1.安装Scrapy(Windows)
1.pip install lxml
该过程中可能出现的问题:error:command 'E:\\program file <x86>\\Microsoft Visual Studio14.0\UC\BIN\\x86_amd64\\c1.exe' faild with exit status2(该错误是因为缺少lxml)
解决方法:通过https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 下载lxml:

可以通过Ctrl+f查找,注意你需下载的是32位还是64位,由你的Python位数决定。
2.pip install pyOpenSSL -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
3.pip install Twisted-20.3.0-cp39-win amd64.whl
该过程中可能出现问题
解决方案:跟上面一样,https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 下载Twisted
4.使用命令安装Scrapy:pip install Scrapy -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
在Pycharm中运行Scrapy爬虫项目的基本操作
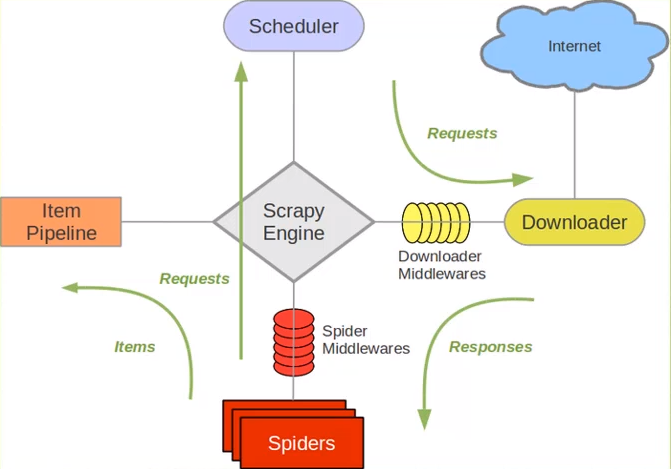
Scrapy框架之初窥门径
使用Scrapy抓取一个网站一共需要四个步骤
--创建一个Scrapy项目
--定义Item容器
--编写爬虫
--存储内容
一、建立Scrapy模板。进入自己的工作目录,shift + 鼠标右键进入命令行模式,在命令行模式下,
输入scrapy startproject 项目名 ,如下:
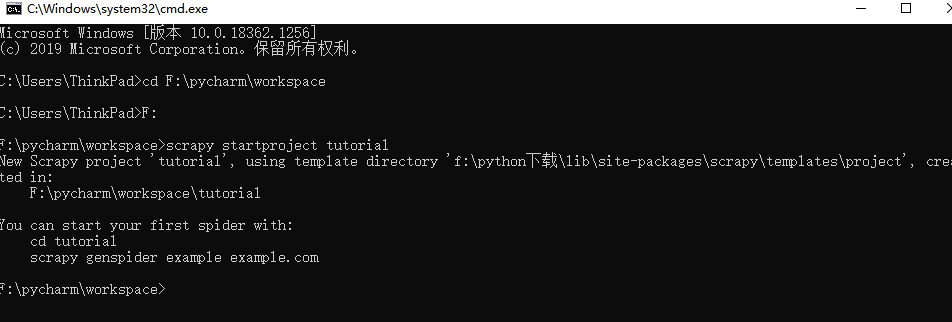
看到以上的代码说明项目已经在工作目录中建好了。
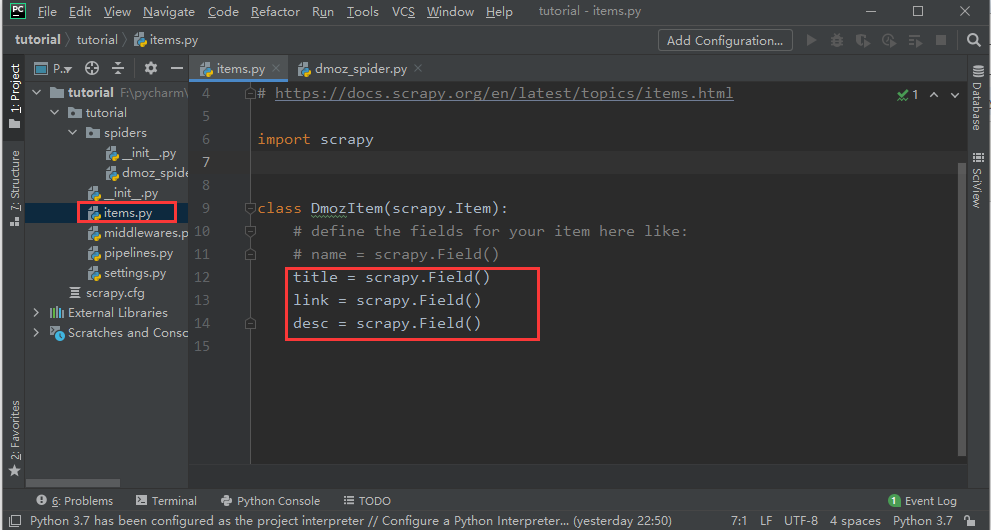
二、定义Item容器
Item是保存爬取到的数据的容器,其使用方法和python字典类似,并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
三、编写爬虫
接下来是编写爬虫类Spider,Spider是用户编写用于从网站上爬取数据的类。
其包含了一个用于下载的初始URL,然后是如何跟进网页中的链接以及如何分析页面中的内容,还有提取生成item的方法。

爬取数据:
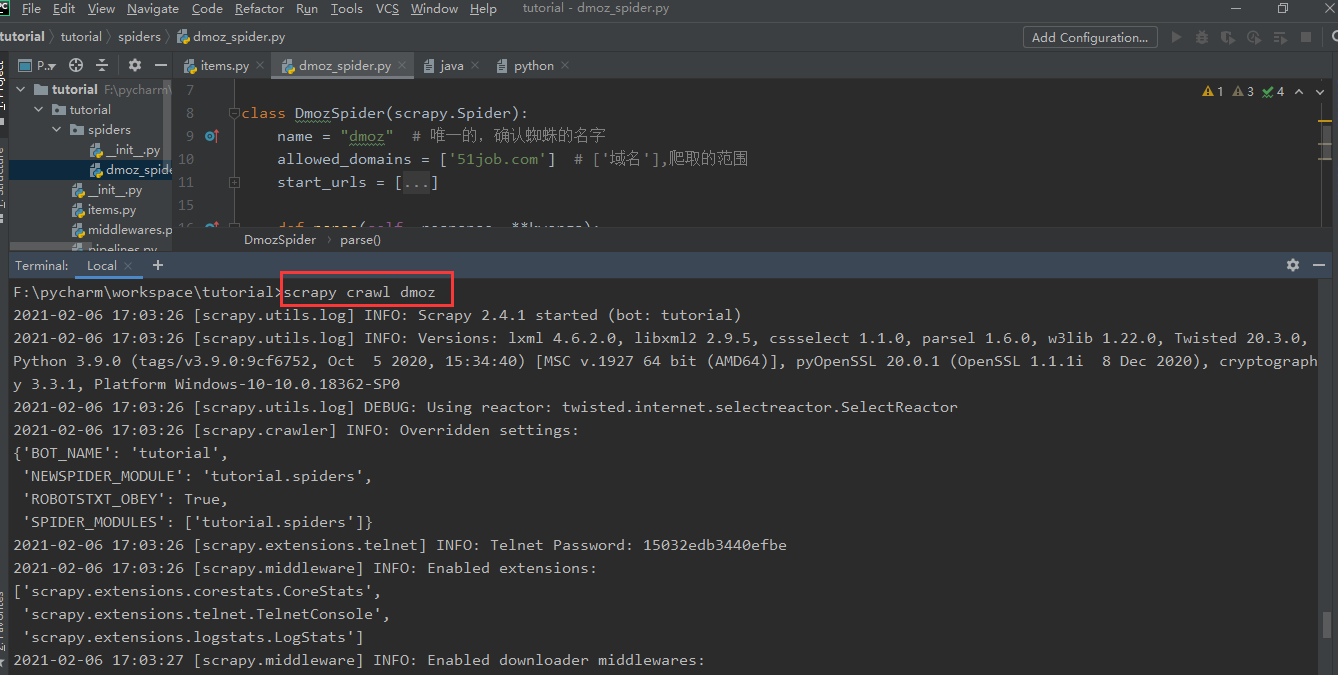
进入shell模式:scrapy shell "网址"
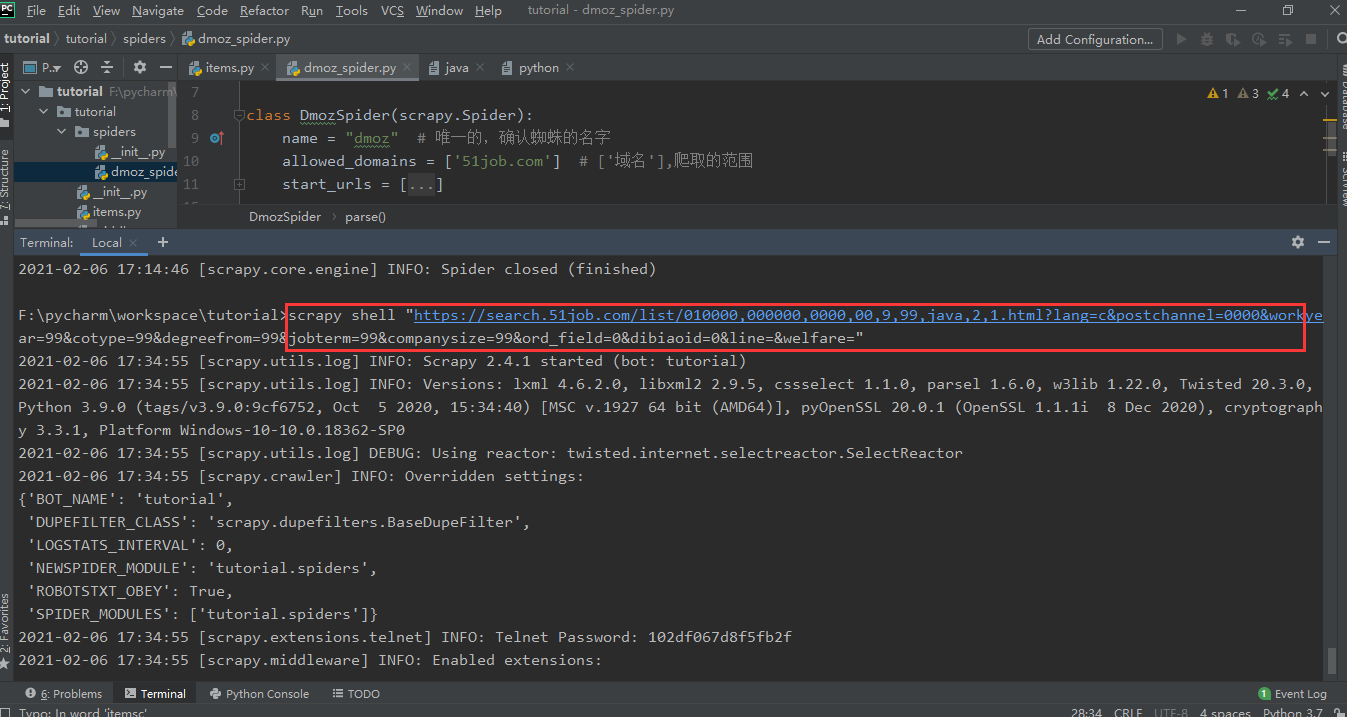
结果导出为最常用的json格式:

四、Scrapy Selectors
在Scrapy中是使用一种基于XPath和CSS的表达式机制:Scrapy Selectors。
Selector是一个选择器,它有四个基本的方法:
xpath():传入xpath表达式,返回该表达式所对应的所有节点的selector list列表。
css():传入CSS表达式,返回该表达式所对应的所有节点的selector list列表。
extract():序列化该节点为unicode字符串并返回list。
re():根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
XPath是一门在网页中查找特定信息的语言。所以用Xpath来筛选数据,要比使用正则表达式容易些。
XPath表达式例子:
/html/head/title:选择HTML文档中<head>标签内的<title>元素
/html/head/title/text():选择上面提到的<title>元素的文字
//td:选择所有的<td>元素
//div[@class="mine"]:选择所有具有class="mine"属性的div元素
五、补充python爬虫代理
步骤:
1.参数是一个字典{'类型':'代理ip:端口号'}
proxy_support = urllib.request.ProxyHandler({})
2.定制、创建一个opener
opener = urllib.request.build_opener(proxy_support)
3.安装opener
urllib.request.install_opener(opener)
4.调用opener
opener.open(url)
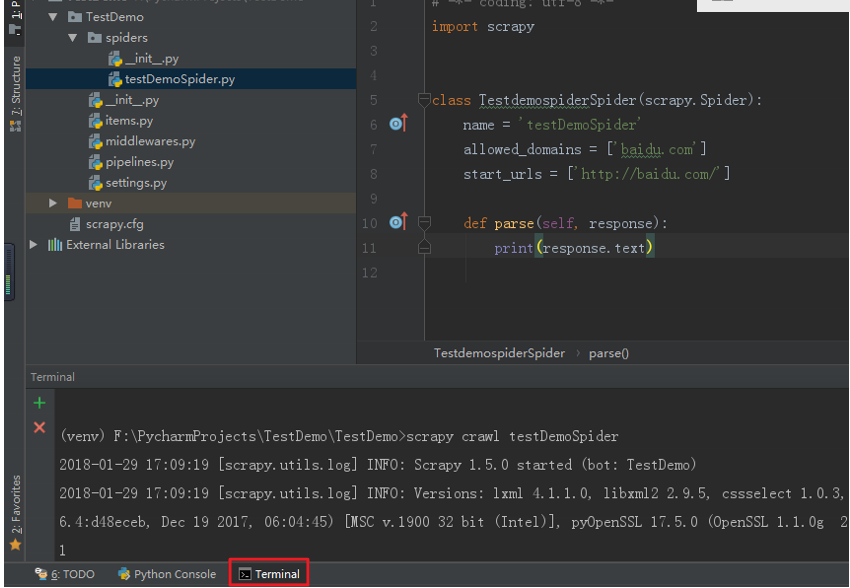
六、Pycharm中scrapy的运行设置。
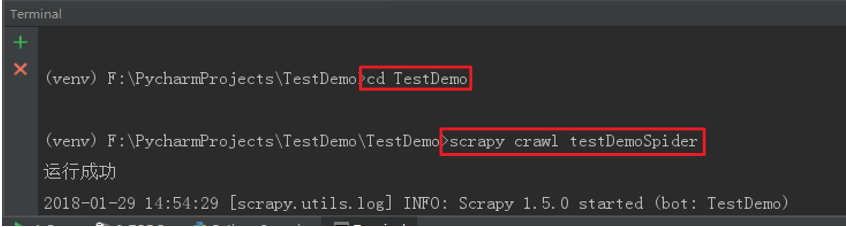
法一:Scrapy爬虫的运行需要到命令行下运行,在pychram中左下角有个Terminal,点开就可以在Pycharm下进入命令行,默认
是在项目目录下的,要运行项目,需要进入下一层目录,使用cd TestDemo 进入下一层目录,然后用scrapy crawl 爬虫名 , 即可运行爬虫。
如图:
法二:在TestDemoSpider目录和scrapy.cfg同级目录下面,新建一个entrypoint.py文件,如图:
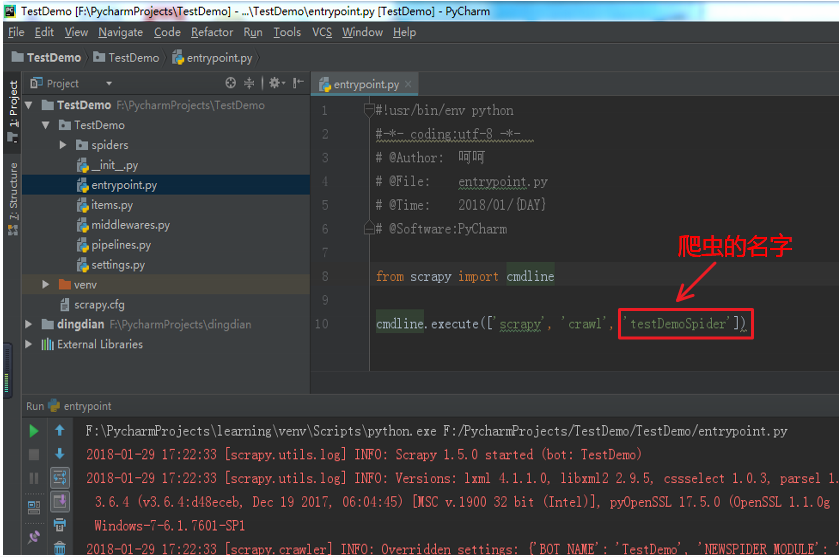
其中只需把红色框体内的内容改成相应的爬虫的名字就可以在不同的爬虫项目中使用了,直接运行该文件就能使得Scrapy爬虫运行
Tips:在创建爬虫时使用模板更加方便一些,如:
scrapy genspider [-t template] <name> <domain> 即:scrapy genspider testDemoSpider baidu.com
参考博客:https://www.cnblogs.com/llssx/p/8378832.html