2.1内置序列类型概览
Python标准库用C实现了丰富的序列模型,列举如下:
1> 序列模型 list、tuple和collection.deque这些序列能存放不同类型的序列
2> 扁平模型 str、bytes、bytearray、memoryview和array.array这类序列只能存放一种类型
容器序列存放的是它们所包含任意类型对象的引用,而扁平序列存放的是值而不是引用。
序列类型还能按照能否被修改来分类:
1> 可变序列 list bytearray array.array collections.deque memoryview
2> 不可变序列 tuple str bytes
下图显示了可变序列(MutableSequence)和不可变序列(Sequence)的差异,同时也能看出前者从后者那里继承了一些方法。了解基类可以帮助我们总结出那些完整的序列类型包含了哪些功能。

2.2 列表推导和生成器表达式
列表推导是构建列表的快捷方式,而生成器表达式则可以创建其他任何类型的序列。( 列表推导(list comprehension)简称为listcomps;生成器表达式(generator expression)则称为genexps )
2.2.1 列表推导和可读性
通常原则:只用列表推导创建新的列表,并且尽量保持简短。如果列表推导的代码超过了两行就要考虑是不是得用for循环重写。Python会忽略代码里[]、{}、() 中的换行,故在多行的列表、列表推导、生成器表达式、字典这一类的,可以省略不太好看的续行符 。
1 symbols = 'hseksdth' 2 codes = [] 3 """ 4 ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。 5 """ 6 for symbol in symbols: 7 codes.append(ord(symbol)) 8 print(codes) #[104, 115, 101, 107, 115, 100, 116, 104] 9 10 symbols = 'dgshsgjh' 11 codes = [ord(symbol) for symbol in symbols] 12 print(codes) # [100, 103, 115, 104, 115, 103, 106, 104] 13 14 x = 'ABC' 15 dummy = [ord(x) for x in x] 16 print(dummy) # [65, 66, 67]
2.2.2 列表推导同filter和map的比较
Filter和map合起来做的事情,列表推导也可以做,而且还不需要借助难以理解和阅读的lambda表达式:
如下示例:
1 symbols = '$%#*&' 2 dummy = [ord(x) for x in symbols] 3 beyound_ascii = [ord(s) for s in symbols if ord(s) > 36] 4 beyound_asciii = list(filter(lambda c:c>36,map(ord,symbols))) 5 print(beyound_ascii) # [37, 42, 38] 6 print(dummy) # [36, 37, 35, 42, 38] 7 print(beyound_asciii) # [37, 42, 38]
2.2.3 笛卡尔积
用列表推导可以生成两个或以上的可迭代类型的笛卡尔积,笛卡尔积是一个列表,列表里的元素是由输入的可迭代类型的元素对构成的元组,因此笛卡尔积的列表长度等于输入变量的乘积。
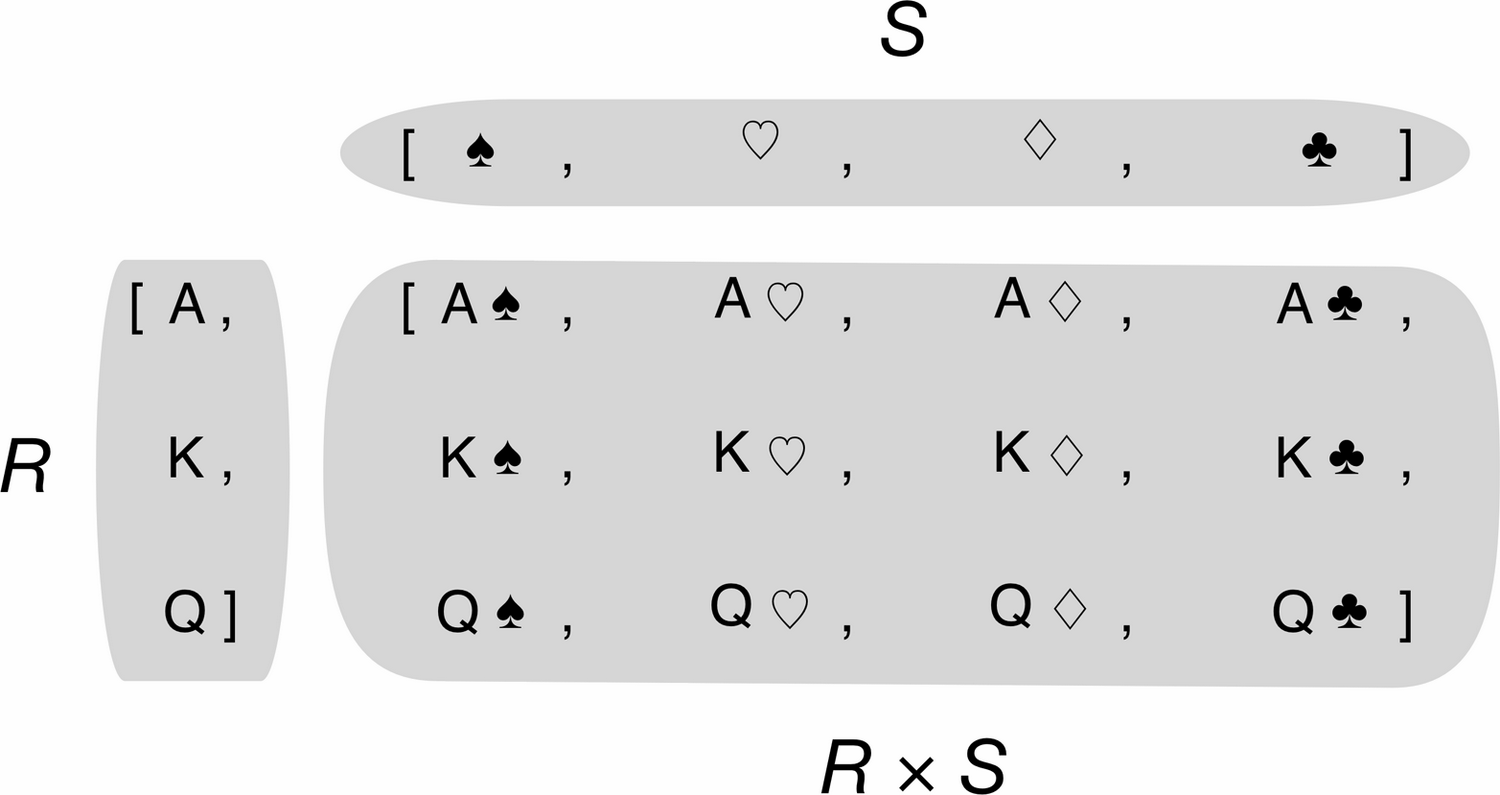
如下示例:
1 colors = ['black','white'] 2 sizes = ['S','M','L'] 3 tshirts = [(color,size) for color in colors for size in sizes] 4 print(tshirts) 5 输出:[('black', 'S'), ('black', 'M'), ('black', 'L'), ('white', 'S'), ('white', 'M'), ('white', 'L')] 6 7 tshirts2 = [(color,size) for size in sizes for color in colors] 8 print(tshirts2) 9 输出:[('black', 'S'), ('white', 'S'), ('black', 'M'), ('white', 'M'), ('black', 'L'), ('white', 'L')]
列表推导的作用只有一个:生成列表。如果想生成其他类型的序列,生成器表达式就派上了用场。
2.2.3 生成器表达式
虽然也可以用列表推导来初始化元组、数组或其他序列类型,但是生成器表达式是更好的选择。这是因为生成器表达式背后遵循了迭代器协议,可以逐个的产生元素,而不是先建立一个完整的列表,然后再把这个列表传递到某个构造函数里。生成器表达式的语法跟列表推到差不多,只不过把方括号换成圆括号。
如下示例:
1 symbols = '*&%$#@' 2 print(tuple(ord(symbol)for symbol in symbols)) 3 输出:(42, 38, 37, 36, 35, 64) 4 5 print(array.array('I',(ord(symbol)for symbol in symbols))) 6 输出:array('I', [42, 38, 37, 36, 35, 64]) 7 8 colors = ['R','G','B'] 9 sizes = ['S','M','L'] 10 for tshirt in ('%s %s'%(c,s)for c in colors for s in sizes): 11 print(tshirt) 12 输出: 13 R S 14 R M 15 R L 16 G S 17 G M 18 G L 19 B S 20 B M 21 B L
【注】1、 如果生成器表达式是一个函数调用过程中的唯一参数,那么不需要额外再用括号把它括起来。
2、array的构造方法需要两个参数,因此括号是必须的。array构造方法的第一个参数指定了数组中数字的存储方式。(后面会讲到生成器的工作原理,这里一笔带过)
2.3 元组不仅仅是不可变的列表
2.3.1 元组和记录
元组其实是对数据的记录:元组中每个元素都存放了记录中一个字段的数据,外加这个字段的位置。正是这个位置信息给数据赋予了意义。如果只把元组理解为不可变的列表,其它的信息---它所含有的元素的总数和它们的位置—似乎变得可有可无。但如果把元组当做一些字段的集合,那么数量和位置信息就变得非常重要了。
如下示例:
1 lax_coordinates = (55.236,864.1259) 2 city,year,pop,chg,area = ('Tokyo',2019,1547,0.152,8746) 3 traveler_ids = [('USA','1857642'),('BRA','845696'),('BHY','45963')] 4 for passport in sorted(traveler_ids): 5 print('%s/%s'%passport) 6 输出: 7 BHY/45963 8 BRA/845696 9 USA/1857642 10 11 for country,_ in traveler_ids: 12 print(country) 13 输出: 14 USA 15 BRA 16 BHY
【注】1、在迭代过程中,passport变量被绑定到每个元组上。
2、%格式运算符能被匹配到对应元组元素上。
3、for 循环可以分别提取元组里的元素,也叫作拆包(unpacking)。因为元组中第二个元素对我们没什么用,所以将它赋给 ‘_’ 占位符。
2.3.2 元组拆包
元组拆包可以应用到任何可迭代的对象上,唯一的硬性要求是:被可迭代对象中元素数量必须跟接受这些元素的元组空挡数一致,除非我们用 * 号来表示忽略多余的元素。
最好辨认的元组拆包形式就是平行赋值,也就是说把一个可迭代对象里的元素,一并赋值到由对应的变量组成的元组中。
1 lax_corrdinates = (33.1258,-56.4895) 2 latitude,longtitude = lax_corrdinates 3 print(latitude) 4 print(longtitude) 5 输出:33.1258 6 -56.4895
还可以用 * 运算把一个可迭代运算拆开作为函数的参数。
1 b,a = a,b # 这种写法可以在不使用中间变量的情况下交换 a,b 的值 2 print(divmod(20,8)) # divmod 把除数和余数运算结合起来,返回包含商和余数的元组 3 t = (20,8) 4 print(divmod(*t)) 5 quotient,remainder = divmod(*t) 6 print(quotient,remainder) 7 输出:(2, 4) 8 (2, 4) 9 2 4
下面一个示例,元组拆包的用法则是让一个函数可以用元组的形式返回多个值,然后调用函数的代码就能轻松地接受这些返回值。比如os.path.split() 函数就会返回以路径和最后一个文件名组成的元组(path,last_part):
1 filepath,filename = os.path.split('/home/download/myfile/study.docx') 2 print('filepath = ',filepath) 3 输出:filepath = /home/download/myfile 4 print('filename = ',filename) 5 输出:filename = study.docx 6 print('full path = '+filepath+'/'+filename) 7 输出:full path = /home/download/myfile/study.docx
在进行拆包的时候,我们不总是对元组里所有的数据都感兴趣,_占位符能帮助处理这种情况,如上所示。
除此之外,元组拆包中使用 * 也可以帮助我们将注意力集中在部分元素上面,如下示例用 * 来处理剩下的元素。在python中,函数用*args来获取不确定数量的参数算是一种经典写法。
1 a,b,*rest = range(10) 2 print(a,b,rest) 3 输出:0 1 [2, 3, 4, 5, 6, 7, 8, 9] 4 a1,b1,*rest1 = range(2) 5 print(a1,b1,rest1) 6 输出:0 1 []
在平行赋值中,*前缀只能用在一个变量名前面,但是这个变量可以出现在赋值表达式的任意位置
1 a,*body,c,d = range(5) 2 print(a,body,c,d) 3 输出:0 [1, 2] 3 4 4 *head,b,c,d = range(5) 5 print(head,b,c,d) 6 输出:[0, 1] 2 3 4
2.3.3 嵌套元组拆包
接受表达式的元组可以是嵌套的,例如 (a,b,(c,d)) 。只要这个接受元组的嵌套结构符合表达式本身的嵌套结构,python 就可以做出正确的对应。
如下示例:
1 metro_areas = [ 2 ('Tokyo','JP',50.3654,(12.458,63.45896)), 3 ('ShangHai', 'JSH', 62.3789, (85.34596, 111.25)), 4 ('GuangHou', 'GZ', 50.3654, (23.214, 98.125)), 5 ('Zhengzhou', 'ZH', 50.3654, (658.145, 985.12)), 6 ('LaSha', 'LS', 50.3654, (528.461, 753.159)), 7 ] 8 9 print('{:15}|{:^9}|{:^9}'.format('','lat.','long.')) 10 fmt = '{:15}|{:9.4f}|{:9.4f}' 11 for name,cc,pop,(latitude,longitude) in metro_areas: 12 print(fmt.format(name,latitude,longitude)) 13 输出: 14 | lat. | long. 15 Tokyo | 12.4580 | 63.4590 16 ShangHai | 85.3460 | 111.2500 17 GuangHou | 23.2140 | 98.1250 18 Zhengzhou | 658.1450 | 985.1200 19 LaSha | 528.4610 | 753.1590
【注】python3之前,元组可以作为形参放在函数声明中,例如:def fn(a,(b,c),d),然而Python3 不在支持这种形式。
2.3.4 具名元组
collections.namedtuple是一个工厂函数,它用来构建一个带字段名的元组和一个有名字的类。
用namedtuple构建的类的实例所消耗的内存跟元组是一样的,因为字段名都被存在对应的类里面。这个实例跟普通的对象实例比起来也要小一些,因为Python不会用__dict__来存放这些实例的属性。
1 City = namedtuple('City','name country population coordinates') 2 tokyo = City('Tokyo','JP',36.4598,(86.56987,84.1259)) 3 print('tokyo = ',tokyo) 4 print('tokyo.population = ',tokyo.population) 5 print('tokyo.coordinates = ',tokyo.coordinates) 6 print('City._fields = ',City._fields) 7 输出: 8 tokyo = City(name='Tokyo', country='JP', population=36.4598, coordinates=(86.56987, 84.1259)) 9 tokyo.population = 36.4598 10 tokyo.coordinates = (86.56987, 84.1259) 11 City._fields = ('name', 'country', 'population', 'coordinates')
由上可知:
1、创建一个具名元组需要两个参数:类名/类的各个字段名。后者可以是由数个字符串组成的可迭代的对象,或者是由空格分隔开的字段名组成的字符串。
2、存放在对应字段里的数据要以一串参数的形式传入到构造函数中(注意:元组的构造函数只接受单一的可迭代对象)
3、可通过字段名或者位置来获取一个字段的信息
具名元组也有自己的属性,列举几个最有用的:_fields类属性、类方法_make(iterable)和实例方法_asdict()
1 Latlong = namedtuple('Latlong','lat long') 2 delhi_data = ('Delhi NCR','IN',21.459,Latlong(25.465,87.1276)) 3 delhi = City._make(delhi_data) 4 print('delhi._asdict() = ',delhi._asdict()) 5 输出:delhi._asdict() = OrderedDict([('name', 'Delhi NCR'), ('country', 'IN'), ('population', 21.459), ('coordinates', Latlong(lat=25.465, long=87.1276))])
由上可知:
1、_fields属性是一个包含这个类所有字段名称的元组
2、用_make()通过接受一个可迭代对象来生成这个类的一个实例,它的作用跟City(*delhi_data) 是一样的
3、_asdict() 把具名元组以collections.OrderedDict的形式返回,我们可以利用它把元组里的信息友好的呈现出来