1. 迭代器
迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退。另外,迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件。
特点:
a)访问者不需要关心迭代器内部的结构,仅需通过next()方法或不断去取下一个内容
b)不能随机访问集合中的某个值 ,只能从头到尾依次访问
c)访问到一半时不能往回退
d)便于循环比较大的数据集合,节省内存
e)也不能复制一个迭代器。如果要再次(或者同时)迭代同一个对象,只能去创建另一个迭代器对象。enumerate()的返回值就是一个迭代器,我们以enumerate为例:

a = enumerate(['a','b'])
for i in range(2): #迭代两次enumerate对象
for x, y in a:
print(x,y)
print(''.center(50,'-'))
结果:
0 a 1 b -------------------------------------------------- --------------------------------------------------
可以看到再次迭代enumerate对象时,没有返回值;
我们可以用linux的文件处理命令vim和cat来理解一下:
a) 读取很大的文件时,vim需要很久,cat是毫秒级;因为vim是一次性把文件全部加载到内存中读取;而cat是加载一行显示一行
b) vim读写文件时可以前进,后退,可以跳转到任意一行;而cat只能向下翻页,不能倒退,不能直接跳转到文件的某一页(因为读取的时候这个“某一页“可能还没有加载到内存中)
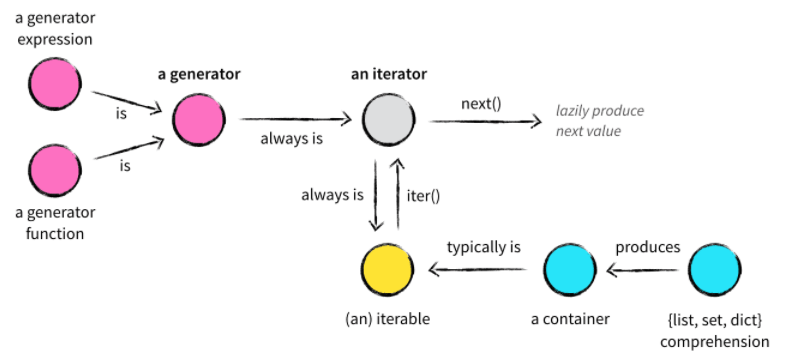
正式进入python迭代器之前,我们先要区分两个容易混淆的概念:可迭代对象和迭代器;
可以直接作用于for循环的对象统称为可迭代对象(Iterable)。
可以被next()函数调用并不断返回下一个值的对象称为迭代器(Iterator)。
所有的Iterable均可以通过内置函数iter()来转变为Iterator。
1)可迭代对象
首先,迭代器是一个对象,不是一个函数;是一个什么样的对象呢?就是只要它定义了可以返回一个迭代器的__iter__方法,或者定义了可以支持下标索引的__getitem__方法,那么它就是一个可迭代对象。
python中大部分对象都是可迭代的,比如list,tuple等。如果给一个准确的定义的话,看一下list,tuple类的源码,都有__iter__(self)方法。
常见的可迭代对象:
a) 集合数据类型,如list、tuple、dict、set、str等;
b) generator,包括生成器和带yield的generator function。
注意:生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator,关于生成器,继续往下看
如何判断一个对象是可迭代对象呢?可以通过collections模块的Iterable类型判断:
>>> from collections import Iterable
>>> isinstance([], Iterable)
True
>>> isinstance({}, Iterable)
True
>>> isinstance('abc', Iterable)
True
>>> isinstance((x for x in range(10)), Iterable)
True
>>> isinstance(100, Iterable)
False
2)迭代器
一个可迭代对象是不能独立进行迭代的,Python中,迭代是通过for ... in来完成的。
for循环在迭代一个可迭代对象的过程中都做了什么呢?
a)当for循环迭代一个可迭代对象时,首先会调用可迭代对象的__iter__()方法,然我们看看源码中关于list类的__iter__()方法的定义:
def __iter__(self, *args, **kwargs): # real signature unknown
""" Implement iter(self). """
pass
__iter__()方法调用了iter(self)函数,我们再来看一下iter()函数的定义:
def iter(source, sentinel=None): # known special case of iter
"""
iter(iterable) -> iterator
iter(callable, sentinel) -> iterator
Get an iterator from an object. In the first form, the argument must
supply its own iterator, or be a sequence.
In the second form, the callable is called until it returns the sentinel.
"""
pass
iter()函数的参数是一个可迭代对象,最终返回一个迭代器
b) for循环会不断调用迭代器对象的__next__()方法(python2.x中是next()方法),每次循环,都返回迭代器对象的下一个值,直到遇到StopIteration异常。
>>> lst_iter = iter([1,2,3]) >>> lst_iter.__next__() 1 >>> lst_iter.__next__() 2 >>> lst_iter.__next__() 3 >>> lst_iter.__next__() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>>
这里注意:这里的__next__()方法和内置函数next(iterator, default=None)不是一个东西;(内置函数next(iterator, default=None)也可以返回迭代器的下一个值)
c) 而for循环可以捕获StopIteration异常并结束循环;
总结一下:
a)for....in iterable,会通过调用iter(iterable)函数(实际上,首先调用的对象的__iter__()方法),返回一个迭代器iterator;
b)每次循环,调用一次对象的__next__(self),直到最后一个值,再次调用会触发StopIteration
c)for循环捕捉到StopIteration,从而结束循环
上面说了这么多,到底什么是迭代器Iterator呢?
任何实现了__iter__和__next__()(python2中实现next())方法的对象都是迭代器,__iter__返回迭代器自身,__next__返回容器中的下一个值;
既然知道了什么迭代器,那我们自定义一个迭代器玩玩:
 View Code
View Code如何判断一个对象是一个迭代器对象呢?两个方法:
1)通过内置函数next(iterator, default=None),可以看到next的第一个参数必须是迭代器;所以迭代器也可以认为是可以被next()函数调用的对象
2)通过collection中的Iterator类型判断
>>> from collections import Iterator >>> >>> isinstance([1,2,3], Iterator) False >>> isinstance(iter([1,2,3]), Iterator) True >>> isinstance([1,2,3].__iter__(), Iterator) True >>>
这里大家会不会有个疑问:
对于迭代器而言,看上去作用的不就是__next__方法嘛,__iter__好像没什么卵用,干嘛还需要__iter__方法呢?
我们知道,python中迭代是通过for循环实现的,而for循环的循环对象必须是一个可迭代对象Iterable,而Iterable必须是一个实现了__iter__方法的对象;知道为什么需要__iter__魔术方法了吧;
那么我就是想自定义一个没有实现__iter__方法的迭代器可以吗?可以,像下面这样:
View Code先定义一个可迭代对象(包含__iter__方法),然后该对象返回一个迭代器;这样看上去是不是很麻烦?是不是同时带有__iter__和__next__魔术方法的迭代器更好呢!
同时,这里要纠正之前的一个迭代器概念:只要__next__()(python2中实现next())方法的对象都是迭代器;
既然这样,只需要迭代器Iterator接口就够了,为什么还要设计可迭代对象Iterable呢?
这个和迭代器不能重复使用有关,下面同意讲解:
3)总结和一些重要知识点
a) 如何复制迭代器
之前在使用enumerate时,我们说过enumerate对象通过for循环迭代一次后就不能再被迭代:
>>> e = enumerate([1,2,3]) >>> >>> for x,y in e: ... print(x,y) ... 0 1 1 2 2 3 >>> for x,y in e: ... print(x,y) ... >>>
这是因为enumerate是一个迭代器;
迭代器是一次性消耗品,当循环以后就空了。不能再次使用;通过深拷贝可以解决;
>>> import copy >>> >>> e = enumerate([1,2,3]) >>> >>> e_deepcopy = copy.deepcopy(e) >>> >>> for x,y in e: ... print(x,y) ... 0 1 1 2 2 3 >>> for x,y in e_deepcopy: ... print(x,y) ... 0 1 1 2 2 3 >>>
b)为什么不只保留Iterator的接口而还需要设计Iterable呢?
因为迭代器迭代一次以后就空了,那么如果list,dict也是一个迭代器,迭代一次就不能再继续被迭代了,这显然是反人类的;所以通过__iter__每次返回一个独立的迭代器,就可以保证不同的迭代过程不会互相影响。而生成器表达式之类的结果往往是一次性的,不可以重复遍历,所以直接返回一个Iterator就好。让Iterator也实现Iterable的兼容就可以很灵活地选择返回哪一种。
总结说,Iterator实现的__iter__是为了兼容Iterable的接口,从而让Iterator成为Iterable的一种实现。
另外,迭代器是惰性的,只有在需要返回下一个数据时它才会计算。就像一个懒加载的工厂,等到有人需要的时候才给它生成值返回,没调用的时候就处于休眠状态等待下一次调用。所以,Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
c)通过__getitem__来实现for循环
前面关于可迭代对象的定义是这样的:定义了可以返回一个迭代器的__iter__方法,或者定义了可以支持下标索引的__getitem__方法,那么它就是一个可迭代对象。
但是如果对象没有__iter__,但是实现了__getitem__,会改用下标迭代的方式。
class NoIterable(object):
def __init__(self, data):
self.data = data
def __getitem__(self, item):
return self.data[item]
no_iter = NoIterable('abcde')
for item in no_iter:
print(item)
 View Code
View Code2. 生成器
理解了迭代器以后,生成器就会简单很多,因为生成器其实是一种特殊的迭代器。不过这种迭代器更加优雅。它不需要再像上面的类一样写__iter__()和__next__()方法了,只需要一个yiled关键字。 生成器一定是迭代器(反之不成立),因此任何生成器也是以一种懒加载的模式生成值。
语法上说,生成器函数是一个带yield关键字的函数。
调用生成器函数后会得到一个生成器对象,这个生成器对象实际上就是一个特殊的迭代器,拥有__iter__()和__next__()方法
我们先用一个例子说明一下:
>>> def generator_winter(): ... i = 1 ... while i <= 3: ... yield i ... i += 1 ... >>> generator_winter <function generator_winter at 0x000000000323B9D8> >>> generator_iter = generator_winter() >>> generator_iter <generator object generator_winter at 0x0000000002D9CAF0> >>> >>> generator_iter.__next__() 1 >>> generator_iter.__next__() 2 >>> generator_iter.__next__() 3 >>> generator_iter.__next__() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>>
现在解释一下上面的代码:
a)首先我们创建了一个含有yield关键字的函数generator_winter,这是一个生成器函数
b)然后,我们调用了这个生成器函数,并且将返回值赋值给了generator_iter,generator_iter是一个生成器对象;注意generator_iter = generator_winter()时,函数体中的代码并不会执行,只有显示或隐示地调用next的时候才会真正执行里面的代码。
c)生成器对象就是一个迭代器,所以我们可以调用对象的__next__方法来每次返回一个迭代器的值;迭代器的值通过yield返回;并且迭代完最后一个元素后,触发StopIteration异常;
既然生成器对象是一个迭代器,我们就可以使用for循环来迭代这个生成器对象:
>>> def generator_winter(): ... i = 1 ... while i <= 3: ... yield i ... i += 1 ... >>> >>> for item in generator_winter(): ... print(item) ... 1 2 3 >>>
我们注意到迭代器不是使用return来返回值,而是采用yield返回值;那么这个yield有什么特别之处呢?
1)yield
我们知道,一个函数只能返回一次,即return以后,这次函数调用就结束了;
但是生成器函数可以暂停执行,并且通过yield返回一个中间值,当生成器对象的__next__()方法再次被调用的时候,生成器函数可以从上一次暂停的地方继续执行,直到触发一个StopIteration
上例中,当执行到yield i后,函数返回i值,然后print这个值,下一次循环,又调用__next__()方法,回到生成器函数,并从yield i的下一句继续执行;
摘一段<python核心编程>的内容:
生成器的另外一个方面甚至更加强力----协同程序的概念。协同程序是可以运行的独立函数调用,可以暂停或者挂起,并从程序离开的地方继续或者重新开始。在有调用者和(被调用的)协同程序也有通信。举例来说,当协同程序暂停时,我们仍可以从其中获得一个中间的返回值,当调用回到程序中时,能够传入额外或者改变了的参数,但是仍然能够从我们上次离开的地方继续,并且所有状态完整。挂起返回出中间值并多次继续的协同程序被称为生成器,那就是python的生成真正在做的事情。这些提升让生成器更加接近一个完全的协同程序,因为允许值(和异常)能传回到一个继续的函数中,同样的,当等待一个生成器的时候,生成器现在能返回控制,在调用的生成器能挂起(返回一个结果)之前,调用生成器返回一个结果而不是阻塞的等待那个结果返回。
2) 什么情况会触发StopIteration
两种情况会触发StopIteration
a) 如果没有return,则默认执行到函数完毕时返回StopIteration;
b) 如果在执行过程中 return,则直接抛出 StopIteration 终止迭代;
c) 如果在return后返回一个值,那么这个值为StopIteration异常的说明,不是程序的返回值。
>>> def generator_winter(): ... yield 'hello world' ... return 'again' ... >>> >>> winter = generator_winter() >>> winter.__next__() 'hello world' >>> winter.__next__() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration: again >>>
3) 生成器的作用
说了这么多,生成器有什么用呢?作为python主要特性之一,这是个极其牛逼的东西,由于它是惰性的,在处理大型数据时,可以节省大量内存空间;
当你需要迭代一个巨大的数据集合,比如创建一个有规律的100万个数字,如果采用列表来存储访问,那么会占用大量的内存空间;而且如果我们只是访问这个列表的前几个元素,那么后边大部分元素占据的内存空间就白白浪费了;这时,如果采用生成器,则不必创建完整的列表,一次循环返回一个希望得到的值,这样就可以大量节省内存空间;
这里在举例之前,我们先介绍一个生成器表达式(类似于列表推导式,只是把[]换成()),这样就创建了一个生成器。
>>> gen = (x for x in range(10)) >>> gen <generator object <genexpr> at 0x0000000002A923B8> >>>
生成器表达式的语法如下:
(expr for iter_var in iterable if cond_expr)
用生成器来实现斐波那契数列
View Code4)生成器方法
直接看生成器源代码
class __generator(object):
'''A mock class representing the generator function type.'''
def __init__(self):
self.gi_code = None
self.gi_frame = None
self.gi_running = 0
def __iter__(self):
'''Defined to support iteration over container.'''
pass
def __next__(self):
'''Return the next item from the container.'''
pass
def close(self):
'''Raises new GeneratorExit exception inside the generator to terminate the iteration.'''
pass
def send(self, value):
'''Resumes the generator and "sends" a value that becomes the result of the current yield-expression.'''
pass
def throw(self, type, value=None, traceback=None):
'''Used to raise an exception inside the generator.'''
pass
首先看到了生成器是自带__iter__和__next__魔术方法的;
a)send
生成器函数最大的特点是可以接受外部传入的一个变量,并根据变量内容计算结果后返回。这是生成器函数最难理解的地方,也是最重要的地方,协程的实现就全靠它了。
看一个小猫吃鱼的例子:
def cat():
print('我是一只hello kitty')
while True:
food = yield
if food == '鱼肉':
yield '好开心'
else:
yield '不开心,人家要吃鱼肉啦'
中间有个赋值语句food = yield,可以通过send方法来传参数给food,试一下:
情况1)
miao = cat() #只是用于返回一个生成器对象,cat函数不会执行
print(''.center(50,'-'))
print(miao.send('鱼肉'))
结果:
Traceback (most recent call last):
--------------------------------------------------
File "C:/Users//Desktop/Python/cnblogs/subModule.py", line 67, in <module>
print(miao.send('鱼肉'))
TypeError: can't send non-None value to a just-started generator
看到了两个信息:
a)miao = cat() ,只是用于返回一个生成器对象,cat函数不会执行
b)can't send non-None value to a just-started generator;不能给一个刚创建的生成器对象直接send值
改一下
情况2)
miao = cat()
miao.__next__()
print(miao.send('鱼肉'))
结果:
我是一只hello kitty 好开心
没毛病,那么到底send()做了什么呢?send()的帮助文档写的很清楚,'''Resumes the generator and "sends" a value that becomes the result of the current yield-expression.''';可以看到send依次做了两件事:
a)回到生成器挂起的位置,继续执行
b)并将send(arg)中的参数赋值给对应的变量,如果没有变量接收值,那么就只是回到生成器挂起的位置
但是,我认为send还做了第三件事:
c)兼顾__next__()作用,挂起程序并返回值,所以我们在print(miao.send('鱼肉'))时,才会看到'好开心';其实__next__()等价于send(None)
所以当我们尝试这样做的时候:
1 def cat():
2 print('我是一只hello kitty')
3 while True:
4 food = yield
5 if food == '鱼肉':
6 yield '好开心'
7 else:
8 yield '不开心,人家要吃鱼肉啦'
9
10 miao = cat()
11 print(miao.__next__())
12 print(miao.send('鱼肉'))
13 print(miao.send('骨头'))
14 print(miao.send('鸡肉'))
就会得到这个结果:
我是一只hello kitty None 好开心 None 不开心,人家要吃鱼肉啦
我们按步骤分析一下:
a)执行到print(miao.__next__()),执行cat()函数,print了”我是一只hello kitty”,然后在food = yield挂起,并返回了None,打印None
b)接着执行print(miao.send('鱼肉')),回到food = yield,并将'鱼肉’赋值给food,生成器函数恢复执行;直到运行到yield '好开心',程序挂起,返回'好开心',并print'好开心'
c)接着执行print(miao.send('骨头')),回到yield '好开心',这时没有变量接收参数'骨头',生成器函数恢复执行;直到food = yield,程序挂起,返回None,并print None
d)接着执行print(miao.send('鸡肉')),回到food = yield,并将'鸡肉’赋值给food,生成器函数恢复执行;直到运行到yield'不开心,人家要吃鱼肉啦',程序挂起,返回'不开心,人家要吃鱼肉啦',,并print '不开心,人家要吃鱼肉啦'
大功告成;那我们优化一下代码:
1 def cat():
2 msg = '我是一只hello kitty'
3 while True:
4 food = yield msg
5 if food == '鱼肉':
6 msg = '好开心'
7 else:
8 msg = '不开心,人家要吃鱼啦'
9
10 miao = cat()
11 print(miao.__next__())
12 print(miao.send('鱼肉'))
13 print(miao.send('鸡肉'))
我们再看一个更实用的例子,一个计数器
def counter(start_at = 0):
count = start_at
while True:
val = (yield count)
if val is not None:
count = val
else:
count += 1
count = counter(5)
print(count.__next__())
print(count.__next__())
print(count.send(0))
print(count.__next__())
print(count.__next__())
结果:
5 6 0 1 2
b)close
帮助文档:'''Raises new GeneratorExit exception inside the generator to terminate the iteration.'''
手动关闭生成器函数,后面的调用会直接返回StopIteration异常
>>> def gene(): ... while True: ... yield 'ok' ... >>> g = gene() >>> g.__next__() 'ok' >>> g.__next__() 'ok' >>> g.close() >>> g.__next__() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>>
在close以后再执行__next__会触发StopIteration异常
c)throw
用来向生成器函数送入一个异常,throw()后直接抛出异常并结束程序,或者消耗掉一个yield,或者在没有下一个yield的时候直接进行到程序的结尾。
>>> def gene(): ... while True: ... try: ... yield 'normal value' ... except ValueError: ... yield 'we got ValueError here' ... except TypeError: ... break ... >>> g = gene() >>> print(g.__next__()) normal value >>> print(g.__next__()) normal value >>> print(g.throw(ValueError)) we got ValueError here >>> print(g.__next__()) normal value >>> print(g.throw(TypeError)) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>>
5)通过yield实现单线程情况下的异步并发效果
def consumer(name):
print('%s准备吃包子了' % name)
while True:
baozi_name = yield
print('[%s]来了,被[%s]吃了'% (baozi_name, name))
def producer(*name):
c1 = consumer(name[0])
c2 = consumer(name[1])
c1.__next__()
c2.__next__()
for times in range(5):
print('做了两个包子')
c1.send('豆沙包%s'%times)
c2.send('菜包%s'%times)
producer('winter', 'elly')
效果:
winter准备吃包子了 elly准备吃包子了 做了两个包子 [豆沙包0]来了,被[winter]吃了 [菜包0]来了,被[elly]吃了 做了两个包子 [豆沙包1]来了,被[winter]吃了 [菜包1]来了,被[elly]吃了 做了两个包子 [豆沙包2]来了,被[winter]吃了 [菜包2]来了,被[elly]吃了 做了两个包子 [豆沙包3]来了,被[winter]吃了 [菜包3]来了,被[elly]吃了 做了两个包子 [豆沙包4]来了,被[winter]吃了 [菜包4]来了,被[elly]吃了
创建了两个独立的生成器,很有趣,很吊;
6)补充几个小例子:
a)使用生成器创建一个range
def range(n):
count = 0
while count < n:
yield count
count += 1
b ) 使用生成器监听文件输入
def fileTail(filename):
with open(filename) as f:
while True:
tail = f.readline()
if line:
yield tail
else:
time.sleep(0.1)
c)计算移动平均值
def averager(start_with = 0):
count = 0
aver = start_with
total = start_with
while True:
val = yield aver
total += val
count += 1
aver = total/count
有个弊端,需要通过__next__或next()初始化一次,通过预激解决
d)预激计算移动平均值
def init(f):
def wrapper(start_with = 0):
g_aver = f(start_with)
g_aver.__next__()
return g_aver
return wrapper
@init
def averager(start_with = 0):
count = 0
aver = start_with
total = start_with
while True:
val = yield aver
total += val
count += 1
aver = total/count
e)读取文件字符数最多的行的字符数
最传统的写法:
def longestLine(filename):
with open(filename, 'r', encoding='utf-8') as f:
alllines = [len(x.strip()) for x in f]
return max(alllines)
使用生成器以后的写法:
def longestLine(filename):
return max(len(x.strip()) for x in open(filename))
f)多生成器迭代
>>> g = (i for i in range(5)) >>> for j in g: ... print(j) ... 0 1 2 3 4 >>> for j in g: ... print(j) ... >>>
因为for j in g, 每次循环执行一次g.__next__();直到结束,触发StopIteration;
主意下面结果的输出:
>>> g = (i for i in range(4)) >>> g1 = (x for x in g) >>> g2 = (y for y in g1) >>> >>> print(list(g1)) [0, 1, 2, 3] >>> print(list(g2)) [] >>>
为什么print(list(g2))为空呢?理一下,不然会乱:
看下面的代码:
1 def g():
2 print('1.1')
3 for i in range(2):
4 print('1.2')
5 yield i
6 print('1.3')
7
8 def g1():
9 print('2.1')
10 for x in s:
11 print('2.2')
12 yield x
13 print('2.3')
14
15 def g2():
16 print('3.1')
17 for y in s1:
18 print('3.2')
19 yield y
20 print('3.3')
21
22 s = g()
23 s1 = g1()
24 s2 = g2()
25 print('start first list')
26 print(list(s1))
27 print('start second list')
28 print(list(s2))
结果:
1 start first list 2 2.1 3 1.1 4 1.2 5 2.2 6 2.3 7 1.3 8 1.2 9 2.2 10 2.3 11 1.3 12 [0, 1] 13 start second list 14 3.1 15 []
注意第11行之后,g触发了StopIteration,被for x in s捕捉,即不能继续s.__next__()了;同样的g1触发StopIteration,被list捕捉,即不能继续s1.__next__()了;于是打印[0,1]
当进行print(list(s2))时,执行s2.__next__(),停留在代码的第17行for y in s1,但是这是不能继续s1.__next__()了;于是直接触发了StopIteration;结果为[]
再看一个有意思的输出:
def add(n,i):
return n+i
g = (i for i in range(4))
for n in [1,10]:
g = (add(n,i) for i in g)
print(list(g))
输出为:
[20, 21, 22, 23]
其实上面的代码翻译如下:
def add(n,i):
return n+i
def g1():
for i in g:
yield add(n,i)
def g2():
for i in s1:
yield add(n,i)
n = 1
s1 = g1()
n = 10
s2 = g2()
print(list(s2))
转载自:https://www.cnblogs.com/deeper/p/7565571.html
最终n用的是10,