关键词句和文本集每篇文章相关度计算:假设语料库中有几万篇文章,每篇文章的长度不一,你任意输入关键词或句子,通过代码以tf-idf值为准检索出来相似度高的文章。
- 1、TF-IDF概述
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TFIDF实际上是:TF * IDF。TF-IDF值与该词的出现频率成正比,与在整个语料库中的出现次数成反比。
- 2、词频(TF)和逆文档频率IDF
TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。
词频 (TF)= 某个词在文章中出现的总次数/文章的总词数,TF表示词条在文档d中出现的频率。
逆文档频率(IDF) = log(词料库的文档总数/包含该词的文档数+1),为了避免分母为0,所以在分母上加1.。IDF的主要思想是:如果包含该词的文档数越少,也就是log里面分母越小,IDF越大,则说明该词具有很好的类别区分能力。
- 3、停用词和语料库(已分好词)
停用词大致分为两类。一类是人类语言中包含的功能词,这些功能词极其普遍,与其他词相比,功能词没有什么实际含义,比如'the'、'is'、'at'、'which'、'on'等。但是对于搜索引擎来说,当所要搜索的短语包含功能词,特别是像'The Who'、'The The'或'Take The'等复合名词时,停用词的使用就会导致问题。另一类词包括词汇词,比如'want'等,这些词应用十分广泛,但是对这样的词搜索引擎无法保证能够给出真正相关的搜索结果,难以帮助缩小搜索范围,同时还会降低搜索的效率,所以通常会把这些词从问题中移去,从而提高搜索性能。
该语料库每行是一篇文章,每篇文章前面是题目,后面是摘要。包含两万多篇文章,仅做测试用。
停用词表和语料库见百度云链接:链接:https://pan.baidu.com/s/1wNNUd0Pe20HFLAyuNcwDrg 密码:367d
- 4、python代码实现
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Tue Jul 31 10:57:03 2018 4 5 @author: Lenovo 6 """ 7 import jieba 8 import math 9 import numpy as np 10 11 filename = '句子相似度/title.txt'#语料库 12 filename2 = '句子相似度/stopwords.txt'#停用词表,使用的哈工大停用词表 13 14 def stopwordslist():#获取停用词表 15 stopwords = [line.strip() for line in open(filename2, encoding='UTF-8').readlines()] 16 return stopwords 17 18 stop_list = stopwordslist() 19 def get_dic_input(str): 20 dic = {} 21 22 cut = jieba.cut(str) 23 list_word = (','.join(cut)).split(',') 24 25 for key in list_word:#去除输入停用词 26 if key in stop_list: 27 list_word.remove(key) 28 29 length_input = len(list_word) 30 31 for key in list_word: 32 dic[key] = 0 33 34 return dic, length_input 35 36 def get_tf_idf(filename): 37 s = input("请输入要检索的关键词句:") 38 39 dic_input_idf, length_input = get_dic_input(s) 40 f = open(filename, 'r', encoding='utf-8') 41 list_tf = [] 42 list_idf = [] 43 word_vector1 = np.zeros(length_input) 44 word_vector2 = np.zeros(length_input) 45 46 lines = f.readlines() 47 length_essay = len(lines) 48 f.close() 49 50 for key in dic_input_idf:#计算出每个词的idf值依次存储在list_idf中 51 for line in lines: 52 if key in line.split(): 53 dic_input_idf[key] += 1 54 list_idf.append(math.log(length_essay / (dic_input_idf[key]+1))) 55 56 for i in range(length_input):#将idf值存储在矩阵向量中 57 word_vector1[i] = list_idf.pop() 58 59 for line in lines:#依次计算每个词在每行的tf值依次存储在list_tf中 60 length = len(line.split()) 61 dic_input_tf, length_input= get_dic_input(s) 62 63 for key in line.split(): 64 if key in stop_list:#去除文章中停用词 65 length -= 1 66 if key in dic_input_tf: 67 dic_input_tf[key] += 1 68 for key in dic_input_tf: 69 tf = dic_input_tf[key] / length 70 list_tf.append(tf) 71 72 for i in range(length_input):#将每行tf值存储在矩阵向量中 73 word_vector2[i] = list_tf.pop() 74 75 #print(word_vector2) 76 #print(word_vector1) 77 tf_idf = float(np.sum(word_vector2 * word_vector1)) 78 if tf_idf > 0.3:#筛选出相似度高的文章 79 print("tf_idf值:", tf_idf) 80 print("文章:", line) 81 82 get_tf_idf(filename)
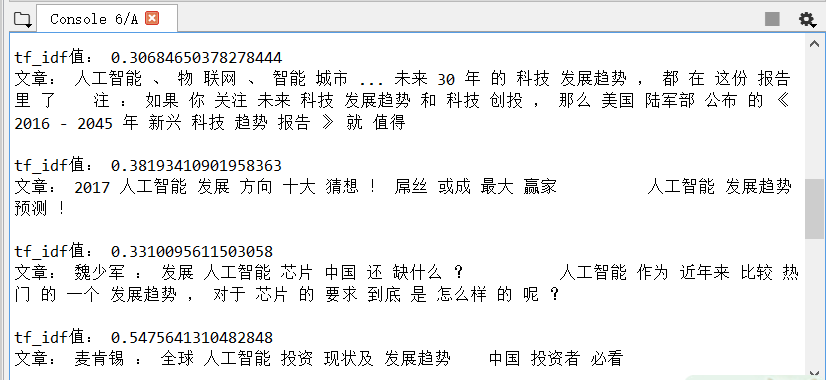
- 5、输出结果
输入:人工智能发展趋势
输出如下:输出tf-idf值大于0.3的,从两万多篇中检索出12篇