python中的网络编程又可以称为socket(套接字)编程。
主要分为TCP编程,UDP编程。
先理清几个的概念。
socket,为什么说网络编程又称为socket编程。socket可以翻译成插座,在python中,python为我们提供了一个socket 模块,通过这个模块我们可以快速地进行网络编程。
TCP/IP协议是互联网的基础协议,任何与互联网相关的操作都离不开TCP/IP协议,不管是OSI七层模型,还是TCP/IP四层、五层模型,每一层都有自己的专属协议,完成自己相应的工作以及与上下层之间的联系。PS:运输层(TCP/IP)

Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。
下面是进行socket编程的步骤
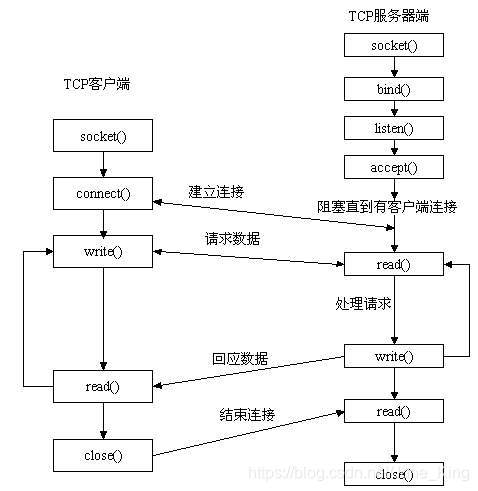
先从服务器端说起。服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
下面是简单的示例。
# 服务端
import socket # 导入socket模块
# 创建socket套接字,TCP类型
ss = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
ipaddr = ('127.0.0.1', 8888)
# 绑定IP与端口
ss.bind(ipaddr)
# 设置连接数量
ss.listen(5)
# 开始监听,将会阻塞到这里,直到有客户端接入
conn, ip = ss.accept()
print('conn------->', conn)
while 1:
#接收数据
getdata = conn.recv(1024)
print('client:', getdata.decode('utf-8'))
print('toClient:', getdata.upper().decode('utf-8'))
conn.send(getdata.upper())
ss.close()# 客户端
import socket
cc = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
ipaddr = ('127.0.0.1', 8888)
# 连接服务端
cc.connect(ipaddr)
while True:
data = input('--->>')
# 向服务端发送数据
cc.send(data.encode('utf-8'))
print('send:', data)
getdata = cc.recv(1024)
print('Server: ', getdata.decode('utf-8'))
cc.close()实现了简单的基于TCP的客户端服务端通信。
socket.socket(socket.AF_INET, socket.SOCK_STREAM)创建一个TCP套接字,
socket.socket(socket.AF_INET, socket.SOCK_DGRAM)创建一个UDP套接字服务端套接字函数
s.bind() 绑定(主机,端口号)到套接字,元组类型
s.listen() 开始TCP监听
s.accept() 被动接受TCP客户的连接,(阻塞式)等待连接的到来
客户端套接字函数
s.connect() 主动初始化TCP服务器连接
s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
公共用途的套接字函数
s.recv() 接收TCP数据
s.send() 发送TCP数据(send在待发送数据量大于己端缓存区剩余空间时,数据丢失,不会发完)
s.sendall() 发送完整的TCP数据(本质就是循环调用send,sendall在待发送数据量大于己端缓存区剩余空间时,数据不丢失,循环调用send直到发完)
s.recvfrom() 接收UDP数据
s.sendto() 发送UDP数据
s.getpeername() 连接到当前套接字的远端的地址
s.getsockname() 当前套接字的地址
s.getsockopt() 返回指定套接字的参数
s.setsockopt() 设置指定套接字的参数
# setsockopt(SOL_SOCKET,SO_REUSEADDR,1)解决程序关闭后立即打开程序,显示地址被占用的问题
s.close() 关闭套接字PS: 在程序不进行并发的时候,TCP一次只能为一个客户端进行服务,因为TCP进行通信是先进行三次握手建立一个连接,进行数据流的通信,然后双方进行网络通信,而UDP则没有这个限制,因为UDP是无连接的面向数据报文的通信。
UDP示例
# UDP服务端
import socket
ss = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 第二个参数与建立TCP时不同
ip_port = ('127.0.0.1', 8888)
buffer_size = 1024
ss.bind(ip_port)
# 没了listen和accept
while 1:
data, ipaddr = ss.recvfrom(buffer_size) # 接收数据的方法也不同
print('{0}客户端发来------->{1}'.format(ipaddr, data))
ss.sendto(data, ipaddr) # 发送数据的方法也不同
ss.close()# UDP客户端
import socket
cc = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
ip_port = ('127.0.0.1', 8888)
while True:
data = input('--->>')
cc.sendto(data.encode('utf-8'), ip_port) # 发送方式是数据,ip+port
print('send:', data)
getdata, ipaddr = cc.recvfrom(1024)
print('Server: ', getdata.decode('utf-8'))
cc.close()
使用UDP进行通信时,服务端可以同时为多个客户端进行服务,但是可能会丢包,在网络不好的情况下很容易丢包。
TCP在进行通信时,很容易发生粘包。
举个例子,当我们服务端发送给我们1024个字节的内容时,我们只接受的512个字节的内容,那么另外的512个字节将会和下一次的数据放到一起接收。
可以通过下面的例子来看粘包的现象
# 服务端
from socket import *
import subprocess
ip_port = ('127.0.0.1', 8888)
buffer_size = 1024
back_log = 5
ss = socket(AF_INET, SOCK_STREAM)
ss.bind(ip_port)
ss.listen(back_log)
conn, addr = ss.accept()
while True:
cmd = conn.recv(buffer_size)
print(cmd)
res = subprocess.Popen(cmd.decode('utf-8'),shell=True,
stdout=subprocess.PIPE,
stdin=subprocess.PIPE,
stderr=subprocess.PIPE
)
resstdout = res.stdout.read()
resstderr = res.stderr.read()
if resstdout:
msg = resstdout
else:
msg = resstderr
conn.send(msg)
conn.close()
ss.close()
# 客户端
from socket import *
ip_port = ('127.0.0.1', 8888)
buffer_size = 512
back_log = 5
cc = socket(AF_INET, SOCK_STREAM)
cc.connect(ip_port)
while True:
msg = input('>>>')
cc.send(msg.encode('utf-8'))
res = cc.recv(buffer_size)
print(res.decode('gbk'))
cc.close()当我们在客户端输入cmd命令后,服务端将执行的结果发送给我们,我们会发现第二次输入之后收到的内容包含第一次命令执行的结果。这就是粘包现象。
所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
此外,发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,即便是你输入的是空内容(直接回车),那也不是空消息,udp协议会帮你封装上消息头
so,我们可以通过先发送给要发送数据的长度,然后对方通过这个数据的长度来进行接收,即可解决粘包的问题。
解决粘包版本之菜鸟版
# 服务端
from socket import *
import subprocess
ip_port = ('127.0.0.1', 8888)
buffer_size = 1024
ss = socket(AF_INET, SOCK_STREAM)
ss.bind(ip_port)
ss.listen(5)
conn, addr = ss.accept()
while True:
cmd = conn.recv(buffer_size)
print(cmd)
res = subprocess.Popen(cmd.decode('utf-8'),shell=True,
stdout=subprocess.PIPE,
stdin=subprocess.PIPE,
stderr=subprocess.PIPE
)
resstdout = res.stdout.read()
resstderr = res.stderr.read()
if resstdout:
msg = resstdout
else:
msg = resstderr
length = len(msg)
conn.send(str(length).encode('utf-8'))#发送数据长度给客户端,客户端根据这个数值进行接收
status = conn.recv(buffer_size).decode('utf-8')
if status == 'ready':
conn.sendall(msg)
conn.close()
# 客户端
from socket import *
ip_port = ('127.0.0.1', 8888)
buffer_size = 1024
cc = socket(AF_INET,SOCK_STREAM)
cc.connect(ip_port)
while True:
msg = input('>>>')
cc.send(msg.encode('utf-8'))
data_size = int(cc.recv(buffer_size).decode('utf-8'))# 获取要接收数据的长度
get_size = 0
res = b''
cc.send('ready'.encode('utf-8'))
while get_size < data_size:
res += cc.recv(1024)
get_size = len(res)
print(res.decode('gbk'))
cc.close()上面这个方法存在一个问题,就是我们虽然接收了要接收数据的长度,但是int(cc.recv(buffer_size).decode('utf-8'))这一个并不能确定啊。写法还是有些繁琐。
下面是升级版本
# 服务端
from socket import *
import subprocess
import struct
ip_port = ('127.0.0.1', 8888)
buffer_size = 1024
ss = socket(AF_INET, SOCK_STREAM)
ss.bind(ip_port)
ss.listen(5)
conn, addr = ss.accept()
while True:
cmd = conn.recv(buffer_size)
print(cmd)
res = subprocess.Popen(cmd.decode('utf-8'),shell=True,
stdout=subprocess.PIPE,
stdin=subprocess.PIPE,
stderr=subprocess.PIPE
)
resstdout = res.stdout.read()
resstderr = res.stderr.read()
if resstdout:
msg = resstdout
else:
msg = resstderr
length = len(msg)
data_length = struct.pack('i', length) # 四个字节
conn.send(data_length)# 发送固定长度
conn.send(msg)
conn.close()
# 客户端
from socket import *
import struct
from functools import partial
ip_port = ('127.0.0.1', 8888)
buffer_size = 1024
cc = socket(AF_INET, SOCK_STREAM)
cc.connect(ip_port)
while True:
msg = input('>>>')
cc.send(msg.encode('utf-8'))
length_data = cc.recv(4)# 获取要接收数据的长度
data_size = struct.unpack('i', length_data)[0]
l = iter(partial(cc.recv, 1024), b' ')
for i in l:
print(i.decode('gbk'))
cc.close()
我们通过struct模块将数据长度打包成四字节的大小的数据进行发送,解决了粘包的问题。
同样我们还可以发送更为复杂的更多的数据。
下面是个简单的ftp文件上传的示例
# 服务端
from socket import *
import subprocess
import hashlib
# ip_port = ('', 8889)
ip_port = ('127.0.0.1', 8888)
buffer_size = 1024
back_log = 5
ss = socket(AF_INET, SOCK_STREAM)
ss.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
ss.bind(ip_port)
ss.listen(back_log)
conn, addr = ss.accept()
while True:
msg = conn.recv(buffer_size)
print(msg)
file_size = int(conn.recv(buffer_size).decode('utf-8'))
print('file_size')
file_hash = conn.recv(buffer_size).decode('utf-8')
print('file_hash')
print('data--->>>>', file_size, 'byte')
print('data--->>>>%d' % (file_size / (1024 * 1024)), 'MB')
print('ready')
get_size = 0
hash = 0
with open("bei" + msg.decode(), 'wb+') as f:
print('get')
md5obj = hashlib.md5()
while hash != file_hash:
file_data = conn.recv(buffer_size)
if file_data:
f.write(file_data)
get_size += buffer_size
md5obj.update(file_data)
hash = md5obj.hexdigest()
print('recv%.2f' % ((os.path.getsize(msg.decode()) / (1024 * 1024)) / (file_size / 1024 / 1024)), '%')
print('recv_success')
buffer_size = 1024
conn.close()
ss.close()
# 客户端
from socket import *
import os
import time
import hashlib
ip_port = ('127.0.0.1', 8888)
buffer_size = 1024
back_log = 5
cc = socket(AF_INET, SOCK_STREAM)
cc.connect(ip_port)
while True:
filepath = input('input file path--->')
try:
print(filepath)
f = open(filepath, 'rb+')
f.close()
except FileNotFoundError as e:
print('file not found')
continue
except Exception as e:
print('unerror')
continue
with open(filepath, 'rb') as f:
md5obj = hashlib.md5()
md5obj.update(f.read())
file_hash = md5obj.hexdigest()
print(file_hash)
filesize = str(os.path.getsize(filepath))
namepath, filename = os.path.split(filepath)
print(filename)
print('data--->>>>', filesize, 'byte')
print('data--->>>>%d' % (int(filesize) / (1024 * 1024)), 'MB')
cc.send(filename.encode('utf-8'))
time.sleep(1)
cc.send(filesize.encode('utf-8'))
time.sleep(1)
cc.send(file_hash.encode('utf-8'))
print('start upload...')
send_size = 0
hash = 0
with open(filepath, 'rb+') as f:
print('uploading...')
md5obj = hashlib.md5()
while hash != file_hash:
res = f.read(buffer_size)
cc.send(res)
md5obj.update(res)
hash = md5obj.hexdigest()
print('upload success...')
cc.close()
起初我通过已接收数据的大小与文件大小是否相等来判断是否继续接收数据,后来发现文件没接收完成程序便抛出异常。不知道是因为网络的原因还是机器的原因,后来改用这个方法,通过文件的md5值来决定是否接受数据。每个数据的md5值是不一样,即唯一性,通过这个方法,可以很好的解决文件的上传之后是否发生变化,是否上传完整。