思路
我选取的网址是电影天堂。
- 下载需要用到的包
axiosiconv-lite - 进行网络请求,拿到数据
- 使用正则表达式解析数据,分离出我们需要的信息
- 将有用信息写入本地文件
代码
const axios = require("axios");
const fs = require("fs");
const iconv = require("iconv-lite");
async function movie(){
let result = await axios({
method: 'get',
url: 'https://dy.dytt8.net/html/gndy/jddy/20160320/50523.html',
responseType: 'arraybuffer'
}).then(result => result.data);
// 重新编码
result = iconv.decode(Buffer.from(result), 'gb2312');
// result = iconv.encode(buf, 'utf8').toString();
// let infoList = result.match(/<p.*a.*>/g);
// 正则表达式匹配
let infoList = result.match(/<p.*(br|a|(. .*))+.*>/g);
// console.log(infoList.slice(200, 300));
for(let i = 0; i < infoList.length; i++){
// 去除标签
infoList[i] = infoList[i].replace(/<.*?>/g, "");
}
// 写入文件
let ws = fs.createWriteStream('IMDB评分8分左右影片.txt');
await ws.write(infoList.join('
'));
ws.end();
console.log("文件写入完毕。");
}
// 调用
movie()
途中遇到的问题
起初,我没有进行重新编码,于是我请求到的数据是乱码:
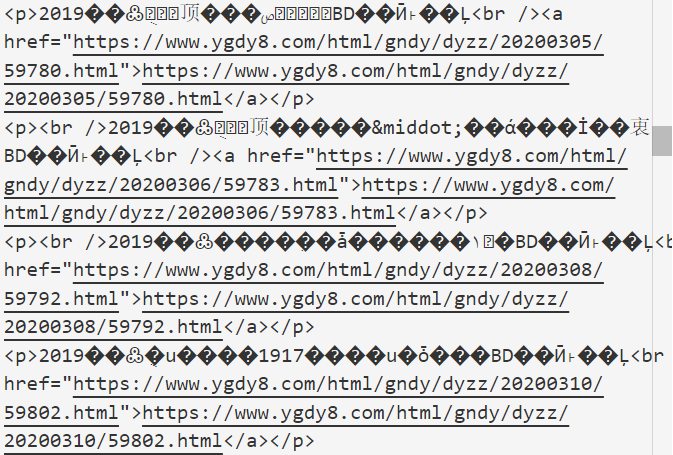
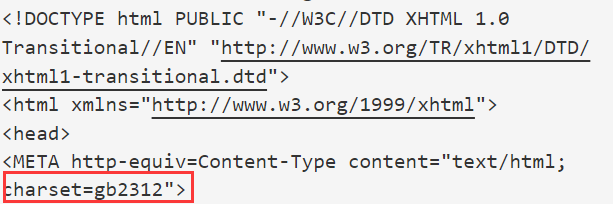
后来我读取首部信息,发现编码方式是gb2312,于是下载了iconv-lite来解码。
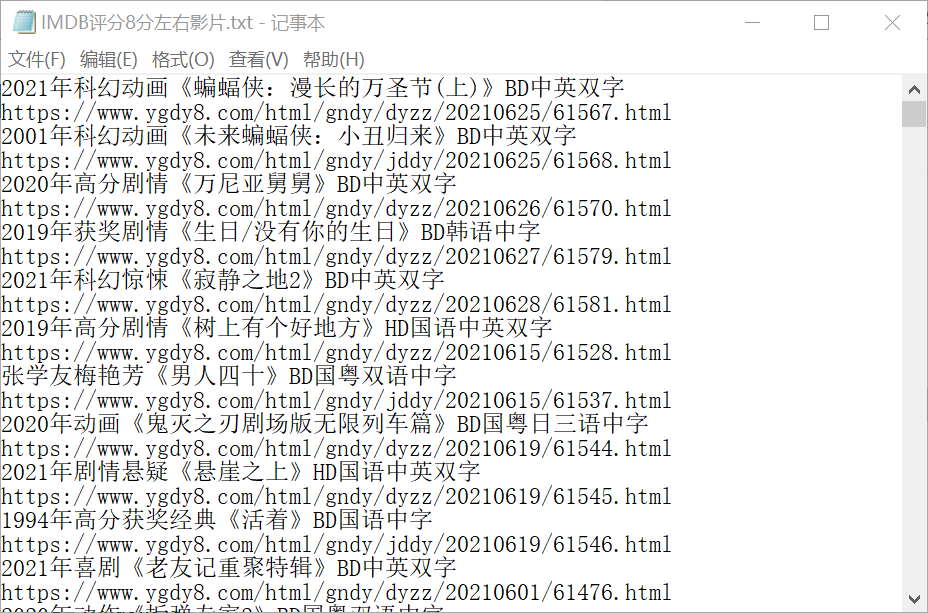
结果
大概获取了五百多部影片链接。
优化
- 可以引入别的包将数据制作成表格
- 匹配一些额外信息