作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2753
一.列表,元组,字典,集合分别如何增删改查及遍历。
- 列表
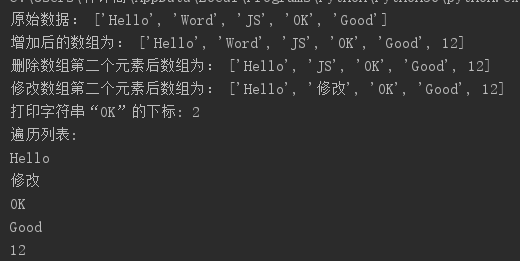
# 列表的增加 ls =['Hello','Word','JS','OK','Good'] print("原始数据:",ls) ls.append(12) # 在数组列表后面增加字符串“12” print("增加后的数组为:",ls) # 列表的删除 del ls[1] # 删除数组的第二个元素,即下标为1的字符串 # ls.pop() # 删除列表最后一个元素 print("删除数组第二个元素后数组为:",ls) # 列表的修改 ls[1] = "修改" # 删除数组的第二个元素,即下标为1的字符串 print("修改数组第二个元素后数组为:",ls) # 列表的查询 ls.index('OK') # 查找“OK”字符串 print("打印字符串“OK”的下标:",ls.index('OK')) # 遍历列表 print("遍历列表:") for i in ls: print(i)
结果:
- 元组
1 # 元组 2 YZ = ('元','组','的','元','素','不','修','改') 3 YZ1 = ('的','!') 4 YZ2 = YZ + YZ1 5 del YZ # 删除元组 6 print("元组的遍历:") 7 for i in YZ2: 8 print(" ",i)
结果:

- 字典
1 # 字典 2 D = {'这':1,'是':2,'字':3,'典':4,'!':5} 3 D['这']=11 # 修改键“这”的值 4 del D['是'] # 删除键“是” 5 a = D['这'] # 查看键a的值 6 print("字典 查看“这”的下标:",a) 7 # D.clear() # 删除字典中的所有条目 8 # 遍历输出列表 9 str(D) # 打印字典 10 for key in D: 11 print(key)
结果:

- 集合
# 集合 aa = {1, 2, 3} aa.add(4) # 增加 print(aa) aa.remove(2) # 删除 print(aa) # 遍历打印 for i in aa: print(" ",i)
结果:

二、总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
- 括号
- 有序无序
- 可变不可变
- 重复不可重复
- 存储与查找方式
|
列表 |
元组 |
字典 |
集合 |
|
|
名称 |
list |
tuple |
dict |
set |
|
初始化 |
[‘0’,’0’,’1’] |
(‘0’,’0’,’1’) |
{‘0’:1,’0’:2,’1’:3} |
{1,2}或set([2,3]) |
|
是否有序 |
有序 |
有序 |
无序,自动正序 |
无序 |
|
可否重复 |
是 |
是 |
是 |
否 |
|
读写性 |
读写 |
只读 |
读写 |
读写 |
|
存储方式 |
值 |
值 |
键值对(键不可重复) |
键(不可重复) |
|
添加 |
append |
只读 |
add |
d[‘key’]=’value’ |
三、词频统计
1.下载一长篇小说,存成utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
-
- 自定义停用词表
- 或用stops.txt
8.输出TOP(20)
9.可视化:词云
排序好的单词列表word保存成csv文件
import pandas as pd # 打开小说 f = open(r'..Linfile_textSophies World.txt', 'r', encoding='utf8') book = f.read() f.close() book_symbol = [' ', ' ', '?', '?', '!', "!"," '", "'", ' "', '"', '""', ',', ',', '.', '。','“','”',','] # 删除标点符号 for i in book_symbol: book = book.replace(i, '') # 把所有的小写 以空格分隔开 book = book.lower().split() # 打开停用词 f = open(r'..Linfile_textstops.txt', 'r', encoding='utf8') stops = f.read() f.close() # 删除多余符号 stop_symbol = [" '", "'", ' "', '"', ' '] for i in stop_symbol: stops = stops.replace(i, '') # 以逗号分隔 stops = stops.split(',') word_dict = {} # 创建词典 # 去掉停用词 word_set = set(book) - set(stops) # 遍历计算词频 for i in word_set: word_dict[i] = book.count(i) word_count = list(word_dict.items()) word_count.sort(key = lambda x:x[1], reverse = True) pd.DataFrame(data=word_count[0:20]).to_csv('Sophies World.csv', encoding='utf-8')
结果:
