| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 600 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 180 | 150 |
| · Design Spec | · 生成设计文档 | 40 | 30 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| · Design | · 具体设计 | 40 | 60 |
| · Coding | · 具体编码 | 180 | 180 |
| · Code Review | · 代码复审 | 60 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 180 |
| Reporting | 报告 | 210 | 220 |
| · Test Repor | · 测试报告 | 60 | 90 |
| · Size Measurement | · 计算工作量 | 30 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 120 | 120 |
| | 合计 | 840 | 940
解题思路:
- 首先,明确命令行程序WordCount要实现的五个功能:统计文件的字符数、统计文件的单词总数(单词:至少以4个英文字母开头,跟上字母数字符号)、统计文件的有效行数、统计文件中各单词的出现次数,输出频率最高的10个、按字典序输出到文件result.txt。其次,每条功能分析,设计解决办法。对于文件字符数,将文件内容赋值给一个string类型的变量strTxt,使用.length()即可求出文件字符数;对于文件的有效行数,定义int类型变量len,设初始值为1,每两个换行符中间包含有非空字符则len++,最后一行特殊考虑;对于文件的单词总数,将strTxt中非单词的字符置为空格,即可分离出单词,统计单词总数,然后使用unordered_map容器储存单词和单词出现的频率<string, int>;对于单词的排序输出,借助vector容器使用sort()函数即可完成排序,输出则是使用输出文件流将结果输出到文件result.txt。
- 在该题目设计解决方案的过程中,对于我来说,统计文件单词出现频率这个功能耗时比较久。一开始我并没有想到使用容器,我想到的是一个string数组,对应一个int数组,但是考虑到如果使用两个数组来存储,那么后面的排序什么的代码实现起来会比较复杂,所以我上网查找了具有一个string对应一个int功能的数据存储方式,找到了unordered_map容器正好适用于题目的情景,所以临时学习了一下这个容器的概念和使用,应用于本题的储存。
设计实现:
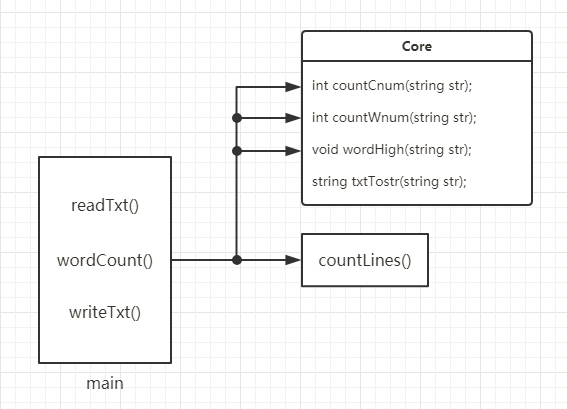
- WordCount主要设计了3个函数,readTxt()用于读入文本并将大写字母改为小写后赋值给string类型变量strTxt,countWords()用于统计文本有效行以及单词总数和频率,writeTxt()用于输出结果文本result.txt。readTxt()在读入文本时是一个一个字母读入的,且改为小写后再接到strTxt后,因此之后在统计相同单词的时候不需考虑大小写问题;countWords()的关键在于使用哈希容器unordered_map存储key-value,通过key(单词)快速索引到value(频率),此外通过C++自带的sort()函数借助vector容器对key-value进行排序,排序根据题目所给规则,找到出现频率最高的10个;writeTxt()简单使用输出文件流将结果输出到文件result.txt。
总的流程图:
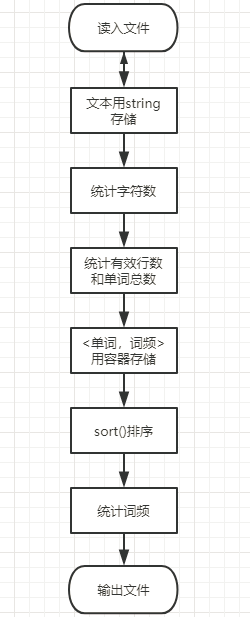
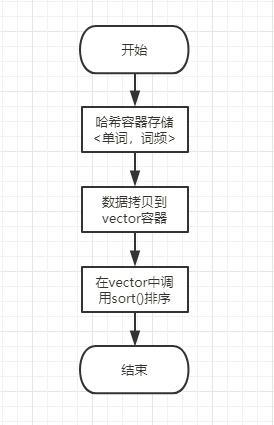
统计词频的流程图:
类图:

函数关系图:
代码说明:
统计词频的代码:
void Core::wordHigh(string str) {
unordered_map<string, int> strMap = createMap(str);
for (auto it = strMap.begin(); it != strMap.end(); it++) {
//使用迭代器将unordered_map容器中的数据拷贝到vector容器中
vtMap.push_back(make_pair(it->first, it->second));
}
sort(vtMap.begin(), vtMap.end(), myFunc);
//使用vector容器进行排序
}
unordered_map<string, int> createMap(string str) {
unordered_map<string, int> strMap;
string strWords;
stringstream strm(strManage(str));
//使用unordered_map容器存储<string,int>对
while (strm >> strWords) {
unordered_map<string, int>::iterator it = strMap.find(strWords);
if (it == strMap.end()) {
//容器中没有找到单词则将单词存入容器,int值设为1
strMap.insert(unordered_map<string, int>::value_type(strWords, 1));
}
else {
//容器中找到单词则相对应的int值自加1
strMap[strWords]++;
}
}
return strMap;
}
bool myFunc(const pair<string, int> &x, const pair<string, int> &y) {
//用于定义sort()函数的比较规则
if (x.second > y.second)
return true;
else if (x.second == y.second) {
if (x.first < y.first)
return true;
else
return false;
}
else if (x.second < y.second)
return false;
}
- 在统计词频的实现中,我先用unordered_map容器存储<单词,词频>对,再将数据拷贝到vector容器中,在vector容器中使用sort()函数对<单词,词频>对进行排序。使用unordered_map容器存储<单词,词频>对是因为该容器内部实现了哈希表,查找速度非常快,而每个单词都需要查找一遍容器,因此选择该容器存储<单词,词频>对。而由于unordered_map容器中使用hash组织内容,内部是无序的,所以我选择将该容器中的数据拷贝到vector容器中使用sort()函数进行排序,再根据题目要求编写比较规则即可实现排序功能。
性能改进:

消耗最大的函数代码:
void writeTxt() {
ofstream outfile("result.txt", ios::out);
if (!outfile) {
cerr << "open error!" << endl;
exit(1);
}
int t = 0;
outfile << "characters: " << characters << endl;
outfile << "words: " << words << endl;
outfile << "lines: " << lines << endl;
for (auto it = vtMap.begin(); t<10 && it != vtMap.end(); ++it, t++) {
outfile << "<" << it->first << ">: " << it->second << endl;
}
outfile.close();
}
单元测试:
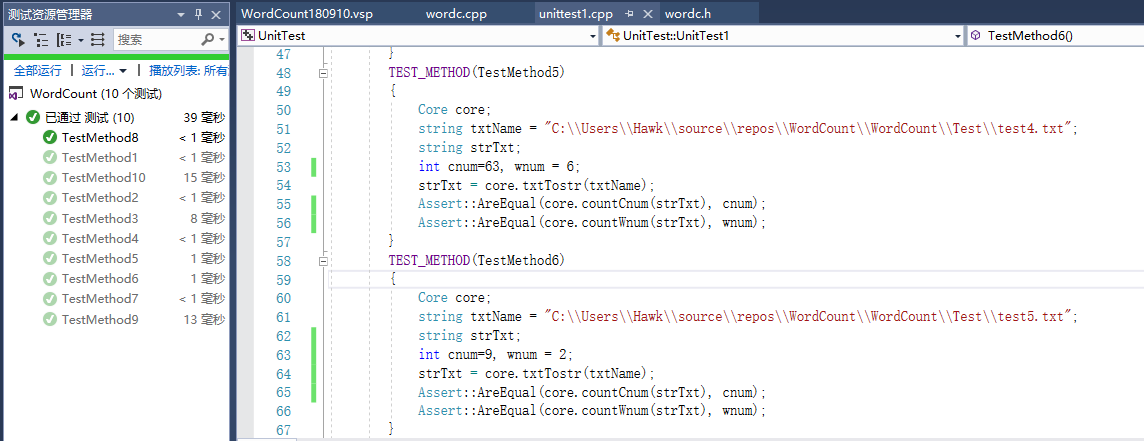
- 根据题目的要求可以测试以下情况:包含空白字符的无效行、非四个字母开头的字符串(例如:“123File”、"F1ile3"等)、大小写不同的相同单词(例如:"Window2010"和"winDows2010"等)、少于四个字母的字符串(例如:“aaa”、“dfs”等)、多个回车等;我的程序经过几次测试修改后,已经能够满足自己找到多个测试例子的要求,输出结果都是正确的,因此应该能够满足该程序的测试要求。
部分单元测试代码:
TEST_METHOD(TestMethod5)
{
Core core;
string txtName = "C:\Users\Hawk\source\repos\WordCount\WordCount\Test\test4.txt";
string strTxt;
int cnum=63, wnum = 6;
strTxt = core.txtTostr(txtName);
Assert::AreEqual(core.countCnum(strTxt), cnum);
Assert::AreEqual(core.countWnum(strTxt), wnum);
}
TEST_METHOD(TestMethod6)
{
Core core;
string txtName = "C:\Users\Hawk\source\repos\WordCount\WordCount\Test\test5.txt";
string strTxt;
int cnum=9, wnum = 2;
strTxt = core.txtTostr(txtName);
Assert::AreEqual(core.countCnum(strTxt), cnum);
Assert::AreEqual(core.countWnum(strTxt), wnum);
}
- 在单元测试中我主要测试了文本的字符数函数和单词总数函数,使用Assert的AreEqual测试字符数和单词总数是否是正确的。
代码覆盖率:

- 代码覆盖率为84%。通过观察未覆盖的代码可知,未覆盖的部分是一些if...else中未执行的分支,可知代码覆盖率还是比较合理的。
异常处理:
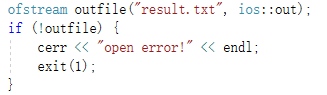
输入异常:(无法打开输入文件)

输出异常:(无法打开输出文件)
心得与收获:
- 通过本次编程作业,我才感受到这门《软件工程》课程并不是一门简单的编程实践课。如果只是简单的编程实践课,那么代码的编写便很随意了,没有接口封装的要求,只需要保证代码的可行性和正确性即可,甚至可以把代码全部放在main()函数里,但是那样的代码就显得很乱,可读性很差,所以一般我来写也会定义一些函数,将功能大致分开来写。一开始写代码的时候,我主要考虑的是代码最终功能的实现,在程序功能的分割方面做的不是很细致,这给我后面的封装和测试造成了很大的麻烦。
- 因为我基本没有类似的项目经验,一些容器的使用等项目常用工具的掌握不是很熟练,需要临时的学习和使用,所以花费了较多的时间在搜索和阅读上。但是经过这样一番学习下来,对当前项目或有用的或没有用的都看了许多,我也确实学习到了很多东西,例如vector、unordered_map容器的简单使用等。经过了实践,我对之前学习的C++的知识又进行了一番检验,有了不一样的理解。
- 对于这次编程作业,我感受得最深刻的是“规范”。拿到题目思考并有了解题思路后,并不是一股脑把代码写下去,而是要设计功能模块的划分,设计接口和函数,一步步实现代码。这样有规范地书写代码,不仅能保证代码的可读性,还能方便程序的测试和接口的封装。根据功能模块进行测试,你较快能够找到bug所在,但是如果是杂乱的代码的话,那么多次的测试出现bug可能会让你test疯掉。在进行算法优化时,只要找到相对应地模块所在便可以轻松修改代码,但如果代码的书写比较随意的话,需要修改的地方将不仅仅是一处。我感受到了不规范代码的痛苦,所以切身体会到了代码书写规范的好处,在今后的代码书写中,我将有意识地要求自己规范地书写代码,做到比较好的程度。