前言.....
文档来源于 : What problems does the actor model solve?
Actor解决了什么问题?
Akka使用Actor模型来克服传统面向对象编程模型的局限性,并应对高并发分布式系统所带来的挑战。 充分理解Actor模型是必需的,它有助于我们认识到传统的编程方法在并发和分布式计算的领域上的不足之处。
封装的弊端
面向对象编程(OOP)是一种广泛采用的,熟悉的编程模型,它的一个核心理念就是封装,并规定对象封装的内部数据不能从外部直接访问,只允许相关的属性方法进行数据操作,比如我们熟悉的Javabean中的getX,setX等方法,对象为封装的内部数据提供安全的数据操作。
举个例子,有序二叉树必须保证树节点数据的分布规则,若你想利用有序二叉树进行查询相关数据,就必须要依赖这个约束。
当我们在分析面向对象编程在运行时的行为时,我们可能会绘制一个消息序列图,用来显示方法调用时的交互,如下图所示:
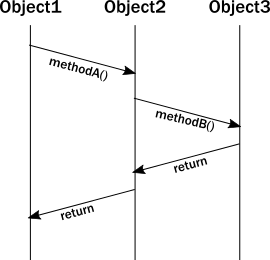
但上述图表并不能准确地表示实例在执行过程中的生命线。实际上,一个线程执行所有这些调用,并且变量的操作也在调用该方法的同一线程上。为刚才的序列图加上执行线程,看起来像这样:

但当在面对多线程的情况下,会发现此前的图越来越混乱和变得不清晰,现在我们模拟多个线程访问同一个示例:

在上面的这种情况中,两个线程调用同一个方法,但别调用的对象并不能保证其封装的数据发生了什么,两个调用的方法指令可以任意方式的交织,无法保证共享变量的一致性,现在,想象一下在更多线程下这个问题会更加严重。
解决这个问题最通常的方法就是在该方法上加锁。通过加锁可以保证同一时刻只有一个线程能进入该方法,但这是一个代价非常昂贵的方法:
-
锁非常严重的限制并发,它在现在的CPU架构上代价是非常大的,它需要操作系统暂停和重启线程。
-
调用者的线程会被阻塞,以致于它不能去做其他有意义的任务,举个例子我们希望桌面程序在后台运行的时候,操作UI界面也能得到响应。在后台,,线程阻塞完全是浪费的,有人可能会说可以通过启动新线程进行补偿,但线程也是一种非常昂贵的资源。
-
使用锁会导致一个新的问题:死锁。
这些现实存在的问题让我们只能两者选一:
-
不使用锁,但会导致状态混乱。
-
使用大量的锁,但是会降低性能并很容易导致死锁。
另外,锁只能在本地更好的利用,当我们的程序部署在不同的机器上时,我们只能选择使用分布式锁,但不幸的是,分布式锁的效率可能比本地锁低好几个量级,对后续的扩展也会有很大的限制,分布式锁的协议要求多台机器在网络上进行相互通信,因此延迟可能会变得非常高。
在面向对象语言中,我们很少会去考虑线程或者它的执行路径,我们通常将系统想象成许多实例对象连接成的网络,通过方法调用,修改实例对象内部的状态,然后通过实例对象之前的方法调用驱动整个程序进行交互:

然后,在多线程分布式环境中,实际上线程是通过方法调用遍历这个对象实例网络。因此,线程是方法调用驱动执行的:

总结:
-
对象只能保证在单一线程中封装数据的正确性,在多线程环境下可能会导致状态混乱,在同一个代码段,两个竞争的线程可能导致变量的不一致。
-
使用锁看起来可以在多线程环境下保证封装数据的正确性,但实际上它在程序真是运行时是低效的并且很容易导致死锁。
-
锁在单机工作可能还不错,但是在分布式的环境表现的很不理想,扩展性很差。
共享内存在现代计算机架构上的弊端
在80-90年代的编程模型概念中,写一个变量相当于直接把它写入内存,但是在现代的计算机架构中,我们做了一些改变,写入相应的缓存中而不是直接写入内存,大多数缓存都是CPU核心的本地缓存,但是由一个CPU写入的缓存对其他CPU是不可见的。为了让本地缓存的变化对其他CPU或者线程可见的话,缓存必须进行交互。
在JVM上,我们必须使用volatile标识或者Atomic包装类来保证内存对跨线程的共享,否则,我们只能用锁来保证共享内存的正确性。那么我们为什么不在所有的变量上都加volatile标识呢?因为在缓存间交互信息是一个代价非常昂贵的操作,而且这个操作会隐式的阻止CPU核心不能去做其他的工作,并且会导致缓存一致性协议(缓存一致性协议是指CPU用于在主内存和其他CPU之间传输缓存)的瓶颈。
即使开发者认识到这些问题,弄清楚哪些内存位置需要使用volatile标识或者Atomic包装类,但这并非是一种很好的解决方案,可能到程序后期,你都不清楚自己做了什么。
总结:
-
没有真正的共享内存了,CPU核心就像网络上的计算机一样,将数据块(高速缓存行)明确地传递给彼此。CPU间的通信和网络通信有更多的共同点。 现在通过CPU或网络计算机传递消息是标准的。
-
使用共享内存标识或者Atomic数据结构来代替隐藏消息传递,其实有一种更加规范的方法就是将共享状态保存在并发实体内,并明确并发实体间通过消息来传递事件和数据。
调用堆栈的弊端
今天,我们还经常调用堆栈来进行任务执行,但是它是在并发并不那么重要的时代发明的,因为当时多核的CPU系统并不常见。调用堆栈不能跨线程,所以不能进行异步调用。
线程在将任务委托后台执行会出现一个问题,实际中,是将任务委托给另一个线程执行,这不是简单的方法调用,而是有本地的线程直接调用执行,通常来说,一个调用者线程将任务添加到一个内存位置中,具体的工作线程可以不断的从中选取任务进行执行,这样的话,调用者线程不必阻塞可以去做一些其他的任务了。
但是这里有几个问题,第一个就是调用者如何受到任务完成的通知?还有一个更重要的问题是当任务发生异常出现错误后,异常会被谁处理?异常将会被具体执行任务的工作线程所处理并不会关心是哪个调用者调用的任务:

这是一个很严重的问题,具体执行任务的线程是怎么处理这种状况的?具体执行任务去处理这个问题并不是一个好的方案,因为它并不清楚该任务执行的真正目的,而且调用者应该被通知发生了什么,但是实际上并没有这样的结构去解决这个问题。假如并不能正确的通知,调用者线程将不会的到任何错误的信息甚至任务都会丢失。这就好比在网络上你的请求失败或者消息丢失却得不到任何的通知。
在某些情况,这个问题可能会变得更糟糕,工作线程发生了错误但是其自身却无法恢复。比如一个由bug引起的内部错误导致了线程的关闭,那么会导致一个问题,到底应该由谁来重启线程并且保存线程之前的状态呢?表面上看,这个问题是可以解决的,但又会有一个新的意外可能发生,当工作线程正在执行任务的时候,它便不能共享任务队列,而事实上,当一个异常发生后,并逐级上传,最终可能导致整个任务队列的状态全部丢失。所以说即使我们在本地交互也可能存在消息丢失的情况。
总结:
-
实现任何一个高并发且高效性能的系统,线程必须将任务有效率的委托给别的线程执行以至不会阻塞,这种任务委托的并发方式在分布式的环境也适用,但是需要引入错误处理和失败通知等机制。失败成为这种领域模型的一部分。
-
并发系统适用任务委托机制需要去处理服务故障也就意味需要在发生故障后去恢复服务,但实际情况下,重启服务可能会丢失消息,即使没有发生这种情况,调用者得到的回应也可能因为队列等待,垃圾回收等影响而延迟,所以,在真正的环境中,我们需要设置请求回复的超时时间,就像在网络系统亦或者分布式系统。
为什么在高并发,分布式系统需要Actor模型?
综上所述,通常的编程模型并不适用现代的高并发分布式系统,幸运的是,我们可以不必抛弃我们了解的知识,另外,Actor用很好的方式帮我们克服了这些问题,它让我们以一种更好的模型去实现我们的系统。
我们重点需求的是以下几个方面:
-
使用封装,但是不使用锁。
-
构建一种实体能够处理消息,更改状态,发送消息用来推动整个程序运行。
-
不必担心程序执行与真实环境的不匹配。
Actor模型能帮我们实现这些目标,以下是具体描述。
使用消息机制避免使用锁以防止阻塞
不同于方法调用,Actor模型使用消息进行交互。发送消息的方式不会将发送消息方的执行线程转换为具体的任务执行线程。Actor可以不断的发送和接收消息但不会阻塞。因此它可以做更多的工作,比如发送消息和接收消息。
在面对对象编程上,直到一个方法返回后,才会释放对调用者线程的控制。在这这一方面上,Actor模型跟面对对象模型类似,它对消息做出处理,并在消息处理完成后返回执行。我们可以模拟这种执行模式:

但是这种方式与方法调用方式最大的区别就是没有返回值。通过发送消息,Actor将任务委托给另一Actor执行。就想我们之前说的堆栈调用一样,加入你需要一个返回值,那么发送Actor需要阻塞或者与具体执行任务的Actor在同一个线程中。另外,接收Actor以消息的方式返回结果。
第二个关键的变化是继续保持封装。Actor对消息处理就就跟调用方法一样,但是不同的是,Actor在多线程的情况下能保证自身内部的状态和变量不会被破坏,Actor的执行独立于发送消息的Actor,并且同一个Actor在同一个时刻只处理一个消息。每个Actor有序的处理接收的消息,所以一个Actor系统中多个Actor可以并发的处理自己的消息,充分的利用多核CPU。因为一个Actor同一时刻最多处理一个消息,所以它不需要同步机制保障变量的一致性。所以说它并不需要锁:

总而言之,Actor执行的时候会发生以下行为:
1.Actor将消息加入到消息队列的尾部。 2.假如一个Actor并未被调度执行,则将其标记为可执行。 3.一个(对外部不可见)调度器对Actor的执行进行调度。 4.Actor从消息队列头部选择一个消息进行处理。 5.Actor在处理过程中修改自身的状态,并发送消息给其他的Actor。 6.Actor
为了实现这些行为,Actor必须有以下特性:
- 邮箱(作为一个消息队列)
- 行为(作为Actor的内部状态,处理消息逻辑)
- 消息(请求Actor的数据,可看成方法调用时的参数数据)
- 执行环境(比如线程池,调度器,消息分发机制等)
- 位置信息(用于后续可能会发生的行为)
消息会被添加到Actor的信箱中,Actor的行为可以看成Actor是如何对消息做出回应的(比如发送更多消息或者修改自身状态)。执行环境提供一组线程池,用于执行Actor的这些行为操作。
Actor是一个非常简单的模型而且它可以解决先前提到的问题:
-
继续使用封装,但通过信号机制保障不需传递执行(方法调用需要传递执行线程,但发送消息不需要)。
-
不需要任何的锁,修改Actor内部的状态只能通过消息,Actor是串行处理消息,可以保障内部状态和变量的正确性。
-
因为不会再任何地方使用锁,所以发送者不会被阻塞,成千上万个Actor可以被合理的分配在几十个线程上执行,充分利用了现代CPU的潜力。任务委托这个模式在Actor上非常适用。
-
Actor的状态是本地的,不可共享的,变化和数据只能通过消息传递。
Actor优雅的处理错误
Actor不再使用共享的堆栈调用,所以它要以不同的方式去处理错误。这里有两种错误需要考虑:
-
第一种情况是当任务委托后再目标Actor上由于任务本身错误而失败了(典型的如验证错误,比如不存在的用户ID)。在这个情况下,Actor服务本身是正确的,只是相应的任务出错了。服务Actor应该想发送Actor发送消息,已告知错误情况。这里没什么特殊的,错误作为Actor模型的一部分,也可以当做消息。
-
第二种情况是当服务本身遇到内部故障时。Akka强制所有Actor被组织成一个树状的层次结构,即创建另一个Actor的Actor成为该新Actor的分级。 这与操作系统将流程组合到树中非常相似。就像进程一样,当一个Actor失败时,它的父actor被通知,并对失败做出反应。此外,如果父actor停止,其所有子Actor也被递归停止。这中形式被称为监督,它是Akka的核心:

监管者可以根据被监管者(子Actor)的失败的错误类型来执行不同的策略,比如重启该Actor或者停止该Actor让其它Actor代替执行任务。一个Actor不会无缘无故的死亡(除非出现死循环之类的情况),而是失败,并可以将失败传递给它的监管者让其做出相应的故障处理策略,当然也可能会被停止(若被停止,也会接收到相应的消息指令)。一个Actor总有监管者就是它的父级Actor。Actor重新启动是不可见的,协作Actor可以帮其代发消息直到目标Actor重启成功。