一、前述
本文讲述池化层和经典神经网络中的架构模型。
二、池化Pooling
1、目标
降采样subsample,shrink(浓缩),减少计算负荷,减少内存使用,参数数量减少(也可防止过拟合)
减少输入图片大小(降低了图片的质量)也使得神经网络可以经受一点图片平移,不受位置的影响(池化后相当于把图片上的点平移了)
正如卷积神经网络一样,在池化层中的每个神经元被连接到上面一层输出的神经元,只对应一小块感受野的区域。我们必须定义大小,步长,padding类型
池化神经元没有权重值,它只是聚合输入根据取最大或者是求均值
2*2的池化核,步长为2,没有填充,只有最大值往下传递,其他输入被丢弃掉了
2、举例
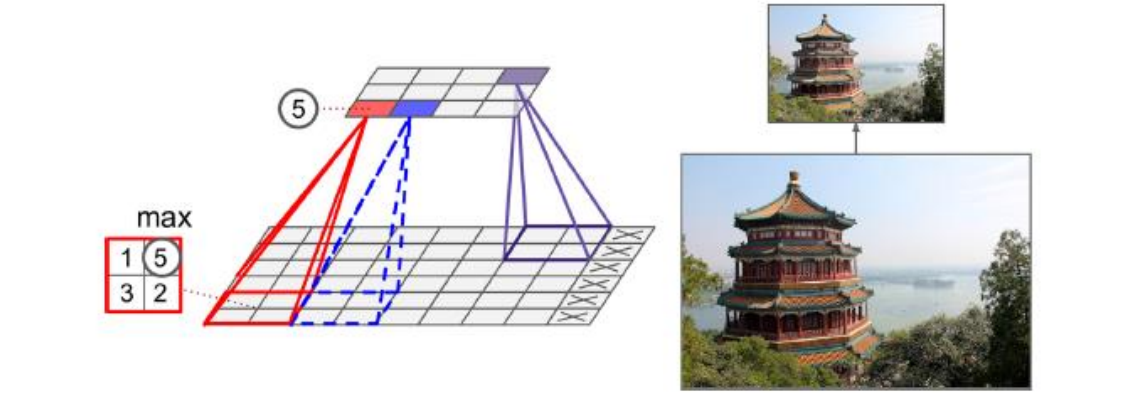
3、结论
长和宽两倍小,面积4倍小,丢掉75%的输入值
一般情况下,池化层工作于每一个独立的输入通道,所以输出的深度和输入的深度相同
4、代码
import numpy as np from sklearn.datasets import load_sample_images import tensorflow as tf import matplotlib.pyplot as plt # 加载数据集 # 输入图片通常是3D,[height, width, channels] # mini-batch通常是4D,[mini-batch size, height, width, channels] dataset = np.array(load_sample_images().images, dtype=np.float32) # 数据集里面两张图片,一个中国庙宇,一个花 batch_size, height, width, channels = dataset.shape print(batch_size, height, width, channels)# channels是3个 # 创建输入和一个池化层 X = tf.placeholder(tf.float32, shape=(None, height, width, channels)) # TensorFlow不支持池化多个实例,所以ksize的第一个batch size是1 # TensorFlow不支持池化同时发生的长宽高,所以必须有一个是1,这里channels就是depth维度为1 max_pool = tf.nn.max_pool(X, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')#没有卷积直接做池化 # avg_pool() with tf.Session() as sess: output = sess.run(max_pool, feed_dict={X: dataset}) plt.imshow(output[0].astype(np.uint8)) # 画输入的第一个图像 plt.show()
总结:在一个卷积层里面,不同的卷积核步长和维度都一样的,每个卷积核的channel是基于上一层的channel来的
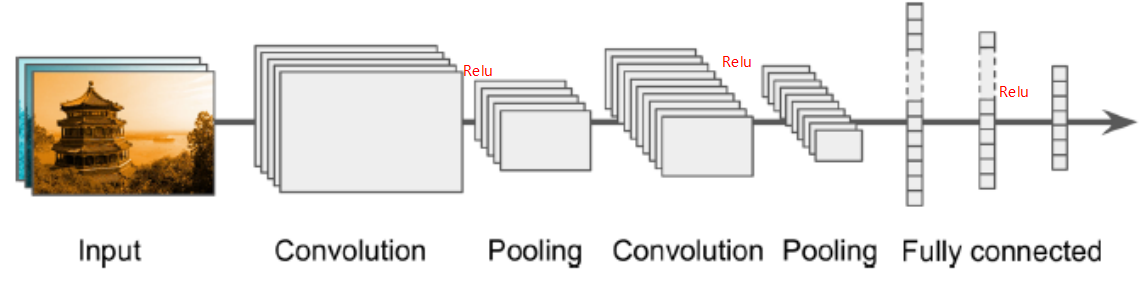
三、CNN架构
原理:
典型的CNN架构堆列一些卷积层
1、一般一个卷积层后跟ReLU层,然后是一个池化层,然后另一些个卷积层+ReLU层,然后另一个池化层,通过网络传递的图片越来越小,但是也越来越深,例如更多的特征图!(随着深度越深,宽度越宽,卷积核越多),这些层都是在提取特征。
2、最后常规的前向反馈神经网络被添加,由一些全连接的层+ReLU层组成,最后是输出层预测,例如一个softmax层输出预测的类概率(真正分类是最后全连接层)。
3、一个常见的误区是使用卷积核过大,你可以使用和9*9的核同样效果的两个3*3的核,好处是会有更少的参数需要被计算,还可以在中间多加一个非线性激活函数ReLU,来提供复杂程度(层次越多不是坏事)
图示: