1 Pandas文件读取和写入
1.1 文件读取(csv、txt、xls/xlsx)
# 读取 csv 文件
pandas.read_csv( )
# 读取 txt 文件
pandas.read_table( )
# 读取 xls/xlsx 文件
pandas.read_excel( ) # 需要安装openpyxl
1.2 文件写入(csv、xls/xlsx)
# 写入 csv 文件
pandas.to_csv( )
# 写入 xls/xlsx 文件
pandas.to_excel( )
2 Pandas基本数据结构(Series、Dataframe)
2.1 Series
(1)创建Series
官方文档上定义Series是轴标签为索引的一维数组(包含时间序列)。
参数有:
- data:数据。
- index:索引
- dtype:输出数据的类型
- name:Series名称
- copy:复制数据。bool型,默认为False
s = pd.Series(np.random.randn(5),
index=['a','b','c','d','e'],
name='这是一个Series',
dtype='float64')
(2)访问Series属性
Series有很多属性,如value、size、shape、T等。
可以通过Series_name.Attributes来访问属性。如:
s.values
(3)访问Series方法
用法类似访问属性的操作。
2.2 DataFrame
DataFrame是一个二维的数据结构。
函数原型是:DataFrame([data, index, columns, dtype, copy])
(1) 创建一个DataFrame
df = pd.DataFrame({'col1':list('abcde'),'col2':range(5,10),'col3':[1.3,2.5,3.6,4.6,5.8]},
index=list('一二三四五'))
(2)行列操作
-
取出一列:
df['col1'] -
修改行/列名:
df.rename(index={'一':'one'}, columns={'col1':'new_col1'}) -
调用属性和方法
-
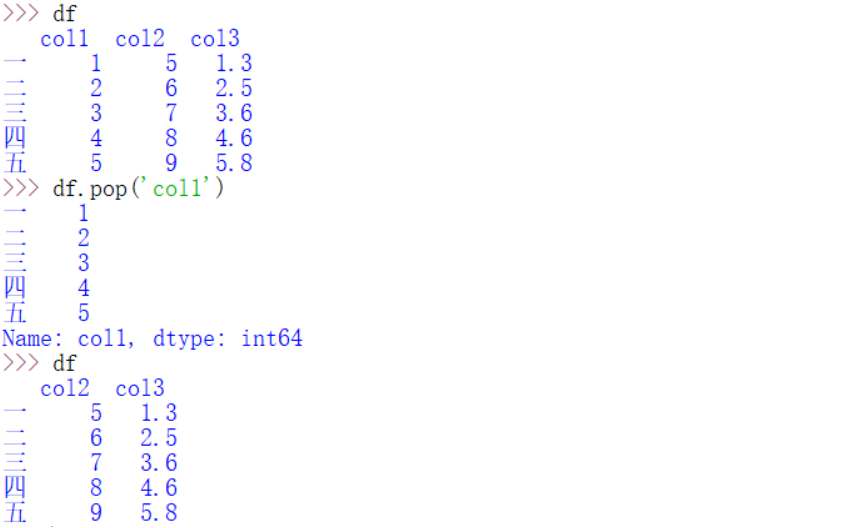
删除行列。(两种方法:
drop(),pop())- drop():
inplace=False不改变原DataFrame中的行列, - pop() 方法直接在原来的DataFrame上操作,且返回被删除的列,与python中的pop函数类似
- drop():
df.drop(index='五',columns='col1',inplace=False)


- 增加行列
- 直接增加:
- 使用assign方法。但assign方法不会对原DataFrame做修改
(3) DataFrame的索引对其特性
df1 = pd.DataFrame({'A':[1,2,3]},index=[1,2,3])
df2 = pd.DataFrame({'A':[1,2,3]},index=[3,1,2])
print(df1)
print(df2)
df1-df2 #由于索引对齐,因此结果不是0

(4) 根据类型选择列
df.select_dtypes(include=['number']).head()

(5) Series转换为DataFrame
s = df.mean()
s.to_frame()

3 Pandas常用基本函数
(1) head和tail
data.head():返回data的前几行数据,默认为前五行,需要前十行则data.head(10)data.tail():返回data的后几行数据,默认为后五行,需要后十行则data.tail(10)
(2) unique和nunique
data['column'].nunique():显示有多少个唯一值data['column'].unique():显示所有的唯一值
(3) count和value_counts
data['column'].count():返回非缺失值元素个数data['column'].value_counts():返回每个元素有多少个
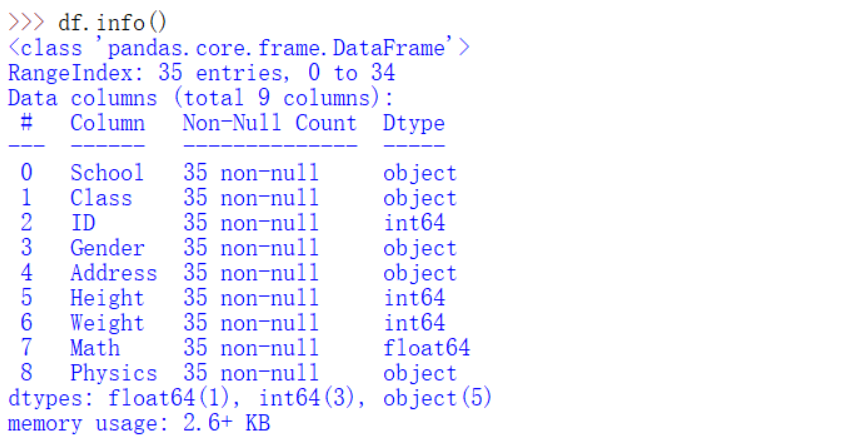
(4) describe和info
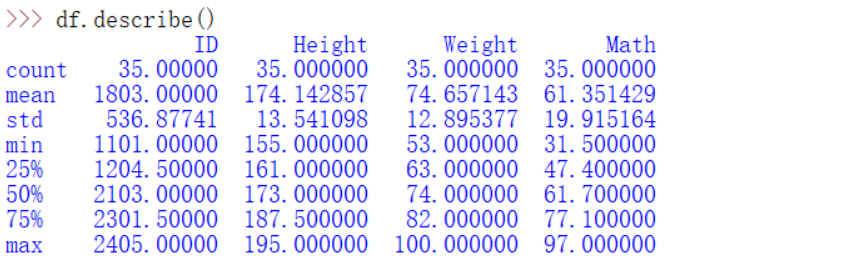
data.info():返回有哪些列、有多少非缺失值、每列的类型data.describe():默认统计数值型数据的各个统计量。包括数量、均值、最大最小值、分位数等。describe()可以自行选择分位数。表达式为:df.describe(percentiles=[.05, .25, .75, .95])
describe()也可以用于非数值型数据。df['Physics'].describe()
(5) idxmax和nlargest
data['column'].indxmax():idxmax函数返回最大值。idxmin功能类似data['column'].nlargest(num):nlargest函数返回前num个大的元素值,nsmallest功能类似
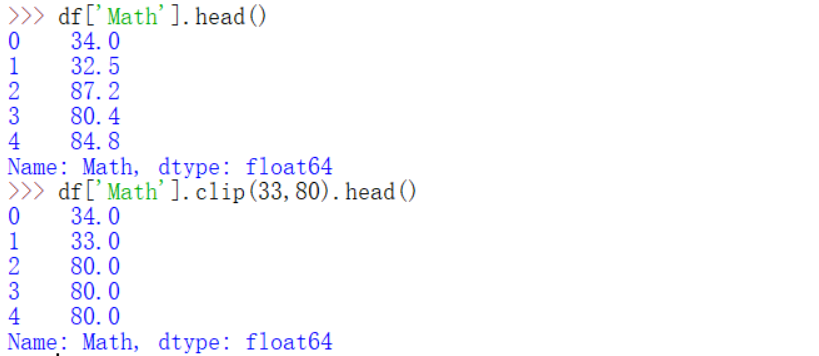
(6) clip和replace
-
data['column'].clip(low, up):对超过up或者低于low的数进行截断
-
data['column'].replace(num):replace是对某些值进行替换。也可以通过字典直接在表中修改。

(7) apply()函数
apply是一个自由度很高的函数。对于Series,它可以迭代每一列的值操作;对于DataFrame,它可以迭代每一个列操作。
df['Math'].apply(lambda x:str(x)+'!').head() #可以使用lambda表达式,也可以使用函数

df.apply(lambda x:x.apply(lambda x:str(x)+'!')).head() #这是一个稍显复杂的例子,有利于理解apply的功能

4 Pandas排序操作
(1) 索引排序
sort_index()可以设置ascending参数为升序(True)或者降序(False),默认升序
df.set_index('Math').head() #设置索引
df.set_index('Math').sort_index().head()
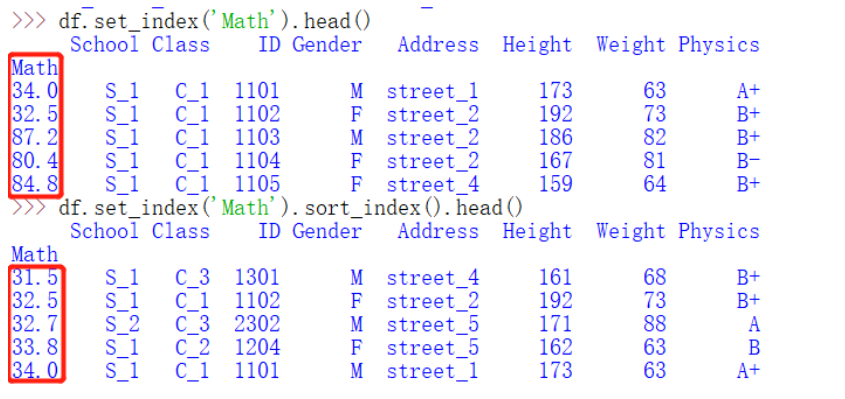
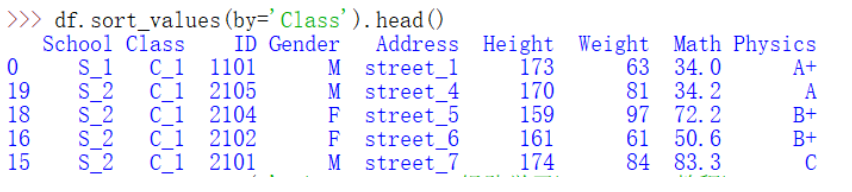
(2) 值排序
df.sort_values(by='Class').head()
多个值排序,即先对第一层排,在第一层相同的情况下对第二层排序
df.sort_values(by=['Address','Height']).head()

5 问题
【问题一】 Series和DataFrame有哪些常见属性和方法?
-
Series
- 属性:values、 index、、name、dtype
- 方法:mean、T、abs、array、append ......
-
DataFrame
- 属性:columns、index、value、shape
- 方法:mean
【问题二】 value_counts会统计缺失值吗?
答:不会。
df = pd.DataFrame({'col1':[1, 1, 2], 'col2':[3, 4, np.nan]})
df['col1'].value_counts()
df['col2'].value_counts()

【问题三】 与idxmax和nlargest功能相反的是哪两组函数?
答: indxmin() 和 nsmallest()
【问题四】 在常用函数一节中,由于一些函数的功能比较简单,因此没有列入,现在将它们列在下面,请分别说明它们的用途并尝试使用。
sum:求指定轴的和。用法:data.sum(axis=0)。mean:求指定轴的平均数。用法:data.mean()median:求指定轴的中位数。用法:data.median()mad:求指定轴的平均绝对离差min:求指定轴的最小值max:求指定轴的最大值abs:元素的绝对值std:求指定轴样本的标准偏差,默认ddof=1var:求指定轴的方差,默认ddof=1quantile:求指定轴的分位数,参数q默认为0.5,(q in [0, 1])cummax:求指定轴上积累的最大值。默认情况下,NaN值会被忽略,若要包含NaN,则需要使参数skipna=Falsecumsum:求累计和cumprod:求累计乘。cumsum和cumprod可以用来看数据的变化趋势,累加是通过流量得到存量,比如每天销售量的多少,得到今年的销售量总量;累乘是通过变化率来得到存量,比如有每天的数据变动趋势,通过累乘来得到当前的数据。
【问题五】 df.mean(axis=1)是什么意思?它与df.mean()的结果一样吗?第一问提到的函数也有axis参数吗?怎么使用?
axis=1是对1轴进行操作。在DataFrame中,0轴是index轴,1轴是column轴。- 正因为如此,df.mean()对0轴和1轴操作的结果肯定是不一样的。
- 属性没有axis参数,方法有axis参数,用法个人认为是一样的。
如什么问题,欢迎留言交流,觉得有用的小伙伴顺手点个赞吧。
你的肯定是我的最大动力!