参考《Redis 设计与实现》 (基于redis3.0.0) 作者:黄健宏
学习redis3.2.13
对象的类型与编码
对象的结构
对象类型
编码与底层数据结构实现
对象类型、对象编码、对象之间的关系
字符串对象概览
列表对象概览
集合对象概览
有序集合对象概览
哈希对象概览
值对象底层编码查看
对象共享与内存回收
空转时长
字符串对象
部分字符串命令实现
列表对象
转换ziplist到quicklist
哈希对象
默认编码OBJ_ENCODING_ZIPLIST
转换到OBJ_ENCODING_HT
部分哈希对象命令实现
集合对象
转换到OBJ_ENCODING_HT
集合对象部分命令实现
有序集合对象
编码转换
转换到OBJ_ENCODING_SKIPLIST
转换到OBJ_ENCODING_ZIPLIST
部分有序集合对象命令实现
类型检查与命令多态
介绍
redis基于数据结构sds、adlist、dict、ziplist、inset,实现了一个对象系统,系统内含五种对象:字符串对象、列表对象、哈希对象、集合对象和有序集合对象。
使用对象的好处:
- 每个对象类型与对应的命令相匹配,在执行给定命令之前,根据对象的类型来判断一个对象是否可以执行给定的命令
- 可针对不同的使用场景为对象设置不同的数据结构实现,优化对象在不同场景的使用效率
- 对象系统实现了基于引用计数技术的内存回收机制,避免了资源泄露
- 实现了基于引用计数的对象共享机制,通过使多个键共享一个对象来节约内存
- 对象带有访问时间记录信息,用于计算键的空转时长,在启动maxmemory 功能时,优先删除空转时间较大的键
对象的类型与编码
redis中的键与值都是redis对象,每当使用命令在redis中创建键值对时都会产生两个对象,一个键对象,一个值对象
对象的结构
#define LRU_BITS 24
typedef struct redisObject {
//对象的类型
unsigned type:4;
//编码类型(底层数据结构类型)
unsigned encoding:4;
//标记对象最后一次被访问时间,淘汰数据时使用
unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */
//引用计数
int refcount;
//指向对象底层数据结构实现的指针
void *ptr;
} robj;对象类型
redis的key总是一个字符串对象,其value是上面提到的5种对象之一,redisObject 的type成员表明了对象的类型:
#define OBJ_STRING 0 //字符串对象
#define OBJ_LIST 1 //列表对象
#define OBJ_SET 2 //集合对象
#define OBJ_ZSET 3 //有序集合对象
#define OBJ_HASH 4 //哈希对象使用type命令,可以查询到key对应value对象的类型
编码与底层数据结构实现
redisObject 中的指针ptr保存了对象的底层数据结构的地址,encoding表明了对象底层到底用哪个数据结构实现
通过位同一对象设定不同底层数据结构实现,并用encoding记录使用的编码,提高了redis的灵活性与效率
| 编码宏定义 | 对应的底层数据结构 |
|---|---|
| OBJ_ENCODING_RAW | 简单动态字符串sds |
| OBJ_ENCODING_INT | long类型的整数 |
| OBJ_ENCODING_HT | 字典dict |
| OBJ_ENCODING_ZIPMAP | 压缩字典zipmap |
| OBJ_ENCODING_ZIPLIST | 压缩列表ziplist |
| OBJ_ENCODING_INTSET | 整数集合intset |
| OBJ_ENCODING_SKIPLIST | 跳表skiplist |
| OBJ_ENCODING_EMBSTR | embstr编码的sds(嵌入式sds) |
| OBJ_ENCODING_QUICKLIST | 快速列表quicklist(压缩列表组成的双端列表) |
对象类型、对象编码、对象之间的关系
字符串对象概览
| 对象类型 | 对象编码 | 对象 |
|---|---|---|
| OBJ_STRING | OBJ_ENCODING_RAW | 使用简单动态字符串实现的字符串对象 |
| OBJ_STRING | OBJ_ENCODING_EMBSTR | 使用embstr编码的简单动态字符串实现的字符串对象 |
| OBJ_STRING | OBJ_ENCODING_INT | 使用整数值实现的字符串对象 |
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution). */
o->lru = LRU_CLOCK();
return o;
}
//可以看到raw编码时 sds与object是分开的,为两块不同的内存
robj *createRawStringObject(const char *ptr, size_t len) {
return createObject(OBJ_STRING,sdsnewlen(ptr,len));
}
//采用embstr编码时,sds与object是连续的内存
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
struct sdshdr8 *sh = (void*)(o+1);
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR;
o->ptr = sh+1;
o->refcount = 1;
o->lru = LRU_CLOCK();
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '�';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
//由代码可知,1、当value取值在0到9999时,共享对象,并通过引用计数记录使用情况
//2、取值在可由long表示时,强制转换为使用long实现对象
//3、其余情况使用sds表示该value
robj *createStringObjectFromLongLong(long long value) {
robj *o;
if (value >= 0 && value < OBJ_SHARED_INTEGERS) { //#define OBJ_SHARED_INTEGERS 10000
incrRefCount(shared.integers[value]);
o = shared.integers[value];
} else {
if (value >= LONG_MIN && value <= LONG_MAX) {
o = createObject(OBJ_STRING, NULL);
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*)((long)value);
} else {
o = createObject(OBJ_STRING,sdsfromlonglong(value));
}
}
return o;
}列表对象概览
| 对象类型 | 对象编码 | 对象 |
|---|---|---|
| OBJ_LIST | OBJ_ENCODING_QUICKLIST | 使用快速列表实现的列表对象 |
| OBJ_LIST | OBJ_ENCODING_ZIPLIST | 使用压缩列表实现的列表对象 |
robj *createQuicklistObject(void) {
quicklist *l = quicklistCreate();
robj *o = createObject(OBJ_LIST,l);
o->encoding = OBJ_ENCODING_QUICKLIST;
return o;
}
robj *createZiplistObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_LIST,zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}集合对象概览
| 对象类型 | 对象编码 | 对象 |
|---|---|---|
| OBJ_SET | OBJ_ENCODING_HT | 使用字典实现的集合对象 |
| OBJ_SET | OBJ_ENCODING_INTSET | 使用整数集合实现的集合对象 |
robj *createSetObject(void) {
dict *d = dictCreate(&setDictType,NULL);
robj *o = createObject(OBJ_SET,d);
o->encoding = OBJ_ENCODING_HT;
return o;
}
robj *createIntsetObject(void) {
intset *is = intsetNew();
robj *o = createObject(OBJ_SET,is);
o->encoding = OBJ_ENCODING_INTSET;
return o;
}有序集合对象概览
| 对象类型 | 对象编码 | 对象 |
|---|---|---|
| OBJ_ZSET | OBJ_ENCODING_SKIPLIST | 使用跳跃表和字典实现的有序集合对象 |
| OBJ_ZSET | OBJ_ENCODING_ZIPLIST | 使用压缩列表实现的有序集合对象 |
robj *createZsetObject(void) {
zset *zs = zmalloc(sizeof(*zs));
robj *o;
zs->dict = dictCreate(&zsetDictType,NULL);
zs->zsl = zslCreate();
o = createObject(OBJ_ZSET,zs);
o->encoding = OBJ_ENCODING_SKIPLIST;
return o;
}
robj *createZsetZiplistObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_ZSET,zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}哈希对象概览
| 对象类型 | 对象编码 | 对象 |
|---|---|---|
| OBJ_HASH | OBJ_ENCODING_ZIPLIST | 使用压缩列表实现的哈希对象 |
| OBJ_HASH | OBJ_ENCODING_HT | 使用字典实现的哈希对象 |
robj *createHashObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_HASH, zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}以OBJ_ENCODING_HT编码的哈希对象并不是直接创建出来的,而是经由OBJ_ENCODING_ZIPLIST编码的哈希对象转换而来;具体的转换规则后面说。
值对象底层编码查看
object encoding可以查看键对应值对象的编码
| 对象所使用的底层数据结构 | 编码 | object encoding输出 |
|---|---|---|
| 整数 | OBJ_ENCODING_INT | "int" |
| embstr编码的简单动态字符串 | OBJ_ENCODING_EMBSTR | "embstr" |
| 简单动态字符串 | OBJ_ENCODING_RAW | "raw" |
| 字典 | OBJ_ENCODING_HT | "hashtable" |
| 快速列表 | OBJ_ENCODING_QUICKLIST | "quicklist" |
| 压缩列表 | OBJ_ENCODING_ZIPLIST | "ziplist" |
| 整数集合 | OBJ_ENCODING_INTSET | "intset" |
| 跳跃表 | OBJ_ENCODING_SKIPLIST | "skiplist" |
char *strEncoding(int encoding) {
switch(encoding) {
case OBJ_ENCODING_RAW: return "raw";
case OBJ_ENCODING_INT: return "int";
case OBJ_ENCODING_HT: return "hashtable";
case OBJ_ENCODING_QUICKLIST: return "quicklist";
case OBJ_ENCODING_ZIPLIST: return "ziplist";
case OBJ_ENCODING_INTSET: return "intset";
case OBJ_ENCODING_SKIPLIST: return "skiplist";
case OBJ_ENCODING_EMBSTR: return "embstr";
default: return "unknown";
}
}
/* Object command allows to inspect the internals of an Redis Object.
* Usage: OBJECT <refcount|encoding|idletime> <key> */
void objectCommand(client *c) {
robj *o;
if (!strcasecmp(c->argv[1]->ptr,"refcount") && c->argc == 3) {
if //xxx
} else if (!strcasecmp(c->argv[1]->ptr,"encoding") && c->argc == 3) {
if ((o = objectCommandLookupOrReply(c,c->argv[2],shared.nullbulk))
== NULL) return;
addReplyBulkCString(c,strEncoding(o->encoding));
} else if //xxx
} else {
addReplyError(c,"Syntax error. Try OBJECT (refcount|encoding|idletime)");
}
}对象共享与内存回收
redisObject 中的refcount用于记录对象的引用计数信息,方便多个键共享内容相同的同一整数字符串对象,以节约内存,并能根据计数信息释放对象回收内存,避免资源泄露
整数字符串共享
前面的函数createStringObjectFromLongLong就是共享整数字符串对象的例子
因为共享之前需要对比创建的目标对象与已有对象内容是否完全一致,已有整数字符串对象可以使用数组存储,对比时时间复杂度为O(1),而对比普通字符串对象为O(n),对比其他对象复杂度更高,为了效率内存兼得,redis目前只共享0到9999整数字符串对象
通过命令 object refcount 可查看对象的引用计数个数
内存回收
除了前面的createObject,涉及到的refcount的函数还有:
- 增加计数的incrRefCount
void incrRefCount(robj *o) {
o->refcount++;
}- 减少计数并适时释放对象的decrRefCount
void decrRefCount(robj *o) {
if (o->refcount <= 0) serverPanic("decrRefCount against refcount <= 0");
if (o->refcount == 1) {
//释放obj的指向的低层数据结构
switch(o->type) {
case OBJ_STRING: freeStringObject(o); break;
case OBJ_LIST: freeListObject(o); break;
case OBJ_SET: freeSetObject(o); break;
case OBJ_ZSET: freeZsetObject(o); break;
case OBJ_HASH: freeHashObject(o); break;
default: serverPanic("Unknown object type"); break;
}
zfree(o);//释放obj结构本身
} else {
o->refcount--;
}
}- 单纯重置计数而不释放对象的resetRefCount
robj *resetRefCount(robj *obj) {
obj->refcount = 0;
return obj;
}空转时长
redisObject 中的lru成员记录了对象最后一次被访问时间,当前时间减去对象的lru时间就是空转时长
如果服务器开启了maxmemory选项,并且内存回收算法为 volatile-lru或者allkeys-lru时,当服务器内存占用超过
maxmemory选项设置的上限值时,空转时长较高的键会优先被服务器释放,以回收内存
具体的内存释放过程参看函数freeMemoryIfNeeded
通过命令 object idletime可以打印对象的空转时长
字符串对象
从前面的字符串对象概览,字符串对象有三种创建方式,可以存储int、raw、embstr,当
1、 当需要保存的字符串是整数(最大long long),且在long表示范围内,并不属于共享对象范围内,其值会被转为long后保存在对象的ptr成员中,编码会被设为OBJ_ENCODING_INT
2、 当需要保存的字符串长度大于44时,将会以SDS保存,编码将会是OBJ_ENCODING_RAW;反之,将会是OBJ_ENCODING_EMBSTR
embstr除了内存分配、释放次数比raw少外, 连续的内存也能更好的利用缓存
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}黄健宏老师书中说raw与embstr的界限是39,查证了一下,3.0版本的确实是39,在此版本的注释中也仍然写的39
3、当需要保存的字符串是浮点,并且在long double表示范围内,该浮点会被转换为字符串来保存,使用编码为embstr或raw;当执行命令incrbyfloat时,存储的字符串将会被转回浮点,计算后将结果继续作为字符串存储
void incrbyfloatCommand(client *c) {
long double incr, value;
robj *o, *new, *aux;
//从db中拿出键(c->argv[1]内是键)对应的值对象o
o = lookupKeyWrite(c->db,c->argv[1]);
//incrbyfloat命令操作对象为字符串,所以进行类型检查
if (o != NULL && checkType(c,o,OBJ_STRING)) return;
//将存储的字符串转为long double
if (getLongDoubleFromObjectOrReply(c,o,&value,NULL) != C_OK ||
getLongDoubleFromObjectOrReply(c,c->argv[2],&incr,NULL) != C_OK)
return;
//做运算
value += incr;
if (isnan(value) || isinf(value)) {
addReplyError(c,"increment would produce NaN or Infinity");
return;
}
//使用long double 的value创建新串
new = createStringObjectFromLongDouble(value,1);
//指定的键对象存在则覆盖其值,不存在添加
if (o)
dbOverwrite(c->db,c->argv[1],new);
else
dbAdd(c->db,c->argv[1],new);
//...后续代码省略
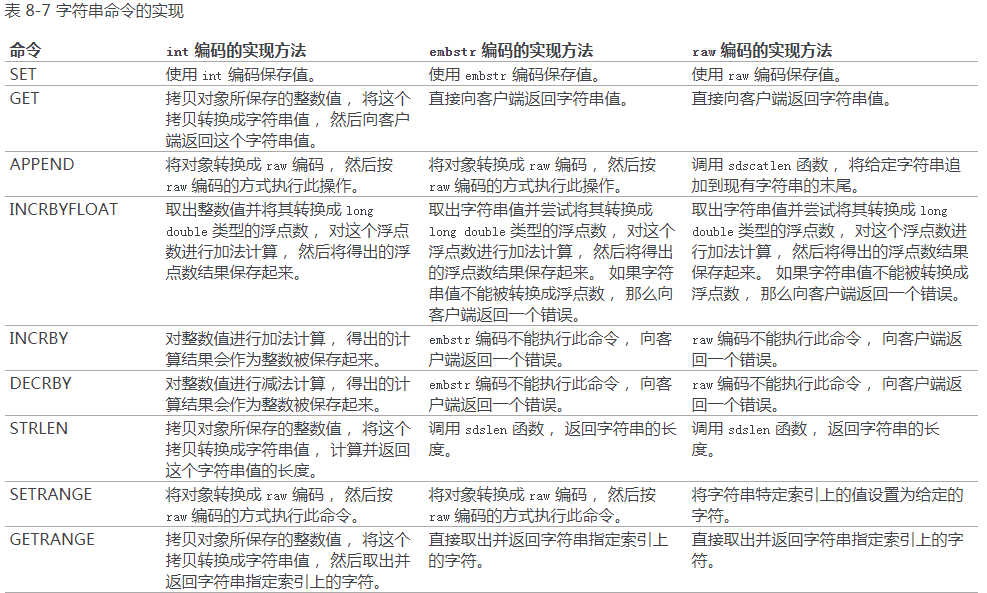
}部分字符串命令实现
列表对象
此版本中,列表对象可以由ziplist与quicklist实现,默认情况下由quicklist实现:
void pushGenericCommand(client *c, int where) {
int j, waiting = 0, pushed = 0;
robj *lobj = lookupKeyWrite(c->db,c->argv[1]); //找key对于val列表对象
//类型判断
if (lobj && lobj->type != OBJ_LIST) {
addReply(c,shared.wrongtypeerr);
return;
}
for (j = 2; j < c->argc; j++) {
//将字符串参数转换为整数字符串;不能转换时,如果参数为raw且小于44则转为emstr的字符串对象;仍旧不能转换时,去掉剩余可用空间节省内存
c->argv[j] = tryObjectEncoding(c->argv[j]);
//val列表不存在,创建快速列表,并设置其中ziplist大小、深度后,将key以及列表加入DB
if (!lobj) {
lobj = createQuicklistObject();
quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,
server.list_compress_depth);
dbAdd(c->db,c->argv[1],lobj);
}
listTypePush(lobj,c->argv[j],where); //根据where指示,插入头或尾,where由lpush或rpush指定
pushed++;
}
//...后续代码省略
}转换ziplist到quicklist
加载rdb文件时,如果加载到的value对象是RDB_TYPE_LIST_ZIPLIST,则会被转换为quicklist
robj *rdbLoadObject(int rdbtype, rio *rdb) {
robj *o = NULL, *ele, *dec;
size_t len;
unsigned int i;
if xxx
else if (rdbtype == RDB_TYPE_HASH_ZIPMAP ||
rdbtype == RDB_TYPE_LIST_ZIPLIST ||
rdbtype == RDB_TYPE_SET_INTSET ||
rdbtype == RDB_TYPE_ZSET_ZIPLIST ||
rdbtype == RDB_TYPE_HASH_ZIPLIST)
{
switch(rdbtype) {
case xxx
case RDB_TYPE_LIST_ZIPLIST:
o->type = OBJ_LIST;
o->encoding = OBJ_ENCODING_ZIPLIST;
listTypeConvert(o,OBJ_ENCODING_QUICKLIST);
break;
default xxx
}
}
return o;
}哈希对象
默认编码OBJ_ENCODING_ZIPLIST
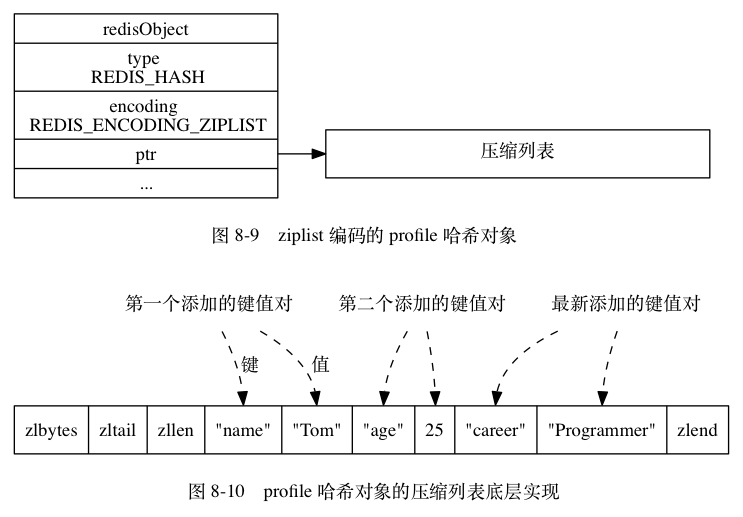
根据前面的知识,哈希对象的编码有OBJ_ENCODING_ZIPLIST与OBJ_ENCODING_HT,但是默认情况下哈希对象的编码是OBJ_ENCODING_ZIPLIST,此时哈希对象内部实现为ziplist
默认使用ziplist:
- 节约了内存的使用
- 由于ziplist连续、紧凑,可以放入缓存,有利于性能提升
在函数hsetCommand中,调用函数hashTypeLookupWriteOrCreate进行哈希对象的查找或创建,在该函数内,当找不到db中指定key对应的哈希对象时,将会调用函数createHashObject进行哈希对象创建,被创建的哈希对象采用OBJ_ENCODING_ZIPLIST编码(需查看此函数的定义请移步哈希对象概览),这是哈希对象的默认编码,此时,被存入的field与value会被紧挨着推入到压缩列表内,field在前value在后
取书中的例子:
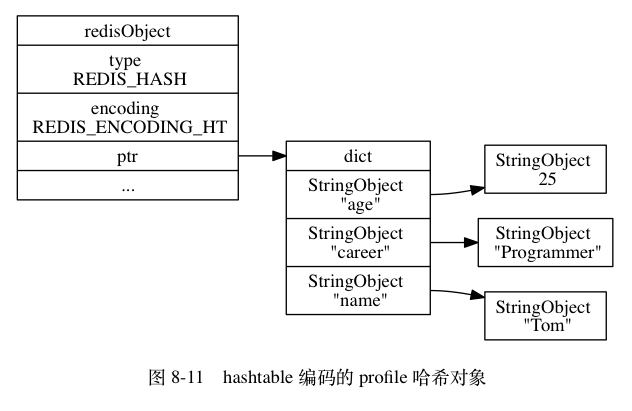
特定情况下哈希对象的编码会发生改变,变为OBJ_ENCODING_HT,并以字典来作为底层实现,这种情况下,字典中的键与值都是字符串对象
还是取书中的例子:
转换到OBJ_ENCODING_HT
前面说了,哈希对象的OBJ_ENCODING_ZIPLIST编码到一定条件会被单向转换到OBJ_ENCODING_HT,默认条件如下:
- 键值对均为为字符串对象,键值对的键对象或值对象中有一个对象长度大于server.hash_max_ziplist_value
- 或 哈希对象保存的键值对个数超过server.hash_max_ziplist_entries
这两个变量默认值如下:
#define OBJ_HASH_MAX_ZIPLIST_ENTRIES 512
#define OBJ_HASH_MAX_ZIPLIST_VALUE 64也可以通过配置文件redis.conf改变server.hash_max_ziplist_value与server.hash_max_ziplist_entries的取值,只需改变下面的字段
# Hashes are encoded using a memory efficient data structure when they have a
# small number of entries, and the biggest entry does not exceed a given
# threshold. These thresholds can be configured using the following directives.
hash-max-ziplist-entries 512
hash-max-ziplist-value 64当发生转换时,保存在ziplist中的全部键值对都会被转移到dict中(存在copy动作):
//转换哈希对象o低层实现 enc为目标编码
void hashTypeConvertZiplist(robj *o, int enc) {
//对象o的原低层实现必须为ziplist
serverAssert(o->encoding == OBJ_ENCODING_ZIPLIST);
if (enc == OBJ_ENCODING_ZIPLIST) {
/* Nothing to do... */
} else if (enc == OBJ_ENCODING_HT) {
hashTypeIterator *hi;
dict *dict;
int ret;
hi = hashTypeInitIterator(o);
dict = dictCreate(&hashDictType, NULL);
while (hashTypeNext(hi) != C_ERR) {
robj *field, *value;
//取出hash对象中的key,当原对象低层实现为ziplist时,copy出原数据创建出字符串对象(低层实现为dict时,共享对象,增加引用计数)
field = hashTypeCurrentObject(hi, OBJ_HASH_KEY);
field = tryObjectEncoding(field);
value = hashTypeCurrentObject(hi, OBJ_HASH_VALUE);
value = tryObjectEncoding(value);
ret = dictAdd(dict, field, value);
if (ret != DICT_OK) {
serverLogHexDump(LL_WARNING,"ziplist with dup elements dump",
o->ptr,ziplistBlobLen(o->ptr));
serverAssert(ret == DICT_OK);
}
}
hashTypeReleaseIterator(hi);
zfree(o->ptr);
o->encoding = OBJ_ENCODING_HT;
o->ptr = dict;
} else {
serverPanic("Unknown hash encoding");
}
}部分哈希对象命令实现

集合对象
集合对象内存的元素是唯一的,其唯一性由底层数据结构实现保证,底层实现可以是intset或dict,intset做底层实现时用于保存整数,dict做底层实现时,键是字符串对象,值是null
转换到OBJ_ENCODING_HT
和哈希对象一样,集合对象也会发生单向编码转换,当符合下面的条件时,集合会从OBJ_ENCODING_INTSET转为OBJ_ENCODING_HT:
- intset内保存整数个数大于server.set_max_intset_entries
- 或 保存的元素不再是整数
变量set_max_intset_entries的默认取值为:
#define OBJ_SET_MAX_INTSET_ENTRIES 512也可通过改变配置文件中字段来改变变量的取值:
# Sets have a special encoding in just one case: when a set is composed
# of just strings that happen to be integers in radix 10 in the range
# of 64 bit signed integers.
# The following configuration setting sets the limit in the size of the
# set in order to use this special memory saving encoding.
set-max-intset-entries 512发生转换时,inset中保存的全部整数,会被转换为字符串对象,随后作为键与null一起添加到字典中:
void setTypeConvert(robj *setobj, int enc) {
setTypeIterator *si;
serverAssertWithInfo(NULL,setobj,setobj->type == OBJ_SET &&
setobj->encoding == OBJ_ENCODING_INTSET);
if (enc == OBJ_ENCODING_HT) {
int64_t intele;
dict *d = dictCreate(&setDictType,NULL);
robj *element;
/* Presize the dict to avoid rehashing */
dictExpand(d,intsetLen(setobj->ptr));
/* To add the elements we extract integers and create redis objects */
si = setTypeInitIterator(setobj);
while (setTypeNext(si,&element,&intele) != -1) {
element = createStringObjectFromLongLong(intele);
serverAssertWithInfo(NULL,element,
dictAdd(d,element,NULL) == DICT_OK); //键为字符串对象element,值为null
}
setTypeReleaseIterator(si);
setobj->encoding = OBJ_ENCODING_HT;
zfree(setobj->ptr);
setobj->ptr = d;
} else {
serverPanic("Unsupported set conversion");
}
}集合对象部分命令实现

有序集合对象
有序集合中的元素按照分值的大小以小到大排序,并且可以通过成员或分值操作存储其中的元素,成员是字符串对象,分值是double浮点。有序集合的编码是OBJ_ENCODING_ZIPLIST与OBJ_ENCODING_SKIPLIST
- 当编码是OBJ_ENCODING_ZIPLIST时,有序集合的元素是是一个紧挨在一起的成员分值对,成员在前,分值在后,成员分值共同构成一个元素,并且元素间按其分值大小有小到大排序
- 当编码是OBJ_ENCODING_SKIPLIST时,使用到了结构体zset,其内部同时含有zskiplist与dict,结构体定义如下:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;虽然zset结构使用到了两个数据结构,但由于两者通过指针共享了元素成员与分值,所以不会存在两份数据,没有浪费空间,并且有以下好处:
- 使用dict来存储成员分值对,有利于利用dict的key-val映射关系,来高效执行成员为目标的相关操作,如查找、删除,并为O(1)的时间复杂度
- 使用skiplist来存储成员分值对,利用了skiplist按分值排序的特性,使得范围相关操作高效,取得logN级别的时间复杂度
由于zset同时需要这两种操作,dict与skiplist一起使用,实现了操作性能互补
当编码为OBJ_ENCODING_SKIPLIST,有序集合对象像这样:
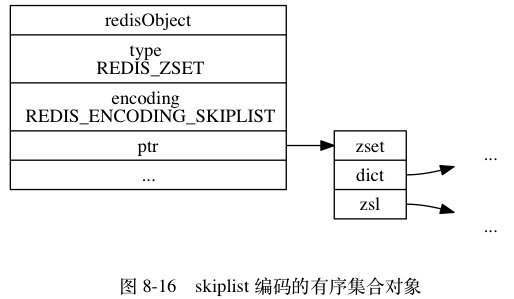
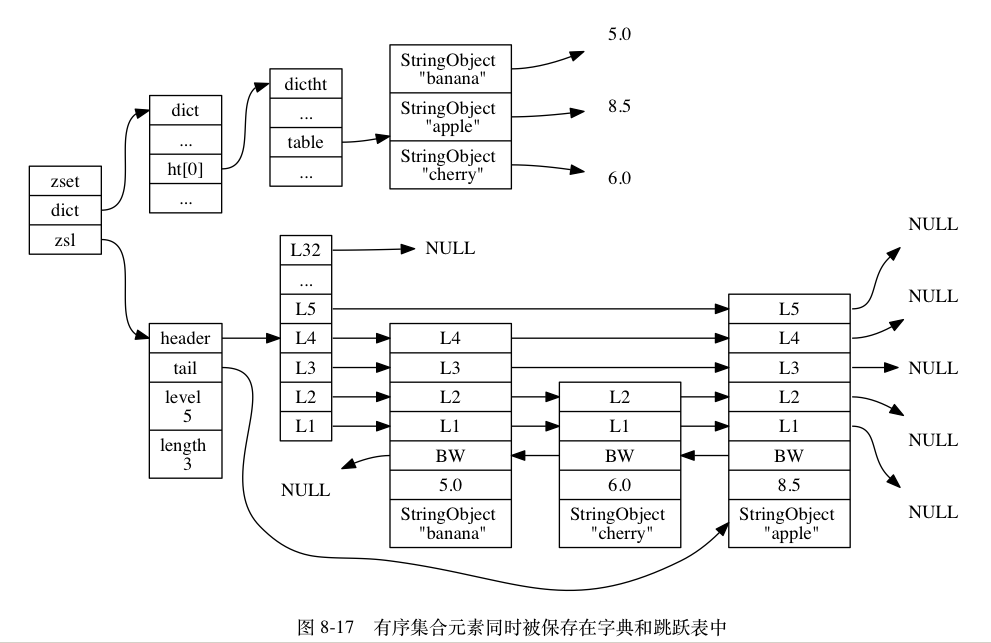
注:实际情况下,图中重复出现的对象是共享的
编码转换
转换到OBJ_ENCODING_SKIPLIST
当满足以下条件时有序集合对象的编码会从OBJ_ENCODING_ZIPLIST转变为OBJ_ENCODING_SKIPLIST:
- 压缩列表内保存的元素个数超过server.zset_max_ziplist_entries
- 或被保存元素的成员字符串长度超过server.zset_max_ziplist_value
变量zset_max_ziplist_entries与zset_max_ziplist_value的默认取值为:
#define OBJ_ZSET_MAX_ZIPLIST_ENTRIES 128
#define OBJ_ZSET_MAX_ZIPLIST_VALUE 64也可通过改变配置文件中字段来改变变量的取值:
# Similarly to hashes and lists, sorted sets are also specially encoded in
# order to save a lot of space. This encoding is only used when the length and
# elements of a sorted set are below the following limits:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64发生转换时,保存在ziplist中的全部元素(成员-分值对)将会被逐个取出插入跳表,并将元素添加入字典(取元素时存在copy动作):
void zsetConvert(robj *zobj, int encoding) {
zset *zs;
zskiplistNode *node, *next;
robj *ele;
double score;
if (zobj->encoding == encoding) return;
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl = zobj->ptr;
unsigned char *eptr, *sptr;
unsigned char *vstr;
unsigned int vlen;
long long vlong;
if (encoding != OBJ_ENCODING_SKIPLIST)
serverPanic("Unknown target encoding");
zs = zmalloc(sizeof(*zs));
zs->dict = dictCreate(&zsetDictType,NULL);
zs->zsl = zslCreate();
//取出ziplist的首个元素(成员)的地址以及第二个元素(分值)地址
eptr = ziplistIndex(zl,0);
serverAssertWithInfo(NULL,zobj,eptr != NULL);
sptr = ziplistNext(zl,eptr);
serverAssertWithInfo(NULL,zobj,sptr != NULL);
//逐个取出分值、成员字符串对象,插入跳表,随后将对象与分值地址添加到字典内并增加引用计数
while (eptr != NULL) {
score = zzlGetScore(sptr);
serverAssertWithInfo(NULL,zobj,ziplistGet(eptr,&vstr,&vlen,&vlong));
if (vstr == NULL)
ele = createStringObjectFromLongLong(vlong);
else
ele = createStringObject((char*)vstr,vlen);
/* Has incremented refcount since it was just created. */
node = zslInsert(zs->zsl,score,ele);
serverAssertWithInfo(NULL,zobj,dictAdd(zs->dict,ele,&node->score) == DICT_OK);
incrRefCount(ele); /* Added to dictionary. */
zzlNext(zl,&eptr,&sptr);
}
zfree(zobj->ptr);
zobj->ptr = zs;
zobj->encoding = OBJ_ENCODING_SKIPLIST;
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
//省略
} else {
serverPanic("Unknown sorted set encoding");
}
}转换到OBJ_ENCODING_ZIPLIST
有序集合对象的编码会也可以从OBJ_ENCODING_SKIPLIST转回OBJ_ENCODING_ZIPLIST,条件与之前描述的相反,转换条件判断为:
- 加载rdb文件时,加载到的value对象是RDB_TYPE_ZSET
- 对有序集合求交集
转换过程如下:
void zsetConvert(robj *zobj, int encoding) {
zset *zs;
zskiplistNode *node, *next;
robj *ele;
double score;
if (zobj->encoding == encoding) return;
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
//省略
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
unsigned char *zl = ziplistNew();
if (encoding != OBJ_ENCODING_ZIPLIST)
serverPanic("Unknown target encoding");
/* Approach similar to zslFree(), since we want to free the skiplist at
* the same time as creating the ziplist. */
zs = zobj->ptr;
dictRelease(zs->dict);
node = zs->zsl->header->level[0].forward; //从跳表内首个元素开始
zfree(zs->zsl->header);
zfree(zs->zsl);
//依次取出每个跳表跳表节点中存储的成员与分值,并存入压缩列表
while (node) {
ele = getDecodedObject(node->obj);
zl = zzlInsertAt(zl,NULL,ele,node->score);
decrRefCount(ele);
next = node->level[0].forward;
zslFreeNode(node);
node = next;
}
zfree(zs);
zobj->ptr = zl;
zobj->encoding = OBJ_ENCODING_ZIPLIST;
} else {
serverPanic("Unknown sorted set encoding");
}
}部分有序集合对象命令实现

类型检查与命令多态
redis中操作键的命令分为两种:
- 一种可以针对任何类型的键执行,如DEL 命令、 EXPIRE 命令、 RENAME 命令、 TYPE 命令、 OBJECT 命令
- 另一种命令只能针对特定类型键执行
对于特定类型相关命令,执行命令时有以下流程:
- 执行具体操作前,检查值对象类型,是否为命令所需类型,是则执行命令;否则返回类型错误
- 执行命令时,查看值对象的编码类型,再调用编码对应数据结构实现的API实现命令