上面我们谈了在搜索引擎中,如何建立索引,这里,我们讲如何自动下载互联网上所有的网页,重点就是图论中的遍历算法。
1.图论和网络爬虫
遍历算法主要有两种,一种是深度优先遍历,一种是广度优先遍历。所谓深度优先遍历,就是从一个节点开始,一直沿着一条路走到底,直到没路了,再回过头去找别的路,再一路走到底。说白了,就是往深处走。同样的,广度优先遍历,顾名思义,就是从一个节点开始,先把和他相连的都走一边,然后再以走过的节点为中心,一层一层走。拿网页来说,深度优先遍历,就是打开一个网页,选择其中一个URL,再打开,再在打开的URL中选择一个URL接着打开,每次只打开一个,知道页面没有URL为止;广度优先,则是把一个页面中所有的URL都打开,然后遍历这些URL,把对应页面的URL也都打开,以此类推。当然这些已经访问过的URL都是要做标记的(使用哈希表),每个URL都只访问一次。这就是我们讲的网络爬虫。
2.延伸阅读:图论的两点补充说明
2.1欧拉七桥问题的证明
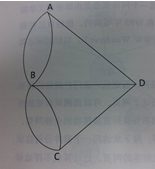
如图是欧拉七桥问题的抽象图,对于图中的每一个顶点,它相连的边的数量定义为它的度。
定理:如果一个图能够从一个顶点出发,每条边不重复的遍历一遍回到这个定点,那么每个定点的度数必定是偶数。
证明:假如能够遍历图的每一条边各一次,那么对于每个顶点,需要从某条边进入顶点,同时从另一条边离开这个顶点。进入和离开顶点的次数是相同的。因此每个顶点有多少条进入的边,就有多少条出去的边。也就是说,每个顶点相连的边的数量是成对出现的,即每个顶点的度是偶数。
2.2 构建网络爬虫的工程要点
前面我们说过了,爬虫有深度优先和广度优先两说,那么我们是用哪个呢?
理论上来说这两个算法效果差不多。但是在现实中是做不到的。如果我们把爬虫定义成“如何在有限时间里最多地爬下最重要的网页”。显然一个网站最重要的是他的首页,如果一个爬虫很小,我们只能下载有限的网页,那么,我们就应该首先下载他主页上的网页,因为放在主页的网页,一般来说都是比较重要的,这是,BFS明显优于DFS。
那么DFS的优势在哪呢?我们知道,网络通信有一个著名的“握手”定理(百度自查)。所以每次下载前都一个额外的消耗,如果消耗太多,效率就低了。实际的网络爬虫是由成千上万个服务器组成的分布式系统,对于一个网站,一般是由特定的服务器(组)下载,下载完一个,再进入另一个,而不是每个先下载一部分,再回头接着下。这样就可以避免“握手”产生的消耗。这有点像DFS(实际上并不是DFS)。
不管是DFS还是BFS,都需要有一个调度系统,决定接下来下载哪个。
其次,我们知道,现在的很多网站,都用了很多脚本代码,URL不是直接可见的,需要运行脚本后才行。这时,我们就需要做一件事:模拟浏览器,访问一个网页。这在python里面是很简单的一件事(就一行代码)。不过有些网页的脚本写得很不规范,解析起来非常困难,导致搜索引擎可能找不到它。
最后,我们还需要一张URL表(哈希表)来记录哪些网页下载过的。这样就可以避免重复多次下载某个网页。哈希表的好处我就不多说了,查询效率比较高。但是要考虑这样一个问题,爬虫是一个庞大的过程,表也会很大,建立和维护一张哈希表不容易。首先,一台服务器可能存储不下;其次,由于下载前后都需要访问哈希表,并做修改,那么这个存储哈希表的服务器的通信就成了爬虫的瓶颈问题,一次过多访问可能造成服务器崩溃。下面是一些参考的解决方案:首先可以采用类似哈希的方法,根据URL安排服务器下载,这样的可以避免很多服务器对同一个URL做出是否需要下载的判断。然后申请一批URL下载。
3.小结
图论在出现后的很长时间里都是默默无闻的,大部分人体会不出其作用,但随着互联网的出现,图的遍历一下子又有了用武之地!