高性能网络通讯原理
前言
本来想对netty的源码进行学习和探究,但是在写netty之前许多底层的知识和原理性的东西理解清楚,那么对学习网络通讯框架的效果则会事半功倍。
本篇主要探讨高性能网络通讯框架的一些必要知识和底层操作系统相关的原理。在探讨如何做之前,我们先讨论下为什么要做。
随着互联网的高速发展,用户量呈指数形式递增,从原来的PC普及到现在的移动设备普及。用户量都是千万甚至亿为单位计算,尤其是实时通讯软件,在线实时互动的应用出现,在线用户数从原来的几十上百到后来的上万甚至上千万。单台服务的性能瓶颈和网络通讯瓶颈慢慢呈现。应用架构从单应用到应用数据分离,再到分布式集群高可用架构。单台服务的性能不足可以通过构建服务集群的方式水平扩展,应用性能瓶颈被很好的解决。但是横向扩展带来了直接的经济成本。
一个高性能的网络通讯框架从硬件设备到操作系统内核以及用户模式都需要精心设计。只要有任何地方有疏漏都会出现短板效应。
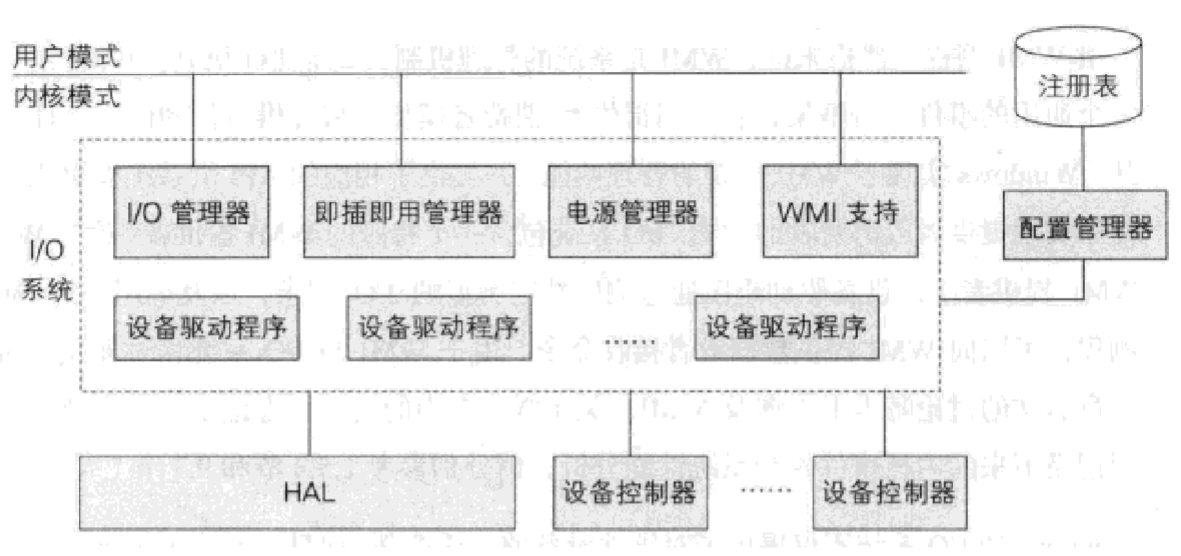
I/O访问
当我们在读取socket数据时,虽然我们在代码仅仅是调用了一个Read操作,但是实际操作系统层面做了许多事情。首先操作系统需要从用户模式转换为内核模式,处理器会通过网卡驱动对网卡控制器进行操作,网卡控制器则控制网卡。
处理器不会直接操控硬件。
为了提高CPU利用率,I/O访问方式也发生了很大变化。
- 早期的CPU直接控制外围设备,后来增加了控制器或I/O模块。处理器开始将I/O操作从外部设备接口分离出来。处理器通过向I/O模块发送命令执行I/O指令。然而当I/O操作完成时并不会通知处理器I/O,因此处理器需要定时检查I/O模块的状态,它会进行忙等待,因此效率并不高。
- 后来CPU支持了中断方式,处理器无需等待执行I/O操作,通过中断控制器产生中断信号通知I/O操作完成,大大的提高了处理器利用效率。这时的I/O操作使用特定的in/out(I/O端口)指令或直接读写内存的方式(内存映射I/O)。但是这些方式都需要处理器使用I/O寄存器逐个内存单元进行访问,效率并不高,在I/O操作时需要消耗的CPU时钟周期。
- 为了提高效率,后来增加了DMA控制器,它可以模拟处理起获得内存总线控制权,进行I/O的读写。当处理器将控制权交给DMA控制器之后,DMA处理器会先让I/O硬件设备将数据放到I/O硬件的缓冲区中,然后DMA控制器就可以开始传输数据了。在此过程中处理器无需消耗时钟周期。当DMA操作完成时,会通过中断操作通知处理器。
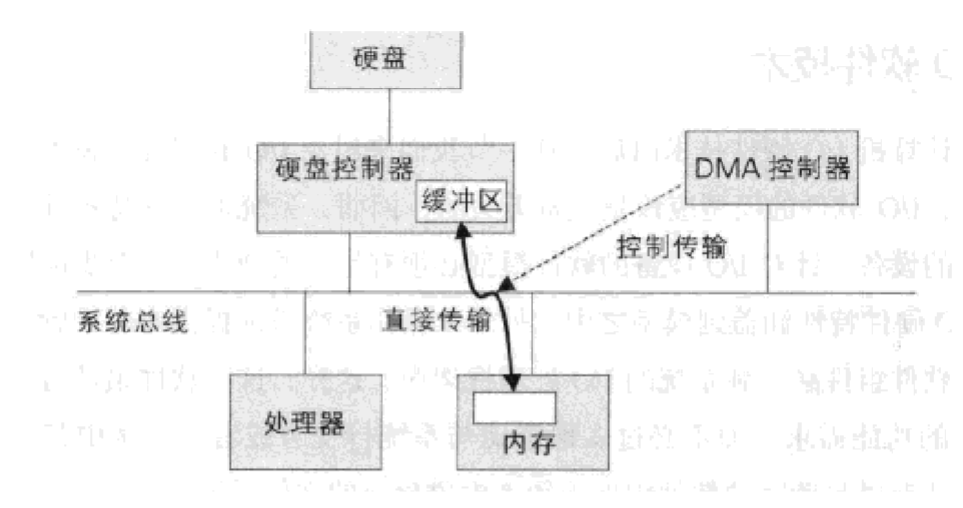
I/O访问的发展趋势是尽可能减少处理器干涉I/O操作,让CPU从I/O任务中解脱出来,让处理器可以去做其他事情,从而提高性能。
对于I/O访问感兴趣的同学可以看《操作系统精髓与设计原理(第5版)》第十一章I/O管理相关内容和《WINDOWS内核原理与实现》第六章I/O论述相关内容
I/O模型
在讨论I/O模型之前,首先引出一个叫做C10K的问题。在早期的I/O模型使用的是同步阻塞模型,当接收到一个新的TCP连接时,就需要分配一个线程。因此随着连接增加线程增多,频繁的内存复制,上下文切换带来的性能损耗导致性能不佳。因此如何使得单机网络并发连接数达到10K成为通讯开发者热门的讨论话题。
同步阻塞
前面提到,在最原始的I/O模型中,对文件设备数据的读写需要同步等待操作系统内核,即使文件设备并没有数据可读,线程也会被阻塞住,虽然阻塞时不占用CPU始终周期,但是若需要支持并发连接,则必须启用大量的线程,即每个连接一个线程。这样必不可少的会造成线程大量的上下文切换,随着并发量的增高,性能越来越差。
select模型/poll模型
为了解决同步阻塞带来线程过多导致的性能问题,同步非阻塞方案产生。通过一个线程不断的判断文件句柄数组是否有准备就绪的文件设备,这样就不需要每个线程同步等待,减少了大量线程,降低了线程上下文切换带来的性能损失,提高了线程利用率。这种方式也称为I/O多路复用技术。但是由于数组是有数组长度上限的(linux默认是1024),而且select模型需要对数组进行遍历,因此时间复杂度是(O_{(n)})因此当高并发量的时候,select模型性能会越来越差。
poll模型和select模型类似,但是它使用链表存储而非数组存储,解决了并发上限的限制,但是并没有解决select模型的高并发性能底下的根本问题。
epoll模型
在linux2.6支持了epoll模型,epoll模型解决了select模型的性能瓶颈问题。它通过注册回调事件的方式,当数据可读写时,将其加入到通过回调方式,将其加入到一个可读写事件的队列中。这样每次用户获取时不需要遍历所有句柄,时间复杂度降低为(O_{(1)})。因此epoll不会随着并发量的增加而性能降低。随着epoll模型的出现C10K的问题已经完美解决。
异步I/O模型
前面讲的几种模型都是同步I/O模型,异步I/O模型指的是发生数据读写时完全不同步阻塞等待,换句话来说就是数据从网卡传输到用户空间的过程时完全异步的,不用阻塞CPU。为了更详细的说明同步I/O与异步I/O的区别,接下来举一个实际例子。
当应用程序需要从网卡读取数据时,首先需要分配一个用户内存空间用来保存需要读取的数据。操作系统内核会调用网卡缓冲区读取数据到内核空间的缓冲区,然后再复制到用户空间。在这个过程中,同步阻塞I/O在数据读取到用户空间之前都会被阻塞,同步非阻塞I/O只知道数据已就绪,但是从内核空间缓冲区拷贝到用户空间时,线程依然会被阻塞。而异步I/O模型在接收到I/O完成通知时,数据已经传输到用户空间。因此整个I/O操作都是完全异步的,因此异步I/O模型的性能是最佳的。
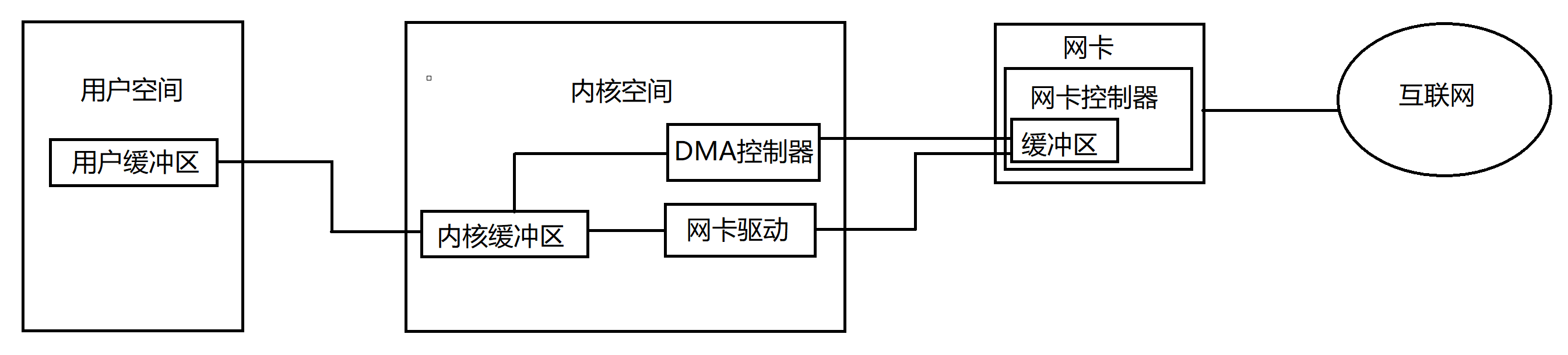
在我的另一篇文章《Windows内核原理-同步IO与异步IO》对windows操作系统I/O原理做了简要的叙述,感兴趣的同学可以看下。
I/O线程模型
从线程模型上常见的线程模型有Reactor模型和Proactor模型,无论是哪种线程模型都使用I/O多路复用技术,使用一个线程将I/O读写操作转变为读写事件,我们将这个线程称之为多路分离器。
对应上I/O模型,Reacor模型属于同步I/O模型,Proactor模型属于异步I/O模型。
Reactor模型
在Reactor中,需要先注册事件就绪事件,网卡接收到数据时,DMA将数据从网卡缓冲区传输到内核缓冲区时,就会通知多路分离器读事件就绪,此时我们需要从内核空间读取到用户空间。
同步I/O采用缓冲I/O的方式,首先内核会从申请一个内存空间用于存放输入或输出缓冲区,数据都会先缓存在该缓冲区。
Proactor模型
Proactor模型,需要先注册I/O完成事件,同时申请一片用户空间用于存储待接收的数据。调用读操作,当网卡接收到数据时,DMA将数据从网卡缓冲区直接传输到用户缓冲区,然后产生完成通知,读操作即完成。
异步I/O采用直接输入I/O或直接输出I/O,用户缓存地址会传递给设备驱动程序,数据会直接从用户缓冲区读取或直接写入用户缓冲区,相比缓冲I/O减少内存复制。
总结
本文通过I/O访问方式,I/O模型,线程模型三个方面解释了操作系统为实现高性能I/O做了哪些事情,通过提高CPU使用效率,减少内存复制是提高性能的关键点。
参考文档
- 新手入门:目前为止最透彻的的Netty高性能原理和框架架构解析
- 高性能网络编程(二):上一个10年,著名的C10K并发连接问题
- NIO的epoll空轮询bug
- 两种高效的服务器设计模型:Reactor和Proactor模型
- TCP的发送缓冲区和接收缓冲区
- IDE(电子集成驱动器)
- 《操作系统精髓与设计原理(第5版)》
- 《WINDOWS内核原理与实现》
微信扫一扫二维码关注订阅号杰哥技术分享
出处:https://www.cnblogs.com/Jack-Blog/p/11923838.html
作者:杰哥很忙
本文使用「CC BY 4.0」创作共享协议。欢迎转载,请在明显位置给出出处及链接。
