@
总体框架图:
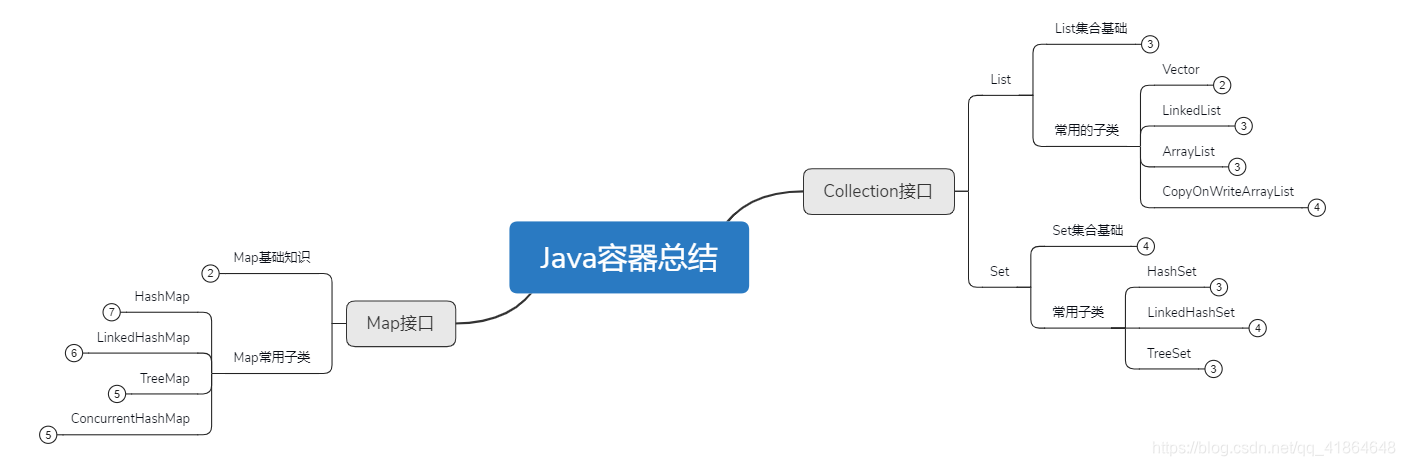
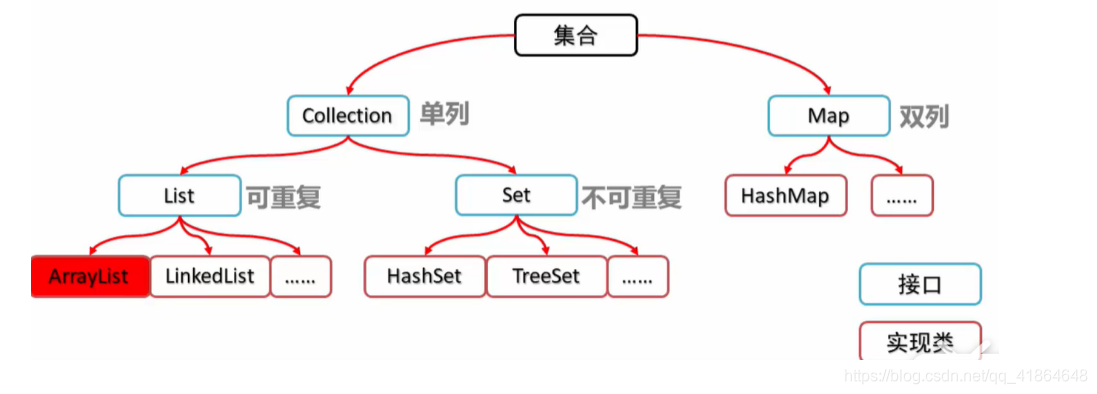
一、Collection接口
基本功能

遍历
方式一:集合转数组

方式二:使用集合自带的迭代器
- iterator 集合的专有遍历方式,通过集合的
iterator()方法获得,所以迭代器是依赖于集合而存在的
//得到迭代器来遍历数组。迭代器与数组是相辅相成的
Iterator it =c.iterator();//通过集合的方法返回迭代器对象
while (it.hasNext()){
String s= (String) it.next();
System.out.println(s);
}
注意基础迭代器会存在并发修改异常的问题,这个后面再详细分析源码讨论

1. List
List 集合概述
- 有序集合(也称序列),用户可以精确控制列表中的每个元素的插入位置,通过整数索引访问元素
- 与 Set集合不同,List允许有重复元素
特点 - 有序:存储与取出的元素顺序一致
- 可重复:存储的元素可重复
List集合的特有方法
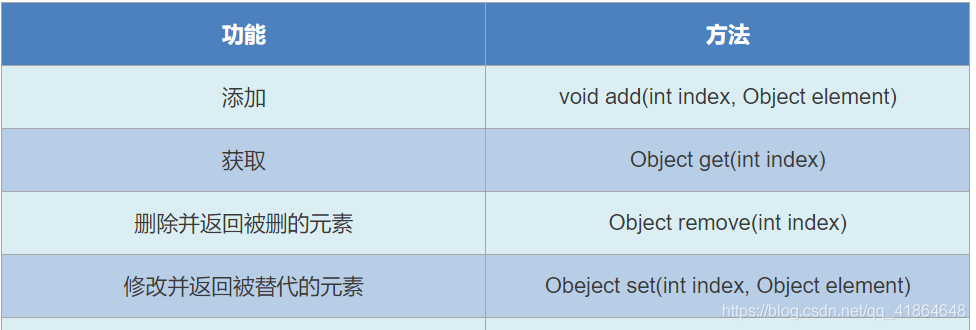
遍历(没有学泛型之前,都要强转)
-
Iterator 普通迭代器在一边迭代同时又出现修改集合操作的时候,会发生
异常 -
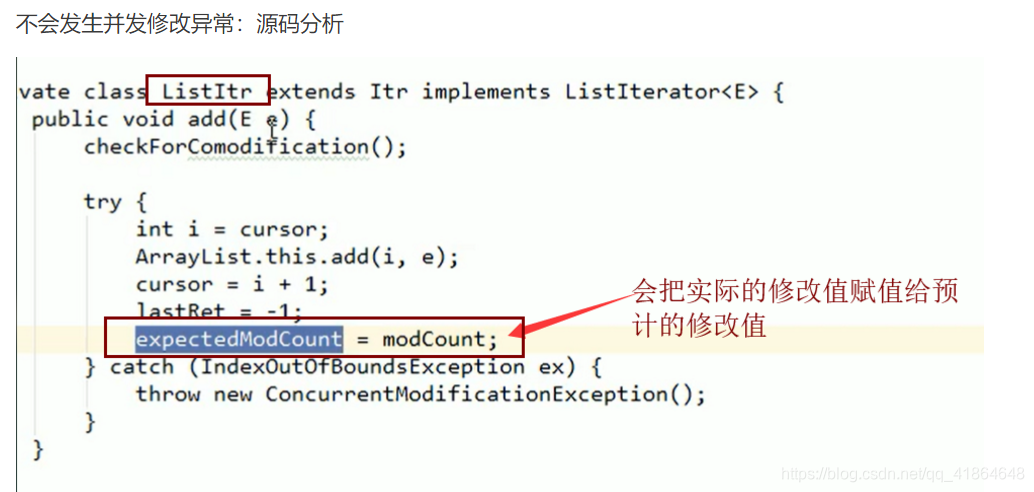
ListIterator listIterator()(继承Iterator,可以从后往前遍历,但开发中不怎么用它)遍历List集合时修改元素不会发生并发修改异常
出现的原因
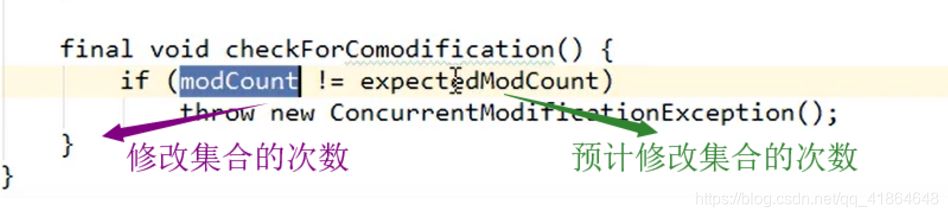
普通迭代器在迭代期间不允许修改元素
迭代器遍历的过程中,通过集合对象修改了集合中的元素,造成了迭代器获取元素中判断预期修改值和实际修改值不一致,则会出现:ConcurrentModificationException
解决的方案
用 普通 for循环遍历,然后用集合对象做对应的操作即可,切记不可以用 增强 for 循环
或者使用专有迭代器 ListIterator




列表迭代器【应用】
ListIterator 介绍
- 通过 List集合的
listIterator()方法得到,所以说它是List集合特有的迭代器 - 用于允许程序员沿任一方向遍历的列表迭代器,从后往前遍历也可以实现
- 允许在迭代期间修改列表,并获取列表中迭代器的当前位置
增强for循环【应用】
for(String s : list) {
System.out.println(s);
}
//内部原理是一个Iterator迭代器
for(String s : list) {
if(s.equals("world")) {
list.add("javaee"); //ConcurrentModificationException
//和普通迭代器一样会抛出并发修改异常
}
}
List集合子类的特点【记忆】
- ArrayList::底层是数组结构实现,查询快、增删慢
- LinkedList: 底层是链表结构实现,查询慢、增删快
- Vector:底层数据结构是数组。线程安全
ArrayList
参考:https://blog.csdn.net/weixin_40304387/article/details/80790177
https://www.cnblogs.com/V1haoge/p/10414458.html
1. 概述
ArrayList底层使用的是数组。是List的可变数组实现,这里的可变是针对List而言,而不是底层数组。
数组有自身的特点,不变性,一旦数组被初始化,那么其长度就固定了,不可被改变。这就导致了ArrayList中的一个重要特性:扩容。
public static void main(String[] args) {
ArrayList<String> arr=new ArrayList<>();
arr.add("hello");
arr.add("world");
arr.add("java");
//arr.add(3,"zy");
arr.add(4,"zy");//IndexOutOfBoundsException: Index: 4, Size: 3
System.out.println(arr);
}
案例:元素去重
/**
* 字符串去重:与自身比较
*/
public class ArrayListDemo01 {
public static void main(String[] args) {
ArrayList arrayList = new ArrayList();
arrayList.add("hello");
arrayList.add("java");
arrayList.add("hello");
arrayList.add("world");
for (int i = 0; i < arrayList.size() - 1; i++){
for (int j = i + 1; j<arrayList.size();j++){
if (arrayList.get(i).equals(arrayList.get(j))){
arrayList.remove(j);
j--;
}
}
}
//遍历集合
for (int i = 0; i < arrayList.size(); i++){
System.out.println(arrayList.get(i));
}
}
}
/**
* 自定义对象的集合,去重
* 自定义对象一定要重写 equals方法
*/
public class ArrayListDemo02 {
public static void main(String[] args) {
Student stu1 = new Student("张三",18);
Student stu2 = new Student("李四",20);
Student stu3 = new Student("张三",18);
Student stu4 = new Student("张三",18);
Student stu5 = new Student("张三",18);
ArrayList list = new ArrayList();
list.add(stu1);
list.add(stu2);
list.add(stu3);
list.add(stu4);
list.add(stu5);
ArrayList newList = new ArrayList();
// 元素去重
for (int i = 0; i < list.size(); i++ ){
Student s = (Student) list.get(i);//没有使用泛型,这里需要强转一下
if (!newList.contains(s)){
newList.add(s);
}
}
//遍历newList
for (int i = 0; i < newList.size(); i++){
Student s = (Student) newList.get(i);
System.out.println(s);
}
}
}
contains() 方法的源码分析:为什么要重写equals()方法
不重写 equals() 方法的话,那list 集合中的每个对象在比较时,内存地址都不一样都是一个完全新生的不同的对象,那么 比较内容 也就不奏效了。

思考:去除字符串的两种方法,一种用了contains,另一种用了equals。其实去除自定义对象时也可以直接用equals,这样更明确需要重写equals。
contains()底层依赖于equals(),String已经重写,所以我们也要把自定义对象重写(eclipse自动生成,但最好自己知道怎么写!)
LinkedList
LinkedList集合的特有功能【应用】
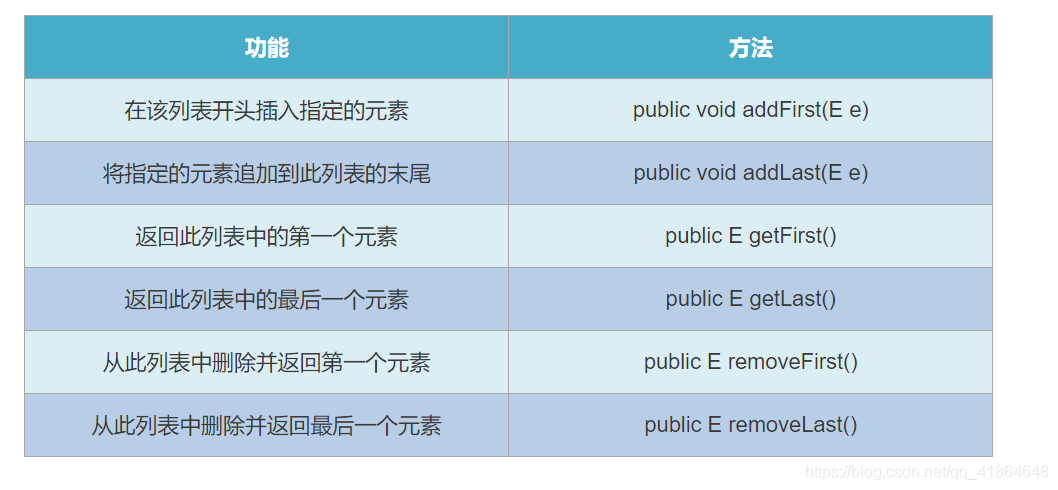
使用 LinkedList 模拟栈
public class MyStack {
private LinkedList link;
public MyStack() {
link = new LinkedList();
}
public void add(Object obj) {
link.addFirst(obj);
}
public Object get() {
// return link.getFirst();
return link.removeFirst();
}
public boolean isEmpty() {
return link.isEmpty();
}
}
Vector
底层是数组,线程安全,效率低,查询快,增删慢

Vector的两种遍历方式

CopyOnWriteArrayList
参考: CopyOnWriteArrayList,冷门容器却每次面试都问
1. CopyOnWriteArrayList的出现原因
一些案例说明了ArrayList使用的局限性,既然是非线程安全,会出现并发修改异常问题,也就是读写时的加锁问题。
那我们就使用一些机制把它变安全不就好了。变安全的方法有很多。比如说替换成Vector,再或者是使用 Collections,可以将 ArrayList 包装成一个线程安全的类。不过这两种方法也有很大的缺点,那就是他们使用的都是独占锁,独占式锁在同一时刻只有一个线程能够获取,效率太低。于是CopyOnWriteArrayList 应用而生了。
2、CopyOnWriteArrayList 介绍
(1)独占锁效率低:采用读写分离思想解决
既然独占锁的效率低下,那我们可以换一种方式,采用读写分离式的思想将读操作和写操作进行分开即可。
读操作不加锁,所有线程都不会阻塞。写操作加锁,线程会阻塞。
(2)写线程获取到锁,其他线程包括读线程阻塞
但是这时候又出现了另外一个问题了:写线程获取到锁之后,其他的读线程会陷入阻塞。
(3)复制思想:解决问题2
这咋办呢?我们可以再转化一下思想:
当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行 Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
这时候会抛出来一个新的问题,也就是数据不一致的问题。如果写线程还没来得及写会内存,其他的线程就会读到了脏数据。
这就是CopyOnWriteArrayList 的思想和原理。就是拷贝一份写。所以使用条件也很局限,那就是在读多写少的情况下比较好。
3、源码分析(基于JDK1.8)
- 读取
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private transient volatile Object[] array;
final Object[] getArray() {
return array;
}
public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}
可以看到,读取代码没有任何同步控制和锁操作,因为内部数组array不会发生修改,只会被另一个array替换,可以保证数据安全。
- 写操作
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
可以看到,写操作使用了锁 ReentrantLock ,
重点在 Object[] newElements = Arrays.copyOf(elements, len + 1);这里在生成一个新的数组,然后将新的元素加入到newElements中,
再将新的数组替换成老的数组,修改就完成了, setArray(newElements);
整个过程不会影响到读取的线程。当修改完成后,读取线程可以立即察觉到这个修改,因为array被volatile修饰了。
4、总结
这个容器很简单,虽然是采用了读写分离的思想,但是却有很大不同,不同之处在于copy。
1、读写锁
读线程具有实时性,写线程会阻塞。解决了数据不一致的问题。但是读写锁依然会出现读线程阻塞等待的情况
2、CopyOnWriteArrayList
读线程具有实时性,写线程会阻塞。不能解决数据不一致的问题。但是CopyOnWriteArrayList 不会出现读线程阻塞等待的情况

2. Set
Set集合概述和特点
- 无序:元素存储和取出没有顺序
- 遍历:没有索引、只能通过迭代器 iterator 或增强 for循环遍历
- 不重复:不能存储重复元素
Set没有特有功能方法,都和 Collection 一样
//创建集合对象
Set<String> set = new HashSet<String>();
HashSet
HashSet 集合的特点
- 底层数据结构是哈希表
- 对集合的迭代顺序不作任何保证,也就是说不保证存储和取出的元素顺序一致
- 没有带索引的方法,所以不能使用普通 for循环遍历
- 由于是 Set集合,所以是不包含重复元素的集合
- HashSet底层数据结构是哈希表:是一个元素为链表的数组,综合了数组和链表的好处。
HashSet 集合的基本使用
HashSet<String> hs = new HashSet<String>();
HashSet集合保证元素唯一性源码分析
1.根据对象的哈希值计算存储位置
- 如果当前位置没有元素则直接存入
- 如果当前位置有元素存在,则进入第二步
.2.当前元素的元素和已经存在的元素比较哈希值
- 如果哈希值不同,则将当前元素进行存储
- 如果哈希值相同,则进入第三步
3.通过equals()方法比较两个元素的内容
- 如果内容不相同,则将当前元素进行存储
- 如果内容相同,则不存储当前元素

LinkedHashSet
LinkedHashSet 集合特点
- 哈希表和链表实现的 Set接口,具有可预测的迭代次序
- 由链表保证元素有序,也就是说元素的存储和取出顺序是一致的
- 由哈希表保证元素唯一,也就是说没有重复的元素
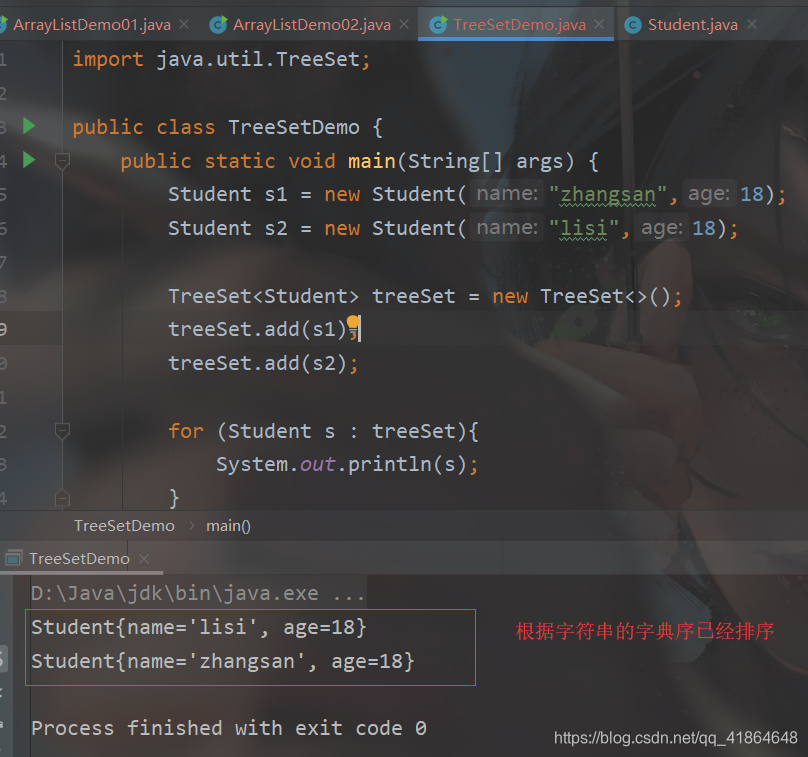
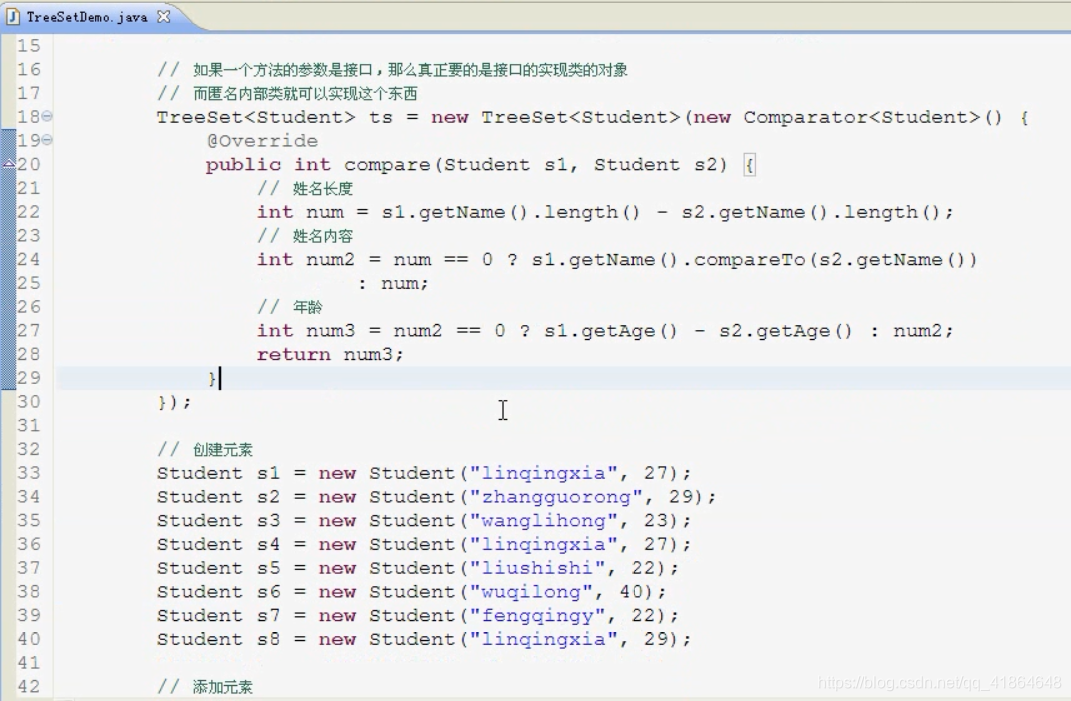
TreeSet
TreeSet 集合特点
-
元素有序,可以按照一定的规则进行排序,具体排序方式取决于构造方法
-
TreeSet() :根据其元素的自然排序进行排序
-
TreeSet(Comparator comparator) :根据指定的比较器进行排序
-
没有带索引的方法,所以不能使用普通 for循环遍历
-
由于是 Set集合,所以不包含重复元素的集合
TreeSet的add()源码解析
底层是二叉树结构
- .第一个元素作为根节点,和后面的元素比较,小的放左边,大的放右边,相同的不放
- 在二叉树结构下,排序又依赖于comparable接口的
compareTo方法,按照指定规则强行给对象比大小,然后存入树中。

Integer自然排序演示
Integer已经实现comparable接口并重写compareTo()方法
另外,String也重写了compareTo()方法,根据字典顺序排序字符串
public class TreeSetDemo01 {
public static void main(String[] args) {
//创建集合对象
TreeSet<Integer> ts = new TreeSet<Integer>();//默认无参构造方法,自然排序
//添加元素
ts.add(10);
ts.add(40);
ts.add(30);
ts.add(50);
ts.add(20);
ts.add(30);
//遍历集合
for(Integer i : ts) {
System.out.println(i);//10 20 30 40 50
}
}
}
存储自定义对象并遍历练习
Student类实现comparable接口并重写compareTo()方法
@Override
public int compareTo(Student s) {
int num = this.age - s.age;
int num2 = num == 0 ? this.name.compareTo(s.name) : num;
return num2;
}
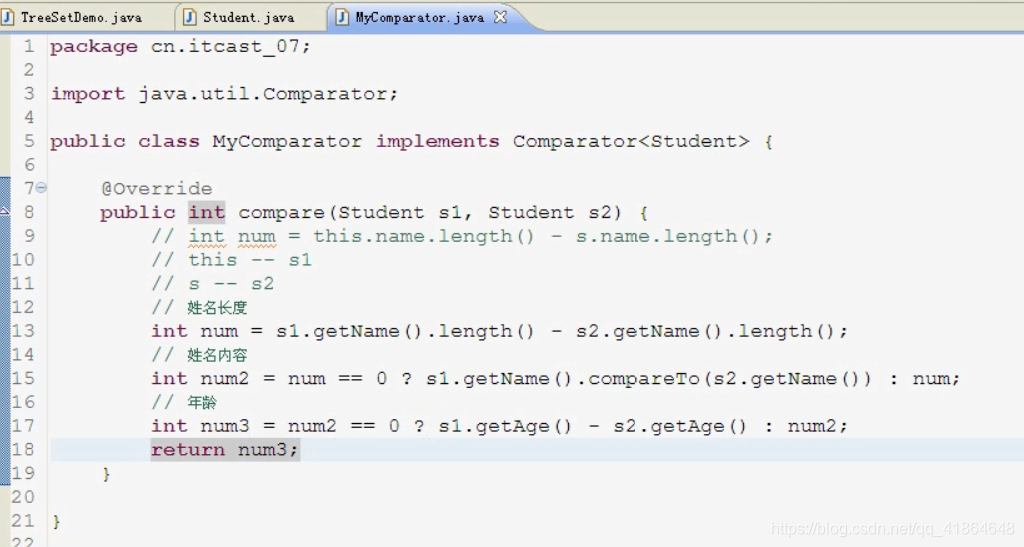
自定义排序比较器
TreeSet(Comparator<? super E> comparator):比较器排序(集合具备比较性)
方式一:创建Mycomparator类实现comparator接口,重写compare()方法:比较条件和自然排序一样写
方式二:如果只用一次,不另外创建比较器,直接用匿名对象传参(开发常用)
总结 TreeSet集合
二、Map接口
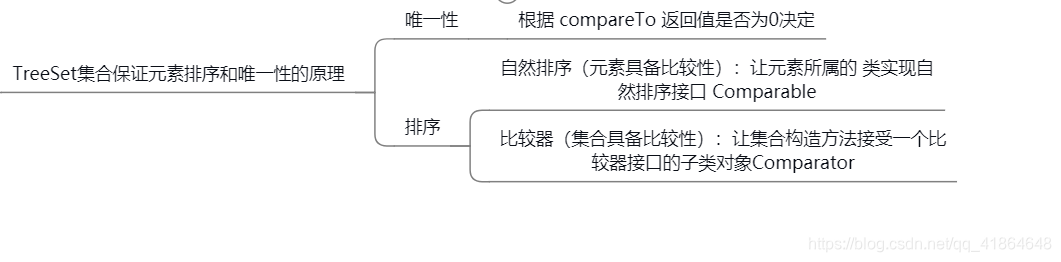
Map 集合的特点
MAP的键要保证唯一性,所以在用自定义的类做键时,一定要重写两个方法:hashmap equals方法
双列集合接口
interface Map<K,V> K:键的类型;V:值的类型
- 键值对映射关系
- 一个键对应一个值
- 键不能重复,值可以重复
- 元素存取无序
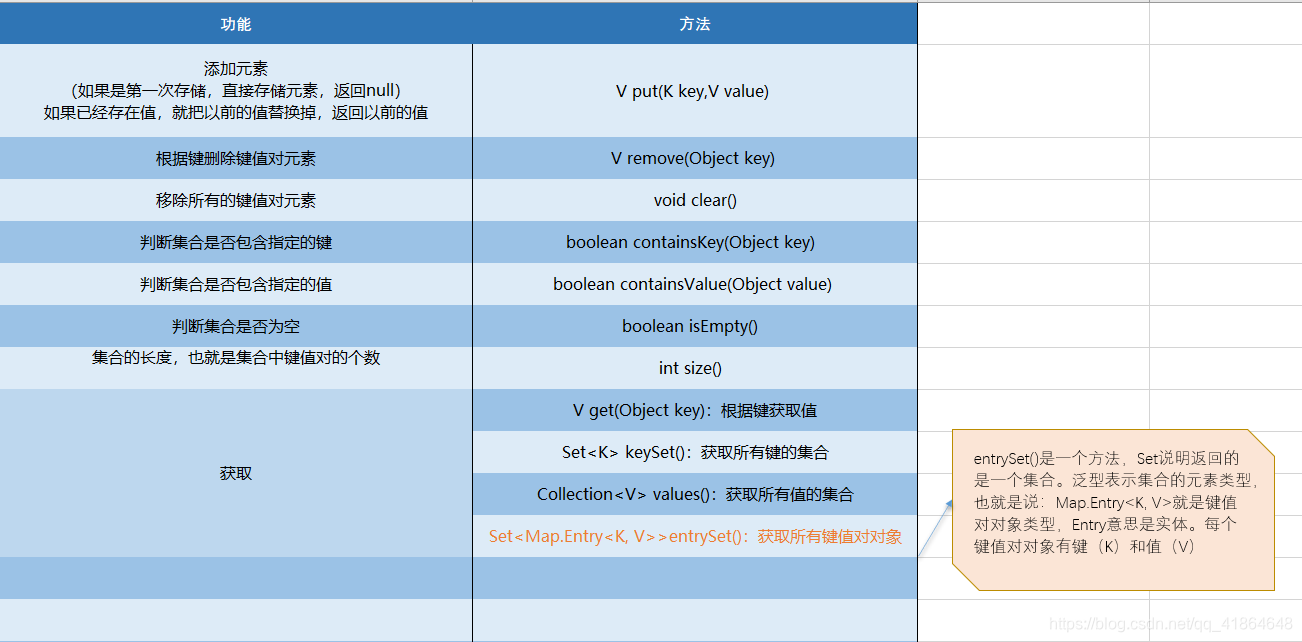
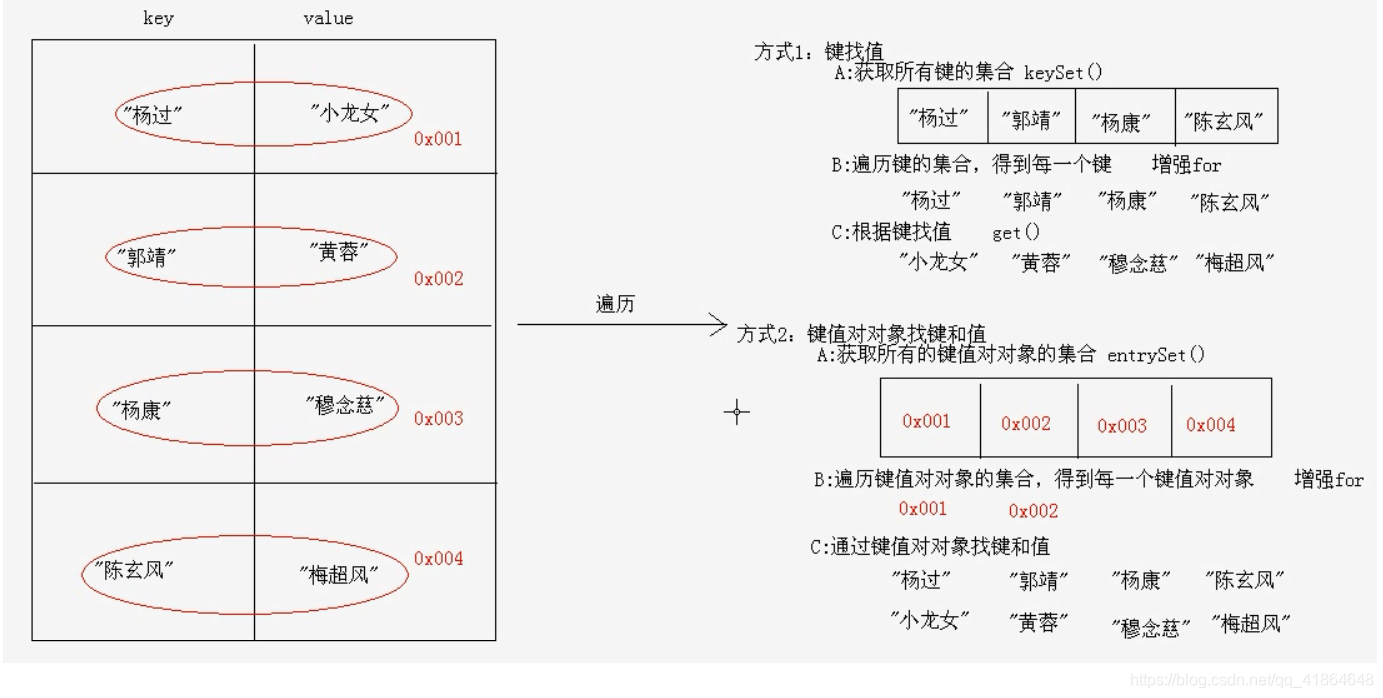
Map集合的遍历(方式1)
遍历思路
- 我们刚才存储的元素都是成对出现的,所以我们把 Map看成是一个夫妻对的集合
- 把所有的丈夫给集中起来
- 遍历丈夫的集合,获取到每一个丈夫
- 根据丈夫去找对应的妻子
//获取所有键的集合。用keySet()方法实现
Set<String> keySet = map.keySet();
//遍历键的集合,获取到每一个键。用增强for实现
for (String key : keySet) {
//根据键去找值。用get(Object key)方法实现
String value = map.get(key);
System.out.println(key + "," + value);
}
}
Map集合的遍历(方式2)
步骤分析
- 获取所有键值对对象的集合
- Set<Map.Entry<K,V>> entrySet() :获取所有键值对实体的集合
- 遍历键值对实体的集合,得到每一个键值对对象
- 用增强 for实现,得到每一个Map.Entry
- 根据键值对对象获取键和值
- 用 getKey()得到键
- 用 getValue()得到值
//创建集合对象
Map<String, String> map = new HashMap<String, String>();
//获取所有键值对对象的集合
Set<Map.Entry<String, String>> entrySet = map.entrySet();
//遍历键值对对象的集合,得到每一个键值对对象
for (Map.Entry<String, String> me : entrySet) {
//根据键值对对象获取键和值
String key = me.getKey();
String value = me.getValue();
System.out.println(key + "," + value);
}
HashMap
HashMap是基于哈希表的Map实现,此处的哈希表结构是用来保证键的唯一性的。
HashMap的几个案例(存储不同的键和值类型)
- HashMap<String, String>
- HashMap<Integer, String>
- HashMap<String, Student>
- HashMap<Student, String>
几个案例中,最后一个案例最重要:
键为student对象,值为String。所谓“键相同,值覆盖”的特性,底层必须借助哈希表保证键的唯一性,也就是student元素的唯一性,由于HashMap键的唯一性是依赖于哈希表,哈希表依赖于hashCode()和equals()的重写。student要保证作为键的唯一性,则必须重写这两个方法!
练习:集合嵌套之ArrayList嵌套HashMap
//创建ArrayList集合
ArrayList<HashMap<String, String>> array = new
ArrayList<HashMap<String, String>>();
//创建HashMap集合,并添加键值对元素
HashMap<String, String> hm1 = new HashMap<String, String>();
hm1.put("孙策", "大乔");
hm1.put("周瑜", "小乔");
HashMap<String, String> hm2 = new HashMap<String, String>();
hm2.put("郭靖", "黄蓉");
hm2.put("杨过", "小龙女");
HashMap<String, String> hm3 = new HashMap<String, String>();
hm3.put("令狐冲", "任盈盈");
hm3.put("林平之", "岳灵珊");
/把HashMap作为元素添加到ArrayList集合
array.add(hm1);
array.add(hm2);
array.add(hm3);
//遍历ArrayList集合
for (HashMap<String, String> hm : array) {
Set<String> keySet = hm.keySet();
for (String key : keySet) {
String value = hm.get(key);
System.out.println(key + "," + value);
}
练习:集合嵌套之HashMap嵌套ArrayList
//创建HashMap集合
HashMap<String, ArrayList<String>> hm = new HashMap<String,
ArrayList<String>>();
//创建ArrayList集合,并添加元素
ArrayList<String> sgyy = new ArrayList<String>();
sgyy.add("诸葛亮");
sgyy.add("赵云");
ArrayList<String> xyj = new ArrayList<String>();
xyj.add("唐僧");
xyj.add("孙悟空");
ArrayList<String> shz = new ArrayList<String>();
shz.add("武松");
shz.add("鲁智深");
//把ArrayList作为元素添加到HashMap集合
hm.put("三国演义",sgyy);
hm.put("西游记",xyj);
hm.put("水浒传",shz);
//遍历HashMap集合
Set<String> keySet = hm.keySet();
for(String key : keySet) {
System.out.println(key);
ArrayList<String> value = hm.get(key);
for(String s : value) {
System.out.println(" " + s);
}
}
题型:统计字符串中每个字符出现的次数
案例需求
- 键盘录入一个字符串,要求统计字符串中每个字符串出现的次数。
- 举例:键盘录入 “aababcabcdabcde” 在控制台输出:“a(5)b(4)c(3)d(2)e(1)”
代码实现
public class CharCountDemo {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("请输入字符串: ");
String line = sc.nextLine();
//创建一个map集合,键是Character,值是Integer(HashMap,TreeMap类型都可)
HashMap<Character,Integer> map = new HashMap<Character,Integer>();
// TreeMap<Character,Integer> map = new TreeMap<>();
//遍历字符串的每一个字符,判断该字符在map中是否存在该键
for (int i = 0; i < line.length(); i++){
char key = line.charAt(i);
Integer value = map.get(key);
//如果返回值是null:说明该字符在Map集合中不存在,就把该字符作为键, 1 作为值存储
if (value == null){
map.put(key,1);
}else{
//如果返回值不是null:说明该字符在Map集合中存在,把该值加1,然后重新存储该字符和对应的值
value++;
map.put(key,value);
}
}
//遍历map集合
StringBuilder sb = new StringBuilder();
Set<Character> keys = map.keySet();
for (Character key : keys){
Integer value = map.get(key);
sb.append(key).append("(").append(value).append(")");
}
System.out.println(sb.toString());
}
}
LinkedHashMap
Map接口的哈希表和链表列表实现,具有可预知的迭代顺序
- 哈希表保证唯一性
- 链表保证有序性
Hashtable
(和HashMap几乎一样,被HashMap替代了)
Hashtable与HashMap的区别
- HashMap:线程不安全,效率高,允许null键和null值
- Hashtable:线程安全,效率低,不允许null键和null值
TreeMap
参考:https://www.jianshu.com/p/e11fe1760a3d
概述:
- TreeMap存储K-V键值对,通过红黑树(R-B tree)实现;
- TreeMap继承了NavigableMap接口,NavigableMap接口继承了SortedMap接口,可支持一系列的导航定位以及导航操作的方法,当然只是提供了接口,需要TreeMap自己去实现;
- TreeMap实现了Cloneable接口,可被克隆,实现了Serializable接口,可序列化;
- TreeMap因为是通过红黑树实现,红黑树结构天然支持排序,默认情况下通过Key值的自然顺序进行排序;
三种Map子类集合的对比:
HashMap可实现快速存储和检索,但其缺点是其包含的元素是无序的,这导致它在存在大量迭代的情况下表现不佳。LinkedHashMap保留了HashMap的优势,且其包含的元素是有序的。它在有大量迭代的情况下表现更好。TreeMap能便捷的实现对其内部元素的各种排序,但其一般性能比前两种map差。
LinkedHashMap映射减少了HashMap排序中的混乱,且不会导致TreeMap的性能损失。
ConcurrentHashMap
链接:https://www.jianshu.com/p/d0b37b927c48
HashMap线程不安全
因为多线程环境下,使用Hashmap进行put操作可能会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。
Hashtable线程安全但效率低下
Hashtable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下Hashtable的效率非常低下。因为当一个线程访问Hashtable的同步方法时,其他线程访问Hashtable的同步方法时,可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
Hashtable
的任何操作都会把整个表锁住,是阻塞的。好处是总能获取最实时的更新,比如说线程A调用putAll写入大量数据,期间线程B调用get,线程B就会被阻塞,直到线程A完成putAll,因此线程B肯定能获取到线程A写入的完整数据。坏处是所有调用都要排队,效率较低。
ConcurrentHashMap
分段锁
是设计为非阻塞的。在更新时会局部锁住某部分数据,但不会把整个表都锁住。同步读取操作则是完全非阻塞的。好处是在保证合理的同步前提下,效率很高。坏处是严格来说读取操作不能保证反映最近的更新。例如线程A调用putAll写入大量数据,期间线程B调用get,则只能get到目前为止已经顺利插入的部分数据。
应该根据具体的应用场景选择合适的HashMap。
三、Collections 集合工具类
方法名 说明
-
排序:
public static <T> void sort(List<T> list)
默认情况下是自然顺序,所以自定义对象要实现Comparable接口 -
反转 :
public static void reverse(List<?> list)反转指定列表中元素的顺序 -
随机置换 :
public static void shuffle(List<?> list)使用默认的随机源随机排列指定的列表 -
二分查找:
public static <T> int binarySearch(List<?> list, T key) -
最大值:
public static <T> max(Collection<?> coll)
案例:使用工具类对arraylist进行排序
{
ArrayList<Student> array = new ArrayList<Student>();
//创建学生对象
Student s1 = new Student("lin", 30);
Student s2 = new Student("wang", 32);
Student s3 = new Student("liu", 33);
Student s4 = new Student("zhang", 33);
//把学生对象添加到集合
array.add(s1);
array.add(s2);
array.add(s3);
array.add(s4);
//使用Collections 对ArrayList集合进行排序
Collections.sort(array, new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
//先按年龄排序,后按名字排序
int num = s1.getAge() - s2.getAge();
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
return num2;
}
});
//遍历集合
for (Student s : array) {
System.out.println(s.getName() + "," + s.getAge());
}
}
案例:斗地主
public class PokerDemo {
public static void main(String[] args) {
//创建HashMap,键是编号,值是牌
HashMap<Integer,String> hm =new HashMap<Integer, String>();
//创建ArrayList,存储编号
ArrayList<Integer> array =new ArrayList<Integer>();
//创建花色数组和点数数组
String[] colors={"♦", "♣", "♥", "♠"};
String[] numbers={"3", "4", "5", "6", "7", "8", "9", "10", "J", "Q",
"K", "A", "2"};
//从0开始往HashMap里面存储编号,并存储对应的牌。同时往ArrayList里面存储编号
int index=0;
for(String number:numbers){
for (String color:colors){
hm.put(index,color+number);
array.add(index);
index++;
}
}
hm.put(index,"小王");
array.add(index);
index++;
hm.put(index,"大王");
array.add(index);
//洗牌(洗的是编号),用Collections的shuffle()方法实现
Collections.shuffle(array);
//发牌(发的也是编号,为了保证编号是排序的,创建TreeSet集合接收)
TreeSet<Integer> lqxSet=new TreeSet<Integer>();
TreeSet<Integer> lySet = new TreeSet<Integer>();
TreeSet<Integer> fqySet = new TreeSet<Integer>();
TreeSet<Integer> dpSet = new TreeSet<Integer>();//底牌
for(int i=0;i<array.size();i++){
int x=array.get(i);
if(i>=array.size()-3){
dpSet.add(x);
}else if (i%3==0){
lqxSet.add(x);
}else if(i%3==1){
lySet.add(x);
}else if(i%3==2){
fqySet.add(x);
}
}
//调用看牌方法
lookPoker("林青霞", lqxSet, hm);
lookPoker("柳岩", lySet, hm);
lookPoker("风清扬", fqySet, hm);
lookPoker("底牌", dpSet, hm);
}
//定义方法看牌(遍历TreeSet集合,获取编号,到HashMap集合找对应的牌)
public static void lookPoker(String name,TreeSet<Integer> ts,HashMap<Integer,String> hm){
System.out.println(name+"的牌是:");
for (Integer key:ts){
String poker=hm.get(key);
System.out.print(poker+" ");
}
System.out.println();
}
}