一、预备知识
URI是统一资源标识的意思,通常我们所说的URL只是URI的一种。典型URL的格式如下所示。下面提到的URL编码,实际上应该指的是URI编码。
foo://example.com:8042/over/there?name=ferret#nose
\_/ \______________/ \________/\_________/ \__/
| | | | |scheme authority path query fragment
Url编码的原则就是使用安全的字符(没有特殊用途或者特殊意义的可打印字符)去表示那些不安全的字符。
哪些字符需要编码
RFC3986文档规定,Url中只允许包含英文字母(a-zA-Z)、数字(0-9)、-_.~4个特殊字符以及所有保留字符。RFC3986文档对Url的编解码问题做出了详细的建议,指出了哪些字符需要被编码才不会引起Url语义的转变,以及对为什么这些字符需要编码做出了相应的解释。
US-ASCII字符集中没有对应的可打印字符:Url中只允许使用可打印字符。US-ASCII码中的10-7F字节全都表示控制字符,这些字符都不能直接出现在Url中。同时,对于80-FF字节(ISO-8859-1),由于已经超出了US-ACII定义的字节范围,因此也不可以放在Url中。
保留字符:Url可以划分成若干个组件,协议、主机、路径等。有一些字符(:/?#[]@)是用作分隔不同组件的。例如:冒号用于分隔协议和主机,/用于分隔主机和路径,?用于分隔路径和查询参数,等等。还有一些字符(!$&'()*+,;=)用于在每个组件中起到分隔作用的,如=用于表示查询参数中的键值对,&符号用于分隔查询多个键值对。当组件中的普通数据包含这些特殊字符时,需要对其进行编码。
RFC3986中指定了以下字符为保留字符:! * ' ( ) ; : @ & = + $ , / ? # [ ]
不安全字符:还有一些字符,当他们直接放在Url中的时候,可能会引起解析程序的歧义。这些字符被视为不安全字符,原因有很多。
- 空格:Url在传输的过程,或者用户在排版的过程,或者文本处理程序在处理Url的过程,都有可能引入无关紧要的空格,或者将那些有意义的空格给去掉。
- 引号以及<>:引号和尖括号通常用于在普通文本中起到分隔Url的作用
- #:通常用于表示书签或者锚点
- %:百分号本身用作对不安全字符进行编码时使用的特殊字符,因此本身需要编码
- {}|^[]`~:某一些网关或者传输代理会篡改这些字符
需要注意的是,对于Url中的合法字符,编码和不编码是等价的,但是对于上面提到的这些字符,如果不经过编码,那么它们有可能会造成Url语义的不同。因此对于Url而言,只有普通英文字符和数字,特殊字符$-_.+!*'()还有保留字符,才能出现在未经编码的Url之中。其他字符均需要经过编码之后才能出现在Url中。
但是由于历史原因,目前尚存在一些不标准的编码实现。例如对于~符号,虽然RFC3986文档规定,对于波浪符号~,不需要进行Url编码,但是还是有很多老的网关或者传输代理会进行编码。
二、javascript处理编码和解码的函数
1、escape()
最古老的一个就是escape()。虽然这个函数现在已经不提倡使用了,但是由于历史原因,很多地方还在使用它,所以有必要先从它讲起。
实际上,escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值。比如“春节”的返回结果是%u6625%u8282,也就是说在Unicode字符集中,“春”是第6625个(十六进制)字符,“节”是第8282个(十六进制)字符。

它的具体规则是,除了ASCII字母、数字、标点符号“@ * _ + - . /”以外,对其他所有字符进行编码。在u0000到u00ff之间的符号被转成%xx的形式,其余符号被转成%uxxxx的形式。对应的解码函数是unescape()。
所以,“Hello World”的escape()编码就是“Hello%20World”。因为空格的Unicode值是20(十六进制)。
![]()
还有两个地方需要注意。首先,无论网页的原始编码是什么,一旦被Javascript编码,就都变为unicode字符。也就是说,Javascipt函数的输入和输出,默认都是Unicode字符。这一点对下面两个函数也适用。

其次,escape()不对“+”编码。但是我们知道,网页在提交表单的时候,如果有空格,则会被转化为+字符。服务器处理数据的时候,会把+号处理成空格。所以,使用的时候要小心。
窍门:
- 采用ISO Latin字符集对指定的字符串停止编码。所有的空格符、标点符号、特殊字符以及更多有联系非ASCII字符都将被转化成%xx各式的字符编码(xx等于该字符在字符集表里面的编码的16进制数字)。比如,空格符对应的编码是%20。
- 不会被此窍门编码的字符: @ * / +
2、encodeURI()
encodeURI()是Javascript中真正用来对URL编码的函数。
它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号“; / ? : @ & = + $ , #”,也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。
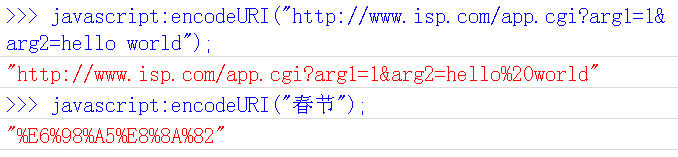
它对应的解码函数是decodeURI()。

需要注意的是,它不对单引号'编码。
窍门:
- 把URI字符串采用UTF-8编码各式转化成escape各式的字符串。
- 不会被此窍门编码的字符:! @ # $& * ( ) = : / ; ? + '
3、encodeURIComponent()
最后一个Javascript编码函数是encodeURIComponent()。与encodeURI()的区别是,它用于对URL的组成部分进行个别编码,而不用于对整个URL进行编码。
因此,“; / ? : @ & = + $ , #”,这些在encodeURI()中不被编码的符号,在encodeURIComponent()中统统会被编码。至于具体的编码方法,两者是一样。
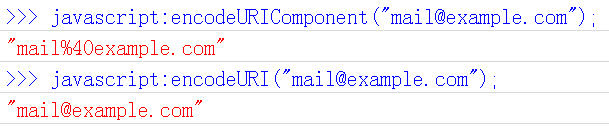
它对应的解码函数是decodeURIComponent()
窍门:
- 把URI字符串采用UTF-8编码各式转化成escape各式的字符串。与encodeURI()相比,那个窍门将对更多的字符停止编码,比如 / 等字符。所以假如字符串里面包含了URI的几个部份的话,别用那个窍门来停止编码,否则 / 字符被编码之后URL将呈现错误。
- 不会被此窍门编码的字符:! * ( ) '
代码实现
<script type="text/vbscript">
Function str2asc(strstr)
str2asc = hex(asc(strstr))
End Function
Function asc2str(ascasc)
asc2str = chr(ascasc)
End Function
</script>
<script type="text/javascript">
/*这里开始时UrlEncode和UrlDecode函数*/
function UrlEncode(str){
var ret="";
var strSpecial="!"#$%&'()*+,/:;<=>?[]^`{|}~%";
var tt= "";
for(var i=0;i<str.length;i++){
var chr = str.charAt(i);
var c=str2asc(chr);
tt += chr+":"+c+"n";
if(parseInt("0x"+c) > 0x7f){
ret+="%"+c.slice(0,2)+"%"+c.slice(-2);
}else{
if(chr==" ")
ret+="+";
else if(strSpecial.indexOf(chr)!=-1)
ret+="%"+c.toString(16);
else
ret+=chr;
}
}
return ret;
}
function UrlDecode(str){
var ret="";
for(var i=0;i<str.length;i++){
var chr = str.charAt(i);
if(chr == "+"){
ret+=" ";
}else if(chr=="%"){
var asc = str.substring(i+1,i+3);
if(parseInt("0x"+asc)>0x7f){
ret+=asc2str(parseInt("0x"+asc+str.substring(i+4,i+6)));
i+=5;
}else{
ret+=asc2str(parseInt("0x"+asc));
i+=2;
}
}else{
ret+= chr;
}
}
return ret;
}
alert(UrlDecode("%C2%D2%C2%EB"));
</script>