为什么使用Git
孔子曾经曰过的,名正则言顺 言顺则事成。
我们在学习一项新技术之前,弄清楚为什么要学它至关重要,至于为什么要学习Git,我用一段if-else语句告诉你原因:
if(你相信我){ 我推荐你学习; } else if(诚然,我又不是什么大牛,你可以不相信我,但是你应该相信大多数人的选择){ 世界上越来越多的人、越来越多的项目在使用Git,大势所趋,势不可挡; }else if(用的人多算什么,你可能认为真理掌握在少数人手中){ 你可以不相信大众,但是你应该相信LinusTorvalds,就是靠一己之力写出了Linux内核原型的大神//我说的是内核的原型,不是内核的全部,不要挑我毛病! Git就是他创造的第二个作品 }else{ 什么?!你没听过LinusTorvalds,更不知道Linux是个什么东西…… throw new Exception(“好吧,你赢了,你可以不用学Git,我运行不下去了”); }
Git是什么
首先,Git是一个版本管理工具。
我们自己平时写个“HelloWorld”程序,或者写一个只有几百行代码的小项目,不需要专门的代码管理工具,依靠自己的记忆就能把代码捋顺。
但是,一旦涉及到代码量巨大的项目,往往需要经过很多人协同工作数周乃至数月才能完成。开发过程中,会面临着代码的修改、增删、恢复等工作,开发人员不可能清楚的记得每次变化,这时候就需要借助版本管理工具来跟踪代码的变化历程。
版本管理工具赋予每个文件一个版本号,每次修改之后,哪怕只改动了一个字母,版本管理工具都会精确地记录下来,并改变该文件的版本号。这样,每个版本号就对应着文件的一次变化,依此可以进行文件的对比、恢复等操作。
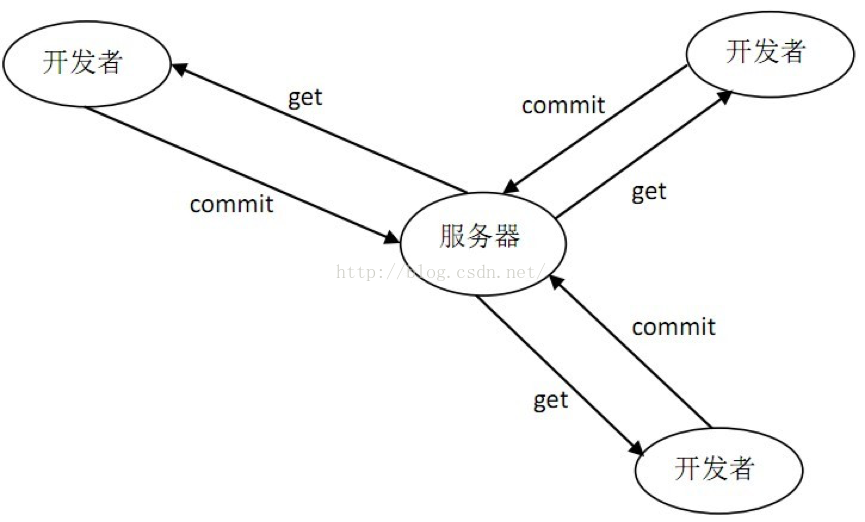
最早广泛应用的版本管理工具是CVS(Concurrent Versions System),后来逐渐被SVN(Subversion)替代,两者的工作原理类似,都是以一台服务器为核心进行集中式代码管理:
集中式 vs 分布式
SVN属于典型的集中式版本控制系统,集中式版本控制系统都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。
这种做法带来了许多好处,特别是相较于老式的本地VCS 来说。现在,每个人都可以一定程度上看到项目中的其他人正在做些什么。而管理员也可以轻松掌控每个开发者的权限。
事分两面,有好有坏。这么做最显而易见的缺点是中央服务器的单点故障。若是宕机一小时,那么在这一小时内,谁都无法提交更新、还原、对比等,也就无法协同工作。如果中央服务器的磁盘发生故障,并且没做过备份或者备份得不够及时的话,还会有丢失数据的风险。最坏的情况是彻底丢失整个项目的所有历史更改记录,被客户端提取出来的某些快照数据除外,但这样的话依然是个问题,不能保证所有的数据都已经有人提取出来。
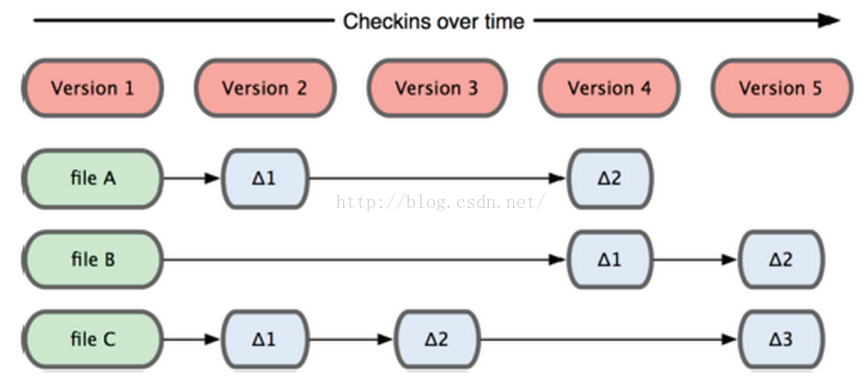
SVN只关心文件内容的具体差异。每次记录有哪些文件作了更新,以及都更新了什么内容。如下图所示:
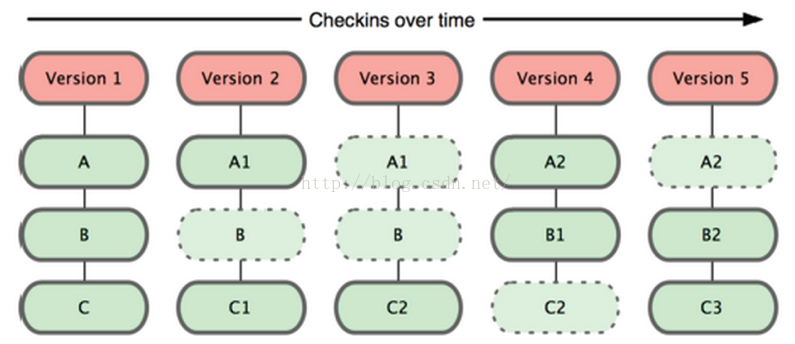
与SVN不同,Git记录版本历史只关心文件数据的整体是否发生变化。Git 并不保存文件内容前后变化的差异数据。实际上,Git 更像是把变化的文件作快照后,记录在一个微型的文件系统中。每次提交更新时,它会纵览一遍所有文件的指纹信息并对文件作一快照,然后保存一个指向这次快照的索引。为提高性能,若文件没有变化,Git 不会再次保存,而只对上次保存的快照作一连接。Git 的工作方式如下图所示:
在分布式版本控制系统中,客户端并不只提取最新版本的文件快照,而是把原始的代码仓库完整地镜像下来。这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。这类系统都可以指定和若干不同的远端代码仓库进行交互。借此,就可以在同一个项目中,分别和不同工作小组的人相互协作。可以根据需要设定不同的协作流程。
另外,因为Git在本地磁盘上保存着所有有关当前项目的历史更新,并且Git中的绝大多数操作都只需要访问本地文件和资源,不用连网,所以处理起来速度飞快。用SVN的话,没有网络或者断开VPN就无法做任何事情。但用Git的话,就算你在飞机或者火车上,都可以非常愉快地频繁提交更新,等到了有网络的时候再上传到远程的镜像仓库。换作其他版本控制系统,这么做几乎不可能,抑或是非常麻烦。
简略的说,Git具有以下特点:
1、Git中每个克隆(clone)的版本库都是平等的。可以从任何一个版本库的克隆来创建属于自己的版本库,同时你的版本库也可以作为源提供给他人,只要你愿意。
2、Git的每一次提取操作,实际上都是一次对代码仓库的完整备份。
3、提交完全在本地完成,无须别人给你授权,你的版本库你作主,并且提交总是会成功。
4、Git的提交不会被打断,直到你的工作完全满意了,PUSH给他人或者他人PULL你的版本库,合并会发生在PULL和PUSH过程中,不能自动解决的冲突会提示你手工完成。
全局版本号 vs 全球版本号
SVN的全局版本号和CVS的每个文件都独立维护一套版本号,在看似简单的全局版本号的背后,是SVN提供对于事物处理的支持,每一个事物处理(即一次提交)都具有整个版本库全局唯一的版本号。
Git的版本号则更进一步,版本号是全球唯一的。在保存到 Git 之前,所有数据都要进行内容的校验和(checksum)计算,并将此结果作为数据的唯一标识和索引。换句话说,不可能在你修改了文件或目录之后,Git 一无所知。这项特性作为 Git 的设计哲学,建在整体架构的最底层。所以如果文件在传输时变得不完整,或者磁盘损坏导致文件数据缺失,Git 都能立即察觉。
Git 使用 SHA-1 算法计算数据的校验和,通过对文件的内容或目录的结构计算出一个 SHA-1 哈希值,作为指纹字符串。该字串由 40 个十六进制字符(0-9 及a-f)组成,看起来就像是这个样子:
24b9da6552252987aa493b52f8696cd6d3b00373
1、所有保存在Git 数据库中的东西都是用此哈希值来作索引的,而不是靠文件名。
2、使用哈希值作版本号的好处就是对于一个分布式的版本控制系统,每个人每次提交后形成的版本号都不会出现重复。另一好处是保证数据的完整性,因为哈希值是根据内容或目录结构计算出来的,所以我们还可以据此来判断数据内容是否被篡改。
3、SVN 的版本号是连续的,可以预判下一个版本号,而 Git 的版本号则不是。因为 subversion 是集中式版本控制,很容易实现版本号的连续性。Git 是分布式的版本控制系统,而且Git 采用 40 位长的哈希值作为版本号,每个人的提交都是各自独立完成的,没有先后之分(即使提交有先后之分,也由于PUSH/PULL的方向和时机而不同)。Git 的版本号虽然不连续,但是是有线索的,即每一个版本都有对应的父版本(一个或者两个),进而可以形成一个复杂的提交链。
4、Git 的版本号简化:Git 可以使用从左面开始任意长度的字串作为简化版本号,只要该简化的版本号不产生歧义。一般采用7位的短版本号(只要不会出现重复的,你也可以使用更短的版本号)。
许多人可能会担心一个问题:在随机的偶然情况下,在他们的仓库里会出现两个具有相同 SHA-1 值的对象。那会怎么样呢?
如果你真的向仓库里提交了一个跟之前的某个对象具有相同 SHA-1 值的对象,Git 将会发现之前的那个对象已经存在在 Git 数据库中,并认为它已经被写入了。如果什么时候你想再次检出那个对象时,你会总是得到先前的那个对象的数据。
不过,你应该了解到,这种情况发生的概率是多么微小。SHA-1 摘要长度是 20 字节,也就是 160 位。为了保证有 50% 的概率出现一次冲突,需要 2^80 个随机哈希的对象(计算冲突机率的公式是p = (n(n-1)/2) *(1/2^160))。2^80 是 1.2 x 10^24,也就是一亿亿亿,那是地球上沙粒总数的 1200 倍。
现在举例说一下怎样才能产生一次SHA-1 冲突。如果地球上 65 亿的人类都在编程,每人每秒都在产生等价于整个 Linux 内核历史(一百万个 Git 对象)的代码,并将之提交到一个巨大的 Git 仓库里面,那将花费 5 年的时间才会产生足够的对象,使其拥有 50% 的概率产生一次 SHA-1 对象冲突……
所以,你还担心会冲突吗?
转自:http://blog.csdn.net/u012152619/article/details/51906008
从什么都不懂开始(一)——什么是Git[转]
前言
背景
用了Git蛮久了,也没有怎么系统地学习过,大部分情况也是比较依赖编译器,所以想从头梳理一下Git基础,就想写一篇从没用过Git的人也能看懂,并能入门,再渐渐成长。
一些运用git很熟练的大牛们可以点击返回或关闭啦~
简介
在了解Git之前,你得先了解什么是版本控制系统,如果不知道什么是版本控制系统,你可以先简单的理解成“可以追踪每次文件修改的系统,如果你某次修改出错,想回退,那么可以回退到某次修改,避免一些灾难性事件发生(比如电脑坏了、硬盘烧了)”。
下面是一张开发的时候使用到的版本控制系统示意图: 
什么是Git
如果你之前使用过SVN,那么Git和SVN是类似的,都是一种版本控制工具,Git拥有”本地仓库“,即使不联网,也能在本地做版本管理。可能Git的命令会很多,但是没关系,我们先慢慢学,掌握几种常用的,再深入学习一些高级技巧。
朝Git迈出第一步
安装Git
Linux
基于 Fedora 的发行版 :
$ sudo yum install git
基于 Debian 的发行版 :
$ sudo apt-get install git
如果还有一些其他版本的Linux请具体参考 :
http://git-scm.com/download/linux
Mac
在Mac上安装有两种方案:
1、直接安装Xcode,装完打开Terminal如果没安装过Command Line Tools 会有相应的提示。
2、在 http://git-scm.com/download/mac 下载最新版本即可
Windows
在Windows上也有几种方法:
1、打开 http://git-scm.com/download/win 会直接下载。
2、下载Github for Windows 地址为:http://windows.github.com
其他安装方法
从源码安装,源码地址在 https://github.com/git/git/releases有兴趣的同学可以去了解一下
下节预告
安装完环境后,就要去尝试一下使用了,那么我们接下来会准备在Github平台去实践,如果没有注册Github的同学们赶紧注册一个,
因为我们是Android开发者,所以接下来的内容会使用Android平台做示范。
转自:http://blog.csdn.net/marktheone/article/details/52047155
起步
本章介绍开始使用 Git 前的相关知识。我们会先了解一些版本控制工具的历史背景,然后试着让 Git 在你的系统上跑起来,直到最后配置好,可以正常开始开发工作。读完本章,你就会明白为什么 Git 会如此流行,为什么你应该立即开始使用它。
1.1 关于版本控制
什么是版本控制?我真的需要吗?版本控制是一种记录若干文件内容变化,以便将来查阅特定版本修订情况的系统。在本书所展示的例子中,我们仅对保存着软件源代码的文本文件作版本控制管理,但实际上,你可以对任何类型的文件进行版本控制。
如果你是位图形或网页设计师,可能会需要保存某一幅图片或页面布局文件的所有修订版本(这或许是你非常渴望拥有的功能)。采用版本控制系统 (VCS)是个明智的选择。有了它你就可以将某个文件回溯到之前的状态,甚至将整个项目都回退到过去某个时间点的状态。你可以比较文件的变化细节,查出最 后是谁修改了哪个地方,从而导致出现怪异问题,又是谁在何时报告了某个功能缺陷等等。使用版本控制系统通常还意味着,就算你乱来一气把整个项目中的文件改 的改删的删,你也照样可以轻松恢复到原先的样子。但额外增加的工作量却微乎其微。
本地版本控制系统
许多人习惯用复制整个项目目录的方式来保存不同的版本,或许还会改名加上备份时间以示区别。这么做唯一的好处就是简单。不过坏处也不少:有时候会混淆所在的工作目录,一旦弄错文件丢了数据就没法撤销恢复。
为了解决这个问题,人们很久以前就开发了许多种本地版本控制系统,大多都是采用某种简单的数据库来记录文件的历次更新差异(见图 1-1)。

图 1-1. 本地版本控制系统
其中最流行的一种叫做 rcs,现今许多计算机系统上都还看得到它的踪影。甚至在流行的 Mac OS X 系统上安装了开发者工具包之后,也可以使用 rcs 命令。它的工作原理基本上就是保存并管理文件补丁(patch)。文件补丁是一种特定格式的文本文件,记录着对应文件修订前后的内容变化。所以,根据每次 修订后的补丁,rcs 可以通过不断打补丁,计算出各个版本的文件内容。
集中化的版本控制系统
接下来人们又遇到一个问题,如何让在不同系统上的开发者协同工作?于是,集中化的版本控制系统( Centralized Version Control Systems,简称 CVCS )应运而生。这类系统,诸如 CVS,Subversion 以及 Perforce 等,都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。多年以来,这 已成为版本控制系统的标准做法(见图 1-2)。

图 1-2. 集中化的版本控制系统
这种做法带来了许多好处,特别是相较于老式的本地 VCS 来说。现在,每个人都可以在一定程度上看到项目中的其他人正在做些什么。而管理员也可以轻松掌控每个开发者的权限,并且管理一个 CVCS 要远比在各个客户端上维护本地数据库来得轻松容易。
事分两面,有好有坏。这么做最显而易见的缺点是中央服务器的单点故障。如果宕机一小时,那么在这一小时内,谁都无法提交更新,也就无法协同工作。要 是中央服务器的磁盘发生故障,碰巧没做备份,或者备份不够及时,就还是会有丢失数据的风险。最坏的情况是彻底丢失整个项目的所有历史更改记录,而被客户端 提取出来的某些快照数据除外,但这样的话依然是个问题,你不能保证所有的数据都已经有人事先完整提取出来过。本地版本控制系统也存在类似问题,只要整个项 目的历史记录被保存在单一位置,就有丢失所有历史更新记录的风险。
分布式版本控制系统
于是分布式版本控制系统( Distributed Version Control System,简称 DVCS )面世了。在这类系统中,像 Git,Mercurial,Bazaar 以及 Darcs 等,客户端并不只提取最新版本的文件快照,而是把原始的代码仓库完整地镜像下来。这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜 像出来的本地仓库恢复。因为每一次的提取操作,实际上都是一次对代码仓库的完整备份(见图 1-3)。

图 1-3. 分布式版本控制系统
更进一步,许多这类系统都可以指定和若干不同的远端代码仓库进行交互。籍此,你就可以在同一个项目中,分别和不同工作小组的人相互协作。你可以根据需要设定不同的协作流程,比如层次模型式的工作流,而这在以前的集中式系统中是无法实现的。
1.2 Git 简史
同生活中的许多伟大事件一样,Git 诞生于一个极富纷争大举创新的年代。Linux 内核开源项目有着为数众广的参与者。绝大多数的 Linux 内核维护工作都花在了提交补丁和保存归档的繁琐事务上(1991-2002年间)。到 2002 年,整个项目组开始启用分布式版本控制系统 BitKeeper 来管理和维护代码。
到了 2005 年,开发 BitKeeper 的商业公司同 Linux 内核开源社区的合作关系结束,他们收回了免费使用 BitKeeper 的权力。这就迫使 Linux 开源社区(特别是 Linux 的缔造者 Linus Torvalds )不得不吸取教训,只有开发一套属于自己的版本控制系统才不至于重蹈覆辙。他们对新的系统制订了若干目标:
* 速度 * 简单的设计 * 对非线性开发模式的强力支持(允许上千个并行开发的分支) * 完全分布式 * 有能力高效管理类似 Linux 内核一样的超大规模项目(速度和数据量)
自诞生于 2005 年以来,Git 日臻成熟完善,在高度易用的同时,仍然保留着初期设定的目标。它的速度飞快,极其适合管理大项目,它还有着令人难以置信的非线性分支管理系统(见第三章),可以应付各种复杂的项目开发需求。
1.3 Git 基础
那么,简单地说,Git 究竟是怎样的一个系统呢?请注意,接下来的内容非常重要,若是理解了 Git 的思想和基本工作原理,用起来就会知其所以然,游刃有余。在开始学习 Git 的时候,请不要尝试把各种概念和其他版本控制系统(诸如 Subversion 和 Perforce 等)相比拟,否则容易混淆每个操作的实际意义。Git 在保存和处理各种信息的时候,虽然操作起来的命令形式非常相近,但它与其他版本控制系统的做法颇为不同。理解这些差异将有助于你准确地使用 Git 提供的各种工具。
直接记录快照,而非差异比较
Git 和其他版本控制系统的主要差别在于,Git 只关心文件数据的整体是否发生变化,而大多数其他系统则只关心文件内容的具体差异。这类系统 (CVS,Subversion,Perforce,Bazaar 等等)每次记录有哪些文件作了更新,以及都更新了哪些行的什么内容,请看图 1-4。

图 1-4. 其他系统在每个版本中记录着各个文件的具体差异
Git 并不保存这些前后变化的差异数据。实际上,Git 更像是把变化的文件作快照后,记录在一个微型的文件系统中。每次提交更新时,它会纵览一遍所有文件的指纹信息并对文件作一快照,然后保存一个指向这次快照 的索引。为提高性能,若文件没有变化,Git 不会再次保存,而只对上次保存的快照作一链接。Git 的工作方式就像图 1-5 所示。

图 1-5. Git 保存每次更新时的文件快照
这是 Git 同其他系统的重要区别。它完全颠覆了传统版本控制的套路,并对各个环节的实现方式作了新的设计。Git 更像是个小型的文件系统,但它同时还提供了许多以此为基础的超强工具,而不只是一个简单的 VCS。稍后在第三章讨论 Git 分支管理的时候,我们会再看看这样的设计究竟会带来哪些好处。
近乎所有操作都是本地执行
在 Git 中的绝大多数操作都只需要访问本地文件和资源,不用连网。但如果用 CVCS 的话,差不多所有操作都需要连接网络。因为 Git 在本地磁盘上就保存着所有当前项目的历史更新,所以处理起来速度飞快。
举个例子,如果要浏览项目的历史更新摘要,Git 不用跑到外面的服务器上去取数据回来,而直接从本地数据库读取后展示给你看。所以任何时候你都可以马上翻阅,无需等待。如果想要看当前版本的文件和一个月 前的版本之间有何差异,Git 会取出一个月前的快照和当前文件作一次差异运算,而不用请求远程服务器来做这件事,或是把老版本的文件拉到本地来作比较。
用 CVCS 的话,没有网络或者断开 VPN 你就无法做任何事情。但用 Git 的话,就算你在飞机或者火车上,都可以非常愉快地频繁提交更新,等到了有网络的时候再上传到远程仓库。同样,在回家的路上,不用连接 VPN 你也可以继续工作。换作其他版本控制系统,这么做几乎不可能,抑或非常麻烦。比如 Perforce,如果不连到服务器,几乎什么都做不了(译注:默认无法发出命令p4 edit file 开始编辑文件,因为 Perforce 需要联网通知系统声明该文件正在被谁修订。但实际上手工修改文件权限可以绕过这个限制,只是完成后还是无法提交更新。);如果是 Subversion 或 CVS,虽然可以编辑文件,但无法提交更新,因为数据库在网络上。看上去好像这些都不是什么大问题,但实际体验过之后,你就会惊喜地发现,这其实是会带来很大不同的。
时刻保持数据完整性
在保存到 Git 之前,所有数据都要进行内容的校验和(checksum)计算,并将此结果作为数据的唯一标识和索引。换句话说,不可能在你修改了文件或目录之后,Git 一无所知。这项特性作为 Git 的设计哲学,建在整体架构的最底层。所以如果文件在传输时变得不完整,或者磁盘损坏导致文件数据缺失,Git 都能立即察觉。
Git 使用 SHA-1 算法计算数据的校验和,通过对文件的内容或目录的结构计算出一个 SHA-1 哈希值,作为指纹字符串。该字串由 40 个十六进制字符(0-9 及 a-f)组成,看起来就像是:
24b9da6552252987aa493b52f8696cd6d3b00373Git 的工作完全依赖于这类指纹字串,所以你会经常看到这样的哈希值。实际上,所有保存在 Git 数据库中的东西都是用此哈希值来作索引的,而不是靠文件名。
多数操作仅添加数据
常用的 Git 操作大多仅仅是把数据添加到数据库。因为任何一种不可逆的操作,比如删除数据,都会使回退或重现历史版本变得困难重重。在别的 VCS 中,若还未提交更新,就有可能丢失或者混淆一些修改的内容,但在 Git 里,一旦提交快照之后就完全不用担心丢失数据,特别是养成定期推送到其他仓库的习惯的话。
这种高可靠性令我们的开发工作安心不少,尽管去做各种试验性的尝试好了,再怎样也不会弄丢数据。至于 Git 内部究竟是如何保存和恢复数据的,我们会在第九章讨论 Git 内部原理时再作详述。
文件的三种状态
好,现在请注意,接下来要讲的概念非常重要。对于任何一个文件,在 Git 内都只有三种状态:已提交(committed),已修改(modified)和已暂存(staged)。已提交表示该文件已经被安全地保存在本地数据库 中了;已修改表示修改了某个文件,但还没有提交保存;已暂存表示把已修改的文件放在下次提交时要保存的清单中。
由此我们看到 Git 管理项目时,文件流转的三个工作区域:Git 的工作目录,暂存区域,以及本地仓库。

图 1-6. 工作目录,暂存区域,以及本地仓库
每个项目都有一个 Git 目录(译注:如果 git clone 出来的话,就是其中 .git 的目录;如果git clone --bare 的话,新建的目录本身就是 Git 目录。),它是 Git 用来保存元数据和对象数据库的地方。该目录非常重要,每次克隆镜像仓库的时候,实际拷贝的就是这个目录里面的数据。
从项目中取出某个版本的所有文件和目录,用以开始后续工作的叫做工作目录。这些文件实际上都是从 Git 目录中的压缩对象数据库中提取出来的,接下来就可以在工作目录中对这些文件进行编辑。
所谓的暂存区域只不过是个简单的文件,一般都放在 Git 目录中。有时候人们会把这个文件叫做索引文件,不过标准说法还是叫暂存区域。
基本的 Git 工作流程如下:
1. 在工作目录中修改某些文件。 2. 对修改后的文件进行快照,然后保存到暂存区域。 3. 提交更新,将保存在暂存区域的文件快照永久转储到 Git 目录中。
所以,我们可以从文件所处的位置来判断状态:如果是 Git 目录中保存着的特定版本文件,就属于已提交状态;如果作了修改并已放入暂存区域,就属于已暂存状态;如果自上次取出后,作了修改但还没有放到暂存区域,就 是已修改状态。到第二章的时候,我们会进一步了解其中细节,并学会如何根据文件状态实施后续操作,以及怎样跳过暂存直接提交。
1.4 安装 Git
是时候动手尝试下 Git 了,不过得先安装好它。有许多种安装方式,主要分为两种,一种是通过编译源代码来安装;另一种是使用为特定平台预编译好的安装包。
从源代码安装
若是条件允许,从源代码安装有很多好处,至少可以安装最新的版本。Git 的每个版本都在不断尝试改进用户体验,所以能通过源代码自己编译安装最新版本就再好不过了。有些 Linux 版本自带的安装包更新起来并不及时,所以除非你在用最新的 distro 或者 backports,那么从源代码安装其实该算是最佳选择。
Git 的工作需要调用 curl,zlib,openssl,expat,libiconv 等库的代码,所以需要先安装这些依赖工具。在有 yum 的系统上(比如 Fedora)或者有 apt-get 的系统上(比如 Debian 体系),可以用下面的命令安装:
$ yum install curl-devel expat-devel gettext-devel
openssl-devel zlib-devel
$ apt-get install libcurl4-gnutls-dev libexpat1-dev gettext
libz-dev libssl-dev之后,从下面的 Git 官方站点下载最新版本源代码:
http://git-scm.com/download然后编译并安装:
$ tar -zxf git-1.7.2.2.tar.gz
$ cd git-1.7.2.2
$ make prefix=/usr/local all
$ sudo make prefix=/usr/local install现在已经可以用 git 命令了,用 git 把 Git 项目仓库克隆到本地,以便日后随时更新:
$ git clone git://git.kernel.org/pub/scm/git/git.git在 Linux 上安装
如果要在 Linux 上安装预编译好的 Git 二进制安装包,可以直接用系统提供的包管理工具。在 Fedora 上用 yum 安装:
$ yum install git-core在 Ubuntu 这类 Debian 体系的系统上,可以用 apt-get 安装:
$ apt-get install git-core在 Mac 上安装
在 Mac 上安装 Git 有两种方式。最容易的当属使用图形化的 Git 安装工具,界面如图 1-7,下载地址在:
http://code.google.com/p/git-osx-installer
图 1-7. Git OS X 安装工具
另一种是通过 MacPorts (http://www.macports.org) 安装。如果已经装好了 MacPorts,用下面的命令安装 Git:
$ sudo port install git-core +svn +doc +bash_completion +gitweb这种方式就不需要再自己安装依赖库了,Macports 会帮你搞定这些麻烦事。一般上面列出的安装选项已经够用,要是你想用 Git 连接 Subversion 的代码仓库,还可以加上 +svn 选项,具体将在第八章作介绍。(译注:还有一种是使用 homebrew(https://github.com/mxcl/homebrew):brew install git。)
在 Windows 上安装
在 Windows 上安装 Git 同样轻松,有个叫做 msysGit 的项目提供了安装包,可以到 Google Code 的页面上下载 exe 安装文件并运行:
http://code.google.com/p/msysgit完成安装之后,就可以使用命令行的 git 工具(已经自带了 ssh 客户端)了,另外还有一个图形界面的 Git 项目管理工具。
1.5 初次运行 Git 前的配置
一般在新的系统上,我们都需要先配置下自己的 Git 工作环境。配置工作只需一次,以后升级时还会沿用现在的配置。当然,如果需要,你随时可以用相同的命令修改已有的配置。
Git 提供了一个叫做 git config 的工具(译注:实际是 git-config 命令,只不过可以通过 git加一个名字来呼叫此命令。),专门用来配置或读取相应的工作环境变量。而正是由这些环境变量,决定了 Git 在各个环节的具体工作方式和行为。这些变量可以存放在以下三个不同的地方:
/etc/gitconfig文件:系统中对所有用户都普遍适用的配置。若使用git config时用--system选项,读写的就是这个文件。~/.gitconfig文件:用户目录下的配置文件只适用于该用户。若使用git config时用--global选项,读写的就是这个文件。- 当前项目的 git 目录中的配置文件(也就是工作目录中的
.git/config文件):这里的配置仅仅针对当前项目有效。每一个级别的配置都会覆盖上层的相同配置,所以.git/config里的配置会覆盖/etc/gitconfig中的同名变量。
在 Windows 系统上,Git 会找寻用户主目录下的 .gitconfig 文件。主目录即 $HOME 变量指定的目录,一般都是C:Documents and Settings$USER。此外,Git 还会尝试找寻/etc/gitconfig 文件,只不过看当初 Git 装在什么目录,就以此作为根目录来定位。
用户信息
第一个要配置的是你个人的用户名称和电子邮件地址。这两条配置很重要,每次 Git 提交时都会引用这两条信息,说明是谁提交了更新,所以会随更新内容一起被永久纳入历史记录:
$ git config --global user.name "John Doe"
$ git config --global user.email johndoe@example.com如果用了 --global 选项,那么更改的配置文件就是位于你用户主目录下的那个,以后你所有的项目都会默认使用这里配置的用户信息。如果要在某个特定的项目中使用其他名字或者电邮,只要去掉--global 选项重新配置即可,新的设定保存在当前项目的.git/config 文件里。
文本编辑器
接下来要设置的是默认使用的文本编辑器。Git 需要你输入一些额外消息的时候,会自动调用一个外部文本编辑器给你用。默认会使用操作系统指定的默认编辑器,一般可能会是 Vi 或者 Vim。如果你有其他偏好,比如 Emacs 的话,可以重新设置:
$ git config --global core.editor emacs差异分析工具
还有一个比较常用的是,在解决合并冲突时使用哪种差异分析工具。比如要改用 vimdiff 的话:
$ git config --global merge.tool vimdiffGit 可以理解 kdiff3,tkdiff,meld,xxdiff,emerge,vimdiff,gvimdiff,ecmerge,和 opendiff 等合并工具的输出信息。当然,你也可以指定使用自己开发的工具,具体怎么做可以参阅第七章。
查看配置信息
要检查已有的配置信息,可以使用 git config --list 命令:
$ git config --list
user.name=Scott Chacon
user.email=schacon@gmail.com
color.status=auto
color.branch=auto
color.interactive=auto
color.diff=auto
...有时候会看到重复的变量名,那就说明它们来自不同的配置文件(比如 /etc/gitconfig 和 ~/.gitconfig),不过最终 Git 实际采用的是最后一个。
也可以直接查阅某个环境变量的设定,只要把特定的名字跟在后面即可,像这样:
$ git config user.name
Scott Chacon1.6 获取帮助
想了解 Git 的各式工具该怎么用,可以阅读它们的使用帮助:
$ git help
比如,要学习 config 命令可以怎么用,运行:
$ git help config我们随时都可以浏览这些帮助信息而无需连网。不过,要是你觉得还不够,可以到 Frenode IRC 服务器(irc.freenode.net)上的 #git 或 #github 频道寻求他人帮助。这两个频道上总有着上百号人,大多都有着丰富的 git 知识,并且乐于助人。
1.7 小结
至此,你该对 Git 有了点基本认识,包括它和以前你使用的 CVCS 之间的差别。现在,在你的系统上应该已经装好了 Git,设置了自己的名字和电邮。接下来让我们继续学习 Git 的基础知识。
转载自:http://www.open-open.com/lib/view/open1328069609436.html