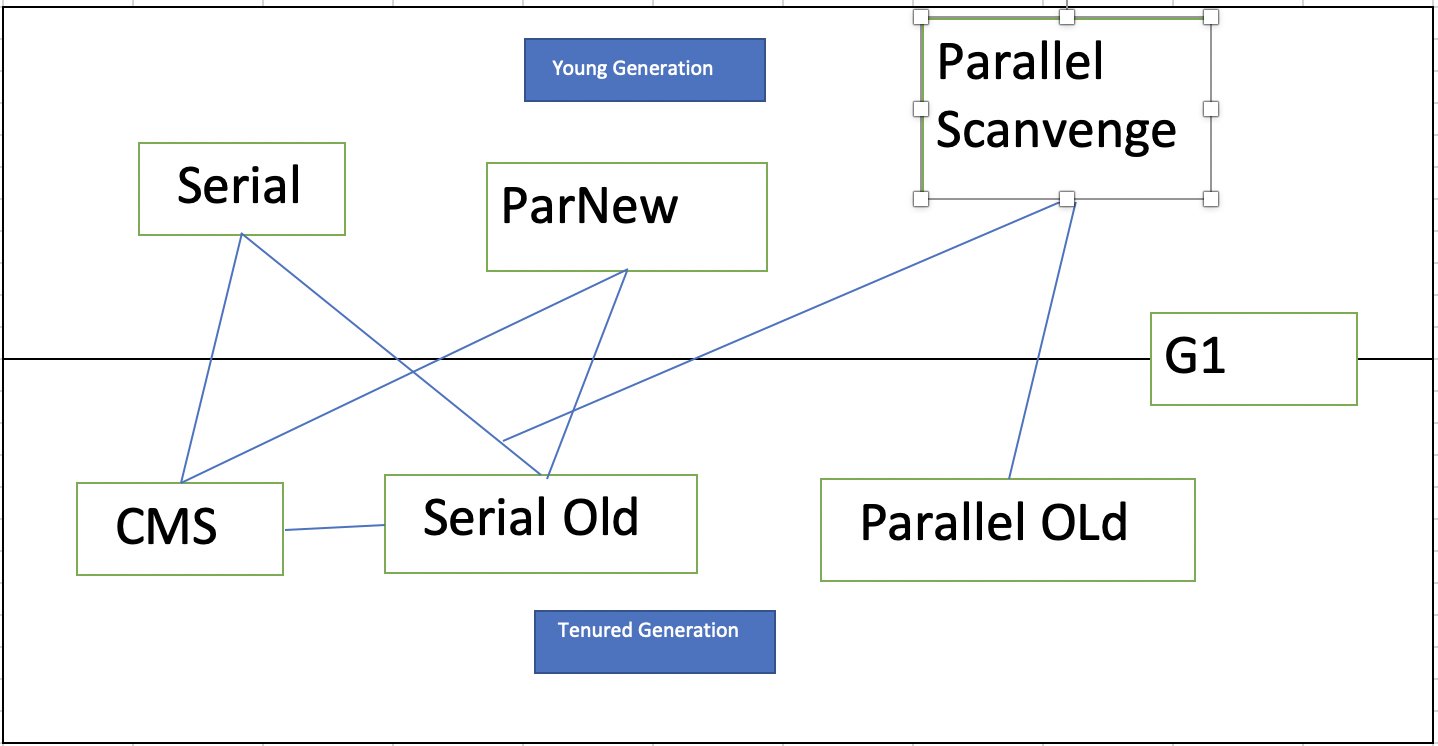
在上一篇提到垃圾收集算法,那么在堆中怎么选择呢?
Young区:复制算法(对象在被分配之后,可能生命周期比较短,Young区复制效率比较高)
Old区:标记清除或标记整理(Old区对象存活时间比较长,没必要进行复制,直接做标记之后清理)
-
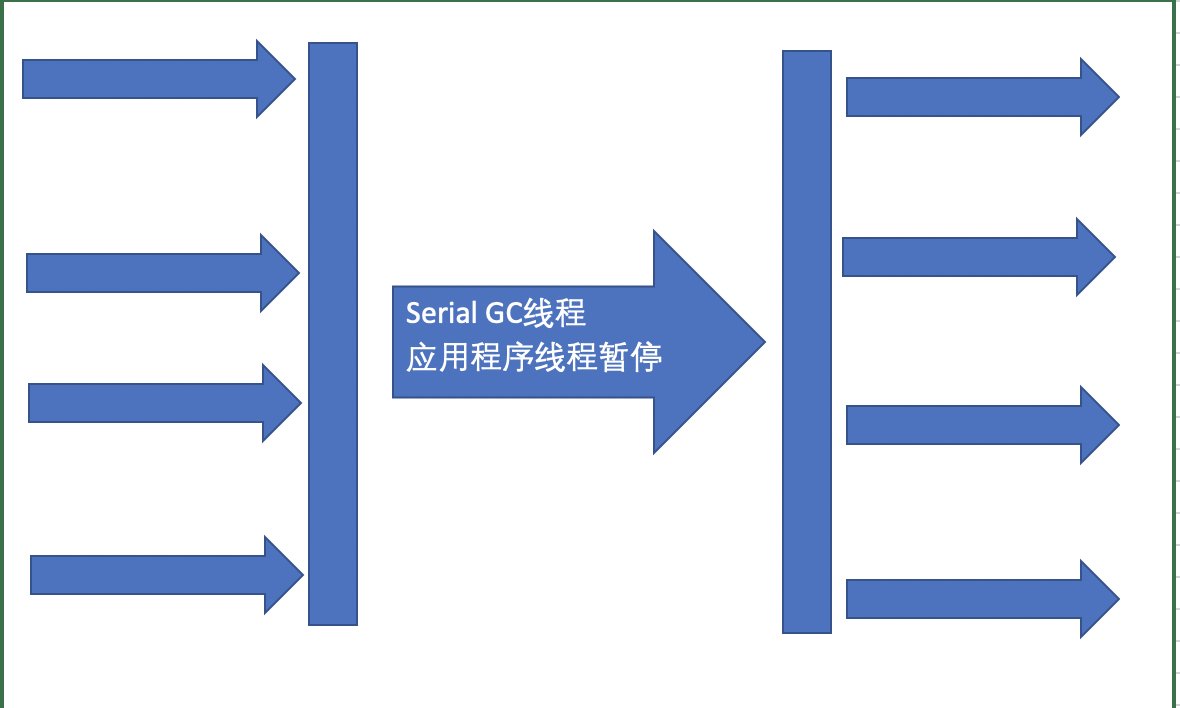
Serial收集器
Serial搜集器是最基本的收集器。它是一种单线程的收集器,不仅仅以为着他指挥使用一个CPU或者一条收集线程去完成垃圾收集工作,更重要是其在进行垃圾回收的时候需要暂停其他线程。
优点:简单高效,拥有很高的单线程手机效率
缺点:手机过程需要暂停的所有线程
算法:复制算法
使用范围:新生代
应用:client模式下的默认新生代收集器
-
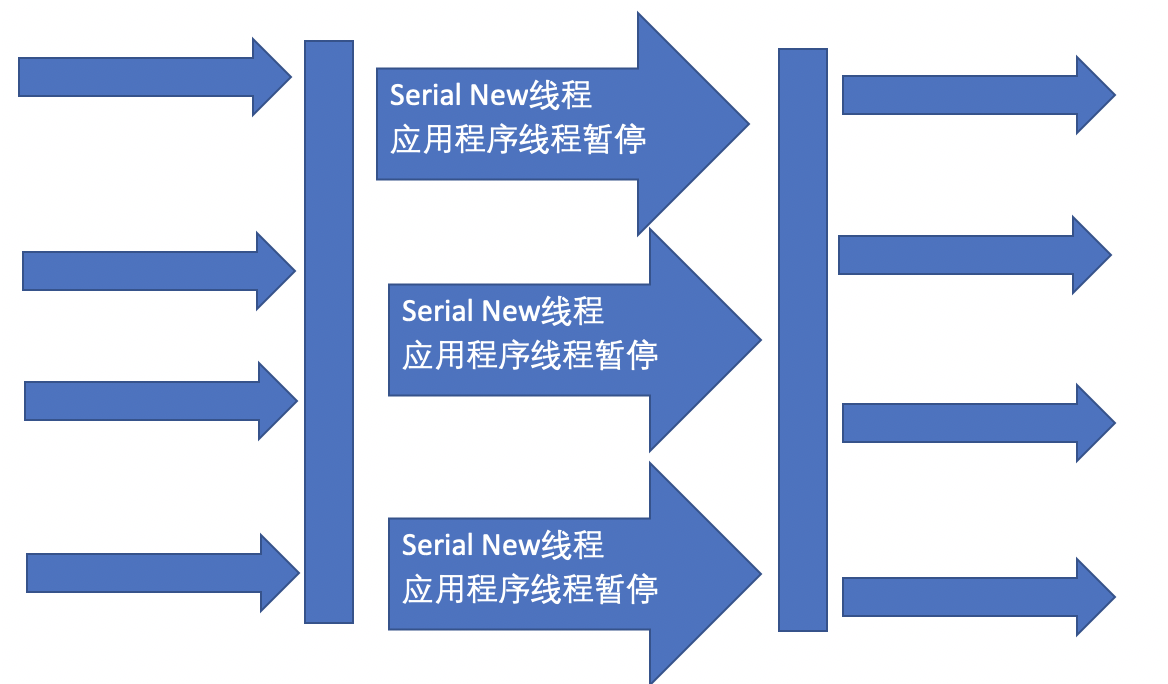
ParNew收集器
可以把这个收集器理解为Serial收集器的多线程版本
优点:在多CPU的时候,比Serial效率高
缺点:收集过程暂停所有应用程序线程,单CPU时比Serial效率差
算法:复制算法
使用范围:新生代
应用:运行在server模式下的虚拟机中首选的新生代收集器
-
Parallel Scavenge收集器
Parallel Scavenge收集器是一个新生代收集器,它也是使用复制算法的收集器,又是并行的多线程收集器,看上去和ParNew一样,但是Parallel Scanvenge更关注系统的吞吐量
吞吐量=运行用户代码的时间/(运行用户代码的时间+垃圾收集时间)
如果吞吐量越大,意味着垃圾收集的时间越短,则用户代码可以充分利用CPU的资源,尽快完成程序的运算任务。
-XX:MaxGCPauseMillis 控制最大的垃圾收集停顿时间 -XX:GCTimeRatio 直接设置吞吐量的大小
-
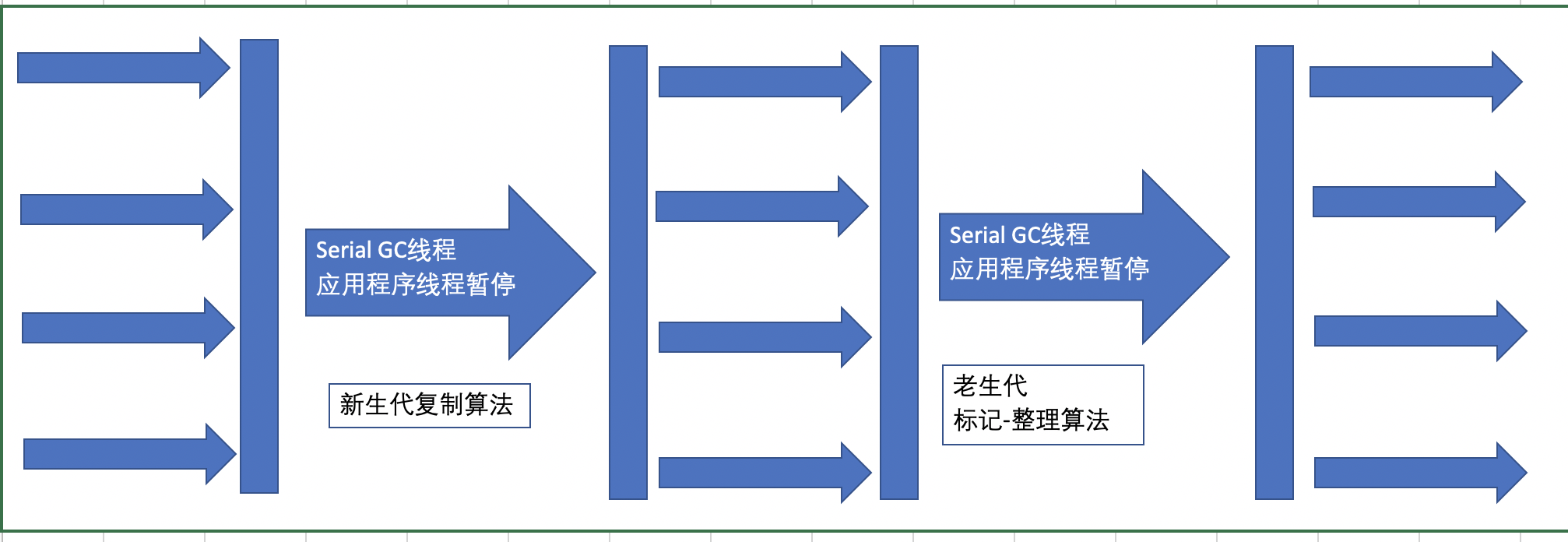
Serial Old收集器
Serial Old收集器是Serial收集器的老年代版本,也是一个单线程收集器,不同的是采用“标记-整理算法”,运行过程和Serial收集器一样。
-
Parallel Old收集器
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理算法”进行垃圾回收。吞吐量优先
-
CMS收集器
CMS(concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。
采用的是“标记-清除算法”。
其过程为:
-
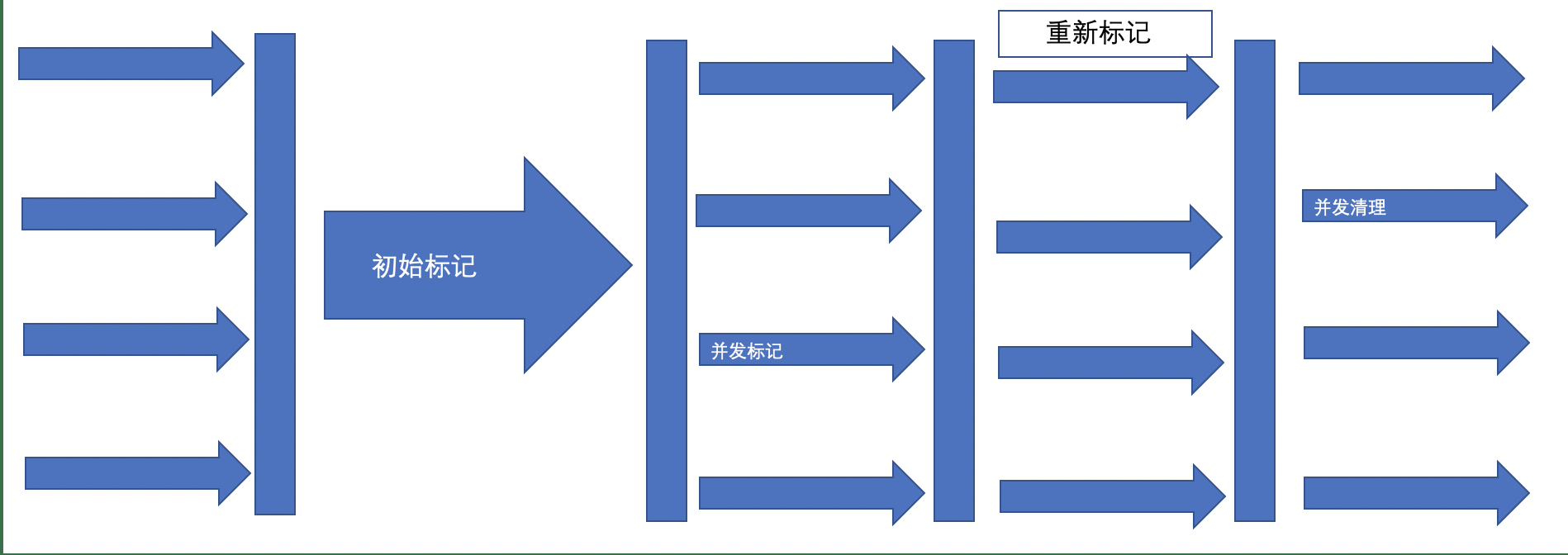
- 初始标记 CMS initial mark 标记GC Roots能关联到的对象 Stop The World--》速度很快
- 并发标记 CMS concurrent mark 进行GC Roots Tracing
- 重新标记 CMS remark。修改并发标记因用户程序变动的内容。Stop The World
- 并发清除 CMS concurrent sweep
由于整个过程中,并发标记和并发清除,收集器线程可以与用户线程一起工作,所以总体上来说,CMS收集器的内存回收过程是与用户线程一起并发的执行的。
优点:并发收集、低停顿
缺点:产生大量的空间碎片、并发阶段会降低吞吐量
-
G1收集器
G1的特点:
-
- 并行与并发
- 分代收集(仍然保留了分代的概念)
- 空间整合(整体上属于“标记-整理“算法,不会导致空间碎片)
- 可预测的停顿(比CMS更先进的地方在于能让使用者明确指定一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒)
- G1收集器会先收集存活对象少的区域,也就是垃圾对象多的区域,这样可以有大量的空间释放出来,这就是Garbage First的由来
使用G1收集器时,Java堆的内存布局与就与其他收集器有很大的差别,它将整个java堆划分为多个大小相等的独立区间(region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,它们都是一部分region(不需要连续)的集合。
工作过程可以分为如下几个步骤:
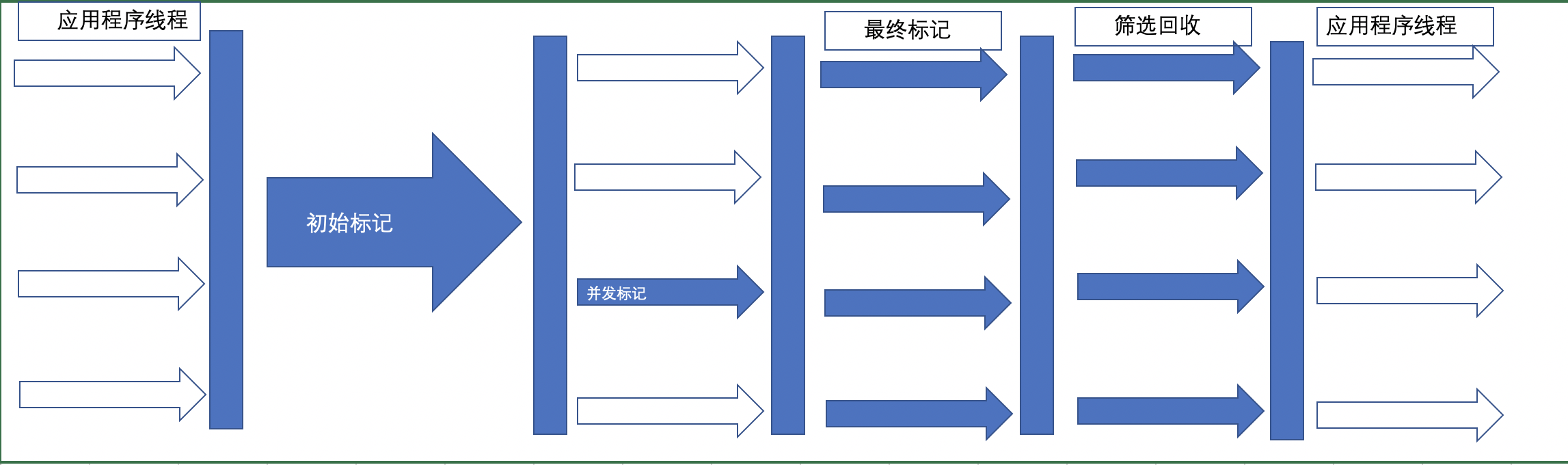
- 初始标记(Initial Marking) 标记一下GC Roots能够关联的对象,并且修改TAMS的值,需要暂停用户线程。
- 并发标记(concurrent Marking) 从GC Roots进行可达性分析,找出存活对象,与用户线程并发执行。
- 最终标记(Final Marking) 修正在并发标记阶段因为用户程序的并发执行导致变动的数据,需要暂停用户线程
- 筛选回收(Live Data Counting and Evacuation) 对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间制定回收计划
如图所示:
-
垃圾收集器分类
- 串行收集器-》Serial和Serial Old
- 只能有一个垃圾回收线程执行,用户线程暂停。适用于内存较小的嵌入式设备
- 并行收集器【吞吐量优先】-》Parallel Scanvenge、Parallel Old
- 多余垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。适用于科学计算、后台处理等若交互场景。
- 并发收集器【停顿时间优先】-》CMS、G1
- 用户线程和垃圾收集线程同时执行(但不一定是并行的,可能是交替执行的),垃圾收集线程在执行的时候不会停顿用户线程的运行。适用于对时间有要求的场景。比如web
- 串行收集器-》Serial和Serial Old
-
吞吐量和停顿时间
- 停顿时间-》垃圾收集器进行垃圾回收终端应用执行响应的时间
- 吞吐量-〉运行用户代码时间/(运行用户代码时间+垃圾收集时间)
【停顿时间越短就越适合和用户交互的程序,良好的响应速度能提升用户的体验;
高吞吐量则可以高效的利用CPU时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多的交互的任务。
】
总结:吞吐量和停顿时间是评价垃圾回收器好处的标准,其实调优也就是在观察者两个变量。
如何选择选择合适的垃圾收集器
- 优先调整堆的大小让服务器自己来选择
- 如果内存大小小于100M,使用串行收集器
- 如果是单核,并且没有停顿时间要求,使用串行或jvm自己选
- 如果允许停顿时间超过1s,选择并行或jvm自己选
- 如果响应时间最重要,并且不能超过1s,使用并发收集器
如何开启需要的垃圾收集器?
-
串行
-
-XX: +UseSerialGC
-
-XX: +UseSerialOldGC
-
-
并行(吞吐量优先)
-
-XX:+UseParallelGC
-
-XX: +UseParallelOldGC
-
- 并发收集器(响应时间优先)
- -XX: +UseconcMarkSweepGC
- -XX: +UseG1GC
有关在不同垃圾收集器中使用的不同的算法的图解参考:https://www.cnblogs.com/LBJLAKERS/p/12287322.html