作业要求参见 https://edu.cnblogs.com/campus/nenu/2018fall/homework/2126
本次作业代码地址:https://coding.net/u/KamiForever/p/SPEC20180918/git 代码为wf.cpp文件。
一,重点分析和代码实现:
1.关于单词的输入,我才去每次都只选取一个字母,如果字母是大写英文字母就变成小写,不是字母就把之前的合并成一个单词(用一个before变量去判定前面的是一个字母,如果不是字母则跳过),然后用hash去把单词给记录进结构体words中储存。
while(~scanf("%c", &c)) { if((c >= 65 && c <= 90) || (c >= 97 && c <= 122)) { if(c >= 65 && c <= 90) c += 32; word[i++] = c; before = 1; } else { if(before) { word[i] = '�'; Hash(word); i = 0; before = 0; } } }
其中关于单词辨识,我认为有任何符号就是把两个单词分开来了,其中会将形如we'll或者someone's处理成两个单词,但是只会处理成we和ll而不是we和will,这里是一个盲点,目前不知道如何解决。
2.关于文件夹批量处理,这里采用_finddata_t结构体和_findfirst与_findnext函数进行处理,具体的使用方式学习于https://blog.csdn.net/wangqingchuan92/article/details/77979669。
bool solvethree(char fileName[]) { strcat(fileName, "\*.txt"); long k = HANDLE = _findfirst(fileName, &file); if(k == -1) return false; //得到的文件夹名字后面加.txt如果能找到就说明输入的是文件夹的名字 else { while (k != -1) { printf("%s ", file.name); solve(file.name); output(); k = _findnext(HANDLE, &file); if(k != -1) printf("---- "); } _findclose(HANDLE); } return true; }
3.对于将单词插入结构体words中,由于考虑到可能数据量很大,采用了hash的方式去插入,具体就是取每个单词的前3个字母(不到3个,有几个取几个)组合成一个6位数,然后去mod一个Maxn(代码里面取的是1000000,可以随情况更改),对于得到的数进行hash插入,如果这个数的位置上有单词了,就往后移动一位知道能插入位置。
void Hash(char word[]) { int len = strlen(word); if(len >= 3) len = 3; int t = 0; for(int i = 0; i < len; i++) { t = t * 100; t += (word[i] - 97); } t = t % Maxn; while(1) { if(words[t].cnt == 0) { words[t].cnt = 1; strcpy(words[t].content, word); wordtotal += 1; wordcnt += 1;; return; } else { if(strcmp(words[t].content, word) == 0) { words[t].cnt += 1; wordtotal += 1; return; } else { if(t == Maxn - 1) t = 0; else t += 1; } } } }
4.重定向,由于样例输入中有“<”将输入重定向到一个文件中,输出则用freopen函数去重定向到文件夹中,先用getwcd函数获取算法文件的地址buff,然后在后面接上out.txt即为输入到的文件名,生成输入到的文件名的地址,然后用freiopen见输出重定向到out.txt中。
char buf[200]; char out[200]; getcwd(buf, sizeof(buf)); //获取本地文件直接地址 strcat(buf, "\"); strcpy(out, buf); strcat(out, "out.txt"); freopen(out, "w", stdout); // freopen重定向使输出到out.txt中
使用完需要用fclose()函数去关闭重定向。
5.文件输入,用到fopen函数,定义FILE变量fp,用fgetc(fp)去读取文件中的每个字符,然后用feof(fp)去判定文件时候到底,最后用fclose关闭。
void getword(char name[]) { fp = fopen(name, "r"); //用fopen打开文件从而进行输入 before = 1; wordcnt = 0; wordtotal = 0; int i = 0; memset(words, 0, sizeof(*words)); while(!feof(fp)) { //用于构造单词,并且把所有的大写字母变为小写字母 c = fgetc(fp); if((c >= 65 && c <= 90) || (c >= 97 && c <= 122)) { if(c >= 65 && c <= 90) c += 32; word[i++] = c; before = 1; } else { if(before) { word[i] = '�'; Hash(word); //将构造出来的单词hash插入结构体words中 i = 0; before = 0; } } } fclose(fp); fp = NULL; return; }
6.文件输出,由于单词数量可能过多,所以只输出前10个单词,当单词数不够10个的时候按此时单词数输出,其中为了统一输出格式,用 去控制空格数量,此时我认为最长单词不超过24位。
void output() { for(int i = 0; i < ((wordcnt < 10) ? wordcnt : 10); i++) { int len = strlen(words[i].content); printf("%s", words[i].content); for(int j = 0; j < 3 - (len / 8); j++) printf(" "); printf("%d ", words[i].cnt); } return; }
二,每种功能实现方式和功能执行图
1.功能一:
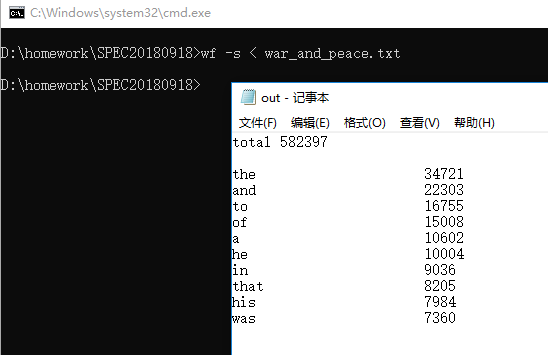
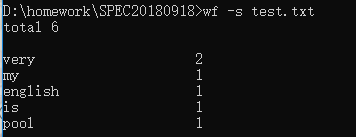
读取文件名test.txt,然后获取每个单词并且用hash方法插入到结构体中,用sort排序然后输出,本功能并没有任何难点。
2.功能二:
读取文章的名字,然后在文章的名字后面加上词缀.txt,然后就和功能一同样的实现方法了,问题在于和功能三的区分这里在功能三的介绍中会出现,由于会有大数据所以数组要开的大一点,我初步认为不会重复的单词数量不超过1000000,如果不够可以改变文件开头的Maxn值去改善。

3.功能三:
读取文件夹的名字,关于在和功能二的区分上,我在获得的字符串后面加上“*.txt”生成fileName,然后用_findfirst(fileName, &file),如果返回结果为-1,则说明输入的是文章的名字而并非文件夹的直接地址,关于文件夹内容批量处理我在上文说过,这里不再赘述,在批量处理中能得到文件的名字,然后将得到的每一个文件的名字都用功能一去处理就完事了。

4.功能四:
功能四的不同点在于可以重定向输入输出,输入可以用"< 文件名"的样例形式,输出则用freopen重定向,然后printf就可以把输出的重定向的文件内。