Task-2 文本预处理;语言模型;循环神经网络基础

3.1 文本预处理
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
- 读入文本
- 分词
- 建立字典,将每个词映射到一个唯一的索引(index)
- 将文本从词的序列转换为索引的序列,方便输入模型
读入文本
我们用一部英文小说,即H. G. Well的Time Machine,作为示例,展示文本预处理的具体过程。
import collections
import re
def read_time_machine():
with open('/home/kesci/input/timemachine7163/timemachine.txt', 'r') as f:
lines = [re.sub('[^a-z]+', ' ', line.strip().lower()) for line in f]
return lines
lines = read_time_machine()
print('# sentences %d' % len(lines))
sentences 3221
分词
我们对每个句子进行分词,也就是将一个句子划分成若干个词(token),转换为一个词的序列。
def tokenize(sentences, token='word'):
"""Split sentences into word or char tokens"""
if token == 'word':
return [sentence.split(' ') for sentence in sentences]
elif token == 'char':
return [list(sentence) for sentence in sentences]
else:
print('ERROR: unkown token type '+token)
tokens = tokenize(lines)
tokens[0:2]
[['the', 'time', 'machine', 'by', 'h', 'g', 'wells', ''], ['']]
建立字典
为了方便模型处理,我们需要将字符串转换为数字。因此我们需要先构建一个字典(vocabulary),将每个词映射到一个唯一的索引编号。
class Vocab(object):
def __init__(self, tokens, min_freq=0, use_special_tokens=False):
counter = count_corpus(tokens) # :
self.token_freqs = list(counter.items())
self.idx_to_token = []
if use_special_tokens:
# padding, begin of sentence, end of sentence, unknown
self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3)
self.idx_to_token += ['', '', '', '']
else:
self.unk = 0
self.idx_to_token += ['']
self.idx_to_token += [token for token, freq in self.token_freqs
if freq >= min_freq and token not in self.idx_to_token]
self.token_to_idx = dict()
for idx, token in enumerate(self.idx_to_token):
self.token_to_idx[token] = idx
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
def count_corpus(sentences):
tokens = [tk for st in sentences for tk in st]
return collections.Counter(tokens) # 返回一个字典,记录每个词的出现次数
我们看一个例子,这里我们尝试用Time Machine作为语料构建字典
vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[0:10])
[('', 0), ('the', 1), ('time', 2), ('machine', 3), ('by', 4), ('h', 5), ('g', 6), ('wells', 7), ('i', 8), ('traveller', 9)]
将词转为索引
使用字典,我们可以将原文本中的句子从单词序列转换为索引序列
for i in range(8, 10):
print('words:', tokens[i])
print('indices:', vocab[tokens[i]])
words: ['the', 'time', 'traveller', 'for', 'so', 'it', 'will', 'be', 'convenient', 'to', 'speak', 'of', 'him', '']
indices: [1, 2, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 0]
words: ['was', 'expounding', 'a', 'recondite', 'matter', 'to', 'us', 'his', 'grey', 'eyes', 'shone', 'and']
indices: [20, 21, 22, 23, 24, 16, 25, 26, 27, 28, 29, 30]
用现有工具进行分词
我们前面介绍的分词方式非常简单,它至少有以下几个缺点:
标点符号通常可以提供语义信息,但是我们的方法直接将其丢弃了
类似“shouldn’t", “doesn’t"这样的词会被错误地处理
类似"Mr.”, "Dr."这样的词会被错误地处理
我们可以通过引入更复杂的规则来解决这些问题,但是事实上,有一些现有的工具可以很好地进行分词,我们在这里简单介绍其中的两个:spaCy和NLTK。
下面是一个简单的例子:
text = "Mr. Chen doesn't agree with my suggestion."
spaCy:
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(text)
print([token.text for token in doc])
['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.']
NLTK:
from nltk.tokenize import word_tokenize
from nltk import data
data.path.append('/home/kesci/input/nltk_data3784/nltk_data')
print(word_tokenize(text))
['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.']
3.2 语言模型
本节将介绍如何预处理一个语言模型数据集,并将其转换成字符级循环神经网络所需要的输入格式。为此,我们收集了周杰伦从第一张专辑《Jay》到第十张专辑《跨时代》中的歌词,并在后面几节里应用循环神经网络来训练一个语言模型。当模型训练好后,我们就可以用这个模型来创作歌词。
读取数据集
首先读取这个数据集,看看前40个字符是什么样的。
import torch
import random
import zipfile
with zipfile.ZipFile('../../data/jaychou_lyrics.txt.zip') as zin:
with zin.open('jaychou_lyrics.txt') as f:
corpus_chars = f.read().decode('utf-8')
corpus_chars[:40]
输出:
'想要有直升机
想要和你飞到宇宙去
想要和你融化在一起
融化在宇宙里
我每天每天每'
这个数据集有6万多个字符。为了打印方便,我们把换行符替换成空格,然后仅使用前1万个字符来训练模型。
corpus_chars = corpus_chars.replace('
', ' ').replace('
', ' ')
corpus_chars = corpus_chars[0:10000]
建立字符索引
我们将每个字符映射成一个从0开始的连续整数,又称索引,来方便之后的数据处理。为了得到索引,我们将数据集里所有不同字符取出来,然后将其逐一映射到索引来构造词典。接着,打印vocab_size,即词典中不同字符的个数,又称词典大小。
idx_to_char = list(set(corpus_chars))
char_to_idx = dict([(char, i) for i, char in enumerate(idx_to_char)])
vocab_size = len(char_to_idx)
vocab_size # 1027
之后,将训练数据集中每个字符转化为索引,并打印前20个字符及其对应的索引。
corpus_indices = [char_to_idx[char] for char in corpus_chars]
sample = corpus_indices[:20]
print('chars:', ''.join([idx_to_char[idx] for idx in sample]))
print('indices:', sample)
输出:
chars: 想要有直升机 想要和你飞到宇宙去 想要和
indices: [250, 164, 576, 421, 674, 653, 357, 250, 164, 850, 217, 910, 1012, 261, 275, 366, 357, 250, 164, 850]
我们将以上代码封装在d2lzh_pytorch包里的load_data_jay_lyrics函数中,以方便后面章节调用。调用该函数后会依次得到corpus_indices、char_to_idx、idx_to_char和vocab_size这4个变量。
时序数据的采样
在训练中我们需要每次随机读取小批量样本和标签。与之前章节的实验数据不同的是,时序数据的一个样本通常包含连续的字符。假设时间步数为5,样本序列为5个字符,即“想”“要”“有”“直”“升”。该样本的标签序列为这些字符分别在训练集中的下一个字符,即“要”“有”“直”“升”“机”。我们有两种方式对时序数据进行采样,分别是随机采样和相邻采样。
随机采样
下面的代码每次从数据里随机采样一个小批量。其中批量大小batch_size指每个小批量的样本数,num_steps为每个样本所包含的时间步数。
在随机采样中,每个样本是原始序列上任意截取的一段序列。相邻的两个随机小批量在原始序列上的位置不一定相毗邻。因此,我们无法用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态。在训练模型时,每次随机采样前都需要重新初始化隐藏状态。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def data_iter_random(corpus_indices, batch_size, num_steps, device=None):
# 减1是因为输出的索引x是相应输入的索引y加1
num_examples = (len(corpus_indices) - 1) // num_steps
epoch_size = num_examples // batch_size
example_indices = list(range(num_examples))
random.shuffle(example_indices)
# 返回从pos开始的长为num_steps的序列
def _data(pos):
return corpus_indices[pos: pos + num_steps]
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
for i in range(epoch_size):
# 每次读取batch_size个随机样本
i = i * batch_size
batch_indices = example_indices[i: i + batch_size]
X = [_data(j * num_steps) for j in batch_indices]
Y = [_data(j * num_steps + 1) for j in batch_indices]
yield torch.tensor(X, dtype=torch.float32, device=device), torch.tensor(Y, dtype=torch.float32, device=device)
让我们输入一个从0到29的连续整数的人工序列。设批量大小和时间步数分别为2和6。打印随机采样每次读取的小批量样本的输入X和标签Y。可见,相邻的两个随机小批量在原始序列上的位置不一定相毗邻。
my_seq = list(range(30))
for X, Y in data_iter_random(my_seq, batch_size=2, num_steps=6):
print('X: ', X, '
Y:', Y, '
')
输出:
X: tensor([[18., 19., 20., 21., 22., 23.],
[12., 13., 14., 15., 16., 17.]])
Y: tensor([[19., 20., 21., 22., 23., 24.],
[13., 14., 15., 16., 17., 18.]])
X: tensor([[ 0., 1., 2., 3., 4., 5.],
[ 6., 7., 8., 9., 10., 11.]])
Y: tensor([[ 1., 2., 3., 4., 5., 6.],
[ 7., 8., 9., 10., 11., 12.]])
相邻采样
除对原始序列做随机采样之外,我们还可以令相邻的两个随机小批量在原始序列上的位置相毗邻。这时候,我们就可以用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态,从而使下一个小批量的输出也取决于当前小批量的输入,并如此循环下去。这对实现循环神经网络造成了两方面影响:一方面,
在训练模型时,我们只需在每一个迭代周期开始时初始化隐藏状态;另一方面,当多个相邻小批量通过传递隐藏状态串联起来时,模型参数的梯度计算将依赖所有串联起来的小批量序列。同一迭代周期中,随着迭代次数的增加,梯度的计算开销会越来越大。
为了使模型参数的梯度计算只依赖一次迭代读取的小批量序列,我们可以在每次读取小批量前将隐藏状态从计算图中分离出来。我们将在下一节(循环神经网络的从零开始实现)的实现中了解这种处理方式。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def data_iter_consecutive(corpus_indices, batch_size, num_steps, device=None):
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
corpus_indices = torch.tensor(corpus_indices, dtype=torch.float32, device=device)
data_len = len(corpus_indices)
batch_len = data_len // batch_size
indices = corpus_indices[0: batch_size*batch_len].view(batch_size, batch_len)
epoch_size = (batch_len - 1) // num_steps
for i in range(epoch_size):
i = i * num_steps
X = indices[:, i: i + num_steps]
Y = indices[:, i + 1: i + num_steps + 1]
yield X, Y
同样的设置下,打印相邻采样每次读取的小批量样本的输入X和标签Y。相邻的两个随机小批量在原始序列上的位置相毗邻。
for X, Y in data_iter_consecutive(my_seq, batch_size=2, num_steps=6):
print('X: ', X, '
Y:', Y, '
')
输出:
X: tensor([[ 0., 1., 2., 3., 4., 5.],
[15., 16., 17., 18., 19., 20.]])
Y: tensor([[ 1., 2., 3., 4., 5., 6.],
[16., 17., 18., 19., 20., 21.]])
X: tensor([[ 6., 7., 8., 9., 10., 11.],
[21., 22., 23., 24., 25., 26.]])
Y: tensor([[ 7., 8., 9., 10., 11., 12.],
[22., 23., 24., 25., 26., 27.]])
3.3.1 循环神经网络基础
本节将介绍循环神经网络。它并非刚性地记忆所有固定长度的序列,而是通过隐藏状态来存储之前时间步的信息。首先我们回忆一下前面介绍过的多层感知机,然后描述如何添加隐藏状态来将它变成循环神经网络。
不含隐藏状态的神经网络
让我们考虑一个含单隐藏层的多层感知机。给定样本数为、输入个数(特征数或特征向量维度)为的小批量数据样本。设隐藏层的激活函数为,那么隐藏层的输出计算为
其中隐藏层权重参数,隐藏层偏差参数 ,为隐藏单元个数。上式相加的两项形状不同,因此将按照广播机制相加。把隐藏变量作为输出层的输入,且设输出个数为(如分类问题中的类别数),输出层的输出为
其中输出变量, 输出层权重参数, 输出层偏差参数。如果是分类问题,我们可以使用来计算输出类别的概率分布。
含隐藏状态的循环神经网络
现在我们考虑输入数据存在时间相关性的情况。假设是序列中时间步的小批量输入,是该时间步的隐藏变量。与多层感知机不同的是,这里我们保存上一时间步的隐藏变量,并引入一个新的权重参数,该参数用来描述在当前时间步如何使用上一时间步的隐藏变量。具体来说,时间步的隐藏变量的计算由当前时间步的输入和上一时间步的隐藏变量共同决定:
与多层感知机相比,我们在这里添加了一项。由上式中相邻时间步的隐藏变量和之间的关系可知,这里的隐藏变量能够捕捉截至当前时间步的序列的历史信息,就像是神经网络当前时间步的状态或记忆一样。因此,该隐藏变量也称为隐藏状态。由于隐藏状态在当前时间步的定义使用了上一时间步的隐藏状态,上式的计算是循环的。使用循环计算的网络即循环神经网络(recurrent neural network)。
循环神经网络有很多种不同的构造方法。含上式所定义的隐藏状态的循环神经网络是极为常见的一种。若无特别说明,本章中的循环神经网络均基于上式中隐藏状态的循环计算。在时间步,输出层的输出和多层感知机中的计算类似:
循环神经网络的参数包括隐藏层的权重、和偏差 ,以及输出层的权重和偏差。值得一提的是,即便在不同时间步,循环神经网络也始终使用这些模型参数。因此,循环神经网络模型参数的数量不随时间步的增加而增长。
图6.1展示了循环神经网络在3个相邻时间步的计算逻辑。在时间步,隐藏状态的计算可以看成是将输入和前一时间步隐藏状态连结后输入一个激活函数为的全连接层。该全连接层的输出就是当前时间步的隐藏状态,且模型参数为与的连结,偏差为。当前时间步的隐藏状态将参与下一个时间步的隐藏状态的计算,并输入到当前时间步的全连接输出层。
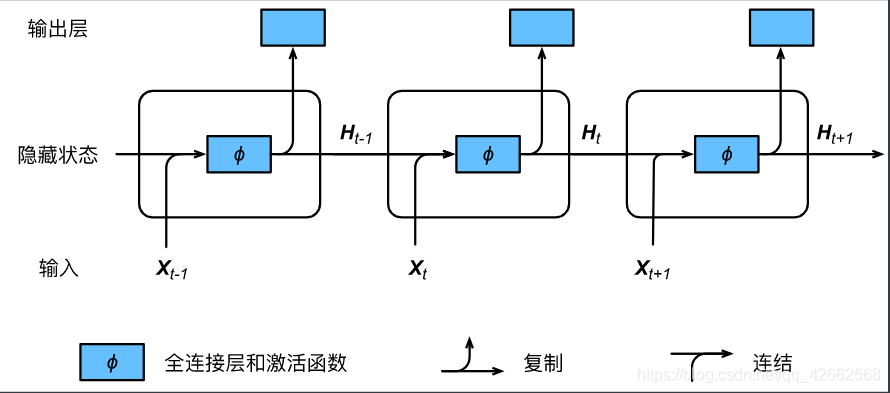 图1 含隐藏状态的循环神经网络
图1 含隐藏状态的循环神经网络
我们刚刚提到,隐藏状态中的计算等价于与连结后的矩阵乘以与连结后的矩阵。接下来,我们用一个具体的例子来验证这一点。首先,我们构造矩阵X、W_xh、H和W_hh,它们的形状分别为(3, 1)、(1, 4)、(3, 4)和(4, 4)。将X与W_xh、H与W_hh分别相乘,再把两个乘法运算的结果相加,得到形状为(3, 4)的矩阵。
import torch
X, W_xh = torch.randn(3, 1), torch.randn(1, 4)
H, W_hh = torch.randn(3, 4), torch.randn(4, 4)
torch.matmul(X, W_xh) + torch.matmul(H, W_hh)
输出:
tensor([[ 5.2633, -3.2288, 0.6037, -1.3321],
[ 9.4012, -6.7830, 1.0630, -0.1809],
[ 7.0355, -2.2361, 0.7469, -3.4667]])
将矩阵X和H按列(维度1)连结,连结后的矩阵形状为(3, 5)。可见,连结后矩阵在维度1的长度为矩阵X和H在维度1的长度之和()。然后,将矩阵W_xh和W_hh按行(维度0)连结,连结后的矩阵形状为(5, 4)。最后将两个连结后的矩阵相乘,得到与上面代码输出相同的形状为(3, 4)的矩阵。
torch.matmul(torch.cat((X, H), dim=1), torch.cat((W_xh, W_hh), dim=0))
输出:
tensor([[ 5.2633, -3.2288, 0.6037, -1.3321],
[ 9.4012, -6.7830, 1.0630, -0.1809],
[ 7.0355, -2.2361, 0.7469, -3.4667]])
应用:基于字符级循环神经网络的语言模型
最后我们介绍如何应用循环神经网络来构建一个语言模型。设小批量中样本数为1,文本序列为“想”“要”“有”“直”“升”“机”。图6.2演示了如何使用循环神经网络基于当前和过去的字符来预测下一个字符。在训练时,我们对每个时间步的输出层输出使用softmax运算,然后使用交叉熵损失函数来计算它与标签的误差。在图6.2中,由于隐藏层中隐藏状态的循环计算,时间步3的输出取决于文本序列“想”“要”“有”。 由于训练数据中该序列的下一个词为“直”,时间步3的损失将取决于该时间步基于序列“想”“要”“有”生成下一个词的概率分布与该时间步的标签“直”。
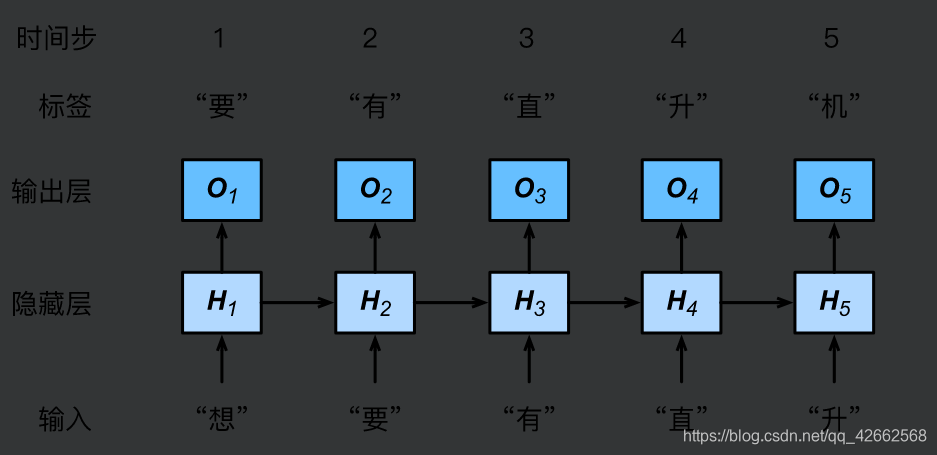
图2 基于字符级循环神经网络的语言模型。
因为每个输入词是一个字符,因此这个模型被称为字符级循环神经网络(character-level recurrent neural network)。因为不同字符的个数远小于不同词的个数(对于英文尤其如此),所以字符级循环神经网络的计算通常更加简单。
3.3.2 循环神经网络的从零开始实现
在本节中,我们将从零开始实现一个基于字符级循环神经网络的语言模型,并在周杰伦专辑歌词数据集上训练一个模型来进行歌词创作。首先,我们读取周杰伦专辑歌词数据集:
import time
import math
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
one-hot向量
为了将词表示成向量输入到神经网络,一个简单的办法是使用one-hot向量。假设词典中不同字符的数量为(即词典大小vocab_size),每个字符已经同一个从0到的连续整数值索引一一对应。如果一个字符的索引是整数, 那么我们创建一个全0的长为的向量,并将其位置为的元素设成1。该向量就是对原字符的one-hot向量。下面分别展示了索引为0和2的one-hot向量,向量长度等于词典大小。
pytorch没有自带one-hot函数(新版好像有了),下面自己实现一个
def one_hot(x, n_class, dtype=torch.float32):
# X shape: (batch), output shape: (batch, n_class)
x = x.long()
res = torch.zeros(x.shape[0], n_class, dtype=dtype, device=x.device)
res.scatter_(1, x.view(-1, 1), 1)
return res
x = torch.tensor([0, 2])
one_hot(x, vocab_size)
我们每次采样的小批量的形状是(批量大小, 时间步数)。下面的函数将这样的小批量变换成数个可以输入进网络的形状为(批量大小, 词典大小)的矩阵,矩阵个数等于时间步数。也就是说,时间步的输入为,其中为批量大小,为输入个数,即one-hot向量长度(词典大小)。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def to_onehot(X, n_class):
# X shape: (batch, seq_len), output: seq_len elements of (batch, n_class)
return [one_hot(X[:, i], n_class) for i in range(X.shape[1])]
X = torch.arange(10).view(2, 5)
inputs = to_onehot(X, vocab_size)
print(len(inputs), inputs[0].shape)
输出:
5 torch.Size([2, 1027])
初始化模型参数
接下来,我们初始化模型参数。隐藏单元个数 num_hiddens是一个超参数。
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
print('will use', device)
def get_params():
def _one(shape):
ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32)
return torch.nn.Parameter(ts, requires_grad=True)
# 隐藏层参数
W_xh = _one((num_inputs, num_hiddens))
W_hh = _one((num_hiddens, num_hiddens))
b_h = torch.nn.Parameter(torch.zeros(num_hiddens, device=device, requires_grad=True))
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, requires_grad=True))
return nn.ParameterList([W_xh, W_hh, b_h, W_hq, b_q])
定义模型
我们根据循环神经网络的计算表达式实现该模型。首先定义init_rnn_state函数来返回初始化的隐藏状态。它返回由一个形状为(批量大小, 隐藏单元个数)的值为0的NDArray组成的元组。使用元组是为了更便于处理隐藏状态含有多个NDArray的情况。
def init_rnn_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
下面的rnn函数定义了在一个时间步里如何计算隐藏状态和输出。这里的激活函数使用了tanh函数。3.8节(多层感知机)中介绍过,当元素在实数域上均匀分布时,tanh函数值的均值为0。
def rnn(inputs, state, params):
# inputs和outputs皆为num_steps个形状为(batch_size, vocab_size)的矩阵
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
H = torch.tanh(torch.matmul(X, W_xh) + torch.matmul(H, W_hh) + b_h)
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H,)
做个简单的测试来观察输出结果的个数(时间步数),以及第一个时间步的输出层输出的形状和隐藏状态的形状。
state = init_rnn_state(X.shape[0], num_hiddens, device)
inputs = to_onehot(X.to(device), vocab_size)
params = get_params()
outputs, state_new = rnn(inputs, state, params)
print(len(outputs), outputs[0].shape, state_new[0].shape)
输出:
5 torch.Size([2, 1027]) torch.Size([2, 256])
定义预测函数
以下函数基于前缀prefix(含有数个字符的字符串)来预测接下来的num_chars个字符。这个函数稍显复杂,其中我们将循环神经单元rnn设置成了函数参数,这样在后面小节介绍其他循环神经网络时能重复使用这个函数。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def predict_rnn(prefix, num_chars, rnn, params, init_rnn_state,
num_hiddens, vocab_size, device, idx_to_char, char_to_idx):
state = init_rnn_state(1, num_hiddens, device)
output = [char_to_idx[prefix[0]]]
for t in range(num_chars + len(prefix) - 1):
# 将上一时间步的输出作为当前时间步的输入
X = to_onehot(torch.tensor([[output[-1]]], device=device), vocab_size)
# 计算输出和更新隐藏状态
(Y, state) = rnn(X, state, params)
# 下一个时间步的输入是prefix里的字符或者当前的最佳预测字符
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t + 1]])
else:
output.append(int(Y[0].argmax(dim=1).item()))
return ''.join([idx_to_char[i] for i in output])
我们先测试一下predict_rnn函数。我们将根据前缀“分开”创作长度为10个字符(不考虑前缀长度)的一段歌词。因为模型参数为随机值,所以预测结果也是随机的。
predict_rnn('分开', 10, rnn, params, init_rnn_state, num_hiddens, vocab_size,
device, idx_to_char, char_to_idx)
输出:
'分开西圈绪升王凝瓜必客映'
裁剪梯度
循环神经网络中较容易出现梯度衰减或梯度爆炸。我们会在6.6节(通过时间反向传播)中解释原因。为了应对梯度爆炸,我们可以裁剪梯度(clip gradient)。假设我们把所有模型参数梯度的元素拼接成一个向量 ,并设裁剪的阈值是。裁剪后的梯度
的范数不超过。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def grad_clipping(params, theta, device):
norm = torch.tensor([0.0], device=device)
for param in params:
norm += (param.grad.data ** 2).sum()
norm = norm.sqrt().item()
if norm > theta:
for param in params:
param.grad.data *= (theta / norm)
困惑度
我们通常使用困惑度(perplexity)来评价语言模型的好坏。回忆一下3.4节(softmax回归)中交叉熵损失函数的定义。困惑度是对交叉熵损失函数做指数运算后得到的值。特别地,
- 最佳情况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
- 最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
- 基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数。
显然,任何一个有效模型的困惑度必须小于类别个数。在本例中,困惑度必须小于词典大小vocab_size。
定义模型训练函数
跟之前章节的模型训练函数相比,这里的模型训练函数有以下几点不同:
- 使用困惑度评价模型。
- 在迭代模型参数前裁剪梯度。
- 对时序数据采用不同采样方法将导致隐藏状态初始化的不同。相关讨论可参考6.3节(语言模型数据集(周杰伦专辑歌词))。
另外,考虑到后面将介绍的其他循环神经网络,为了更通用,这里的函数实现更长一些。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, is_random_iter, num_epochs, num_steps,
lr, clipping_theta, batch_size, pred_period,
pred_len, prefixes):
if is_random_iter:
data_iter_fn = d2l.data_iter_random
else:
data_iter_fn = d2l.data_iter_consecutive
params = get_params()
loss = nn.CrossEntropyLoss()
for epoch in range(num_epochs):
if not is_random_iter: # 如使用相邻采样,在epoch开始时初始化隐藏状态
state = init_rnn_state(batch_size, num_hiddens, device)
l_sum, n, start = 0.0, 0, time.time()
data_iter = data_iter_fn(corpus_indices, batch_size, num_steps, device)
for X, Y in data_iter:
if is_random_iter: # 如使用随机采样,在每个小批量更新前初始化隐藏状态
state = init_rnn_state(batch_size, num_hiddens, device)
else:
# 否则需要使用detach函数从计算图分离隐藏状态, 这是为了
# 使模型参数的梯度计算只依赖一次迭代读取的小批量序列(防止梯度计算开销太大)
for s in state:
s.detach_()
inputs = to_onehot(X, vocab_size)
# outputs有num_steps个形状为(batch_size, vocab_size)的矩阵
(outputs, state) = rnn(inputs, state, params)
# 拼接之后形状为(num_steps * batch_size, vocab_size)
outputs = torch.cat(outputs, dim=0)
# Y的形状是(batch_size, num_steps),转置后再变成长度为
# batch * num_steps 的向量,这样跟输出的行一一对应
y = torch.transpose(Y, 0, 1).contiguous().view(-1)
# 使用交叉熵损失计算平均分类误差
l = loss(outputs, y.long())
# 梯度清0
if params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
grad_clipping(params, clipping_theta, device) # 裁剪梯度
d2l.sgd(params, lr, 1) # 因为误差已经取过均值,梯度不用再做平均
l_sum += l.item() * y.shape[0]
n += y.shape[0]
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (
epoch + 1, math.exp(l_sum / n), time.time() - start))
for prefix in prefixes:
print(' -', predict_rnn(prefix, pred_len, rnn, params, init_rnn_state,
num_hiddens, vocab_size, device, idx_to_char, char_to_idx))
训练模型并创作歌词
现在我们可以训练模型了。首先,设置模型超参数。我们将根据前缀“分开”和“不分开”分别创作长度为50个字符(不考虑前缀长度)的一段歌词。我们每过50个迭代周期便根据当前训练的模型创作一段歌词。
num_epochs, num_steps, batch_size, lr, clipping_theta = 250, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
下面采用随机采样训练模型并创作歌词。
train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, True, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
输出:
epoch 50, perplexity 70.039647, time 0.11 sec
- 分开 我不要再想 我不能 想你的让我 我的可 你怎么 一颗四 一颗四 我不要 一颗两 一颗四 一颗四 我
- 不分开 我不要再 你你的外 在人 别你的让我 狂的可 语人两 我不要 一颗两 一颗四 一颗四 我不要 一
epoch 100, perplexity 9.726828, time 0.12 sec
- 分开 一直的美栈人 一起看 我不要好生活 你知不觉 我已好好生活 我知道好生活 后知不觉 我跟了这生活
- 不分开堡 我不要再想 我不 我不 我不要再想你 不知不觉 你已经离开我 不知不觉 我跟了好生活 我知道好生
epoch 150, perplexity 2.864874, time 0.11 sec
- 分开 一只会停留 有不它元羞 这蝪什么奇怪的事都有 包括像猫的狗 印地安老斑鸠 平常话不多 除非是乌鸦抢
- 不分开扫 我不你再想 我不能再想 我不 我不 我不要再想你 不知不觉 你已经离开我 不知不觉 我跟了这节奏
epoch 200, perplexity 1.597790, time 0.11 sec
- 分开 有杰伦 干 载颗拳满的让空美空主 相爱还有个人 再狠狠忘记 你爱过我的证 有晶莹的手滴 让说些人
- 不分开扫 我叫你爸 你打我妈 这样对吗干嘛这样 何必让它牵鼻子走 瞎 说底牵打我妈要 难道球耳 快使用双截
epoch 250, perplexity 1.303903, time 0.12 sec
- 分开 有杰人开留 仙唱它怕羞 蜥蝪横著走 这里什么奇怪的事都有 包括像猫的狗 印地安老斑鸠 平常话不多
- 不分开简 我不能再想 我不 我不 我不能 爱情走的太快就像龙卷风 不能承受我已无处可躲 我不要再想 我不能
接下来采用相邻采样训练模型并创作歌词。
train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
输出:
epoch 50, perplexity 59.514416, time 0.11 sec
- 分开 我想要这 我想了空 我想了空 我想了空 我想了空 我想了空 我想了空 我想了空 我想了空 我想了空
- 不分开 我不要这 全使了双 我想了这 我想了空 我想了空 我想了空 我想了空 我想了空 我想了空 我想了空
epoch 100, perplexity 6.801417, time 0.11 sec
- 分开 我说的这样笑 想你都 不着我 我想就这样牵 你你的回不笑多难的 它在云实 有一条事 全你了空
- 不分开觉 你已经离开我 不知不觉 我跟好这节活 我该好好生活 不知不觉 你跟了离开我 不知不觉 我跟好这节
epoch 150, perplexity 2.063730, time 0.16 sec
- 分开 我有到这样牵着你的手不放开 爱可不可以简简单单没有伤 古有你烦 我有多烦恼向 你知带悄 回我的外
- 不分开觉 你已经很个我 不知不觉 我跟了这节奏 后知后觉 又过了一个秋 后哼哈兮 快使用双截棍 哼哼哈兮
epoch 200, perplexity 1.300031, time 0.11 sec
- 分开 我想要这样牵着你的手不放开 爱能不能够永远单甜没有伤害 你 靠着我的肩膀 你 在我胸口睡著 像这样
- 不分开觉 你已经离开我 不知不觉 我跟了这节奏 后知后觉 又过了一个秋 后知后觉 我该好好生活 我该好好生
epoch 250, perplexity 1.164455, time 0.11 sec
- 分开 我有一这样布 对你依依不舍 连隔壁邻居都猜到我现在的感受 河边的风 在吹着头发飘动 牵着你的手 一
- 不分开觉 你已经离开我 不知不觉 我跟了这节奏 后知后觉 又过了一个秋 后知后觉 我该好好生活 我该好好生
3.3.3 循环神经网络的pytorch实现
本节将使用PyTorch来更简洁地实现基于循环神经网络的语言模型。首先,我们读取周杰伦专辑歌词数据集。
import time
import math
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
定义模型
PyTorch中的nn模块提供了循环神经网络的实现。下面构造一个含单隐藏层、隐藏单元个数为256的循环神经网络层rnn_layer。
num_hiddens = 256
# rnn_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens) # 已测试
rnn_layer = nn.RNN(input_size=vocab_size, hidden_size=num_hiddens)
与上一节中实现的循环神经网络不同,这里rnn_layer的输入形状为(时间步数, 批量大小, 输入个数)。其中输入个数即one-hot向量长度(词典大小)。此外,rnn_layer作为nn.RNN实例,在前向计算后会分别返回输出和隐藏状态h,其中输出指的是隐藏层在各个时间步上计算并输出的隐藏状态,它们通常作为后续输出层的输入。需要强调的是,该“输出”本身并不涉及输出层计算,形状为(时间步数, 批量大小, 隐藏单元个数)。而nn.RNN实例在前向计算返回的隐藏状态指的是隐藏层在最后时间步的隐藏状态:当隐藏层有多层时,每一层的隐藏状态都会记录在该变量中;对于像长短期记忆(LSTM),隐藏状态是一个元组(h, c),即hidden state和cell state。我们会在本章的后面介绍长短期记忆和深度循环神经网络。关于循环神经网络(以LSTM为例)的输出,可以参考下图(图片来源)。
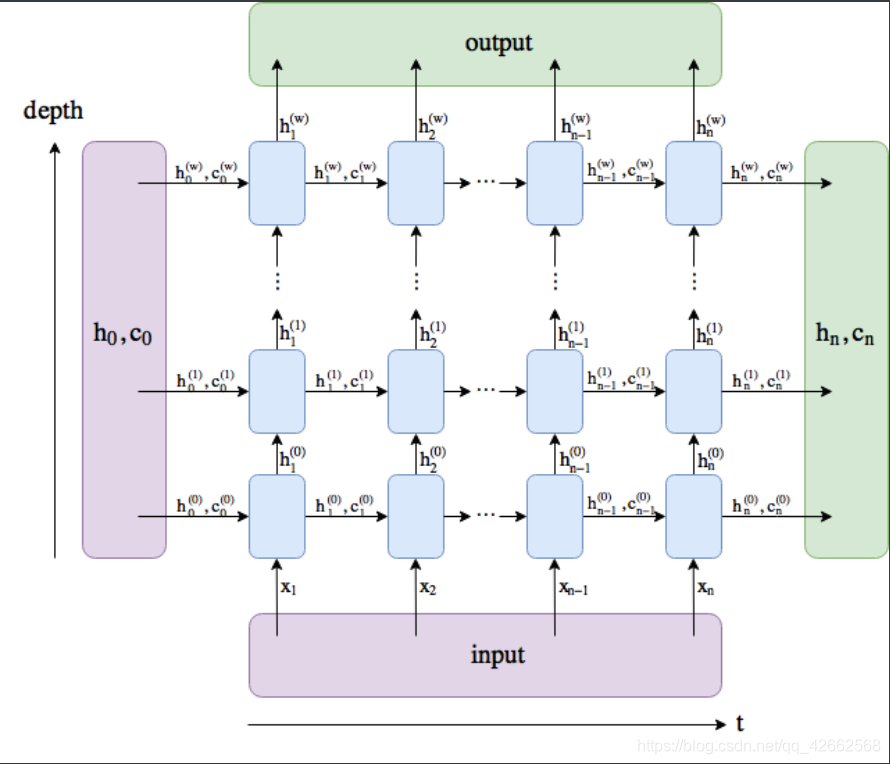 循环神经网络(以LSTM为例)的输出
循环神经网络(以LSTM为例)的输出
来看看我们的例子,输出形状为(时间步数, 批量大小, 隐藏单元个数),隐藏状态h的形状为(层数, 批量大小, 隐藏单元个数)。
num_steps = 35
batch_size = 2
state = None
X = torch.rand(num_steps, batch_size, vocab_size)
Y, state_new = rnn_layer(X, state)
print(Y.shape, len(state_new), state_new[0].shape)
输出:
torch.Size([35, 2, 256]) 1 torch.Size([2, 256])
如果
rnn_layer是nn.LSTM实例,那么上面的输出是什么?
接下来我们继承Module类来定义一个完整的循环神经网络。它首先将输入数据使用one-hot向量表示后输入到rnn_layer中,然后使用全连接输出层得到输出。输出个数等于词典大小vocab_size。
# 本类已保存在d2lzh_pytorch包中方便以后使用
class RNNModel(nn.Module):
def __init__(self, rnn_layer, vocab_size):
super(RNNModel, self).__init__()
self.rnn = rnn_layer
self.hidden_size = rnn_layer.hidden_size * (2 if rnn_layer.bidirectional else 1)
self.vocab_size = vocab_size
self.dense = nn.Linear(self.hidden_size, vocab_size)
self.state = None
def forward(self, inputs, state): # inputs: (batch, seq_len)
# 获取one-hot向量表示
X = d2l.to_onehot(inputs, self.vocab_size) # X是个list
Y, self.state = self.rnn(torch.stack(X), state)
# 全连接层会首先将Y的形状变成(num_steps * batch_size, num_hiddens),它的输出
# 形状为(num_steps * batch_size, vocab_size)
output = self.dense(Y.view(-1, Y.shape[-1]))
return output, self.state
训练模型
同上一节一样,下面定义一个预测函数。这里的实现区别在于前向计算和初始化隐藏状态的函数接口。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def predict_rnn_pytorch(prefix, num_chars, model, vocab_size, device, idx_to_char,
char_to_idx):
state = None
output = [char_to_idx[prefix[0]]] # output会记录prefix加上输出
for t in range(num_chars + len(prefix) - 1):
X = torch.tensor([output[-1]], device=device).view(1, 1)
if state is not None:
if isinstance(state, tuple): # LSTM, state:(h, c)
state = (state[0].to(device), state[1].to(device))
else:
state = state.to(device)
(Y, state) = model(X, state)
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t + 1]])
else:
output.append(int(Y.argmax(dim=1).item()))
return ''.join([idx_to_char[i] for i in output])
让我们使用权重为随机值的模型来预测一次。
model = RNNModel(rnn_layer, vocab_size).to(device)
predict_rnn_pytorch('分开', 10, model, vocab_size, device, idx_to_char, char_to_idx)
输出:
'分开戏想暖迎凉想征凉征征'
接下来实现训练函数。算法同上一节的一样,但这里只使用了相邻采样来读取数据。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes):
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
model.to(device)
state = None
for epoch in range(num_epochs):
l_sum, n, start = 0.0, 0, time.time()
data_iter = d2l.data_iter_consecutive(corpus_indices, batch_size, num_steps, device) # 相邻采样
for X, Y in data_iter:
if state is not None:
# 使用detach函数从计算图分离隐藏状态, 这是为了
# 使模型参数的梯度计算只依赖一次迭代读取的小批量序列(防止梯度计算开销太大)
if isinstance (state, tuple): # LSTM, state:(h, c)
state = (state[0].detach(), state[1].detach())
else:
state = state.detach()
(output, state) = model(X, state) # output: 形状为(num_steps * batch_size, vocab_size)
# Y的形状是(batch_size, num_steps),转置后再变成长度为
# batch * num_steps 的向量,这样跟输出的行一一对应
y = torch.transpose(Y, 0, 1).contiguous().view(-1)
l = loss(output, y.long())
optimizer.zero_grad()
l.backward()
# 梯度裁剪
d2l.grad_clipping(model.parameters(), clipping_theta, device)
optimizer.step()
l_sum += l.item() * y.shape[0]
n += y.shape[0]
try:
perplexity = math.exp(l_sum / n)
except OverflowError:
perplexity = float('inf')
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (
epoch + 1, perplexity, time.time() - start))
for prefix in prefixes:
print(' -', predict_rnn_pytorch(
prefix, pred_len, model, vocab_size, device, idx_to_char,
char_to_idx))
使用和上一节实验中一样的超参数(除了学习率)来训练模型。
num_epochs, batch_size, lr, clipping_theta = 250, 32, 1e-3, 1e-2 # 注意这里的学习率设置
pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
输出:
epoch 50, perplexity 10.658418, time 0.05 sec
- 分开始我妈 想要你 我不多 让我心到的 我妈妈 我不能再想 我不多再想 我不要再想 我不多再想 我不要
- 不分开 我想要你不你 我 你不要 让我心到的 我妈人 可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯狂的
epoch 100, perplexity 1.308539, time 0.05 sec
- 分开不会痛 不要 你在黑色幽默 开始了美丽全脸的梦滴 闪烁成回忆 伤人的美丽 你的完美主义 太彻底 让我
- 不分开不是我不要再想你 我不能这样牵着你的手不放开 爱可不可以简简单单没有伤害 你 靠着我的肩膀 你 在我
epoch 150, perplexity 1.070370, time 0.05 sec
- 分开不能去河南嵩山 学少林跟武当 快使用双截棍 哼哼哈兮 快使用双截棍 哼哼哈兮 习武之人切记 仁者无敌
- 不分开 在我会想通 是谁开没有全有开始 他心今天 一切人看 我 一口令秋软语的姑娘缓缓走过外滩 消失的 旧
epoch 200, perplexity 1.034663, time 0.05 sec
- 分开不能去吗周杰伦 才离 没要你在一场悲剧 我的完美主义 太彻底 分手的话像语言暴力 我已无能为力再提起
- 不分开 让我面到你 爱情来的太快就像龙卷风 离不开暴风圈来不及逃 我不能再想 我不能再想 我不 我不 我不
epoch 250, perplexity 1.021437, time 0.05 sec
- 分开 我我外的家边 你知道这 我爱不看的太 我想一个又重来不以 迷已文一只剩下回忆 让我叫带你 你你的
- 不分开 我我想想和 是你听没不 我不能不想 不知不觉 你已经离开我 不知不觉 我跟了这节奏 后知后觉
原书地址
中文版:动手学深度学习 | Github仓库
English Version: Dive into Deep Learning | Github Repo