本地的jupyter notebook的扛不住呀,写的东西够都存在不住鸭。
心疼自己一秒

参考书目:《Python 深度学习》 弗朗索瓦.肖莱
第一章 什么是深度学习
总体感觉给人耳目一新建议自己读一下。尤其是对于机器学习概念的阐述,确实有作者自己的见解。
第二章 神经网络的数学基础
重点:
- 张量
对于神经网络中训练时,使用反向传播算法来确定参数,这是时候数据的量是怎么选取?小批量,全集?
单词累计:
- epoch 轮次
第三章 神经网络入门
不同数据使用不同神经网络
- 2维度数据 [向量数据] ---> 秘籍连接层[densely connected layer] = 全连接层[fully connected layer] = 密集层[dense layer]
- 3维度数据 [时间序列数据 或 序列数据] ---> 循环神经网络[recurrent layer LSTM]
- 4维度数据 [图像] ---> 卷积神经网络[Conv2D]
- 5维度数据 [视频]
2.1 二分类
数据IMDB数据集
电影评价数据集:
- 0 负面
- 1 正面
翻转字典格式 key,value 颠倒
word_index = imdb.get_word_index() # 字典格式{'fawn': 34701,..}
# 翻转字典格式
reverse_word_index = dict(
[(value, key) for (key, value) in word_index.items()]
)
decoded_review = " ".join(
[reverse_word_index.get(i-3, '?') for i in train_data[0]]
)
print(train_data[0])
print(decoded_review)
数据展示:
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
? this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert ? is an amazing actor and now the same being director ? father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for ? and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also ? to the two little boy's that played the ? of norman and paul they were just brilliant children are often left out of the ? list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all
0,1,2 分别是三个保留索引
imdb.get_word_index()中最小的值是 'the':1
import numpy as np
from keras import models
from keras import layers
from keras.datasets import imdb
from keras import optimizers
import matplotlib.pyplot as plt
def vectorize_squences(squences, dimension=10000):
results = np.zeros((len(squences), dimension)) # 0向量
for i, squence in enumerate(squences):
results[i, squence] = 1. # 把有index的位置换位1
return results
# 绘制训练损失和验证损失
def train_loss_plt(history_dit):
loss_values = history_dit['loss']
val_loss_values = history_dit['val_loss']
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label='Training loss') # bo 蓝色圆点
plt.plot(epochs, val_loss_values, 'b', label='Validation loss') # b 蓝色实线
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
pass
# 绘制训练精度和验证精度
def train_accuracy_plt(history_dit):
plt.clf() # 清空图像
acc = history_dit['acc']
val_acc = history_dit['val_acc']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training loss') # bo 蓝色圆点
plt.plot(epochs, val_acc, 'b', label='Validation loss') # b 蓝色实线
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
pass
# 1 准备数据
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000) # 保留前1000个常见的单词
# 1.1 数据向量化 one-hot编码
x_train = vectorize_squences(train_data)
x_test = vectorize_squences(test_data)
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
# 2.网络构建 (三层)
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000, ))) # 隐藏层1 16个神经元、激活函数relu、输入层输入数据格式(10000,)
model.add(layers.Dense(16, activation='relu')) # 隐藏层2 16个神经元
model.add(layers.Dense(1, activation='sigmoid')) # 隐藏层3 输入概率值
# x_train.shape (25000, 10000)
# 原始训练集保留10000个作为验证集
partial_x_train = x_train[10000:]
partial_y_train = y_train[10000:]
# 剩余是神经网络训练队的数据
x_val = x_train[:10000]
y_val = y_train[:10000]
# 3.优化函数 + 算是函数
model.compile(
optimizer=optimizers.RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics=['acc']
)
# 模型训练20轮,512个样本小批量
history = model.fit(
partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val)
)
# 模型训练构成,查看神经网络优化情况
history_dit = history.history
# 绘图
train_loss_plt(history_dit)
train_accuracy_plt(history_dit)
训练的损失每轮都在降低,训练准确度(精度)都在提高,貌似在第4轮效果达到最佳,其他过拟合
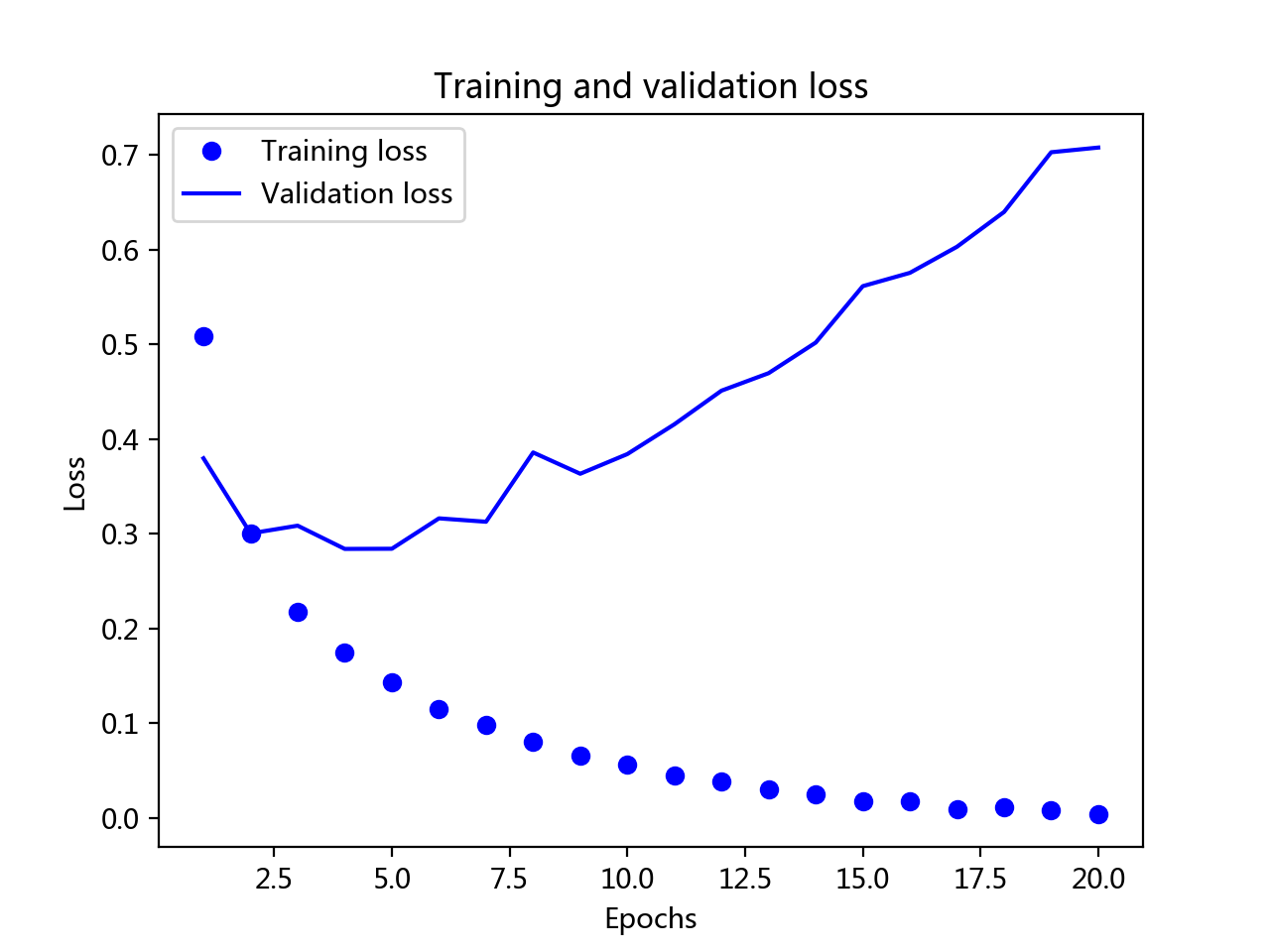
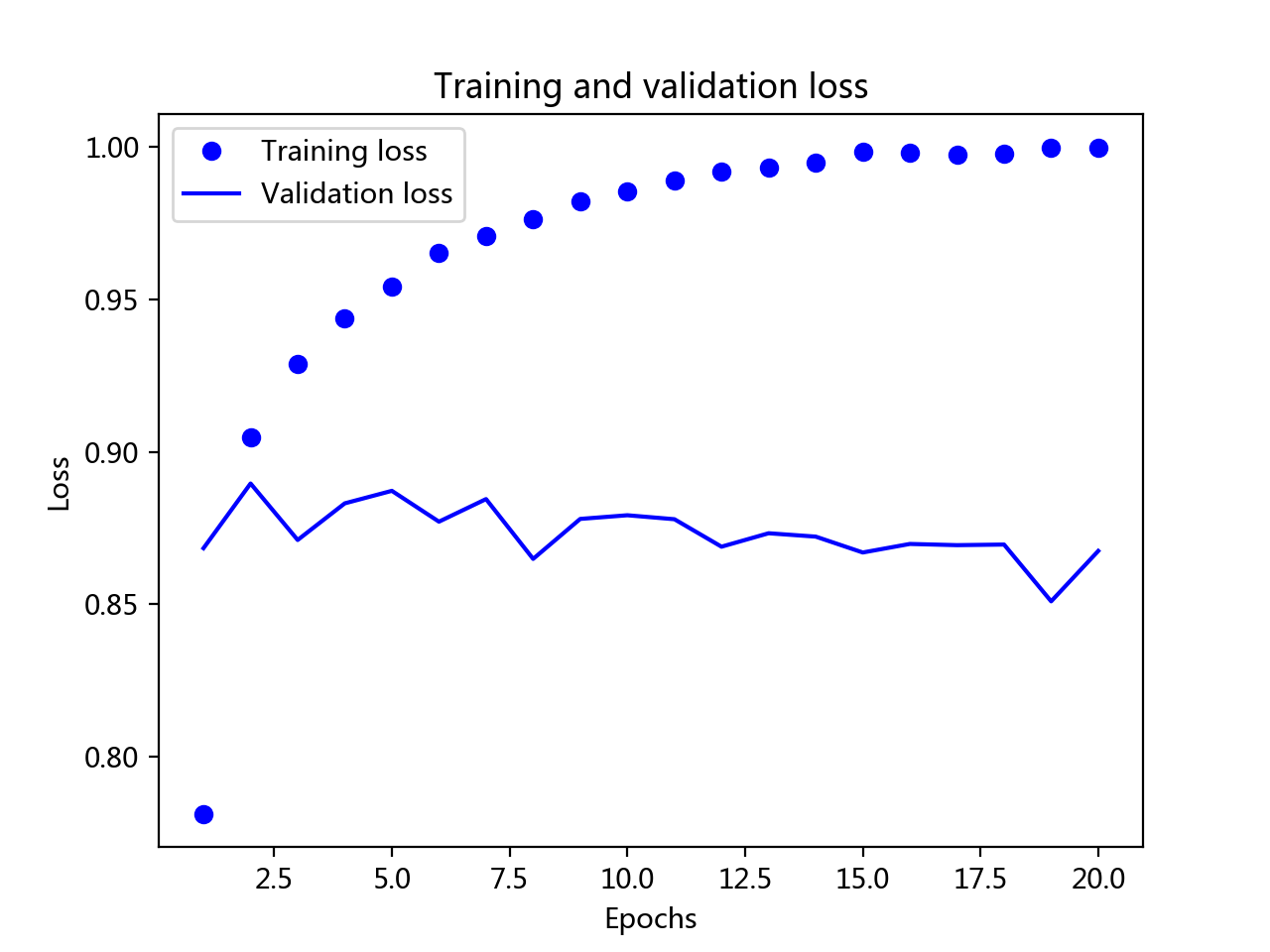
但是论文中没有交到如何确定的第四轮。在在第四章过拟合部分有介绍
2 多分类问题
"""
第三章 神经网络入门
多分类问题
数据:路透社新闻数据
"""
import numpy as np
from keras import models
from keras import layers
from keras.datasets import reuters
import matplotlib.pyplot as plt
# 绘制训练损失和验证损失
def train_loss_plt(history_dit):
loss_values = history_dit['loss']
val_loss_values = history_dit['val_loss']
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label='Training loss') # bo 蓝色圆点
plt.plot(epochs, val_loss_values, 'b', label='Validation loss') # b 蓝色实线
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
pass
# 绘制训练精度和验证精度
def train_accuracy_plt(history_dit):
plt.clf() # 清空图像
acc = history_dit['acc']
val_acc = history_dit['val_acc']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training loss') # bo 蓝色圆点
plt.plot(epochs, val_acc, 'b', label='Validation loss') # b 蓝色实线
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
pass
def translation(data):
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_newswire = ' '.join([reverse_word_index.get(i-3, '?') for i in data]) # 0,1,2 是占位符
return decoded_newswire
# 数据向量化
def vectorize_squence(sequences, dimesion=10000):
results = np.zeros((len(sequences), dimesion))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
# 标签向量化
def to_one_hot(labels, dimesion=46):
results = np.zeros((len(labels), dimesion))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
# 0.数据
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000) # 取10000个词
# 1.数据向量化
# 训练数据向量化
x_train = vectorize_squence(train_data)
one_hot_train_lables = to_one_hot(train_labels)
# 测试数据向量化
x_test = vectorize_squence(test_data)
one_hot_test_lables = to_one_hot(test_labels)
"""
标签向量化 one-hot encoding
3 -> 转化成独热向量
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categrorical(train_labels)
onr_hot_test_labels = ro_categroical(test_labels)
"""
# 2.构建网络
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
# 编译
model.compile(
optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy']
)
# 3.验证集
x_val = x_train[:1000]
partical_x_train = x_train[1000:]
y_val = one_hot_train_lables[:1000]
partical_y_train = one_hot_train_lables[1000:]
# 4.神网络模型训练
history = model.fit(
partical_x_train,
partical_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val)
)
# 模型训练构成,查看神经网络优化情况
history_dit = history.history
# 绘图
train_loss_plt(history_dit)
train_accuracy_plt(history_dit)
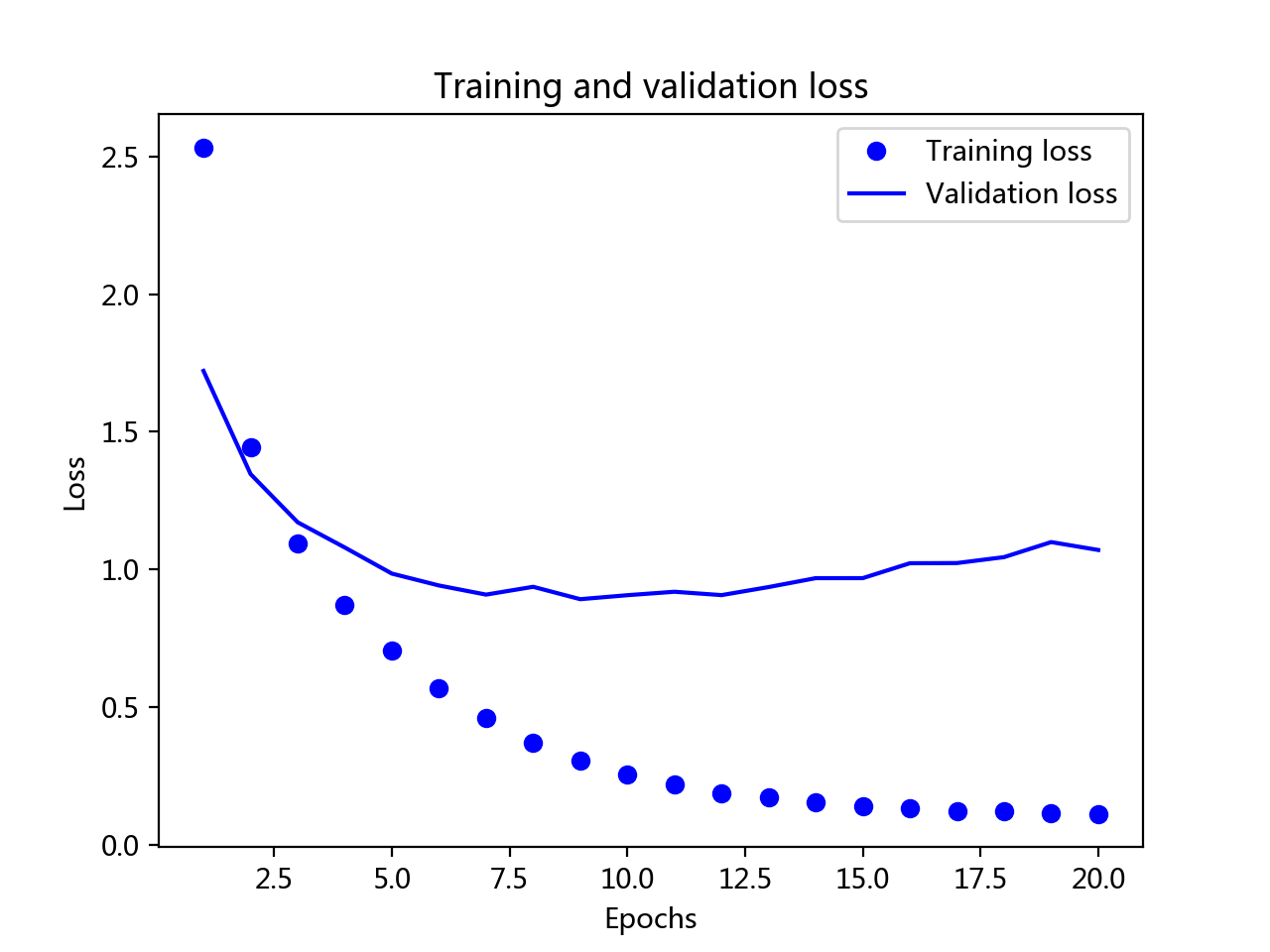
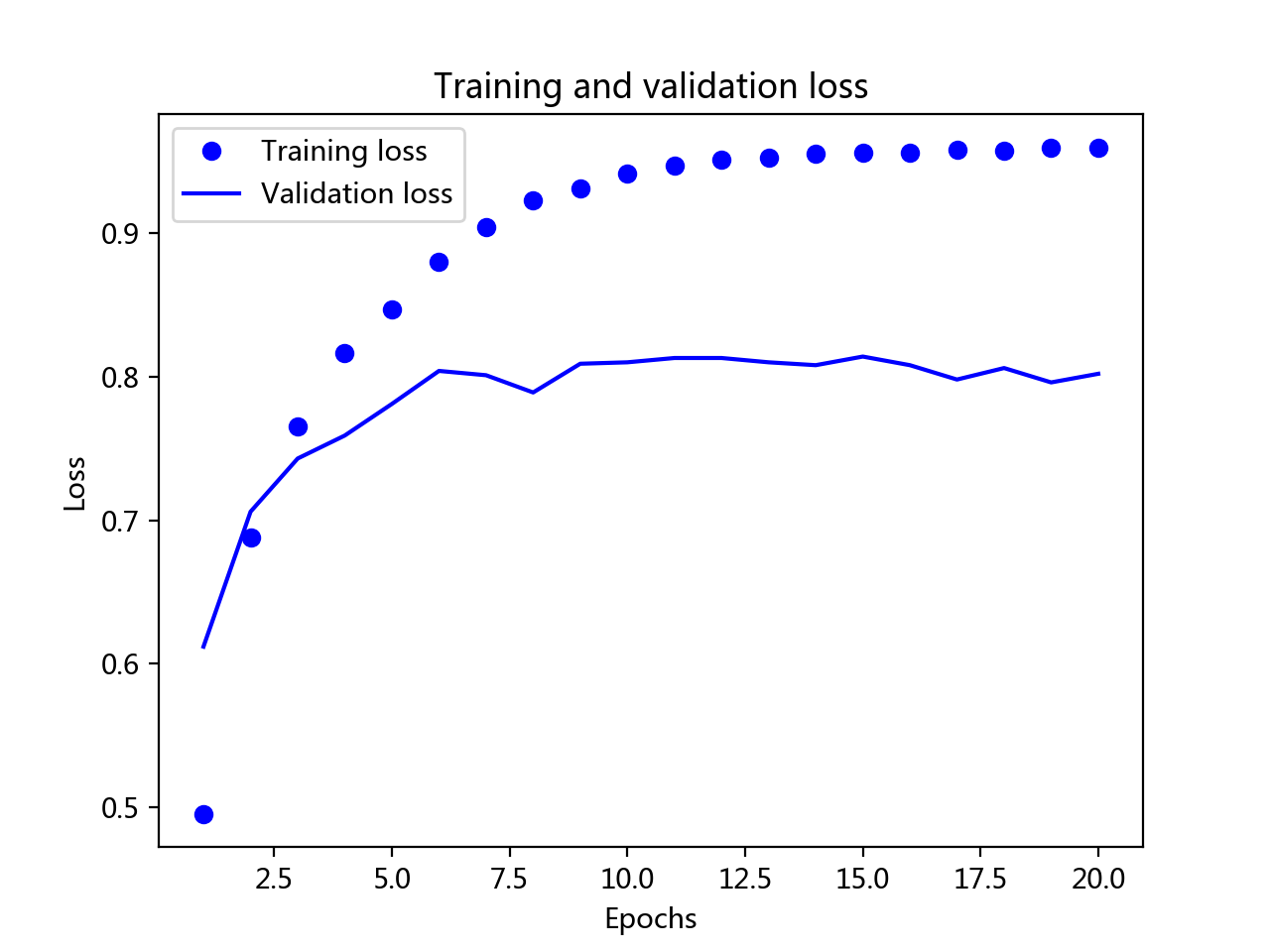
以上模型的建立都是根据这两张图选择迭代次数来确定最优神经网络算法模型。
import copy
复制值,数据的内存空间独立。
3.回归
交叉验证在数据集比较少的情况下进行。
import copy
5.深度学习用于计算机视觉
英文单词对照表
损失函数
- 二元交叉熵 binary_crossentropy
- 均方误差 mean_squared_error
优化函数
- 梯度下降法
- 随机梯度下降法
- rmsprop :RMSProp算法的全称叫 Root Mean Square Prop