1、背景知识
Spark有3种集群部署模式,分别是Standalone、Mesos和YARN,这3种模式都属于master/slave模式。
-
Standalone独立模式,Spark 原生的简单集群管理器, 自带完整的服务, 可单独部署到一个集群中,无需依赖任何其他资源管理系统, 使用 Standalone 可以很方便地搭建一个集群,一般在公司内部没有搭建其他资源管理框架的时候才会使用。
-
Mesos模式,一个强大的分布式资源管理框架,它允许多种不同的框架部署在其上,包括 yarn,由于mesos这种方式目前应用的比较少,这里没有记录mesos的部署方式。
-
YARN模式: 统一的资源管理机制, 在上面可以运行多套计算框架, 如map reduce、storm 等, 根据 driver 在集群中的位置不同,分为 yarn client 和 yarn cluster。
由于在实际工厂环境下使用的绝大多数的集群管理器是 Hadoop YARN,因此我们关注的重点是 Hadoop YARN 模式下的 Spark 集群部署。
2、使用软件及其版本
环境
虚拟机:VirtualBox 6.0.24 r139119
Linux:CentOS 7
Windows:Windows10
软件
Spark
工具
远程连接工具:XShell6
SFTP工具:FileZilla3.33.0
3、目标
-
Spark集群部署
4、操作步骤
-
下载Spark
在Spark官网
`http://spark.apache.org/downloads.html,下载spark。由于前面使用的hadoop是hadoop2.6的cdh5.7版本,官网并没有直接提供,只能在官网下载二进制的版本,进行重新编译
-
安装Spark
Spark On YARN模式中无须单独部署Spark集群,其本质是将Spark程序提交到Hadoop集群的YARN中运行,此时的Spark只作为提交程序的客户端,由于前面已经部署好了Hadoop高可用集群,所以只需要在master节点部署即可
-
上传spark安装包到master节点,解压安装,使用命令
tar -zxvf spark-2.4.7-bin-hadoop2.6.tgz -C ~/app/ -
修改配置文件
进入spark安装目录下的conf目录
-
修改spark-en.sh文件,使用命令
cp spark-env.sh.template spark-env.sh复制spark-env.sh文件,进行编辑,使用命令
sudo vi spark-env.sh在末尾添加配置信息
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_131
export HADOOP_CONF_DIR=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
-
修改master主机中hadoop目录中的/etc/hadoop下的yarn-site.xml,使用命令
sudo vi yarn-site.xml添加配置内容内容
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>-
yarn.nodemanager.pmem-check-enabled:是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true
-
yarn.nodemanager.vmem-check-enabled:是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true

-
-
分发yarn-site.xml到slave01,slave02,使用命令
scp yarn-site.xml hadoop@slave01:~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
scp yarn-site.xml hadoop@slave02:~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
-
-
修改环境变量
使用命令
sudo vi /etc/profile添加配置信息
export SPARK_HOME=/home/hadoop/app/spark-2.4.7-bin-hadoop2.6
export PATH=$SPARK_HOME/bin:$PATH
使用
source /etc/profile命令,使配置生效。 -
验证
使用yarn方式启动spark,使用命令:
spark-shell --master yarn --deploy-mode client,进入spark-shell交互界面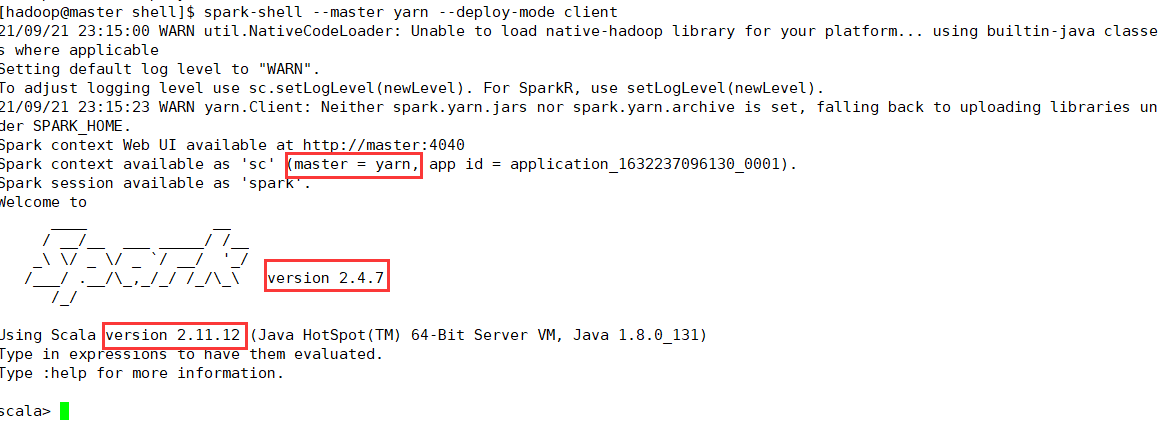
可以看到使用的yarn方式,spark版本是2.4.7,scala的版本是2.11.12,显示上述界面,表示Spark on Yarn 部署成功!
-
Spark集群测试
-
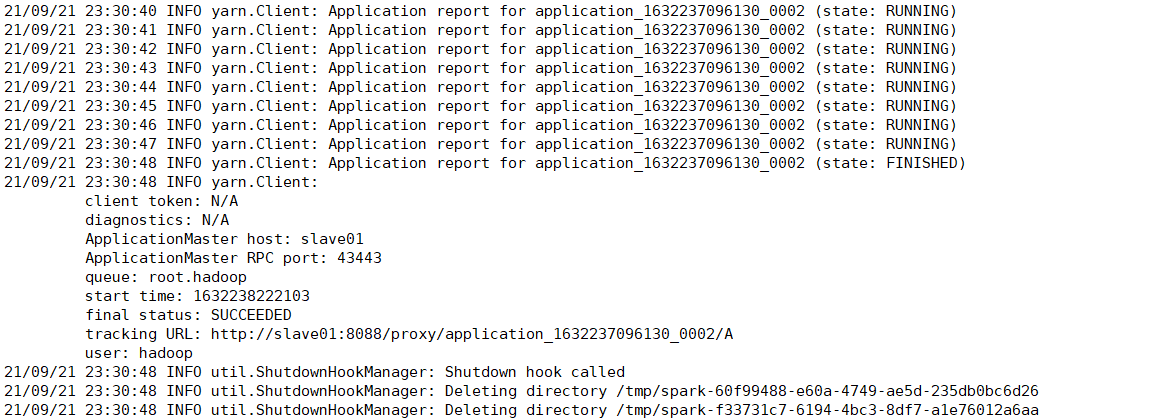
使用Spark官方提供的示例SparkPi,进行集群测试,验证spark任务是否可以成功提交到yarn中运行,使用命令:
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 2g \
--executor-memory 1g \
--executor-cores 1 \
/home/hadoop/app/spark-2.4.7-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.7.jar 10-
--class:调用最后一行中jar包指定类。
-
--master yarn:指定spark任务提交到yarn运行。
-
deploy-mode cluster:指定spark on yarn的运行模式为client,便于查看输出结果。
-
driver-memory 2g:指定每个Driver的可用内存为2GB。
-
executor-memory 1g:指定每个Executor的可用内存为1GB。
-
executor-cores 1:指定每个Executor使用cup的核心数为一
-
执行完上述命令后,在浏览器输入
http://192.168.137.2:8088查看yarn管理界面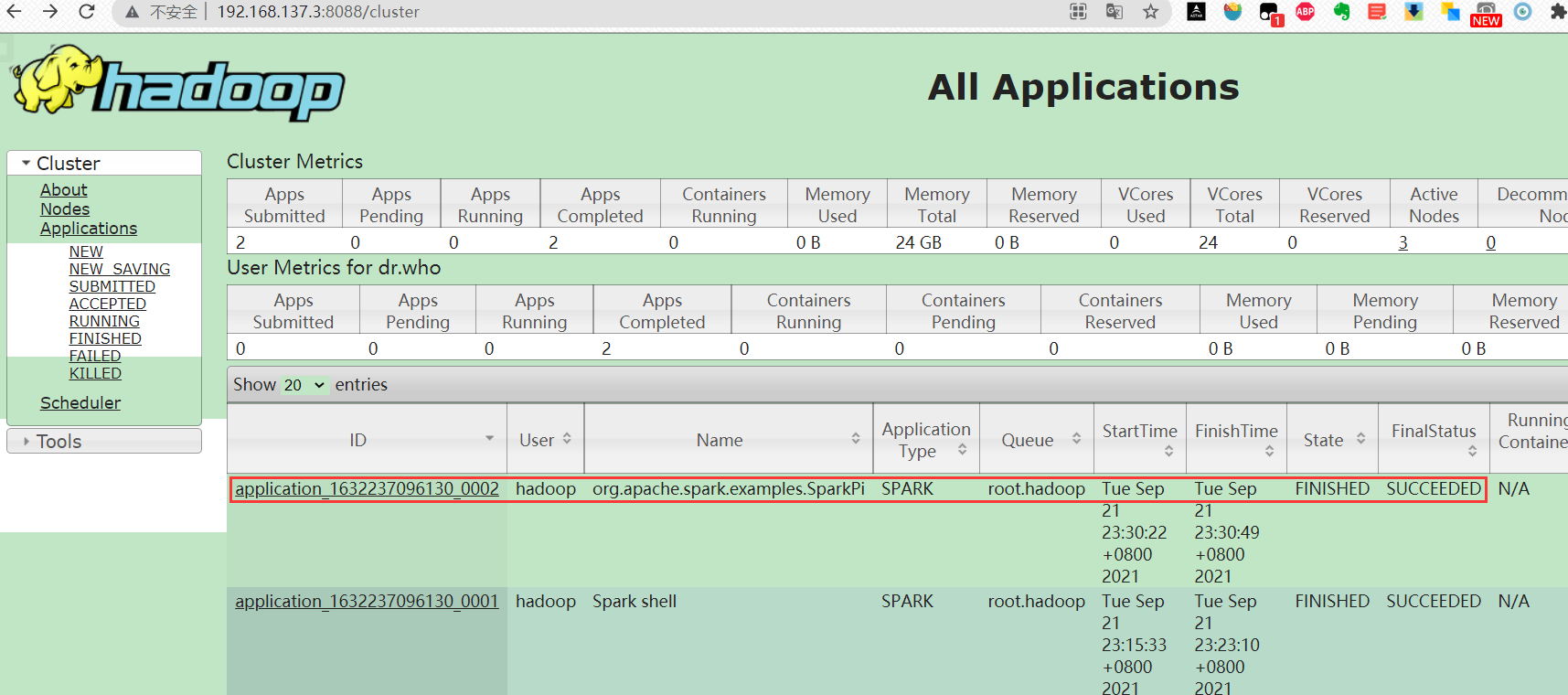
可以看到任务已经提交到yarn集群之上。
点击任务ID,进入界面
点击
logs链接,进入界面
点击输出日志

可以看到输出结果
-
-
5、总结