1、字符串定义和特点
定义:
一个个字符组成的有序的序列,是字符的集合。如: 'sadasd121da'
使用单引号、双引号、三引号引住的字符序列。
特点:
1、和数字一样都是字面常量。
2、不可变的,有序,连续空间,可迭代
3、Python3起,字符串就是Unicode类型
2、字符串的定义,初始化:
举例:
s = 'strint' s = "string" s = '''string''' s = 'hello world' s = r'hello world' # 此时的 就是普通字符 s = 'C:win t' ----> C:win t s = R"C:win t" ----> C:win t s = 'C:win\nt' ----> C:win t s = """ select * from user """
3、字符串元素的访问--下标
—字符串支持使用索引访问
sql = "select * from user where name = 'tom'"
sql[4] ------> 'c'
sql[4] = 'o' 因为字符串不可变,所以此操作抛异常
—有序的字符集合,字符序列,所以可以用for循环迭代。
for c in sql:
print(c)
print(type(c)) # <class 'str'>
—可迭代
lst = list(sql) # ['s', 'd', 'a']
4、字符串join链接******
'string'.join(iterable) ------> 返回 str
1 sql = 'welcome to beijing' 2 s = sql.join(['1','1','1']) # s = sql.join(('#','1','1')) 3 print(s) 4 5 -------> 6 '1welcome to beijing1welcome to beijing1' 7 8 9 s = ''.join(sql) 10 print(s) 11 12 -------> 13 'welcome to beijing' 14 15 s = '-'.join(sql) 16 print(s) 17 18 -------> 19 'w-e-l-c-o-m-e- -t-o- - -b-e-i-j-i-n-g' 20 21 22 lst = ['1','2','3'] 23 print('""'.join(lst)) # 1""2""3 24 print(' '.join(lst)) # 1 2 3 25 lst2 = ['1',[1,2],'3'] # [1,2]是列表,不是字符串, '[1,2]' 26 # print(' '.join(lst2)) 27 lst3 = ['1','[1,2]','3'] 28 print(' '.join(lst3)) # 1 [1,2] 3
5、字符串 + 链接
+ -----> 返回新的str(类似列表,元组)
6、比较 + 和 join 连接效率
1 # 结论:join的效率都低于 + 2 import datetime 3 4 start = datetime.datetime.now() 5 for i in range(1000000): 6 s = ''.join(['pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab','pythontab']) 7 delat = (datetime.datetime.now()- start).total_seconds() 8 print('--',delat) 9 10 start = datetime.datetime.now() 11 for i in range(1000000): 12 s = 'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab'+'pythontab' 13 delat = (datetime.datetime.now()- start).total_seconds() 14 print(delat) 15 16 website= '%s%s%s' % ('python', 'tab', '.com')
-- 0.159004 0.0624
1 # 链接次数少也是一样的结果! 2 3 import datetime 4 5 start = datetime.datetime.now() 6 for i in range(1000000): 7 s = ''.join(['pythontab','pythontab','pythontab']) 8 delat = (datetime.datetime.now()- start).total_seconds() 9 print('--',delat) 10 11 start = datetime.datetime.now() 12 for i in range(1000000): 13 s = 'pythontab'+'pythontab'+'pythontab' 14 delat = (datetime.datetime.now()- start).total_seconds() 15 print(delat) 16 17 website= '%s%s%s' % ('python', 'tab', '.com') 18 19 20 21 22 -- 0.228405 23 0.078
7、字符串分隔
分隔字符串的方法分为2类:
split系:
将字符串按照分隔符分割成若干个字符串,并返回列表。
partition 系
将字符串按照分隔符分割成两段,返回这2段和分隔符的元组
-——split
帮助文档:str.split(sep=None, maxsplit=-1) ------> 返回一个字符串列表
从左往右依次分割
sep 指定分隔符,缺省情况下空白字符串作为分隔符
maxsplit 指定分割次数,-1 表示遍历整个字符串
1 split 2 3 s1 = "Tom is a super student." 4 #s1.split() # ['Tom', 'is', 'a', 'super', 'student.'] 默认分隔符为 空白字符串 5 s2 = "Tom is a super student." 6 s2.split() # ['Tom', 'is', 'a', 'super', 'student.'] 7 s2.split('s') # ['Tom i', ' a ', 'uper ', 'tudent.'] 8 s2.split('super') # ['Tom is a ', ' student.'] 9 s2.split('super ')# ['Tom is a ', 'student.'] 10 s2.split(' ') # ['Tom', '', '', '', '', '', 'is', 'a', 'super', 'student.'] 11 s3 = "Tom is a super student." 12 s3.split(' ')# ['Tom', 'is', 'a', 'super', 'student.']s3 13 s3.split(' ',maxsplit=2) # ['Tom', 'is', 'a super student.'] 14 s3.split(' ',maxsplit=2) # ['Tom is ', 'a super student.'] 15 16 s4 = "Tom is a super student." 17 s4.split() # ['Tom', 'is', 'a', 'super', 'student.'] 注意空白字符和空格的区别 18 s4.split(' ',maxsplit=-1) # ['Tom is ', '', 'a super student.'] 19 s4.split(' ',maxsplit=1) # ['Tom is ', ' a super student.']
1 rsplit 2 3 s1 = "Tom is a super student." 4 5 s1.rsplit() # ['Tom', 'is', 'a', 'super', 'student.'] 6 s1.rsplit('s') # ['Tom i', ' a ', 'uper ', 'tudent.'] 7 s1.rsplit('super') # ['Tom is a ', ' student.'] 8 s1.rsplit(' ') # ['Tom', 'is', 'a', 'super', 'student.'] 9 s1.rsplit(' ',maxsplit=2) # ['Tom is a', 'super', 'student.'] 10 s1.rsplit(' ',maxsplit=2) # ['Tom is a ', 'super ', 'student.']
——splitlines([keepends]) ----> 字符串列表
按照行来切分字符串
keepends 指定的是保留分隔符
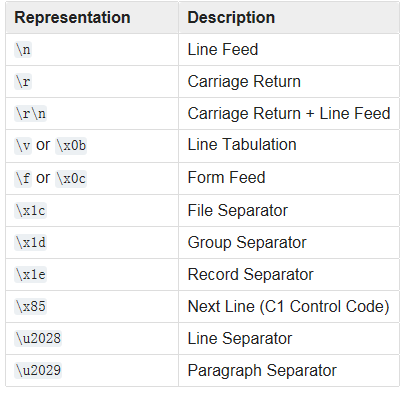
行分隔符包括 , , 等(默认的),可以自定义的行尾分隔符,当然使用此方法就不能默认了,必须指明
1 splitlines 2 3 s1 = "I'm a student. You're a teacher" 4 s1.splitlines() # ["I'm a student.", "You're a teacher"] 5 s1.splitlines(True) # ["I'm a student. ", "You're a teacher"] 6 7 s1 = "I'm a student. You're a teacher" 8 s1.splitlines() # ["I'm a student.", '', '', '', "You're a teacher"] 9 s1.splitlines(True) # ["I'm a student. ", ' ', ' ', ' ', "You're a teacher"]
——partition(sep) ----> 元组 (head,sep,tail)
从左往右,遇到分隔符就把字符串分割成两部分,返回头,分隔符,尾三部分的三元组,如果没有找到分隔符,就返回头,2个空元素的三元组。
sep 分割字符串,必须指定
1 partition rpartition 2 3 s1 = "I'm a student.s You're a teacher" 4 s1.partition('s') # ("I'm a ", 's', "tudent.s You're a teacher") 5 s1.rpartition('s')# ("I'm a student.", 's', " You're a teacher") 6 # rpartition 从右往左 7 s1.partition('stu') # ("I'm a ", 'stu', "dent.s You're a teacher") 8 s1.partition(' ') #("I'm", ' ', "a student.s You're a teacher") 9 s1.partition('_') # ("I'm a student.s You're a teacher", '', '') 10 11 s = '[1,2],[3],[4,5]' 12 s.partition('3') # ('[1,2],[', '3', '],[4,5]')
8、字符串大小写
upper():全大写 ,返回新字符串
lower():全小写,返回新字符串
swapcase():交换大小写,返回新字符串


1 In [18]: s = 'dsadasd' 2 3 In [19]: s.upper() 4 Out[19]: 'DSADASD' 5 6 In [20]: s 7 Out[20]: 'dsadasd' 8 9 In [21]: s = 'dsaD' 10 11 In [22]: s.lower() 12 Out[22]: 'dsad' 13 14 In [23]: s.swapcase() 15 Out[23]: 'DSAd'
9、字符串排版:
title() ----> 返回str,标题的每个单词都大写
capitalize() -----> 返回 str ,首个单词大写
center(width [, fillchar] ) ----> 返回str width 打印宽度, fillchar 填充的字符
zfill(width) -----> str width 是宽度
ljust(width [,fillchar]) ---> str 左对齐
rjust
10、字符串修改*
—replace(old,new[,count]) -----> str
字符串中找到匹配替换为新子串,返回新字符串
count 表示替换几次,不指定就是全部替换
1 IIn [1]: a ='www magedu com' 2 3 In [2]: a.replace('ww','p') 4 Out[2]: 'pw magedu com' 5 6 In [3]: a.replace('www','p') 7 Out[3]: 'p magedu com' 8 9 In [4]: a.replace('w','p') 10 Out[4]: 'ppp magedu com' 11 12 In [5]: a.replace('w','p',2) 13 Out[5]: 'ppw magedu com' 14 15 In [6]: a.replace('w','python',2) 16 Out[6]: 'pythonpythonw magedu com' 17 18 In [7]: a.replace('www','python',2) 19 Out[7]: 'python magedu com' 20 21 In [8]: a.replace('www','python',5) 22 Out[8]: 'python magedu com'
—strip([char]) -----> str
从字符串两端 去除指定得到字符集chars中的所有字符
如果插头上没有志宁,去除两端的空白字符。
In [10]: b = ' very very very ' In [11]: b Out[11]: ' very very very ' In [12]: b.strip()# 默认空白字符 Out[12]: 'very very very' In [13]: b.strip(' ') Out[13]: ' very very very' In [14]: b.strip(' ') Out[14]: ' very very very' In [15]: b.strip(' ') Out[15]: ' very very very' In [16]: b.strip(' y') Out[16]: ' very very ver' In [17]: b.strip(' very') Out[17]: ' ' In [18]: b.strip(' very') Out[18]: ' very very very ' In [20]: c = 'abc abc ab bc' In [21]: c.strip('abc') Out[21]: ' abc ab '
1 In [22]: a 2 Out[22]: 'www magedu com' 3 4 In [23]: a.lstrip('w') 5 Out[23]: ' magedu com' 6 7 In [24]: a.lstrip('m') 8 Out[24]: 'www magedu com'
11、字符串查找*
—find(sub [,start [, end]]) -----> int
在指定的区间,从左到右,查找子串sub,找到返回索引,找不到返回 -1
— rfind (sub [,start [, end]]) -----> int
在指定能够的区间,从右往左,查找子串sub,找到返回正索引,找不到返回-1
1 In [30]: a 2 Out[30]: 'www magedu com' 3 4 In [31]: s 5 Out[31]: 'I am very very very sorry ' 6 7 In [32]: a.find('ww') 8 Out[32]: 0 9 10 In [33]: a.find('w') 11 Out[33]: 0 12 13 In [34]: a.find('m') 14 Out[34]: 4 15 16 In [35]: a.find('m',5,-1) 17 Out[35]: -1 18 19 In [36]: a.find('m',5) 20 Out[36]: 13 21 22 In [38]: a.rfind('w') 23 Out[38]: 2 24 25 In [39]: a.rfind('ww') 26 Out[39]: 1 27 28 In [40]: a.find('ss') 29 Out[40]: -1 30 31 In [41]: a.find('m',4,10000) # end可以无限写,但是没有意义 32 Out[41]: 4
1 In [54]: s 2 Out[54]: 'I am very very very sorry' 3 4 In [55]: s.find('very',1,-1) 5 Out[55]: 5 6 7 In [56]: s.find('very',-5,-1) 8 Out[56]: -1 9 10 In [57]: s.find('very',-10,-1) 11 Out[57]: 15 12 13 In [58]: s.find('very',-1,-10) 14 Out[58]: -1 15 16 In [59]: s.rfind('very',-1,-10) 17 Out[59]: -1 18 19 总结:不论 rfind 还是 find,start都应该在end 的左侧,比如:5就在-1 的左侧,-1不在 -10 的左侧。rfind只是在区间内,找最右侧先匹配到的项。
—index(sub [,start[,end]]) ----> int ,但是找不到会抛异常,得写异常处理,所以一般很少用,选用find
**** 时间复杂度:
find 和 index 都是翻找,随着数据量增大,效率下降,都是O(n)
—len(string)跟列表,元组一样,会提供
—count(str [,start [,end]]) ----> int 时间复杂度是O(n)
在指定区间,从左往右,统计子串sub出现的次数
1 In [61]: s 2 Out[61]: 'I am very very very sorry' 3 4 In [62]: s.count('very') 5 Out[62]: 3 6 7 In [63]: s.count('very',10,-1) 8 Out[63]: 2 9 10 In [64]: s.count('very',-10,-1) 11 Out[64]: 1 12 13 In [65]: s.count('very',-1,-10) 14 Out[65]: 0
12、字符串判断*
—startswith (suffix [,start [,end]]) -----> bool ------> 可以用find 替换的
a.find('www', 0, len('www')) == 0 ------> True or False ------>好处是不抛异常
—endwith ([prefix [ ,start [, end]])----> bool
1 In [68]: s 2 Out[68]: 'I am very very very sorry' 3 4 In [69]: s.startswith('s') 5 Out[69]: False 6 7 In [70]: s.startswith('w') 8 Out[70]: False 9 10 In [71]: s.startswith('I') 11 Out[71]: True
— is 系列
isalnum() ----> bool
isalpha()
isdecimal();是否只包含十进制数字
isdigit(): 是否全部是数字
isidentifiter() :是不是字母和下划线开头,其他都是字母,数字,下划线
islower() # 遍历,还不如都转大写或小写
isupper()
isspace()
13、字符串格式化:
—字符串的格式化是一种能够凭借字符串输出样式的手段,更灵活。
join 拼接,被拼接对象是可迭代对象
+ 拼接,但是需要将非字符串转化为字符串
— printf - style formatting 来源于c语言的ptinf函数
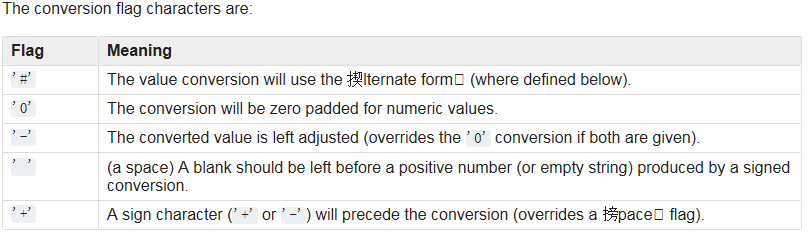
格式要求:
占位符: 使用 % 和格式字符组成,例如 %s %d等。
fornat % valuse ,格式字符串和被格式的值之间使用%分隔
values 只能是一个对象,或是一个和格式字符串占位符数目相等的元组,或一个字典。
1 https://www.cnblogs.com/post/readauth?url=/JerryZao/p/9417465.html
1 In [90]: '%.2f'% 1.23333 2 Out[90]: '1.23' 3 4 In [82]: 'i an %d' % 9 5 Out[82]: 'i an 9' 6 7 In [83]: 'i an %20d' % 9 8 Out[83]: 'i an 9' 9 10 In [84]: 'i an %-20d' % 9 11 Out[84]: 'i an 9 ' 12 13 In [85]: '%3.2f%%, 0x%x, 0X%02X' %(89.32234324,10,12) 14 Out[85]: '89.32%, 0xa, 0X0C'
1 IIn [91]: '%#x' % 10 2 Out[91]: '0xa' 3 4 In [92]: '%#X' % 10 5 Out[92]: '0XA' 6 7 In [93]: 'ox%X' % 10 8 Out[93]: 'oxA'
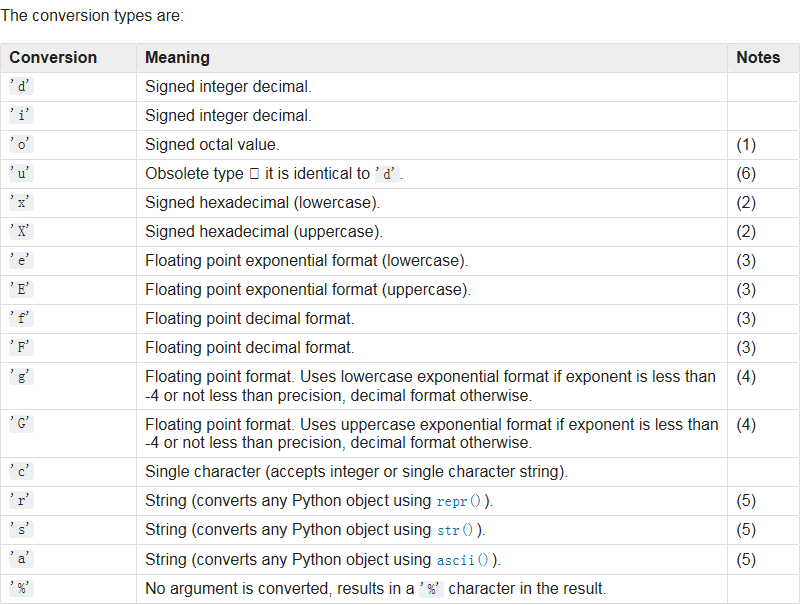
— 使用format 的格式化******
format 函数格式字符串语法----Python鼓励使用
'{} {xxx}'.format(*args, **kwargs) ------> str
args 是位置参数 ,是一个元组
kwargs 是关键字参数,是一个字典
花括号表示占位符
{} 表示按照顺序匹配位置参数,{n} 表示取位置参数索引为n 的值
{xxx} 表示在关键字参数中搜索名称一致的
{{}},表示打印花括号
对齐: In [97]: '{0}*{1}={2:<2}'.format(3,2,2*3) Out[97]: '3*2=6 ' In [98]: '{0}*{1}={2:<02}'.format(3,2,2*3) Out[98]: '3*2=60' In [99]: '{0}*{1}={2:>2}'.format(3,2,2*3) Out[99]: '3*2= 6' In [100]: '{0}*{1}={2:>02}'.format(3,2,2*3) Out[100]: '3*2=06' In [101]: '{0}*{1}={2:0>2}'.format(3,2,2*3) Out[101]: '3*2=06' In [102]: '{0}*{1}={2:0<2}'.format(3,2,2*3) Out[102]: '3*2=60' In [132]: '{:*^30}'.format('*') Out[132]: '******************************' In [124]: '{:<#3}'.format(6) Out[124]: '6 ' In [125]: '{:#<3}'.format(6) Out[125]: '6##' In [126]: '{:^3}'.format(6) Out[126]: ' 6 ' 进制: In [104]: 'int:{0:d}'.format(42) Out[104]: 'int:42' In [105]: 'int:{0:d},hex{0:x},oct{0:o}'.format(42) Out[105]: 'int:42,hex2a,oct52' In [106]: 'int:{0:d},hex{0:#x},oct{0:#o}'.format(42) Out[106]: 'int:42,hex0x2a,oct0o52' In [107]: 'int:{0:d},hex{0:#x},oct{0:#o},bin{0:b}'.format(42) Out[107]: 'int:42,hex0x2a,oct0o52,bin101010' In [108]: 'int:{0:d},hex{0:#x},oct{0:#o},bin{0:#b}'.format(42) Out[108]: 'int:42,hex0x2a,oct0o52,bin0b101010' In [134]: '{:02X}'.format(123) Out[134]: '7B' 浮点数: In [111]: print('{:g}'.format(3**0.5)) #通用精度 1.73205 In [112]: print('{:f}'.format(3**0.5)) 1.732051 In [113]: print('{:}'.format(3**0.5)) 1.7320508075688772 In [114]: print('{:10f}'.format(3**0.5)) # 右对齐,10个位置 1.732051 In [115]: print('{:2}'.format(102.231)) # 加小数位的宽度 102.231 In [116]: print('{:.2}'.format(102.231)) 1e+02 In [117]: print('{:.2}'.format(3**0.5)) # 小数点后两位 1.7 In [118]: print('{:.2f}'.format(3**0.5)) 1.73 In [119]: print('{:3.2f}'.format(3**0.5)) 1.73 In [120]: print('{:3.1f}'.format(3**0.5)) 1.7 In [121]: print('{:3.1f}'.format(0.2745)) 0.3 In [122]: print('{:3.3f}'.format(0.2745)) 0.275 In [123]: print('{:3.3%}'.format(0.2745)) 27.450% 字符串format格式化test
其他使用:https://www.cnblogs.com/post/readauth?url=/JerryZao/p/9417465.html
In [22]: aOut[22]: 'www magedu com'
In [23]: a.lstrip('w')Out[23]: ' magedu com'
In [24]: a.lstrip('m')Out[24]: 'www magedu com'