所需软件:
1. FreePic2Pdf(网上很容易找到)
2. python3
3. 天若OCR
搜狗OCR配置:https://tianruoocr.cn/interface/Txt_sougou.html
免费版调用的是百度的OCR,对于这种目录的识别效果不好,经过尝试发现只有搜狗的效果是最好的,所以如果有需要还是购买专业版,然后配置搜狗的OCR
实现方法:
1. 提取书签内容文本

许多英文书籍PDF的文字是可以直接复制粘贴的,这种情况比较好处理,直接复制出来,暂时保存到文本中。
如果为扫描版PDF,则可以用上面提供的天若OCR进行识别,然后提取文字内容,识别率挺高,不算太麻烦。
最后得到目录内容:
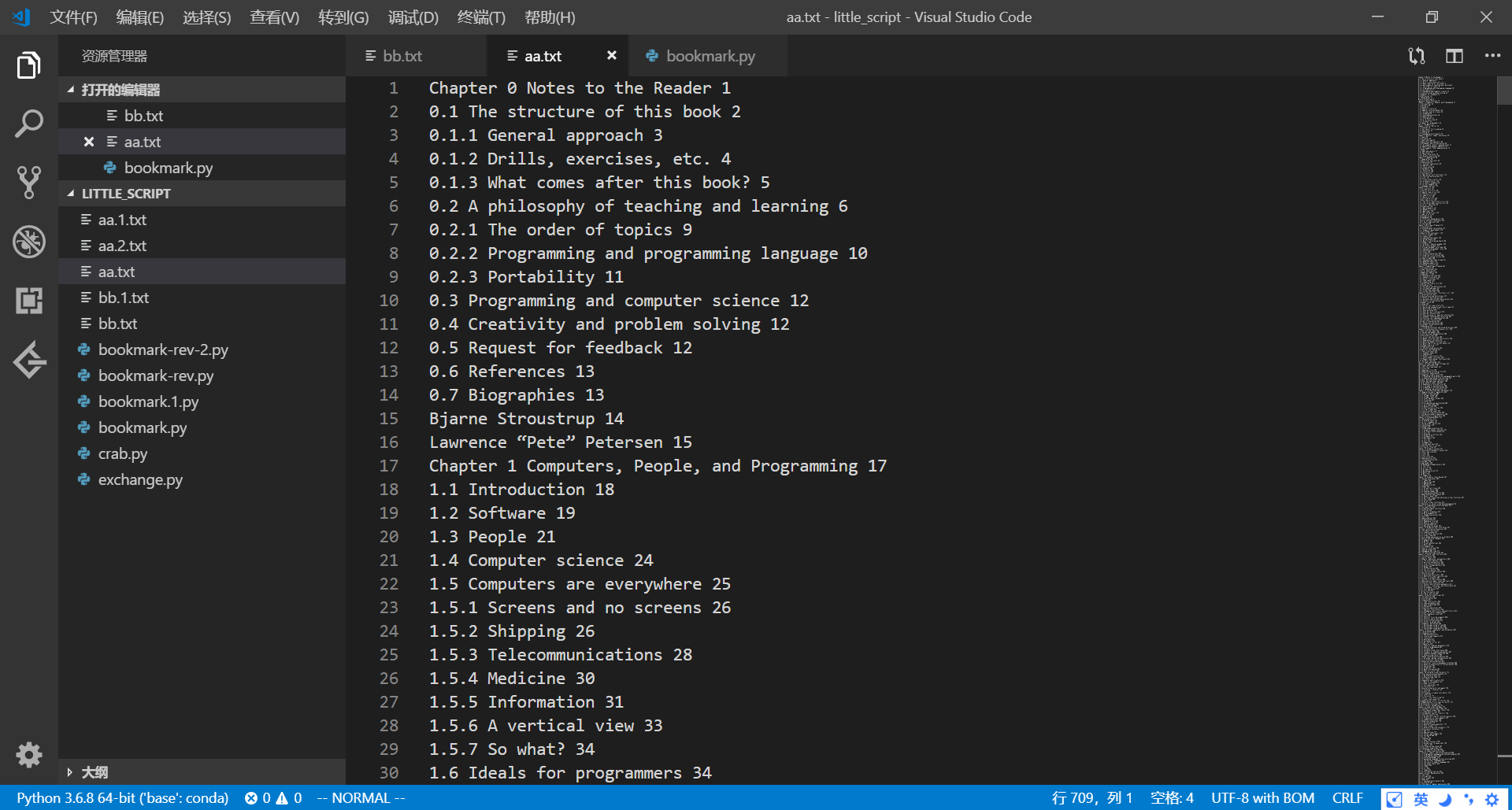
如果是用OCR软件识别的内容,有时候会有一些多余的符号,影响下面python脚本的运行,最常见的是:
1)目录出现换行,导致该行最后一个字符不是数字,脚本无法正确运行,会报错;
2)行末的数字前出现一些多余符号,也会影响脚本运行,一个个手动修改太麻烦,可以在VScode里用vim批量操作。如:

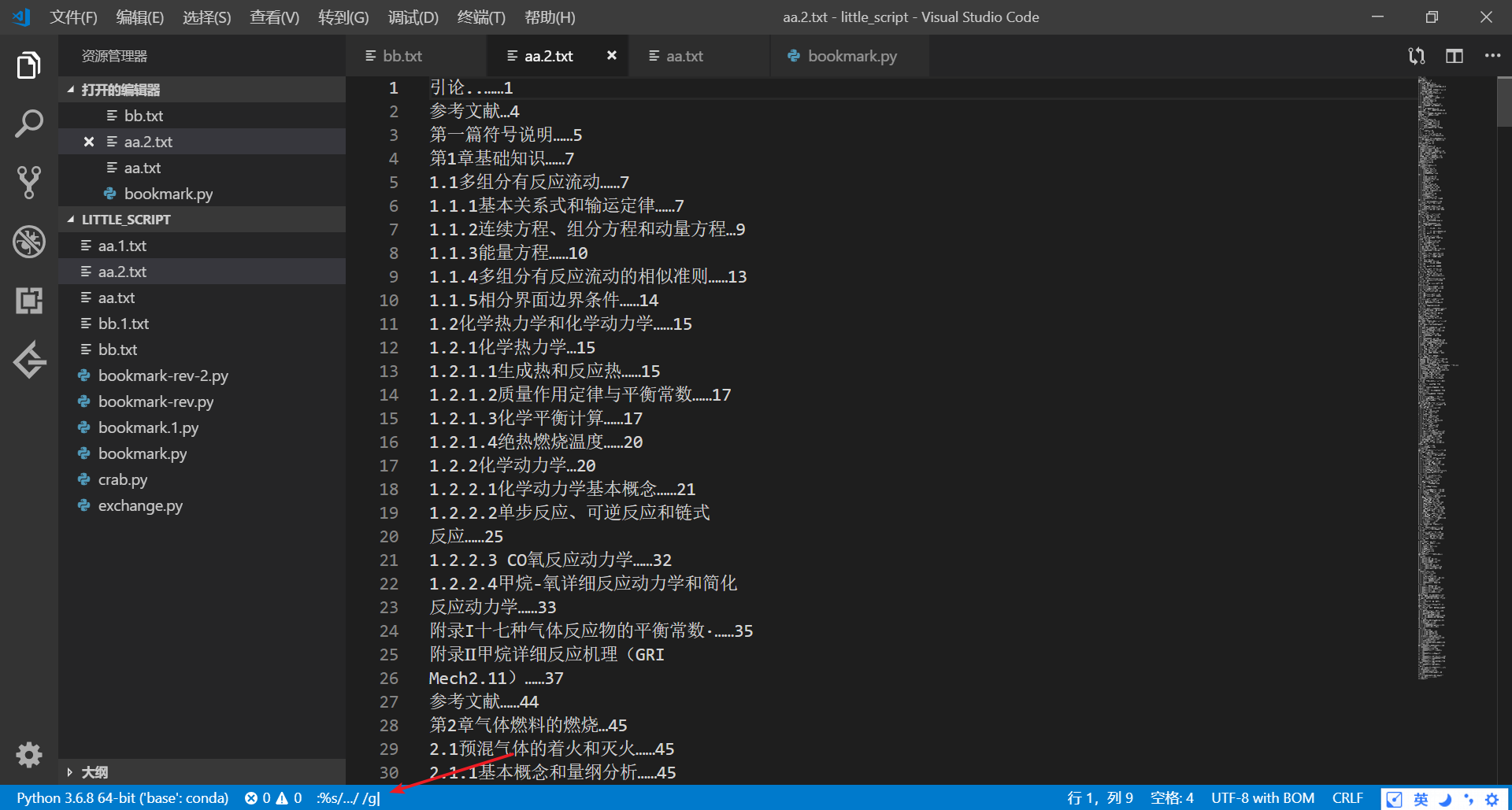
上面输入的替换命令为:
%s/…/ /g
用vim里:模式下的替换命令,上面表示把…全部替换成空格。注意VScode里的vim插件可以在替换命令里粘贴内容,但是我在terminal的vim里似乎不行,有些字符奇怪字符有时候不知道怎么打,可以直接粘贴过去。
%s/(待替换内容)/(替换内容)/g
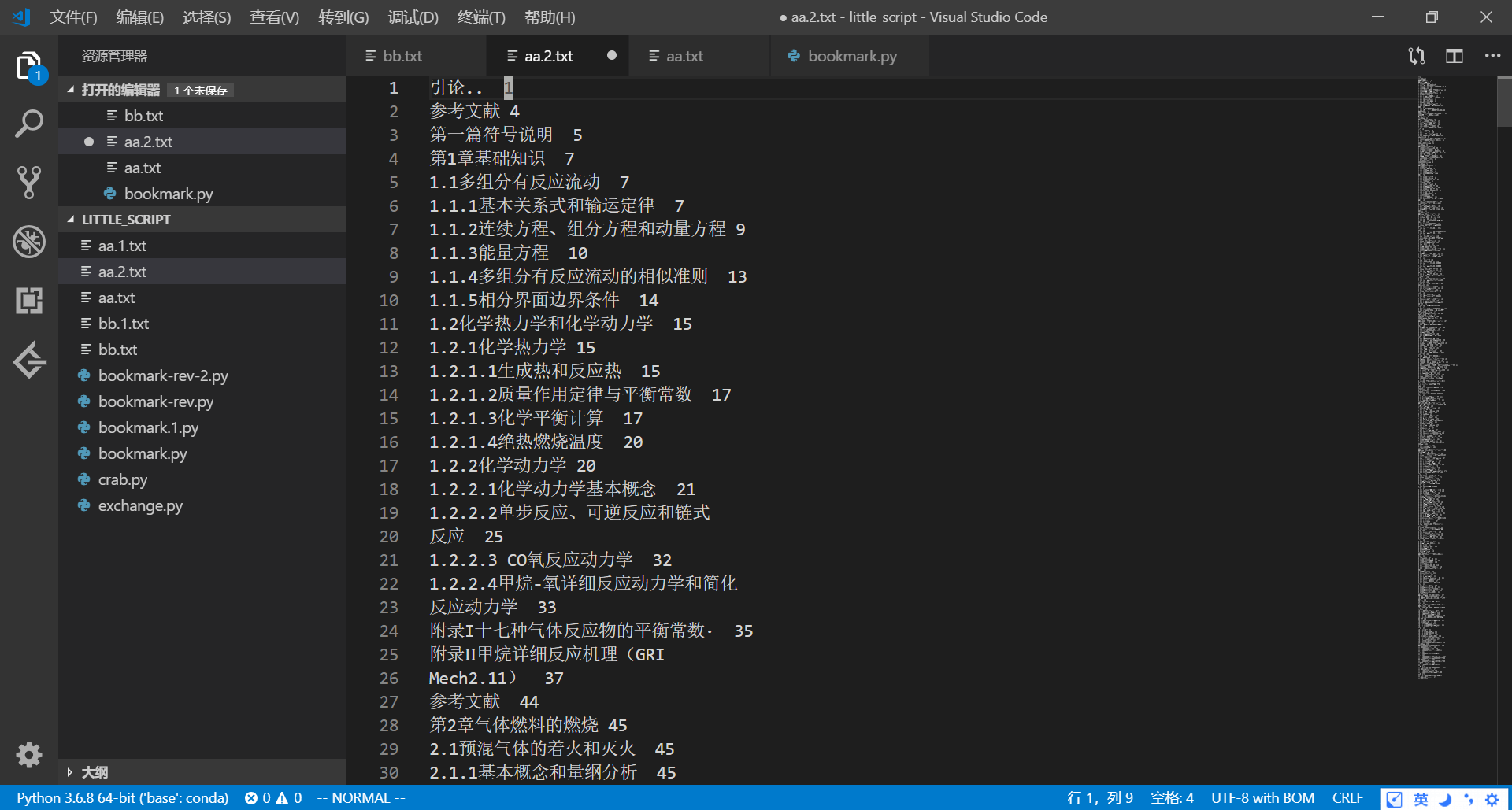
2. 在同一工作目录下运行如下python脚本
#!/usr/bin/python3 # -*- coding: UTF-8 -*- ''' @Author: Yin Weijie @Date: 2018.5.25 @Description: 替换页码 @Revised Date: 2019.3.7 @Description: 在次级目录前加tab ''' fin = open("aa.txt", "r") fout = open("bb.txt", "w") for each_line in fin: list = each_line.split() for i in range(len(list) - 1): #倒数第一个元素是数字,先不放 if (list[i] == '.'): continue # 这里章数默认不超过两位数 if ((len(list[i]) > 1 and list[i][1] == '.') or (len(list[i]) > 2 and list[i][2] == '.')): fout.write(' ') fout.write(list[i]) fout.write(' ') # print(list[i]) fout.write(' ') num = int(list[-1]) + 0 #单独处理倒数第一个数字 fout.write(str(num)) fout.write(" ") fin.close() fout.close()
得到文件bb.txt的内容:

这里实际上就是做一个文本替换,为后面FreePic2Pdf使用作准备。因为FreePic2Pdf只能识别固定格式的书签内容,主要有如下几方面需要修改:
1)页码是PDF中的绝对页码,通常需要加减一个差值,但是这个PDF的排版比较特殊,书中的页码内容和PDF绝对页码内容一致,否则上面python代码中
num = int(list[-1]) + 0 #单独处理倒数第一个数字
这一行加的数字应该是PDF绝对页码和书籍页码的差值。
2)页码数字和前面的文字之间应该是 ab,而不是空格。
3)每行行首也可以加 ab,表示次级目录。也可以加多个 ab增加更多目录层级,这里只做了一个次级目录。
3. 用FreePic2Pdf批量插入标签

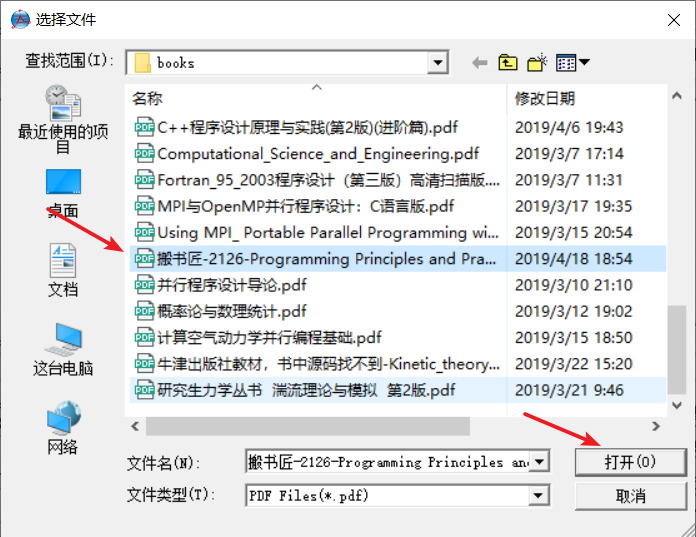
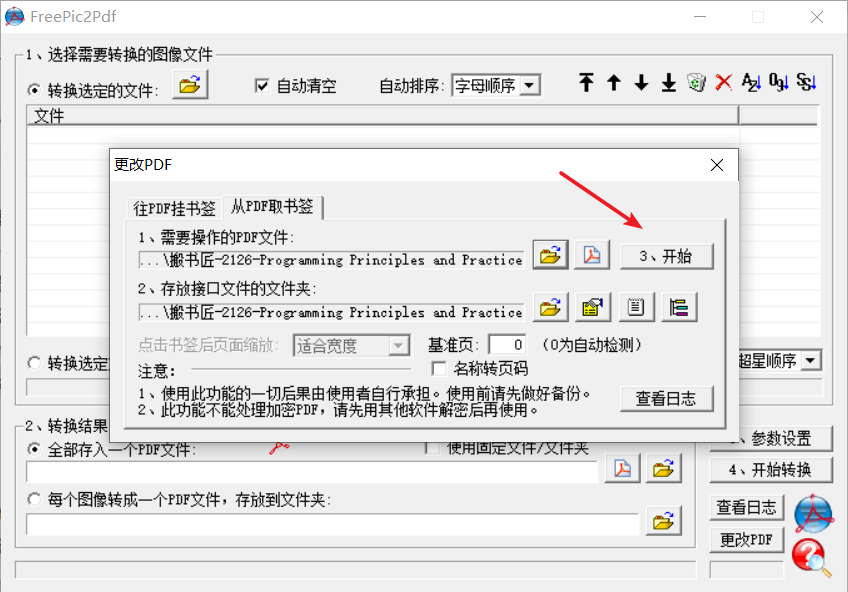
会在该PDF文件所在目录生成一个新的目录,包含如下文件:
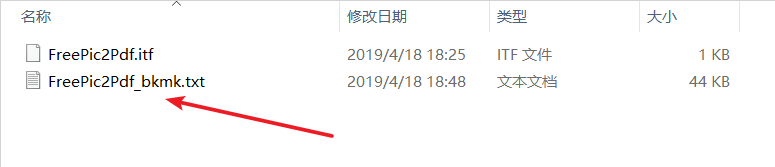
打开上面的txt文件,把之前生成的bb.txt中的内容贴进去,保存。然后再回到FreePic2Pdf软件:
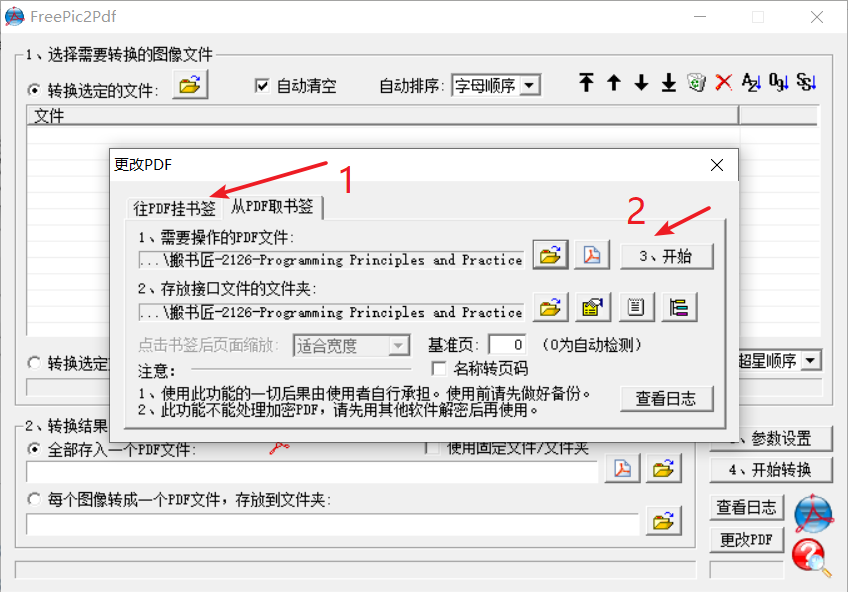
经过上面操作,就能成功添加标签了。
