Hive 支持的存储数的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET
1 默认存储格式:TEXTFILE
Hive 在创建表的时候的时候如果没有使用row format 或者 stored as 子句, 那么这个时候 Hive 所使用的默认存储格式就是TEXTFILE.
文件中一个行(line), 存储表中的一行数据(row).
注意:
默认的行内分隔符是ctrl+a, ASCII 码值是 1, 而不是制表符
集合类(array, struct)的默认分隔符是:ctrl+B (2)
的映射(map)的默认分隔符是ctrl+C (3)
行与行之间用换行符分割( )
前面中分隔符都可以手动设置, 行分隔符目前只支持换行符.
可以用八进制形式表示分隔符: �01 , �02, �03
create table ...; # 等价于 create table ...; row format delimited fields terminated by '�01' collection items terminated by '�02' map keys terminated by '�03' lines terminated by ' '
2 二进制存储格式
SEQUENCEFILE 顺序文件
ORC 文件
PARQUET 文件
二进制格式的使用方法很简单, 只要通过建表语句中的stored as 子句做相应的声明就可以了.
注意: 不需要指定 row format, 因为其格式是由底层的二进制文件格式来控制的.
二进制格式文件可以划分为两大类:
基于行的格式 适合同时处理一行中很多列的情况
基于列的格式 适合于值访问其中一小部分的类的查询比较有效
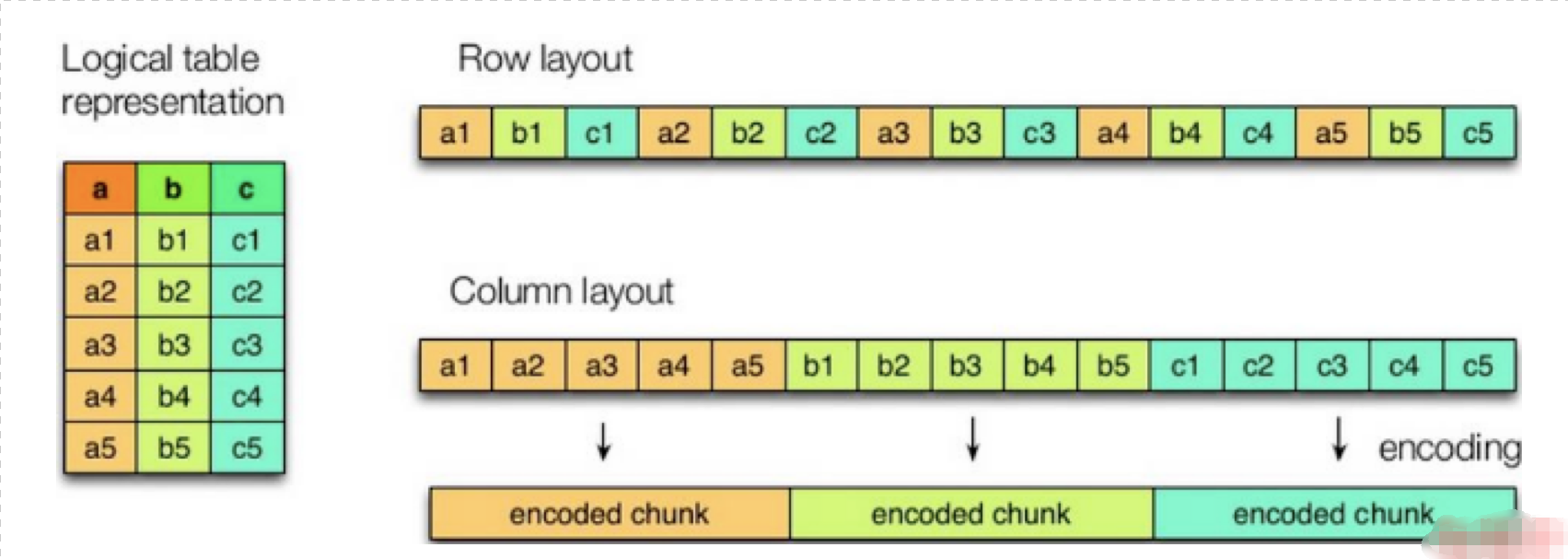
SEQUENCEFILE 的存储格式都是基于行存储的.
ORC 和 PARQUET 是基于列式存储的.