制台打印 // 从第一个数据源读取出数据 f, e := os.Open(fileName) if e != nil { panic(e) } defer f.Close() readerSource := pipeline.ReaderSource(bufio.NewReader(f), -1) var num = 0 for rs := range readerSource{ fmt.Println(rs) num ++ if num > 100 { break } } } func MergeDemo() { mergeChan := pipeline.Merge( pipeline.InMemSort(pipeline.ArraySource(1, 4, 8, 2, 19, 5)), pipeline.InMemSort(pipeline.ArraySource(0, 29, 43, 1, 7, 9))) go func() { for v := range mergeChan { fmt.Println("data:", v) } }() time.Sleep(time.Second * 10) }
package pipeline import ( "bufio" "net" ) func NetWorkSink(addr string, in <- chan int) { // 第一步: 开启服务器的监听端口 listener, e := net.Listen("tcp", addr) if e != nil { panic(e) } go func() { defer listener.Close() // 第二步: 等待客户端连接 conn, e := listener.Accept() if e != nil { panic(e) } defer conn.Close() // 第三步: 将数据通过网络发送出去 writer := bufio.NewWriter(conn) defer writer.Flush() WriteSink(writer, in) }() } func NetWorkSource(addr string) <-chan int{ out := make(chan int) go func() { conn, e := net.Dial("tcp", addr) if e != nil { panic(e) } defer conn.Close() reader := bufio.NewReader(conn) source := ReaderSource(reader, -1) for s := range source { out <- s } close(out) }() return out }
4. sort.go
package main import ( "bufio" "fmt" "os" "strconv" "test007/pipeline" ) func main() { // 第一步: 生成pipeline文件 p := createNetWorkPipeline("large.in", 800000000, 4) //time.Sleep(time.Hour) // 第二步: 写入到文件 writeToFile(p, "large.out") // 第三步: 打印出来 printFile("large.out") } func printFile(fileName string) { file, e := os.Open(fileName) if e != nil { panic(e) } defer file.Close() reader := bufio.NewReader(file) source := pipeline.ReaderSource(reader, -1) count := 0 for v := range source { fmt.Println(v) count ++ if count > 100 { break } } } /** * 将合并后的结果写入到文件 */ func writeToFile(p <- chan int, fileName string) { file, e := os.Create(fileName) if e != nil { panic(e) } defer file.Close() writer := bufio.NewWriter(file) defer writer.Flush() // 这一步是将读取的内容写入到文件 pipeline.WriteSink(writer, p) } /** * @param fileName: 文件名 * @param fileSize: 文件大小 * @param chunkCount: 将文件分成多少块 */ func createPipeline(fileName string, fileSize, chunkCount int) <- chan int{ pipeline.Init() // 每次读取的内容的字节大小 chunkSize := fileSize/chunkCount sortResult := []<-chan int{} for i := 0; i < chunkCount; i++ { file, e := os.Open(fileName) if e != nil { panic(e) } // offset: 从文件的什么位置开始读 whence: 从第几个字符开始读 file.Seek(int64(chunkSize*i) , 0) // 读取文件的内容 source := pipeline.ReaderSource(bufio.NewReader(file), chunkSize) // 在内存中对内容进行排序 sortResult = append(sortResult, pipeline.InMemSort(source)) } // 合并所有的内部排序后的结果 return pipeline.MergeN(sortResult...) } /** * @param fileName: 文件名 * @param fileSize: 文件大小 * @param chunkCount: 将文件分成多少块 */ func createNetWorkPipeline(fileName string, fileSize, chunkCount int) <- chan int{ pipeline.Init() // 每次读取的内容的字节大小 chunkSize := fileSize/chunkCount sortResult := []<-chan int{} sortAddr := []string{} for i := 0; i < chunkCount; i++ { file, e := os.Open(fileName) if e != nil { panic(e) } // offset: 从文件的什么位置开始读 whence: 从第几个字符开始读 file.Seek(int64(chunkSize*i) , 0) // 读取文件的内容 source := pipeline.ReaderSource(bufio.NewReader(file), chunkSize) sort := pipeline.InMemSort(source) addr := ":" + strconv.Itoa(7000 + i) pipeline.NetWorkSink(addr, sort) // 在内存中对内容进行排序 //sortResult = append(sortResult, pipeline.InMemSort(source)) sortAddr = append(sortAddr, addr) } for _, s := range sortAddr { sortResult = append(sortResult, pipeline.NetWorkSource(s)) } // 合并所有的内部排序后的结果 return pipeline.MergeN(sortResult...) }