系统环境搭建:
#2.复制出来的虚拟机配置ip方法
#1.删除mac地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0
#HWADDR="00:0C:29:64:6A:F9"
#2.删除网卡和mac地址绑定的文件
rm -rf /etc/udev/rules.d/70-persistent-net.rules
#3.重启系统
reboot
系统环境初始配置: 1.配置IP vi /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE="eth0" BOOTPROTO="none" HWADDR="00:0C:29:54:E0:EF" IPV6INIT="yes" NM_CONTROLLED="yes" ONBOOT="yes" TYPE="Ethernet" IPADDR=192.168.0.18 NETMASK=255.255.255.0 GATEWAY=192.168.0.1 UUID="3a66fd1d-d033-411b-908d-7386421a281b" 2.配置hosts vi /etc/hosts 2.命名节点名称 vi /etc/sysconfig/network 4.禁用防火墙 service iptables stop chkconfig iptables off 5.配置root用户ssh免密登录 su - root cd ~ #对每个节点分别产生公钥和私钥: cd ~/.ssh ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa #将公钥文件复制保存为authorized_keys cat id_dsa.pub >> authorized_keys 6.修改vim cd ~ vi .bashrc #添加如下内容: alias vi='vim' #执行命令 source .bashrc
环境变量配置【预先配置好】
6.先把所有环境变量配好 cd /usr/local/ rm -rf * vi /etc/profile #添加如下内容最后执行source /etc/profile命令: #配置java环境变量 export JAVA_HOME=/usr/local/jdk export JAVA_BIN=$JAVA_HOME/bin export JAVA_LIB=$JAVA_HOME/lib export CLASSPATH=.:$JAVA_LIB/tools.jar:$JAVA_LIB/dt.jar #配置Python环境变量 export PYTHON_HOME=/usr/local/python2.7 #配置HADOOP环境变量 export HADOOP_HOME=/usr/local/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" #配置HIVE环境变量 export HIVE_HOME=/usr/local/hive #配置zookeeper环境变量 export ZOOKEEPER_HOME=/usr/local/zookeeper #配置hbase的环境变量 export HBASE_HOME=/usr/local/hbase #export PATH=.:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_BIN:$PATH export PATH=.:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_BIN:$PYTHON_HOME/bin:$PATH #设置时区 TZ='Asia/Shanghai' export TZ source /etc/profile
Python安装升级:
cd /software cp Python-2.7.13.tgz /usr/local/ cp get-pip.py /usr/local/ cd /usr/local/ tar -zxvf Python-2.7.13.tgz cd /usr/local/Python-2.7.13 mkdir /usr/local/python2.7 ./configure --prefix=/usr/local/python2.7 make && make install mv /usr/bin/python /usr/bin/python_old ln -s /usr/local/python2.7/bin/python2.7 /usr/bin/python #验证 python -V cd /usr/bin/ vi yum #修改第一行为: #!/usr/bin/python_old cd /software cp pip-9.0.1.tar.gz /usr/local cd /usr/local tar -zxvf pip-9.0.1.tar.gz
yum install gcc libffi-devel python-devel openssl-devel -y yum install openssl-devel yum install ncurses-devel yum install sqlite-devel yum install zlib-devel yum install bzip2-devel yum install python-devel yum -y install zlib* yum install zlibc zlib1g-dev yum install zlib yum install zlib-devel cd /usr/local wget http://pypi.python.org/packages/source/s/setuptools/setuptools-2.0.tar.gz --no-check-certificate tar zxvf setuptools-2.0.tar.gz cd setuptools-2.0 python setup.py build python setup.py install python get-pip.py pip install package numpy:数据处理; matplotlib:数据可视化; pandas:数据分析; pyserial:串口通信(注:利用pip安装的pyserial是版本3的,而在WinXP上只能使用pyserial2版本); cx_freeze:将py打包成exe文件; pip install pyquery pip install beautifulsoup pip install numpy pip install matplotlib pip install pandas:数据分析; pip install pandas pip install cx_freeze pip install lrd pip install pyserial pip install nltk pip install mlpy pip install Pygame pip install Sh pip install Peewee pip install Gooey pip install pillow pip install xlrd pip install lxml pip install configparser pip install uuid pip install msgpack-python pip install psutil pip installMySQL-Python pip install MySQL-Python pip install pymongo pip install cxOracle pip install Arrow pip install when.py pip install PIL pip install Pyquery pip install virtualenv
jdk安装
#-------------------------jdk安装----------------------------- 1.将jdk安装包jdk-8u51-linux-x64.gz上传至/usr/local/目录下 cd /software cp jdk-8u51-linux-x64.gz /usr/local cd /usr/local 2.解压jdk安装包 tar -zxvf jdk-8u51-linux-x64.gz #重命名安装包 mv jdk1.8.0_51 jdk 3.配置环境变量[前面已经配置好] vi /etc/profile export JAVA_HOME=/usr/local/jdk export JAVA_BIN=$JAVA_HOME/bin export JAVA_LIB=$JAVA_HOME/lib export CLASSPATH=.:$JAVA_LIB/tools.jar:$JAVA_LIB/dt.jar #最后将所有的路径加到 export PATH=.:$JAVA_BIN:$PATH #使环境变量生效 source /etc/profile 4.验证jdk安装是否成功 java -version
mysql安装
#-----------------------安装mysql------------------------ 1.上传mysql安装包到/usr/local目录下 cd /software cp MySQL-server-5.6.22-1.el6.x86_64.rpm MySQL-client-5.6.22-1.el6.x86_64.rpm /usr/local/ cd /usr/local 2.卸载依赖包 #查找安装了的mysql rpm -qa | grep mysql #如果有,则执行命令卸载 rpm -e mysql-libs-5.1.71-1.el6.x86_64 --nodeps 2.安装mysql rpm -ivh MySQL-client-5.6.22-1.el6.x86_64.rpm --nodeps rpm -ivh MySQL-server-5.6.22-1.el6.x86_64.rpm --nodeps 3.启动mysql服务 service mysql start 4.查看root账号密码并登陆 cat /root/.mysql_secret #CQslM7ZtrjTbwiFv #登录mysql mysql -uroot -p密码 #设置密码 mysql> SET PASSWORD = PASSWORD('root'); #测试新密码登录 mysql -uroot -proot 5设置允许远程登录 GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION; GRANT ALL PRIVILEGES ON *.* TO 'root'@'hadoop' IDENTIFIED BY 'root' WITH GRANT OPTION; flush privileges; exit; 6.设置开机自动启动 chkconfig mysql on
安装hadoop
#------------------------hadoop安装--------------------------
1.上传hadoop安装包到/usr/local目录下
cd /software
cp hadoop-2.6.0.tar.gz hadoop-native-64-2.6.0.tar /usr/local
cd /usr/local
2.解压hadoop安装包
tar -xzvf hadoop-2.6.0.tar.gz
#重命令hadoop
mv hadoop-2.6.0 hadoop
3.设置hadoop环境变量
vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop
#修改:
export PATH=.:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_BIN:$PATH
4.配置hadoop的参数
#4.1 修改hadoop-env.sh文件
#添加java_home的环境变量
cd /usr/local/hadoop/etc/hadoop
vi hadoop-env.sh
JAVA_HOME=/usr/local/jdk
#4.2 配置core-site.xml
cd /usr/local/hadoop/etc/hadoop
vi core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
<description>change your own hostname</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
#4.3 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
#4.4.配置mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop:9001</value>
<description>change your own hostname</description>
</property>
</configuration>
9.64位系统错误问题处理
##安装Hadoop启动之后总有警告:
##Unable to load native-hadoop library for your platform... using builtin-Javaclasses where applicable
##这是因为在64位的linux系统中运行hadoop不兼容。
##这时候将准备好的64位的lib包解压到已经安装好的hadoop的lib目录下
#注意:是lib目录,而不是lib下的native目录
##执行如下命令:
#tar -x hadoop-native-64-2.4.0.tar -C hadoop/lib/
cd /usr/local
cp hadoop-native-64-2.6.0.tar hadoop/lib
cd /usr/local/hadoop/lib
tar -xvf hadoop-native-64-2.6.0.tar
#然后在环境变量中添加如下内容:
vi /etc/profile
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
#最后使环境变量生效
source /etc/profile
5.对hadoop进行格式化
hadoop namenode -format
6.启动hadoop
start-all.sh
7.验证hadoop是否安装成功:
输入命令:jps
#发现有五个java进程:
DataNode
NameNode
SecondaryNameNode
JobTracker
TaskTracker
#通过浏览器查看:
HDFS:
hadoop:50070
MapReduce:
hadoop:50030
8.修改windows下的文件,即可在本地电脑查看:
C:WindowsSystem32driversetchosts
10.错误处理办法
如果在windows中页面不能成功,有肯能
NameNode进程启动没有成功?
1.没有格式化
2.配置文件
3.hostname没有与ip绑定
4.SSH的免密码登录没有配置成功
#多次格式化也是错误的
方法:删除/usr/local/hadoop/tmp文件夹,重新格式化
11.执行hdfs dfs 命令出现如下警告
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
修改etc/hadoop/log4j.properties文件,在末尾添加:
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
hive安装
1.上传hive安装包到/usr/local目录下 cd /usr/local 2.解压hive安装包 tar -zxvf hive-0.9.0.tar.gz mv hive-0.9.0 hive 3.配置hive环境变量 vi /etc/profile export HIVE_HOME=/usr/local/hive export PATH=.:$HIVE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_BIN:$PATH source /etc/profile 4.上传驱动到/usr/local目录下并添加驱动到hive的lib目录下 cd /usr/local cp mysql-connector-java-5.1.39-bin.jar /usr/local/hive/lib/ 5.hive安装参数配置 #修改hive-env.sh文件,添加hadoop的环境变量 cd /usr/local/hive/conf cp hive-env.sh.template hive-env.sh vi hive-env.sh export HADOOP_HOME=/usr/local/hadoop #修改hive-log4j.properties文件 cd /usr/local/hive/conf cp hive-log4j.properties.template hive-log4j.properties vi hive-log4j.properties #log4j.appender.EventCounter=org.apache.hadoop.metrics.jvm.EventCounter log4j.appender.EventCounter=org.apache.hadoop.log.metrics.EventCounter #修改hive-site.xml文件 cd /usr/local/hive/conf cp hive-default.xml.template hive-site.xml vi hive-site.xml #添加如下内容: <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property> 6.验证hive安装是否成功 hive show databases; mysql -uroot -proot show databases; use hive; show tables; 7.上传hive-builtins-0.9.0.jar包到hdfs的/usr/local/hive/lib/目录下 cd /usr/local/hive/lib hdfs dfs -mkdir -p /usr/local/hive/lib hdfs dfs -put hive-builtins-0.9.0.jar /usr/local/hive/lib
schematool -dbType mysql -initSchema
DB2安装
#--------------------------DB2安装-----------------------------------# 1.配置实例用户 mkdir -p /db2home groupadd -g 600 edwgadm groupadd -g 601 edwgfenc groupadd -g 602 edwgdas useradd -u 600 -g 600 -d /home/edwinst edwinst useradd -u 601 -g 601 -d /db2home/edwfenc edwfenc useradd -u 602 -g 602 -d /db2home/edwdas edwdas passwd edwinst passwd edwfenc passwd edwdas 2.创建目录 mkdir -p /db2home mkdir -p /edwpath mkdir -p /edwpath/edwinst/NODE0000 mkdir -p /edwp0 mkdir -p /edwpath/edwinst/NODE0001 mkdir -p /edwp1 mkdir -p /edwpath/edwinst/NODE0002 mkdir -p /edwp2 mkdir -p /edwpath/edwinst/NODE0003 mkdir -p /edwp3 chown -R edwinst:edwgadm /edwpath chown -R edwinst:edwgadm /edwpath/edwinst/NODE0000 chown -R edwinst:edwgadm /edwp0 chown -R edwinst:edwgadm /edwpath/edwinst/NODE0001 chown -R edwinst:edwgadm /edwp1 chown -R edwinst:edwgadm /edwpath/edwinst/NODE0002 chown -R edwinst:edwgadm /edwp2 chown -R edwinst:edwgadm /edwpath/edwinst/NODE0003 chown -R edwinst:edwgadm /edwp3 3.开启相关服务 #yum install rpcbind nfs-utils #yum install xinetd service nfs restart service sshd restart #service portmap restart service rpcbind restart service xinetd restart chkconfig --level 2345 nfs on chkconfig --level 2345 nfslock on chkconfig --level 2345 sshd on #chkconfig --level 2345 portmap on chkconfig --level 2345 rpcbind on chkconfig --level 2345 xinetd on 创建实例: cd /opt/ibm/db2/V9.7/instance ./db2icrt -s ese -u edwfenc edwinst 1.关闭内存地址随机化机制 vi /etc/sysctl.conf 增加 kernel.randomize_va_space=0 sysctl -p 2.上传db2安装包并解压安装 cd /software cp v9.7fp9_linuxx64_server.tar.gz /usr/local cd /usr/local tar -xvf v9.7fp9_linuxx64_server.tar.gz cd ./server ./db2_install #开始安装db2,选择ESE企业版安装 #安装ksh cd /software rpm -ivh ksh-20120801-33.el6.x86_64.rpm su - edwinst cd ~ #对每个节点分别产生公钥和私钥: cd ~/.ssh ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa #将公钥文件复制保存为authorized_keys cat id_dsa.pub >> authorized_keys 4.修改配置文件,添加端口号 vi /etc/services db2c_edwinst 60000/tcp DB2_edwinst 60001/tcp DB2_edwinst_1 60002/tcp DB2_edwinst_2 60003/tcp DB2_edwinst_3 60004/tcp DB2_edwinst_4 60005/tcp DB2_edwinst_END 60006/tcp 5.新建实例 cd /opt/ibm/db2/V9.7/instance ./db2icrt -s ese -u edwfenc edwinst su - edwinst vi /home/edwinst/sqllib/db2nodes.cfg(更新为一下内容) 0 hadoop 0 1 hadoop 1 2 hadoop 2 3 hadoop 3 6.设置管理参数: db2set DB2RSHCMD=/usr/bin/ssh db2set DB2CODEPAGE=1386 db2set DB2_EXTENDED_OPTIMIZATION=ON db2set DB2_ANTIJOIN=YES db2set DB2COMM=TCPIP db2set DB2_PARALLEL_IO=* db2 update dbm cfg using SVCENAME db2c_edwinst db2start 7.创建EDW数据库 db2 "CREATE DATABASE EDW AUTOMATIC STORAGE NO ON /edwpath USING CODESET GBK TERRITORY CN RESTRICTIVE" db2 connect to edw db2 "CREATE DATABASE PARTITION GROUP PDPG ON DBPARTITIONNUMS (0 to 3)" db2 "CREATE DATABASE PARTITION GROUP SDPG ON DBPARTITIONNUMS (0)" db2 "ALTER BUFFERPOOL IBMDEFAULTBP SIZE 20" db2 "CREATE BUFFERPOOL BP32K ALL DBPARTITIONNUMS SIZE 20 PAGESIZE 32K" db2 update db cfg using LOGFILSIZ 131072 LOGPRIMARY 30 LOGSECOND 5 db2 update dbm cfg using FEDERATED YES db2 force application all db2stop db2start 9.检查并建立 BUFFERPOOL #db2 ALTER BUFFERPOOL IBMDEFAULTBP SIZE 250; db2 ALTER BUFFERPOOL IBMDEFAULTBP SIZE 20; #db2 CREATE BUFFERPOOL BP32K SIZE 16384 PAGESIZE 32768; #db2 CREATE BUFFERPOOL BP32K SIZE 50 PAGESIZE 32768; #db2 CONNECT RESET; db2 -x "select BPNAME,NPAGES,PAGESIZE from syscat.bufferpools with ur" 10.设置当前会话模式 db2 set schema dainst 11.db2执行sql脚本 在命令行中执行建表语句 db2 -svtf crt_dwmm_etl_table.ddl
调度平台安装【另外一台机器】
#--------------------------调度平台安装【另外一台机器】-----------------------------------# # 安装ncompress包 yum -y install ncompress # 上传版本程序包 etldata.tar.gz # apache-tomcat-7.0.73.tar.gz job-schd-engine-0.1Silver.tar.gz JobSchd.war 至当前目录 tar xf apache-tomcat-7.0.73.tar.gz -C ./etldata/script tar xf job-schd-engine-0.1Silver.tar.gz -C ./etldata/script cp JobSchd.war ./etldata/script/apache-tomcat-7.0.73/webapps cd /etl/etldata/script/apache-tomcat-7.0.73/webapps unzip JobSchd.war -d JobSchd cd /etl/etldata/script/apache-tomcat-7.0.73/webapps/JobSchd/WEB-INF/classes vi jdbc.properties /etl/etldata/script/apache-tomcat-7.0.73/webapps cd /etl/etldata/script/apache-tomcat-7.0.73/bin ./startup.sh 浏览器访问:http://192.168.0.18:8080/JobSchd/logon.jsp 用户:admin 密码:12345678 创建联邦: db2 catalog tcpip node EDW remote hadoop server 60000 db2 catalog db EDW as EDW at node EDW db2 terminate db2 connect to EDW user edwinst using edwinst db2 create wrapper drda db2 "create server EDW1SVR type DB2/UDB version 9.7 wrapper "drda" authorization "edwinst" password "edwinst" options(NODE 'EDW',DBNAME 'EDW')" db2 "create user mapping for "dainst" server EDW1SVR options(remote_authid 'edwinst',remote_password 'edwinst')" 导入新增数据: import from '/home/isinst/tmp/1.csv'of del insert into XMETA.SRC_STU_INFO; 导入替换数据s import from '/home/isinst/tmp/1.csv'of del replace into XMETA.SRC_STU_INFO; DB2建表语句【例子】: create table XMETA.SRC_STU_INFO ( SRC_SYS_ID INTEGER NOT NULL , NAME VARCHAR(20) , SCORE INTEGER , SEX VARCHAR(10) NOT NULL ); ALTER TABLE EXT_${tab_name} SET LOCATION 'hdfs://nameservice1/etldata/input/${tab_name}/${today}'
Hbase集群安装
上传压缩包,解压,重命名
配置/usr/local/hbase/conf/hbase-env.sh
如果集群模式就设置为:true
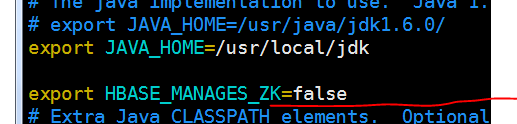
配置hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://master:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>master,slave1,slave2</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>hbase.master.info.port</name> <value>60010</value> </property> </configuration>
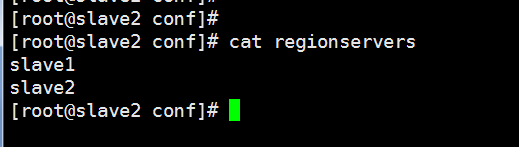
配置/usr/local/hbase/conf/regionservers
Zookeeper集群安装
上传压缩包,解压,重命名
修改conf目录下,重命名为: zoo.cfg
修改dataDir目录,然后创建该目录,并在该目录创建文件myid, 值分别为0, 1, 2

末尾添加:
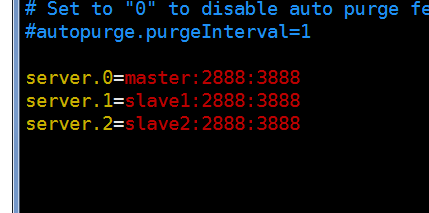
Spark安装
编辑 spark-env.sh
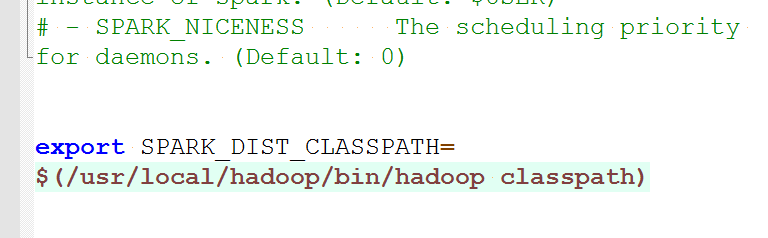
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
hive2端口监听设置
<property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>192.168.48.130</value> </property>
<property>
<name>hive.server2.webui.host</name>
<value>192.168.122.140</value>
<description>The host address the HiveServer2 WebUI will listen on</description>
</property>
<property>
<name>hive.server2.webui.port</name>
<value>10002</value>
<description>The port the HiveServer2 WebUI will listen on. This can beset to 0 o
r a negative integer to disable the web UI</description>
</property>
启动服务:
1):启动metastore
bin/hive --service metastore &
默认端口为9083
2):启动hiveserver2
bin/hive --service hiveserver2 &
3):测试
Web UI:http://192.168.48.130:10002/
flume例子
# Define a memory channel called ch1 on agent1 agent1.channels.ch1.type = memory agent1.channels.ch1.capacity = 100000 agent1.channels.ch1.transactionCapacity = 100000 agent1.channels.ch1.keep-alive = 30 # Define an Avro source called avro-source1 on agent1 and tell it # to bind to 0.0.0.0:41414. Connect it to channel ch1. #agent1.sources.avro-source1.channels = ch1 #agent1.sources.avro-source1.type = avro #agent1.sources.avro-source1.bind = 0.0.0.0 #agent1.sources.avro-source1.port = 41414 #agent1.sources.avro-source1.threads = 5 #define source monitor a file agent1.sources.avro-source1.type = exec agent1.sources.avro-source1.shell = /bin/bash -c agent1.sources.avro-source1.command = tail -n +0 -F /home/workspace/id.txt agent1.sources.avro-source1.channels = ch1 agent1.sources.avro-source1.threads = 5 # Define a logger sink that simply logs all events it receives # and connect it to the other end of the same channel. agent1.sinks.log-sink1.channel = ch1 agent1.sinks.log-sink1.type = hdfs agent1.sinks.log-sink1.hdfs.path = hdfs://192.168.88.134:9000/flumeTest agent1.sinks.log-sink1.hdfs.writeFormat = Text agent1.sinks.log-sink1.hdfs.fileType = DataStream agent1.sinks.log-sink1.hdfs.rollInterval = 0 agent1.sinks.log-sink1.hdfs.rollSize = 1000000 agent1.sinks.log-sink1.hdfs.rollCount = 0 agent1.sinks.log-sink1.hdfs.batchSize = 1000 agent1.sinks.log-sink1.hdfs.txnEventMax = 1000 agent1.sinks.log-sink1.hdfs.callTimeout = 60000 agent1.sinks.log-sink1.hdfs.appendTimeout = 60000 # Finally, now that we've defined all of our components, tell # agent1 which ones we want to activate. agent1.channels = ch1 agent1.sources = avro-source1 agent1.sinks = log-sink1
flume-ng agent --conf conf --conf-file flume.conf --name agent1 -Dflume.root.logger=INFO,console
jupyter notebook安装使用
#1.安装相关需要的工具包 pip install jupyter pip install numpy pip install matplotlib pip install scipy pip install scikit-learn pip install seaborn #2指定ip和端口打开[默认端口:8888] jupyter notebook --no-browser --port 8888 --ip=192.168.0.16 #浏览器打开指定的url #例如:http://192.168.0.16:8888/?token=ab8f641d12a9a2a90aa42cfdb36198db4d23895de8abc2b0