一、前述
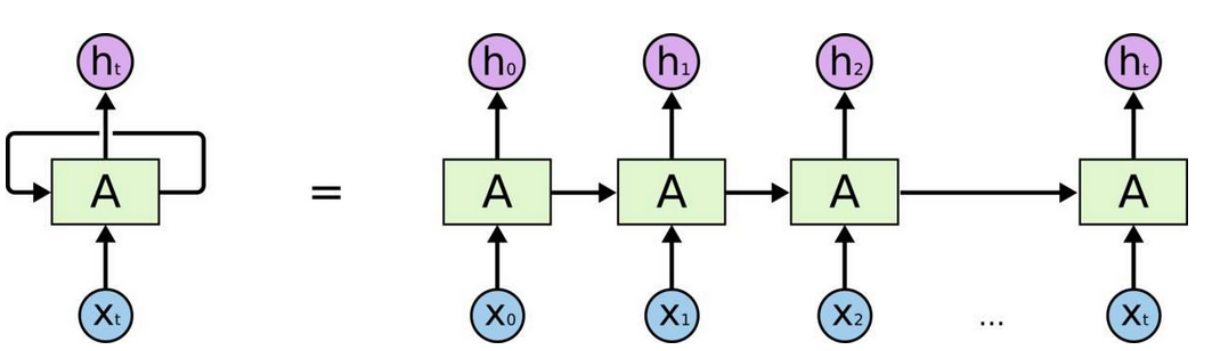
传统的神经网络每个输入节点之间没有联系,
RNN (对中间信息保留):

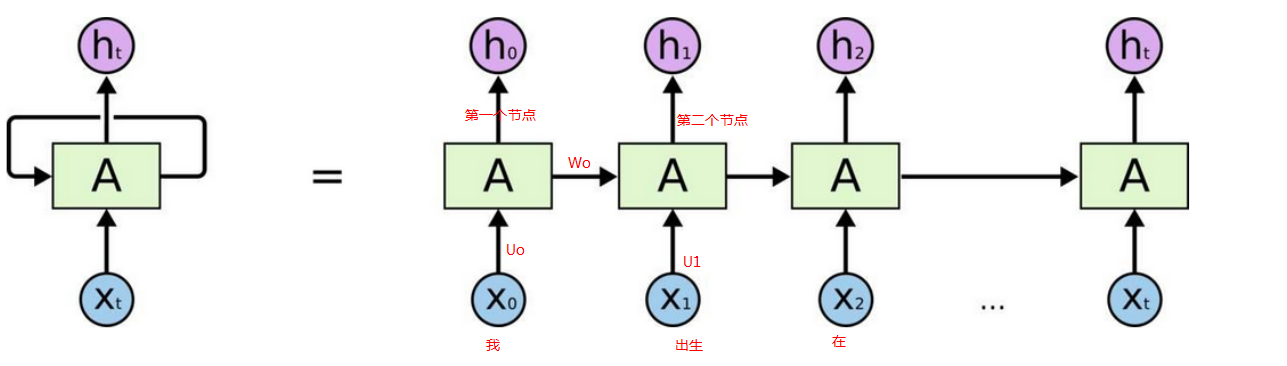
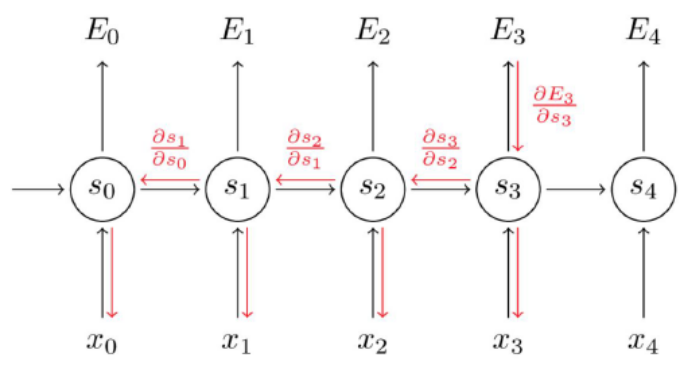
由图可知,比如第二个节点的输入不仅依赖于本身的输入U1,而且依赖上一个节点的输入W0,U0,同样第三个节点依赖于前两个节点的输入,
假设每一个节点分别代表着“我出生在中国,我说——”的一个预测,则“说”后面则是依赖于前面的说的每个单词的所有组合。
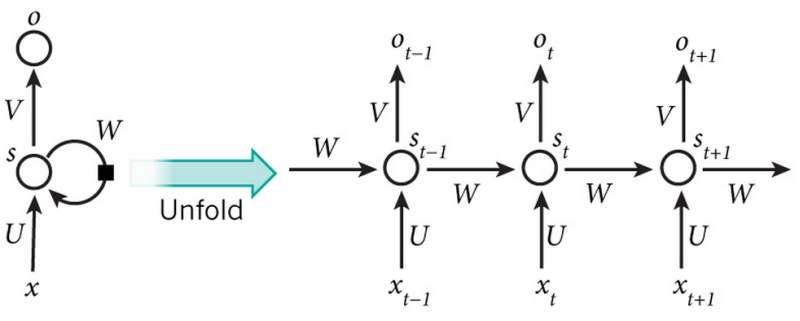
xt表示第t,t=1,2,3...步(step)的输入
st为隐藏层的第t步的状态,它是网络的记忆单元。
st=f(Uxt+Wst−1),其中f一般是非线性的激活函数。
ot是第t步的输出,如下个单词的向量表示softmax(Vst)(多分类)。
二、具体
1、递归神经网络的反向传播
损失函数有多个,以E3为例
E3由t0-t3时刻x,W共同确定 Δ W的确定要考虑E3在各个时刻对w导数。
t3:
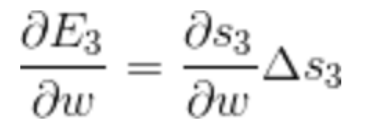
t2:
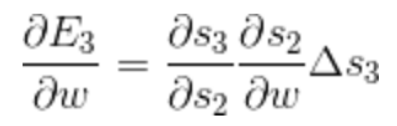
t1:
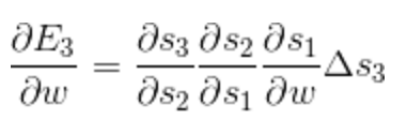
不仅更新当前节点的输入梯度,还更新当前节点的所有记忆单元,一直传播下去。
2、RNN局限性问题
I am Chines, I Love China
递归神经网络参数太多,信息量冗余(因为最后的预测可能只 依赖它最近的词,但我们输入的时候是所有的词,所以信息量冗余)、梯度消失或者爆炸。

3、LSTM(长短记忆网络)
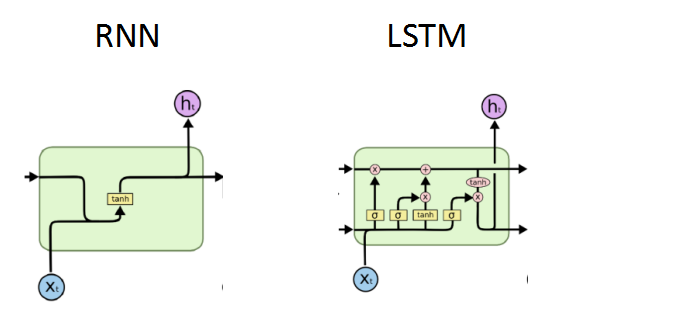
为了解决RNN的一些缺点,RNN与LSTM对比
C:控制参数
决定什么样的信息会被保留什么样的会被遗忘

具体操作:
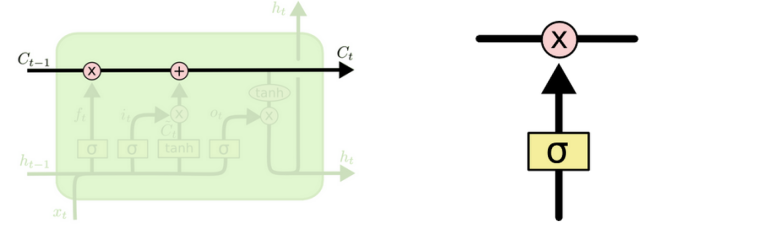
门是一种让信息选择式通过的方法sigmoid 神经网络层和一乘法操作。
Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”!
Sigmoid函数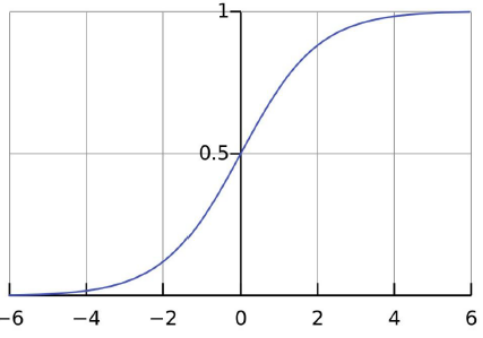

具体过程:
丢弃的信息:
先把当前节点的输入和之前记忆的输入传递进来,然后通过sigmod函数组合起来后得到的函数值(0,1)之间,然后再跟Ct-1组合,决定丢弃什么信息。Ct是永远更新维护的值。


保留的信息:
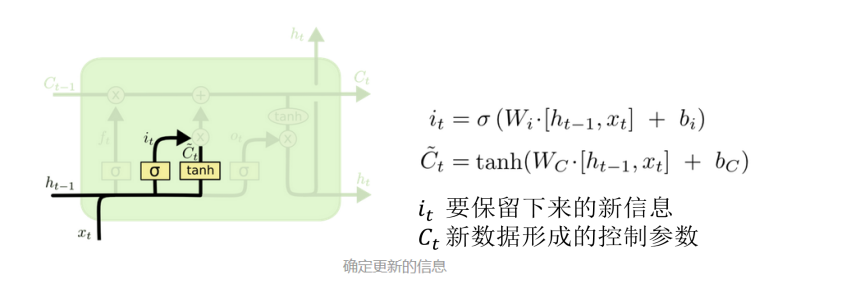

最后总的信息:
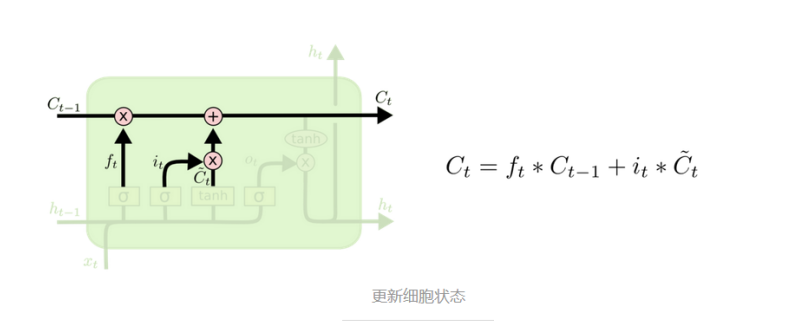
分两部分,遗忘的信息Cti-1和保留Ct的信息。先走遗忘的信息,再走保留的信息。Ct从开始到最后一直更新。
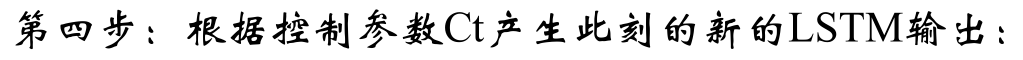
输出:
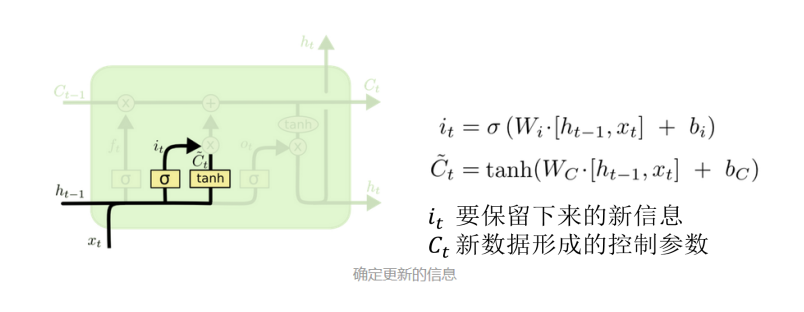
LSTM整体架构:
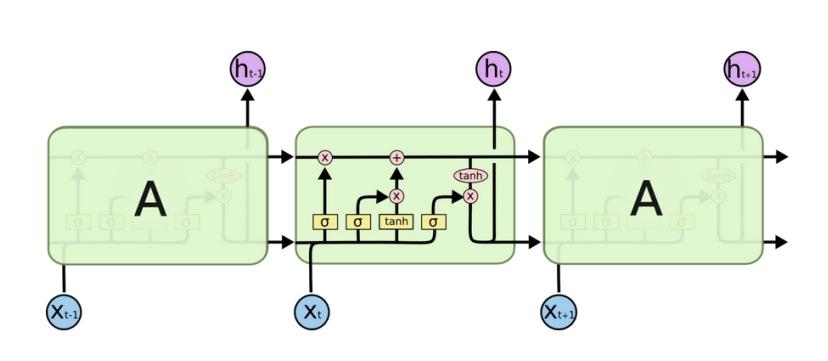
与RNN对比会有一部分信息保留,一部分信息丢弃。LSTM比RNN更实用。